当前位置:网站首页>Emotional analysis of wechat chat records on Valentine's day based on Text Mining
Emotional analysis of wechat chat records on Valentine's day based on Text Mining
2022-07-05 21:29:00 【Potatoes in Greenhouse】
Irons , Tomorrow is Valentine's day , I don't know if you've already started school and met your partner, haha , Unfortunately, I'm still a poor ghost with no object , But it doesn't matter , We can pretend to have haha , So today we are going to practice wechat chat record analysis based on text mining , Prepare for the future, no ... Here we use the chat records with undergraduate friends as the corpus . The whole analysis process is divided into the following parts :
Catalog
1. Wechat chat record acquisition
2. Data cleaning
2.1 participle 、 Stop 、 duplicate removal
2.2 External dictionary call
3. Data analysis
3.1 Word frequency analysis and word cloud display
3.2 LDA Topic probability model and pyLDAvis visualization
3.2 Other deep learning applications
1. Wechat chat record acquisition
Before the analysis , We have to get the data we want as a corpus , There are Android users and IOS user , Among them, all Android users except Xiaomi have to root Before it can be interpreted into txt file , and IOS Users are relatively simple , It can be used directly iturns perhaps Ace assistant Direct export , Specific steps CSDN There are also many detailed explanations on , I won't go into details here , I use the ace assistant here to back up and then export , After connecting the data cable, the specific steps are as follows :



Follow the above steps to export to txt Chat log file of .
2. Data cleaning
Data cleaning is generally divided into two processes .
2.1 participle 、 Stop 、 duplicate removal
The first is basic processing , It is mainly participle 、 Remove stop words 、 duplicate removal . Let's go straight to the code :
# First, import the library we will use
import codecs
import re
import jieba
import numpy as np
import pandas as pd
import wordcloud
import matplotlib.pyplot as plt
# Secondly, read the chat records we obtained txt file , Because there are many repeated expressions and numbers in the chat record , So we directly use regular expressions for the first cleaning
corpus = []
file = codecs.open(" Chat record .txt","r","utf-8")
for line in file.readlines():
corpus.append(line.strip())
stripcorpus = corpus.copy()
stripcorpus = corpus.copy()
for i in range(len(corpus)):
stripcorpus[i] = re.sub("@([\s\S]*?):","",corpus[i]) # Remove @ ...:
stripcorpus[i] = re.sub("\[([\S\s]*?)\]","",stripcorpus[i]) # [...]:
stripcorpus[i] = re.sub("@([\s\S]*?)","",stripcorpus[i]) # Remove @...
stripcorpus[i] = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,.?、[email protected]#¥%……&*()]+","",stripcorpus[i]) # Remove punctuation and special symbols
stripcorpus[i] = re.sub("[^\u4e00-\u9fa5]","",stripcorpus[i]) # Remove all non Chinese content ( English numbers )
# after , Start word segmentation
stoplist=open(' Stoppage vocabulary of Harbin Institute of Technology .txt','r',encoding='utf-8').read()# Sometimes stop words can't be deleted because list The format of , It is amended as follows txt that will do
result = []
for comments in stripcorpus:
jieba.load_userdict(" Custom dictionary .txt")# This definition dictionary
c_words = jieba.cut(comments)
result.append([word for word in c_words if word not in stoplist and len(word)>1])
This is the result of the initial cleaning :

2.2 External dictionary call
You can see , The result of word segmentation is basically better , This may be related to the fact that chat records are more life oriented ,jieba Libraries are easier to identify , But if some words are forcibly separated , For example, the first line “ Near Chengdu ” Divided into “ Chengdu ” and “ near ”, Then we need to set Custom dictionary . The specific method is to create a txt file , Enter specific words in the file that you don't want to separate , The format is “ word + Frequency of occurrence + The part of speech ”. One word, one line , The effect is as follows :

The code implementation is also very simple , Just call the external dictionary directly before word segmentation :
jieba.load_userdict(" Custom dictionary .txt")3. Data analysis
3.1 Word frequency analysis and word cloud analysis
As the name suggests, it is based on some of the most frequently mentioned words in the chat between two people , To enhance the visual effect , Word cloud is widely used for visualization after word frequency analysis , What needs to be noted here is , Word cloud can analyze the word frequency in the absolute sense , Of course, it can be right TF-IDF Analyze the results after feature extraction ,TF-IDF It's also very simple. ,jieba Kuhe gensim There are written modules in the Library , Just call it directly , Here is the word frequency in the absolute sense . Put the renderings directly .

But such a square cloud of words seems a little stereotyped , So here we can also analyze the color of word cloud 、 Modify the shape and other aspects . For example, take a group photo between two people as the base map , Here I choose the base map with two friends :

What needs to be noted here is : The word cloud is only displayed in The dark part , So in order to better show the outline of our background map , Need to carry out Cutout Handle , I chose Wake up picture .
The code of word cloud is also very simple , Direct release :
ciyun = ''.join((open(' Text after cleaning .txt', 'r',encoding='UTF-8')).readlines())
pic = imread(' Base map .jpg')
w = wordcloud.WordCloud(width=640,height=480,background_color = 'black',font_path='C:\WINDOWS\FONTS\MSYH.TTC',max_words=200,mask=pic,contour_color='black')#font_path This parameter must have , Follow the path and choose any font that comes with your computer , otherwise wordcloud The default is English , And the font path is best entered manually , Otherwise, an error will be reported ,mask Is the base map we chose
w.generate(ciyun)# The text here must be the result of word segmentation , There must be spaces or punctuation
plt.subplots(figsize=(10,8),dpi=1200)# Adjust the resolution of the word cloud , Make the picture clearer
plt.imshow(w)
plt.axis("off")# Don't use the axis
plt.show()Then let's take a look at the renderings :

3.2 LDA Topic probability model
Word cloud is just to show us some keywords , But the specific topic of our chat cannot be explored . So here's another one LDA Thematic analysis , And can combine R Language for visualization , It can also be saved as a web page and sent to each other .
because LDA In essence, it is an unsupervised clustering algorithm based on probability model , So there is no label to train its classification , We need to set it in advance topics The number of . similar k-means Of k The mean value is determined , The general evaluation indicators are confusion and consistency . However, the academic circles have mixed comments on these indicators , Even gensim The authors of the library deny themselves . therefore , It is also a good choice to determine according to the actual clustering effect . Here I choose at random 8 A simple demonstration of three topics , The code is relatively long, so I won't write it here , If necessary, you can leave a comment in your email ~. Put the renderings directly . I saved it directly for html, It can be opened directly and can touch different themes for dynamic display .


3.3 Emotional analysis based on machine learning
The above analysis is qualitative , And if you want to pay attention to whether this sentence you say is positive or negative , Quantitative analysis is needed , Emotion analysis is essentially the classification of texts , So we need to mark it for further training , What I choose here is based on Naive Bayes SNOWNLP demonstrate , This library is very simple , Also very initial , It's definitely not good for doing papers , But as usual, you can still play ~ First , Its participle is compared with jieba The effect of word segmentation is not good , We can SnowNLP Modify the source code of , And you can use your own training model , For details, please refer to the following two blogs .
https://blog.csdn.net/weixin_42007766/article/details/89824318?utm_source=app&app_version=5.0.1&code=app_1562916241&uLinkId=usr1mkqgl919blen https://blog.csdn.net/weixin_42007766/article/details/89824318?utm_source=app&app_version=5.0.1&code=app_1562916241&uLinkId=usr1mkqgl919blensnownlp: Custom training samples and model saving _AI Data factory -CSDN Blog _snownlp Training models This paper introduces snownlp Package's emotional analysis model training 、 Save and how to use your training model , From the file structure 、 The source code settings are described . According to this method , You can play easily snownlp Emotional analysis of .
https://blog.csdn.net/weixin_42007766/article/details/89824318?utm_source=app&app_version=5.0.1&code=app_1562916241&uLinkId=usr1mkqgl919blensnownlp: Custom training samples and model saving _AI Data factory -CSDN Blog _snownlp Training models This paper introduces snownlp Package's emotional analysis model training 、 Save and how to use your training model , From the file structure 、 The source code settings are described . According to this method , You can play easily snownlp Emotional analysis of .https://blog.csdn.net/oYeZhou/article/details/82868683?utm_source=app&app_version=5.0.1&code=app_1562916241&uLinkId=usr1mkqgl919blen I also put code and renderings directly here :
line = open(" Text after cleaning .txt","r", encoding='utf8').readlines()
sentimentslist = []
for i in line:
s = SnowNLP(i)
print(s.sentiments)
sentimentslist.append(s.sentiments)
# The interval is converted to [-0.5, 0.5]
result = []
i = 0
while i<len(sentimentslist):
result.append(sentimentslist[i]-0.5)
i = i + 1
# Visual drawing
plt.plot(np.arange(0,2228,1),result, 'r-')
plt.xlabel('the number of wechat')
plt.ylabel('Sentiments')
plt.title('Sentiments of XHB and YYX since 2020.5')
plt.show()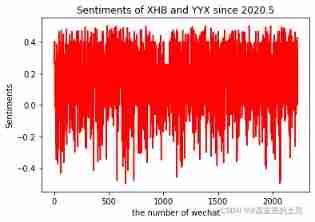
From the above emotional analysis, we can see that the overall fluctuation is relatively large ,0 The above are positive emotions ,0 The following are negative emotions , It can reflect whether two people usually talk in a sunny way, haha , Whether the feelings are harmonious , Of course , I don't have my own training model here for convenience , It uses its own model , So it may not be very accurate , We usually talk in harmony hahaha
3.4 Other deep learning applications
In addition to these , Further exploration is also possible , Such as word2vec semantic similarity , Enter someone's name , See if you have any rival in love, haha , You can also do some fine-grained emotional analysis , See how many you have “ Play ”~.
I have also been learning deep learning to recognize fine-grained emotions , A record will be made later ~
That's all ~ If it helps you , Remember to point a concern hahaha ~~~
边栏推荐
- Sitge joined the opengauss open source community to jointly promote the ecological development of the database industry
- Li Kou ----- the maximum profit of operating Ferris wheel
- 力扣------经营摩天轮的最大利润
- Making global exception handling classes with aspect
- Using webassembly to operate excel on the browser side
- 【案例】定位的运用-淘宝轮播图
- Five layer network protocol
- R language [data management]
- vant 源码解析之 utils/index.ts 工具函数
- @Validated基础参数校验、分组参数验证和嵌套参数验证
猜你喜欢

How to send samples when applying for BS 476-7 display? Is it the same as the display??
Clion configures Visual Studio (MSVC) and JOM multi-core compilation

Zhang Lijun: penetrating uncertainty depends on four "invariants"
使用Aspect制作全局异常处理类
KingbaseES V8R3集群维护案例之---在线添加备库管理节点

EN 438-7 laminated sheet products for building covering decoration - CE certification
Golang(1)|从环境准备到快速上手
Learning robots have no way to start? Let me show you the current hot research directions of robots
递归查询多级菜单数据
ArcGIS栅格重采样方法介绍
随机推荐
Pytorch实战——MNIST数据集手写数字识别
R language [data management]
终端安全能力验证环境搭建和渗透测试记录
递归查询多级菜单数据
The primary key is set after the table is created, but auto increment is not set
Test of incombustibility of cement adhesives BS 476-4
Hdu2377bus pass (build more complex diagram +spfa)
Viewrootimpl and windowmanagerservice notes
面试官:并发编程实战会吗?(线程控制操作详解)
驱动壳美国测试UL 2043 符合要求有哪些?
Simple interest mode - evil Chinese style
Why can't Chinese software companies produce products? Abandon the Internet after 00; Open source high-performance API gateway component of station B | weekly email exclusive to VIP members of Menon w
Arcgis\qgis no plug-in loading (no offset) mapbox HD image map
Opérations de lecture et d'écriture pour easyexcel
100 cases of shell programming
Summary of data analysis steps
Aitm2-0002 12s or 60s vertical combustion test
EN 438-7建筑覆盖物装饰用层压板材产品—CE认证
Add ICO icon to clion MinGW compiled EXE file
【案例】元素的显示与隐藏的运用--元素遮罩