The emergence of large-scale pre training model , It brings a new solution paradigm for natural language processing tasks , It has also significantly improved all kinds of NLP The benchmark effect of the task . since 2020 year ,OPPO Xiaobu assistant team began to explore and apply the pre training model , from “ It can be industrialized on a large scale ” From the angle of , It has successively researched 100 million 、 Pre training model with parameters of 300 million and 1 billion OBERT.
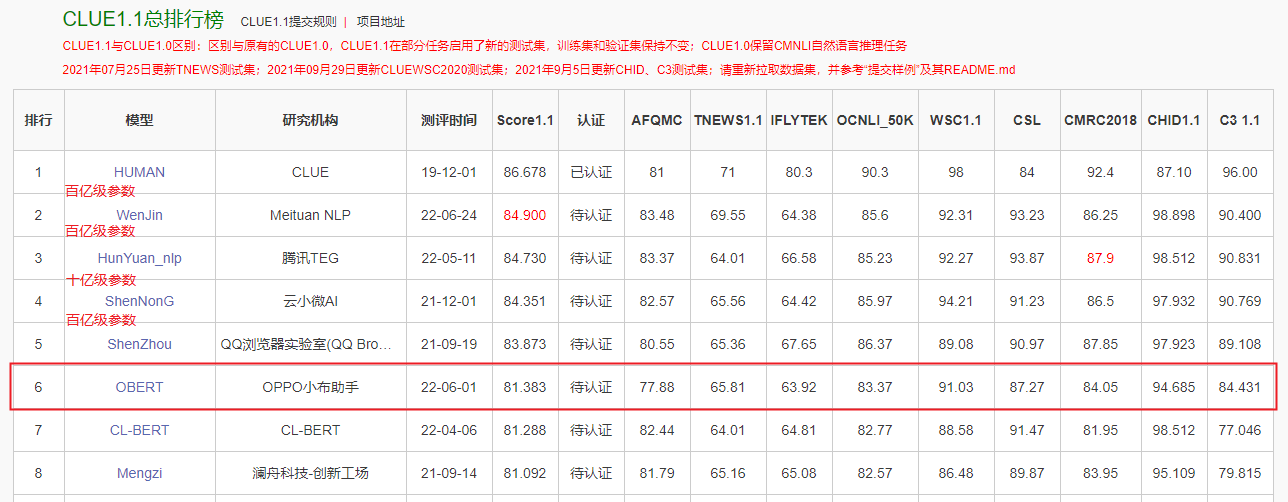
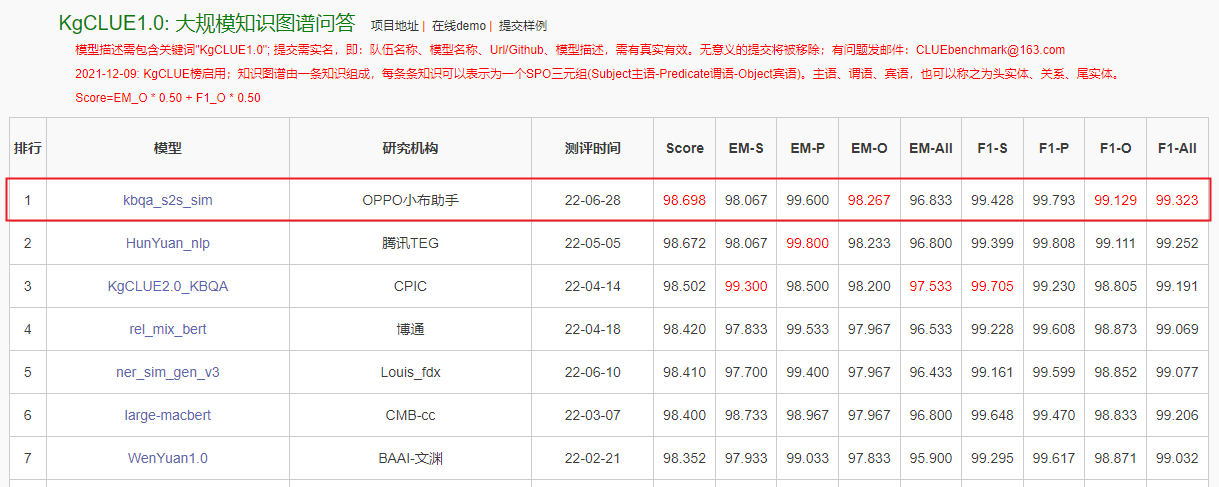
In the near future ,OPPO Xiaobu assistant team and machine learning department jointly completed a billion parameter model “OBERT” Pre training , The model passes through 5 Kind of mask Mechanism from TB Learning language knowledge in English level corpus , In business 4% The above promotion ; In the industry comparison evaluation ,OBERT Leap to the benchmark of Chinese language understanding CLUE1.1 Fifth in the overall list 、 Large scale knowledge map Q & A KgCLUE1.0 Top of the list , Enter the first tier on the billion level model , Scores of multiple subtasks and top ranking 3 The effect of the ten billion parameter model is very close , The parameter quantity is only one tenth of the latter , It is more conducive to large-scale industrial applications .
background
With NLP The rapid development of field pre training technology ,“ Preliminary training + fine-tuning ” It has gradually become a new paradigm to solve problems such as intention recognition , After the early exploration and attempt of Xiaobu assistant team , In Encyclopedia skill classification 、 Chat semantic matching 、 Reading comprehension answer extraction 、FAQ The fine rehearsal and other scenarios have been launched, and the self-developed 100 million level model has achieved significant benefits , And there is still room for improvement , It verifies the necessity of further self-developed onebillion level model and promoting its implementation .
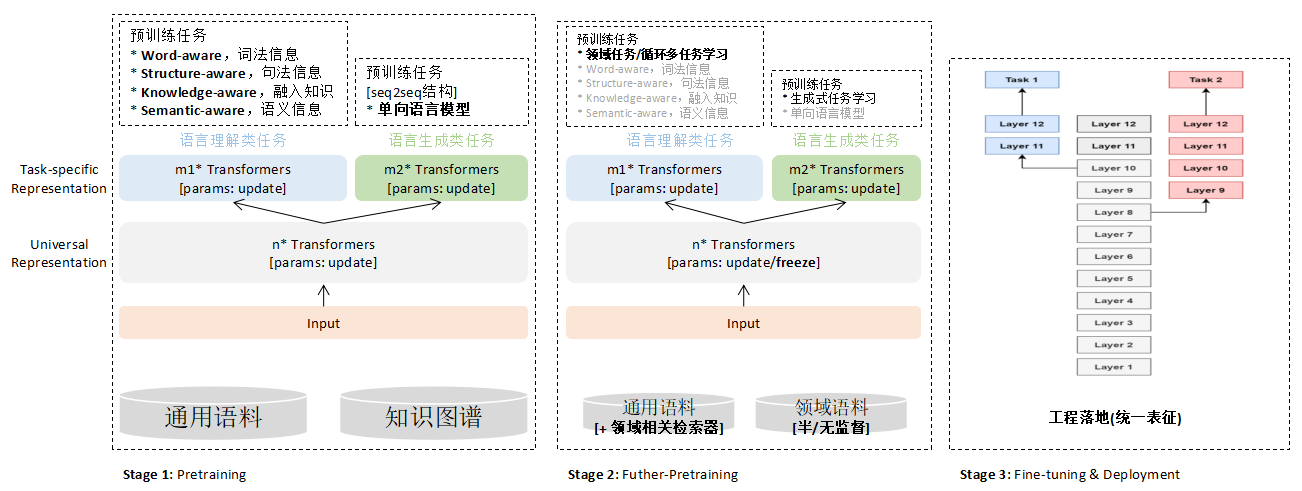
Xiao Bu's assistant scene involves intention understanding 、 Multiple rounds of chat 、 Text matching, etc NLP Mission , Combine work [6,14] Experience , Xiaobu assistant team will follow the figure from pre training to business landing 3 As shown in , Include Pretraining、Futher-Pretraing、Fine-tuning&Deployment Equal stage . There are four main features :
One is
Characterization decoupling
, The unified token adapts to different downstream tasks , It can meet downstream understanding tasks and multiple rounds of chat generation tasks at the same time , Better meet the rich application scenarios of Xiaobu assistant ;
Two is
Retrieval enhancement
, The retrieval objects include knowledge map , And general text fragments related to the target task ;
The third is
Multistage
, From data 、 The dimension of the task gradually adapts to the target scene for training , Balance self-monitoring training and downstream effects , Directional acquisition of unsupervised information related to the target scene 、 Weakly supervised corpus data , Perform further pre training tuning ;
Fourth,
Model magnitude
With 100 million 、 three hundred million 、 Billion level , More friendly support for large-scale application landing .
OBERT Pre training model
Pre training corpus
Work from open source [1] The experimental results show that , The greater the number and content diversity of corpus , The effect of downstream tasks will be further improved . Based on this , The little cloth assistant team collects and cleans 1.6TB corpus , The content includes encyclopedia 、 Community Q & A 、 News, etc . The pretreatment process is shown in the figure 4 Shown . Special thanks to Inspur for sharing the source 1.0 Part of the pre training corpus , by OBERT The training of the model adds more sufficient data resources .

Pretraining task
Thanks to the low cost of data acquisition and the powerful migration ability of language models , at present NLP The main task of pre training is language model based on distributed hypothesis , In the one-way generative language model (LM), Prefix - One way generative language model (Prefix-LM) And bidirectional mask language model (MLM) On the choice of , Affected by work [2,3] Inspired by the , I chose MLM As a pre training task , Because it is in the downstream natural language understanding class (NLU) Better effect on the task .

Specific to the mask Strategy , Pictured 5, There are two kinds of coarse granularity .
First, the whole word 、 Entity 、 key word 、 The phrase 、 Short sentences and other words mask , Text representation can be learned from different granularity , Is a common practice . It should be noted that ,mask Part and context of use
Context
From the same paragraph , The goal is like (1).
P
(
w
|
Context
) (1)
The second is to consider the representation learning of external knowledge enhancement , And REALM[4]、 Memory enhancement [5]、ERNIE3.0[6] Similar approach , Expect to retrieve natural text related to input / Knowledge map triplet , Extended information as input , To better learn text representation . For the current pre training paradigm of knowledge enhancement , The main difference lies in the knowledge base k Set up , And the way of knowledge retrieval . stay OBERT Knowledge mask strategy , Set encyclopedia entries ( Including summary 、 Keywords and other fields ) As a knowledge base , It is equivalent to (Entity,Description,Content) Triple information , Entity link as a way of knowledge retrieval , In particular , Given the initial text , Link entities in the text to knowledge bases such as Baidu Encyclopedia , And take its abstract text as a supplement to the context , Learn more about text representation , The goal is like (2).
P
(
w
|
Context
, k
) (2)
The Xiaobu assistant team first verified the above on the 100 million level model mask The effectiveness of the strategy , Its Zero-shot The effect is significantly better than open source base Level model , Downstream applications have also yielded benefits , Then it is applied to the billion level model training .
Pre training strategy
It mainly adopts course learning , Improve the training difficulty from easy to difficult , So as to improve the stability of training [7]. One side ,seqence length from 64 Gradually increase to 512,batch size from 64 Add to 5120; On the other hand , At the beginning of training mask The strategy is based on word granularity (masked span The length is small , The difficulty of learning is low ), Gradually increase to the phrase 、 Short sentence granularity .
Training accelerates
To speed up OBERT Pre training of the model , There are two challenges in the distributed training framework :
Video memory challenge :
Large model training needs to store model parameters 、 gradient 、 Optimizer status and other parameters , At the same time, there are intermediate results produced by the training process Activation Equal cost , Ten / The scale of 10 billion is far beyond the conventional GPU memory (V100-32GB);
Computational efficiency challenges :
With the increase of the scale of training nodes , How to combine nodes / Network topology and model hybrid parallel , Give greater play to the computing power of nodes , Maintain the linearity of training throughput / Superlinear extension .
Facing these challenges , Based on open source AI Training framework ,OPPO StarFire The machine learning platform team has developed and applied the following solutions :
1、
Hybrid parallel :
Data parallelism + Model parallel + Zero Redundancy Optimizer (ZeRO)[8];
2、
Topology aware communication optimization based on nodes ;
3、
Gradient accumulation .
Through the above optimization method , Compared with the baseline training program 29%+ Improved training throughput , It can be done more quickly OBERT Training iteration of the model , At the same time, it also makes the pre training of 10 billion or even larger parameter models feasible and efficient .
Fine tuning strategy
CLUE1.1 Mission
The Xiaobu assistant team has developed a fine-tuning framework around the pre training model , Contains FGM[9]、PGD[10]、R-Drop[11]、Noise-tune[12]、Multi-Sample Dropout[13] And other ways to improve the robustness of fine-tuning , It also includes the configuration of adding lexical auxiliary tasks for downstream main tasks , Using the framework , Just modify the configuration file to classify the text 、 Similarity degree 、 The above optimization method is used in different downstream tasks such as slot lifting , Get the results of different optimization methods quickly .
KgCLUE1.0 Mission
Xiaobu assistant team reuses the knowledge question and answer scheme of voice assistant , Applied to the KgCLUE Knowledge map question and answer evaluation task ; On the plan , Based on OBERT Big model , The fusion ner+similar Of pipeline Methods and generation based solutions , Got the first place result . What's more valuable is , Xiaobu assistant achieved the above results by using only a single model without integration .
Landing plan
In the practice of pre training landing , The little cloth assistant uses multiple NLU( Such as Knowledge Q & A NLU、 System settings NLU、 gossip NLU) To solve question and answer tasks in various fields , Multiple NLU You need to use pre training alone to fine tune downstream tasks , Will bring huge GPU Calculate the pressure .
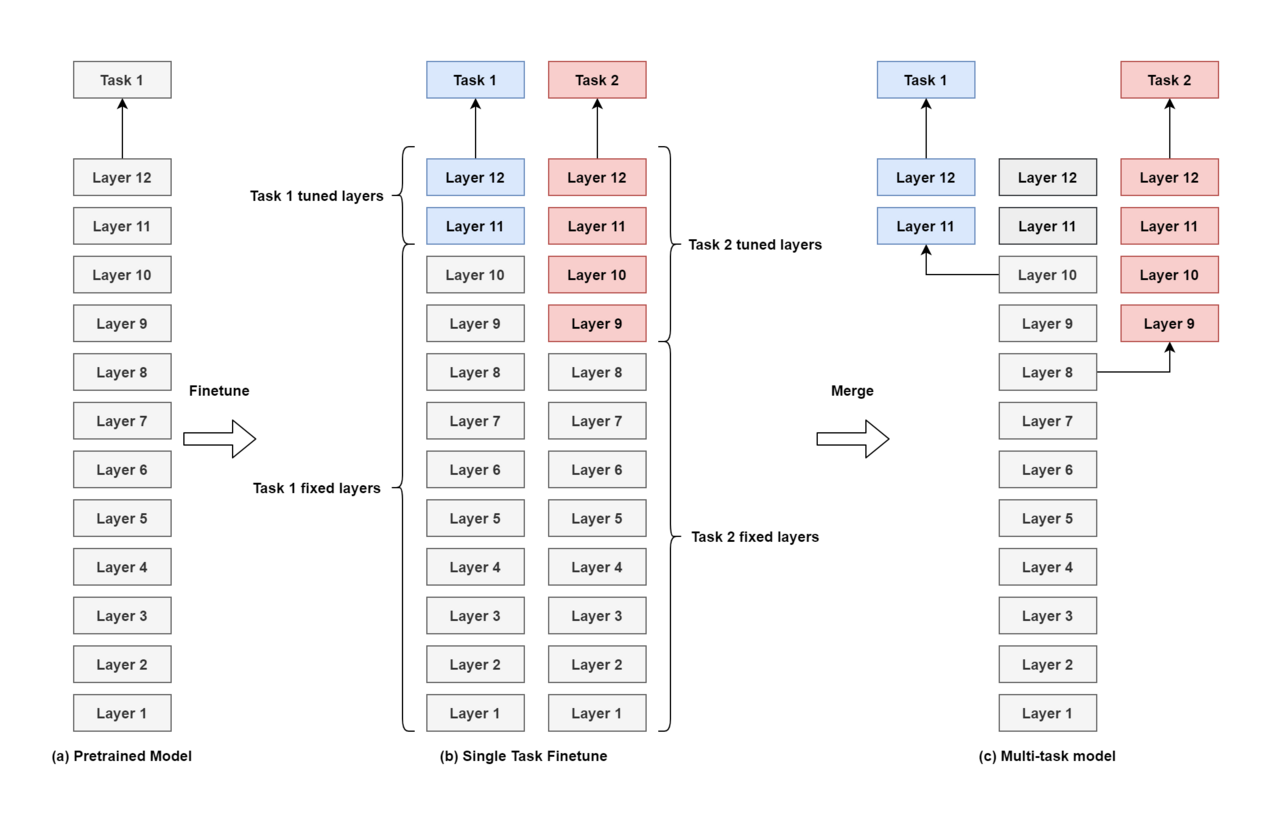
In order to solve the above problems , Little cloth assistant proposed a unified characterization scheme , Here's the picture 7. The scheme includes the following three steps :
1、
Preliminary training
2、
Multitasking fine tuning :
Practical discovery , In order to reduce the amount of global computation , It can be fixed BERT Model topM layer transformer, Only after task fine tuning N layer , The effect is only different from the optimal solution of full fine tuning 1% within
3、
Multitask merge :
Inference time , Calling NLU front , After the first reasoning of the backbone network , By NLU Use the corresponding backbone network layer as the input of downstream tasks , Then carry out single task reasoning .
The practice of Xiaobu assistant shows , When downstream NLU by 10、 Average fine-tuning levels of downstream tasks N=3 when , The global computation of the unified representation scheme is about... Of the full fine-tuning scheme 27%.
Future direction
The Xiaobu assistant team will continue to optimize the pre training technology in combination with the characteristics of the intelligent assistant scene , Including using retrieval enhancement paradigm to optimize short text representation 、 Mining and using feedback information to construct unsupervised pre training tasks 、 And explore model lightweight technology to accelerate the landing of large models .
Team profile
OPPO Xiaobu assistant team takes Xiaobu assistant as AI The key carrier of technology landing , Committed to providing multiple scenarios 、 Intelligent user experience . Little cloth's assistant is OPPO Smartphones and IoT Intelligent assistant built in the device , Including voice 、 Suggest 、 Instructions 、 Five ability modules of screen recognition and scanning . As a multi terminal 、 Multimodal 、 Conversational intelligent assistant , Xiaobu assistant's technology covers speech recognition 、 Semantic understanding 、 Dialogue generation 、 Knowledge Q & a system 、 Open domain chat 、 Recommendation algorithm 、 Digital person 、 Multimodality and other core areas , Provide users with a more friendly and natural human-computer interaction experience . The technical strength of Xiaobu assistant has always maintained a leading position in technological innovation and Application , Currently, it has been used in many natural language processing 、 Speech recognition related industry authoritative competitions and lists have achieved brilliant results .
OPPO The machine learning team is committed to utilizing ML Technology to build an integrated platform , promote AI Engineers' full link development experience . oriented OPPO developer , Provide lightweight 、 The standard 、 Full stack AI development service platform , In data processing 、 model building 、 model training 、 Model deployment 、 Full link of model management AI The development link provides managed services and AI Tools , Cover personalized recommendations 、 Advertising algorithm 、 Mobile image optimization 、 Voice assistant recommends 、 Figure learning risk control 、 Search for NLP Wait for dozens of landing scenes , Help users quickly create and deploy AI application , Manage the whole cycle AI Solution , So as to help accelerate the digital transformation and promote AI Engineering construction .
reference
[1] Cloze-driven Pretraining of Self-attention Networks
[2] Pre-trained Models for Natural Language Processing: A Survey
[3] YUAN 1.0: LARGE-SCALE PRE-TRAINED LANGUAGE MODEL IN ZERO-SHOT AND FEW-SHOT LEARNING
[4] REALM: Retrieval-Augmented Language Model Pre-Training
[5] Training Language Models with Memory Augmentation
[6] ERNIE 3.0: LARGE-SCALE KNOWLEDGE ENHANCED PRE-TRAINING FOR LANGUAGE UNDERSTANDING AND GENERATION
[7] Curriculum Learning: A Regularization Method for Efficient and Stable Billion-Scale GPT Model Pre-Training
[8] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
[9] FGM: Adversarial Training Methods for Semi-Supervised Text Classification
[10] Towards Deep Learning Models Resistant to Adversarial Attacks
[11] R-Drop: Regularized Dropout for Neural Networks
[12] NoisyTune: A Little Noise Can Help You Finetune Pretrained Language Models Better
[13] Multi-Sample Dropout for Accelerated Training and Better Generalization
[14] Mengzi: Towards Lightweight yet Ingenious Pre-trained Models for Chinese
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/185/202207041532498646.html