当前位置:网站首页>How to use tensorflow2 for cat and dog classification and recognition
How to use tensorflow2 for cat and dog classification and recognition
2022-07-05 21:46:00 【Yisu cloud】
How to use Tensorflow2 Classify and recognize cats and dogs
This article mainly explains “ How to use Tensorflow2 Classify and recognize cats and dogs ”, The explanation in the text is simple and clear , Easy to learn and understand , Next, please follow Xiaobian's ideas and go deeper slowly , Study and learn together “ How to use Tensorflow2 Classify and recognize cats and dogs ” Well !
Data set acquisition
Use tf.keras.utils.get_file() Be able to from the specified URL Get the data set directly , We have obtained the pictures needed for cat and dog classification from known websites , In the form of a compressed package , I'm going to call it cats_and_dogs_filtered.zip, Set a variable for this operation path, This variable points to the path stored after the data set is downloaded .
import tensorflow as tfpath=tf.keras.utils.get_file('cats_and_dogs_filtered.zip',origin='https://storage.googleapis.com/mledu-datasets/cats_and_dogs_filtered.zip')print(path)# Will output its path , And the current notebook The file path is the same File decompression
Using third party libraries zipfile Decompress the file , The following code unzips it into the specified folder .
import zipfilelocal_zip = pathzip_ref = zipfile.ZipFile(local_zip, 'r')zip_ref.extractall('C:\\Users\\lenovo\\.keras\\datasets')zip_ref.close()There are two more folders in the folder , It is used to train and verify the neural network model , Each folder contains two more files , The location path of the pictures representing different categories of cats and dogs .
We are building a neural network model , need Training set (train data) And Verification set (validation data). Generally speaking , The training set here is to tell the model the appearance of cats and dogs . The validation set can check the quality of the model , Evaluate the effectiveness of the model .
Divide the file into training set and verification set
Use os The library finds the path to the folder of cat and dog data , Divide it into datasets according to folders .
import osbase_dir = 'C:/Users/lenovo/.keras/datasets/cats_and_dogs_filtered'train_dir = os.path.join(base_dir, 'train')validation_dir = os.path.join(base_dir, 'validation')train_cats_dir = os.path.join(train_dir, 'cats')train_dogs_dir = os.path.join(train_dir, 'dogs')validation_cats_dir = os.path.join(validation_dir, 'cats')validation_dogs_dir = os.path.join(validation_dir, 'dogs')
Let's take a look at train In folder cats The folder and dogs File data in the folder .
train_cat_fnames = os.listdir( train_cats_dir )train_dog_fnames = os.listdir( train_dogs_dir )print(train_cat_fnames[:10])print(train_dog_fnames[:10])
['cat.0.jpg', 'cat.1.jpg', 'cat.10.jpg', 'cat.100.jpg', 'cat.101.jpg', 'cat.102.jpg', 'cat.103.jpg', 'cat.104.jpg', 'cat.105.jpg', 'cat.106.jpg']['dog.0.jpg', 'dog.1.jpg', 'dog.10.jpg', 'dog.100.jpg', 'dog.101.jpg', 'dog.102.jpg', 'dog.103.jpg', 'dog.104.jpg', 'dog.105.jpg', 'dog.106.jpg']
At the same time, check the size of the image data contained in the file .
print('total training cat images :', len(os.listdir(train_cats_dir)))print('total training dog images :', len(os.listdir(train_dogs_dir)))print('total validation cat images :', len(os.listdir(validation_cats_dir)))print('total validation dog images :', len(os.listdir(validation_dogs_dir)))total training cat images : 1000total training dog images : 1000total validation cat images : 500total validation dog images : 500
We learned about data sets for cats and dogs , We all have 1000 This picture is used to train the model ,500 Pictures are used to verify the effect of the model .
Plot view
The following is the output of cat and dog classification data set pictures , Visually observe the similarities and differences of different pictures .
# Set the canvas size and the number of subgraphs %matplotlib inlineimport matplotlib.image as mpimgimport matplotlib.pyplot as pltnrows = 4ncols = 4pic_index = 0
Draw pictures of eight cats and eight dogs , Look at the features of the pictures in the dataset .
fig = plt.gcf()fig.set_size_inches(ncols*4, nrows*4)pic_index+=8next_cat_pix = [os.path.join(train_cats_dir, fname) for fname in train_cat_fnames[ pic_index-8:pic_index] ]next_dog_pix = [os.path.join(train_dogs_dir, fname) for fname in train_dog_fnames[ pic_index-8:pic_index] ]for i, img_path in enumerate(next_cat_pix+next_dog_pix): sp = plt.subplot(nrows, ncols, i + 1) sp.axis('Off') img = mpimg.imread(img_path) plt.imshow(img)plt.show()
By observing the output image, we found that the shape and scale of the image are different . Different from simple handwritten numeral set recognition , Handwritten numeral sets are unified 28*28 The size of the grayscale picture , The cat and dog data set is a color picture with different length and width .
model
Neural network model
model = tf.keras.models.Sequential([ tf.keras.layers.Conv2D(16, (3,3), activation='relu', input_shape=(150, 150, 3)), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(32, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Conv2D(64, (3,3), activation='relu'), tf.keras.layers.MaxPooling2D(2,2), tf.keras.layers.Flatten(), tf.keras.layers.Dense(512, activation='relu'), tf.keras.layers.Dense(1, activation='sigmoid') ])
We consider converting all the pictures into 150*150 Picture of shape , Then add a series of convolution layers and pooling layers , Finally, flatten and enter DNN.
model.summary()# Observe the parameters of the neural network
Output results :
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 18496) 0
_________________________________________________________________
dense (Dense) (None, 512) 9470464
_________________________________________________________________
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 9,494,561
Trainable params: 9,494,561
Non-trainable params: 0
_________________________________________________________________
Outshape The size change of the image in the neural network is shown , It can be seen in the continuous neural network layer , Convolution layer reduces the size of the picture , However, the pool layer always reduces the size of the image by half .
Model compilation
Next, we will compile the model . We will use binary cross entropy binary_crossentropy Loss training our model , Because this is a binary classification problem , The activation function of our last layer is set to sigmoid, We will use a learning rate of 0.001 Of rmsprop Optimizer . During training , We are going to monitor the accuracy of classification .
under these circumstances , Use RMSprop The optimization algorithm is lower than the random gradient (SGD) preferable , because RMSprop Automatically adjust the learning rate for us . ( Other optimizers such as Adam and Adagrad, It will also automatically adjust the learning rate during training , The same applies here .)
from tensorflow.keras.optimizers import RMSpropmodel.compile(optimizer=RMSprop(lr=0.001), loss='binary_crossentropy', metrics = ['acc'])
Data preprocessing
Let's set up the data generator , It will read the pictures in our source folder , Turn them into tensors , And provide them and their labels to the neural network . We will get a generator for training images and a generator for validating images . Our generator will generate in batches 20 The size of Zhang is 150*150 Images and their labels .
Data entering neural networks should usually be standardized in some way , To make it easier to be processed by neural network . In our case , We will normalize the pixel values to [0,1] Within the scope of ( Initially, all values are in [0,255] Within the scope of ) To preprocess our images .
stay Keras in , This can be done by using rescale Parametric keras.preprocessing.image.ImageDataGenerator Class to complete .ImageDataGenerator adopt .flow(data, labels) or .flow_from_directory(directory) Get data . then , These generators can be used in conjunction with..., which accepts data generators as inputs Keras Model methods are used together :fit_generator、evaluate_generator and predict_generator.
from tensorflow.keras.preprocessing.image import ImageDataGenerator# Standardize to [0,1]train_datagen = ImageDataGenerator( rescale = 1.0/255. )test_datagen = ImageDataGenerator( rescale = 1.0/255. )# Batch build 20 The size of the pieces is 150x150 The image and its label are used for training train_generator = train_datagen.flow_from_directory(train_dir, batch_size=20, class_mode='binary', target_size=(150, 150)) # Batch build 20 The size of the pieces is 150x150 The image and its label are used to verify validation_generator = test_datagen.flow_from_directory(validation_dir, batch_size=20, class_mode = 'binary', target_size = (150, 150))
Found 2000 images belonging to 2 classes.Found 1000 images belonging to 2 classes.
model training
We let all 2000 Zhang can train with images 15 Time , And at all 1000 Verification on test images .
We continuously observe the value of each training . See in every period 4 It's worth —— Loss 、 Accuracy 、 Verification loss and verification accuracy .
Loss and Accuracy It is a good indicator of training progress . It guesses the classification of training data , Then calculate the result according to the trained model . Accuracy is part of the right guess . Verification accuracy is the calculation of data not used in training .
history = model.fit_generator(train_generator, validation_data=validation_generator, steps_per_epoch=100, epochs=15, validation_steps=50, verbose=2)
result :
Epoch 1/15
100/100 - 26s - loss: 0.8107 - acc: 0.5465 - val_loss: 0.7072 - val_acc: 0.5040
Epoch 2/15
100/100 - 30s - loss: 0.6420 - acc: 0.6555 - val_loss: 0.6493 - val_acc: 0.5780
Epoch 3/15
100/100 - 31s - loss: 0.5361 - acc: 0.7350 - val_loss: 0.6060 - val_acc: 0.7020
Epoch 4/15
100/100 - 29s - loss: 0.4432 - acc: 0.7865 - val_loss: 0.6289 - val_acc: 0.6870
Epoch 5/15
100/100 - 29s - loss: 0.3451 - acc: 0.8560 - val_loss: 0.8342 - val_acc: 0.6740
Epoch 6/15
100/100 - 29s - loss: 0.2777 - acc: 0.8825 - val_loss: 0.6812 - val_acc: 0.7130
Epoch 7/15
100/100 - 30s - loss: 0.1748 - acc: 0.9285 - val_loss: 0.9056 - val_acc: 0.7110
Epoch 8/15
100/100 - 30s - loss: 0.1373 - acc: 0.9490 - val_loss: 0.8875 - val_acc: 0.7000
Epoch 9/15
100/100 - 29s - loss: 0.0794 - acc: 0.9715 - val_loss: 1.0687 - val_acc: 0.7190
Epoch 10/15
100/100 - 30s - loss: 0.0747 - acc: 0.9765 - val_loss: 1.1952 - val_acc: 0.7420
Epoch 11/15
100/100 - 30s - loss: 0.0430 - acc: 0.9890 - val_loss: 5.6920 - val_acc: 0.5680
Epoch 12/15
100/100 - 31s - loss: 0.0737 - acc: 0.9825 - val_loss: 1.5368 - val_acc: 0.7110
Epoch 13/15
100/100 - 30s - loss: 0.0418 - acc: 0.9880 - val_loss: 1.4780 - val_acc: 0.7250
Epoch 14/15
100/100 - 30s - loss: 0.0990 - acc: 0.9885 - val_loss: 1.7837 - val_acc: 0.7130
Epoch 15/15
100/100 - 31s - loss: 0.0340 - acc: 0.9910 - val_loss: 1.6921 - val_acc: 0.7200
Run the model
Next, use the model to predict the actual operation . The following code will determine whether the specified strange picture is a dog or a cat .
Select a picture file to predict :
import tkinter as tkfrom tkinter import filedialog''' Opens the select Folder dialog box '''root = tk.Tk()root.withdraw()Filepath = filedialog.askopenfilename() # Get the selected file
import numpy as npfrom keras.preprocessing import imagepath=Filepathimg=image.load_img(path,target_size=(150, 150)) x=image.img_to_array(img)x=np.expand_dims(x, axis=0)images = np.vstack([x]) classes = model.predict(images, batch_size=10)print(classes[0]) if classes[0]>0: print("This is a dog") else: print("This is a cat")A file selection box will pop up , Select the file to get the predicted results .
Visual intermediate representation
In order to understand what characteristics have been learned in the neural network model , You can visually input how to convert when you pass through God's network .
We randomly select an image of a cat or dog from the training set , Then generate a graph , Each of these lines is the output of a layer , Each image in the row is a specific filter in the output characteristic graph .
import numpy as npimport randomfrom tensorflow.keras.preprocessing.image import img_to_array, load_img# Input layer successive_outputs = [layer.output for layer in model.layers[1:]]# Visualization model visualization_model = tf.keras.models.Model(inputs = model.input, outputs = successive_outputs)# Choose a picture of a cat or dog at random cat_img_files = [os.path.join(train_cats_dir, f) for f in train_cat_fnames]dog_img_files = [os.path.join(train_dogs_dir, f) for f in train_dog_fnames]img_path = random.choice(cat_img_files + dog_img_files)img = load_img(img_path, target_size=(150, 150)) x = img_to_array(img) # Convert to 150*150*3 Array of x = x.reshape((1,) + x.shape) # Convert to 1*150*150*3 Array of # Standardization x /= 255.0successive_feature_maps = visualization_model.predict(x)layer_names = [layer.name for layer in model.layers]for layer_name, feature_map in zip(layer_names, successive_feature_maps): if len(feature_map.shape) == 4: n_features = feature_map.shape[-1] size = feature_map.shape[ 1] display_grid = np.zeros((size, size * n_features)) for i in range(n_features): x = feature_map[0, :, :, i] x -= x.mean() x /= x.std () x *= 64 x += 128 x = np.clip(x, 0, 255).astype('uint8') display_grid[:, i * size : (i + 1) * size] = x scale = 20. / n_features plt.figure( figsize=(scale * n_features, scale) ) plt.title ( layer_name ) plt.grid ( False ) plt.imshow( display_grid, aspect='auto', cmap='viridis' )




As shown in the picture above , We get from the original pixels of the image to more and more abstract and compact representation . The following image shows what the neural network is beginning to focus on , And they show that fewer and fewer features are “ Activate ”.
These representations carry less and less information about the original pixels of the image , But more and more detailed information about image categories . God can regard the network model as a distillation pipeline of picture information , In this way, the more significant features of the image can be obtained through layer by layer .
Evaluate model accuracy and loss values
Output the variation diagram of accuracy and loss value with training times in the training process
acc = history.history[ 'acc' ]val_acc = history.history[ 'val_acc' ]loss = history.history[ 'loss' ]val_loss = history.history['val_loss' ]epochs = range(len(acc))plt.plot ( epochs, acc ,label='acc')plt.plot ( epochs, val_acc ,label='val_acc')plt.legend(loc='best')plt.title ('Training and validation accuracy')plt.figure()plt.plot ( epochs, loss ,label='loss')plt.plot ( epochs, val_loss ,label='val_loss')plt.legend(loc='best')plt.title ('Training and validation loss')By observing the graph lines, it is found that there is an over fitting phenomenon , Our training accuracy is close to 100%, Our verification accuracy stagnates at about 70%. Our verification loss value is only five epoch Then the minimum value is reached .
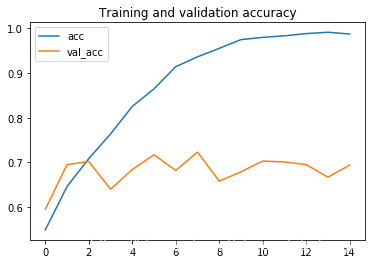
accuracy change
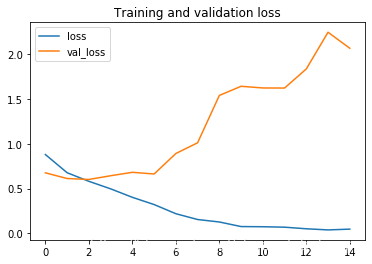
loss Value change
Because the number of our training samples is relatively small , Preventing over fitting should be our primary concern . When there is too little training data , When model learning cannot be extended to new data , That is, when the model starts to use irrelevant features for prediction , Over fitting occurs .
Thank you for reading , That's all “ How to use Tensorflow2 Classify and recognize cats and dogs ” Content. , After learning this article , I believe everyone knows how to use it Tensorflow2 We have a deeper understanding of the problem of cat and dog classification and recognition , The specific use needs to be verified by practice . This is billion speed cloud , Xiaobian will push you articles with more relevant knowledge points , Welcome to your attention !
边栏推荐
- Why can't Chinese software companies produce products? Abandon the Internet after 00; Open source high-performance API gateway component of station B | weekly email exclusive to VIP members of Menon w
- Poj3414广泛搜索
- poj 3237 Tree(树链拆分)
- Objects in the list, sorted by a field
- 2.2 basic grammar of R language
- oracle 控制文件的多路复用
- Analysis and test of ModbusRTU communication protocol
- Parker驱动器维修COMPAX控制器维修CPX0200H
- Sorting out the problems encountered in MySQL built by pycharm connecting virtual machines
- HYSBZ 2243 染色 (树链拆分)
猜你喜欢
Why can't Chinese software companies produce products? Abandon the Internet after 00; Open source high-performance API gateway component of station B | weekly email exclusive to VIP members of Menon w
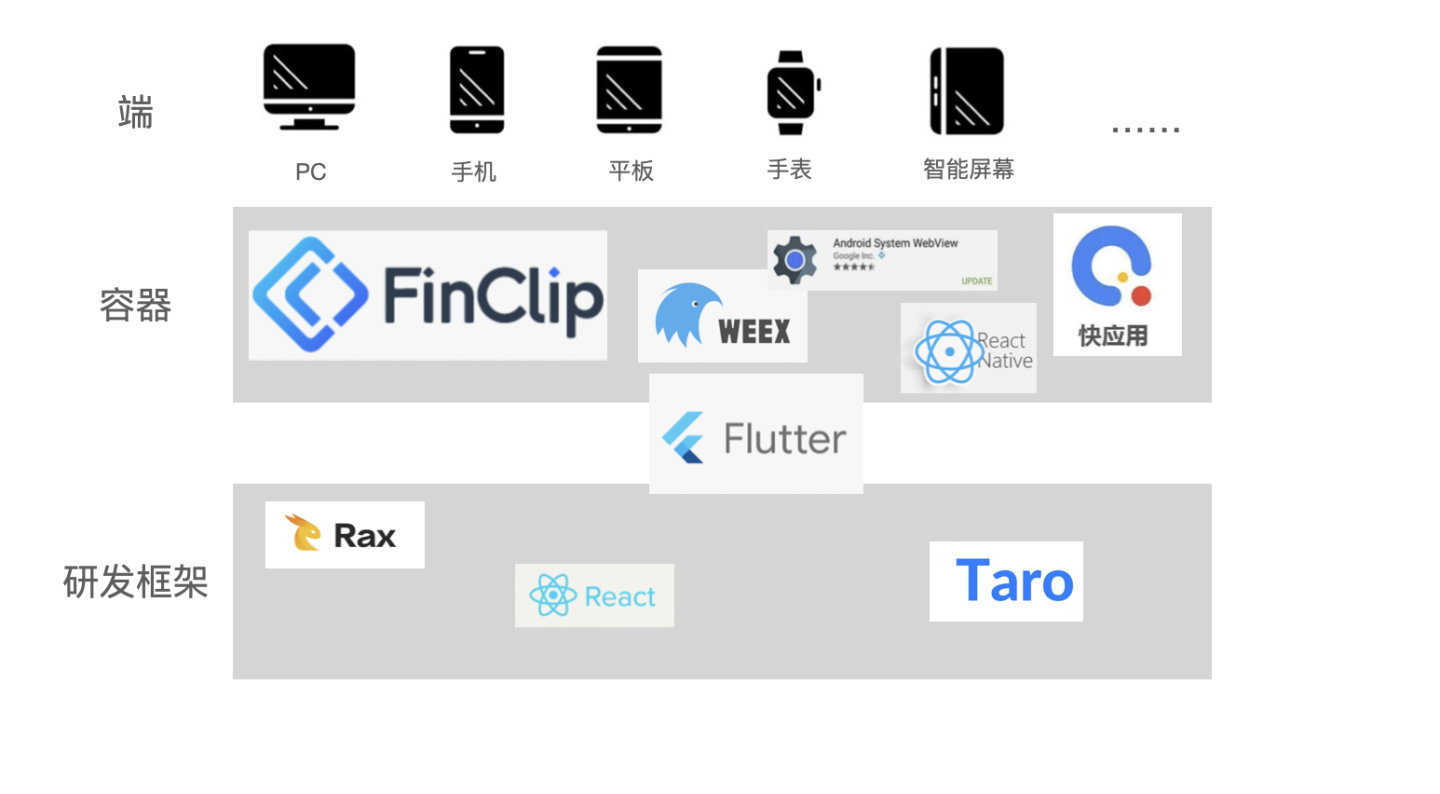
Cross end solution to improve development efficiency rapidly
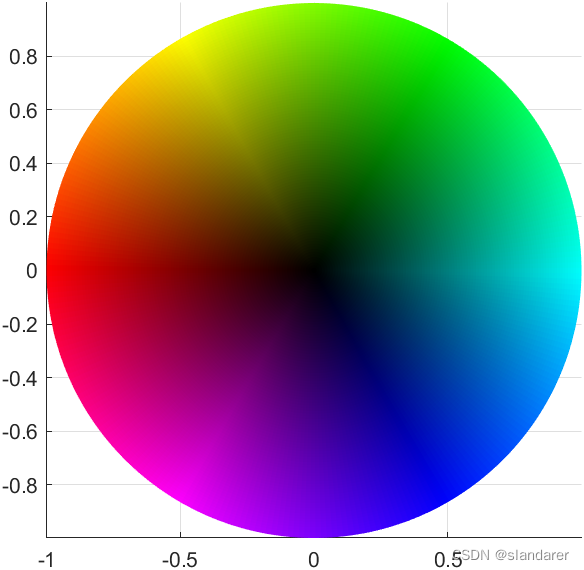
Drawing HSV color wheel with MATLAB
![Longest swing sequence [greedy practice]](/img/e1/70dc21b924232c7e5e3da023a4bed2.png)
Longest swing sequence [greedy practice]

Deeply convinced plan X - network protocol basic DNS
EasyExcel的讀寫操作
Summarize the reasons for 2XX, 3xx, 4xx, 5xx status codes
Golang(1)|从环境准备到快速上手
MMAP
Recursive query of multi-level menu data
随机推荐
Defect detection - Halcon surface scratch detection
kingbaseES V8R3数据安全案例之---审计记录清除案例
Ethereum ETH的奖励机制
Interviewer: will concurrent programming practice meet? (detailed explanation of thread control operation)
Four components of logger
The solution to the problem that Oracle hugepages are not used, causing the server to be too laggy
Robot framework setting variables
Matlab | app designer · I used Matlab to make a real-time editor of latex formula
PostGIS installation geographic information extension
Summary of El and JSTL precautions
R language learning notes
Advantages of robot framework
Get JS of the previous day (timestamp conversion)
123456
秋招将临 如何准备算法面试、回答算法面试题
KingbaseES V8R3集群维护案例之---在线添加备库管理节点
HDU 4391 Paint The Wall 段树(水
MATLAB | App Designer·我用MATLAB制作了一款LATEX公式实时编辑器
Simple interest mode - lazy type
Selenium gets the verification code image in DOM