当前位置:网站首页>MySQL deep paging optimization with tens of millions of data, and online failure is rejected!
MySQL deep paging optimization with tens of millions of data, and online failure is rejected!
2022-07-05 21:03:00 【Heapdump performance community】
During the process of optimizing the project code, a ten million level data deep paging problem was found , The reason is that
There is a consumable in the warehouse MCS_PROD surface , By synchronizing the multi-dimensional data in the external data , Assembled in the system as a single consumable product , Finally sync to ES Search engine
MySQL Sync ES The process is as follows :
1、 Trigger synchronization in the form of scheduled tasks , For example, the time and frequency of half a day or a day
2、 The form of synchronization is incremental synchronization , According to the mechanism of update time , For example, the first synchronous query >= 1970-01-01 00:00:00.0
3、 Record the maximum update time for storage , This is the condition for the next update synchronization
4、 Get data in pagination , The current number of pages plus one , Cycle to the last page
Here the problem arises ,MySQL Query page OFFSET The deeper , The worse performance , Preliminary estimate online MCS_PROD Record in the table 1000w about
If per page 10 strip ,OFFSET Values can drag down query performance , Then form a " Performance abyss "
Synchronization class code has two optimization methods for this problem : Use cursor 、 The flow scheme is optimized
Optimize deep paging performance , The article revolves around this topic
The article list is as follows :
1、 Software and hardware description
2、 Reunderstanding MySQL Pagination
3、 Deep paging optimization
4、 Sub query optimization
5、 Delayed correlation
6、 Bookmark records
7、ORDER BY crater , Tread carefully
8、ORDER BY Examples of index failure
9、 afterword
Text
1、 Software and hardware description
MySQL VERSION
mysql> select version();+-----------+| version() |+-----------+| 5.7.30 |+-----------+1 row in set (0.01 sec)
Table structure description
Learn from the company table structure , Field 、 The length and name have been deleted
mysql> DESC MCS_PROD;+-----------------------+--------------+------+-----+---------+----------------+| Field | Type | Null | Key | Default | Extra |+-----------------------+--------------+------+-----+---------+----------------+| MCS_PROD_ID | int(11) | NO | PRI | NULL | auto_increment || MCS_CODE | varchar(100) | YES | | | || MCS_NAME | varchar(500) | YES | | | || UPDT_TIME | datetime | NO | MUL | NULL | |+-----------------------+--------------+------+-----+---------+----------------+4 rows in set (0.01 sec)
Through the test, the students helped build 500w Left and right data volume
mysql> SELECT COUNT(*) FROM MCS_PROD;+----------+| count(*) |+----------+| 5100000 |+----------+1 row in set (1.43 sec)
SQL The statement is as follows
Because the function needs to meet Incremental pull , Therefore, there will be conditional query of data update time , And related Query sequence ( There are pits here. )
SELECT MCS_PROD_ID, MCS_CODE, MCS_NAME, UPDT_TIMEFROM MCS_PRODWHERE UPDT_TIME >= '1970-01-01 00:00:00.0' ORDER BY UPDT_TIMELIMIT xx, xx
Reunderstanding MySQL Pagination
LIMIT Clauses can be used to enforce SELECT Statement returns the specified number of records .LIMIT Receive one or two digital parameters , Argument must be an integer constant
If two parameters are given , The first parameter specifies the offset of the first return record line , The second parameter specifies the maximum number of record rows returned
A simple example , Under the analysis of SQL The query process , Understand why deep paging performance is poor
mysql> SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE (UPDT_TIME >= '1970-01-01 00:00:00.0') ORDER BY UPDT_TIME LIMIT 100000, 1;+-------------+-------------------------+------------------+---------------------+| MCS_PROD_ID | MCS_CODE | MCS_NAME | UPDT_TIME |+-------------+-------------------------+------------------+---------------------+| 181789 | XA601709733186213015031 | ruler 、 Radius LC-DCP Bone plate | 2020-10-19 16:22:19 |+-------------+-------------------------+------------------+---------------------+1 row in set (3.66 sec)mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE (UPDT_TIME >= '1970-01-01 00:00:00.0') ORDER BY UPDT_TIME LIMIT 100000, 1;+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+| 1 | SIMPLE | MCS_PROD | NULL | range | MCS_PROD_1 | MCS_PROD_1 | 5 | NULL | 2296653 | 100.00 | Using index condition |+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+1 row in set, 1 warning (0.01 sec)
Briefly explain the above SQL Execution process :
1、 First, query the table MCS_PROD, To filter UPDT_TIME Conditions , Query the display column ( Involving back table operation ) Sort and LIMIT
2、LIMIT 100000, 1 It means to scan the 100001 That's ok , Then throw it away before 100000 That's ok
MySQL It took A lot of random I/O On the data of back table query cluster index , And this 100000 Sub random I/O The query data will not appear in the result set
If the system concurrency is a little higher , Each query scan exceeds 100000 That's ok , The performance must be worrying , in addition LIMIT Pagination OFFSET Deeper , The worse performance ( Emphasize many times )
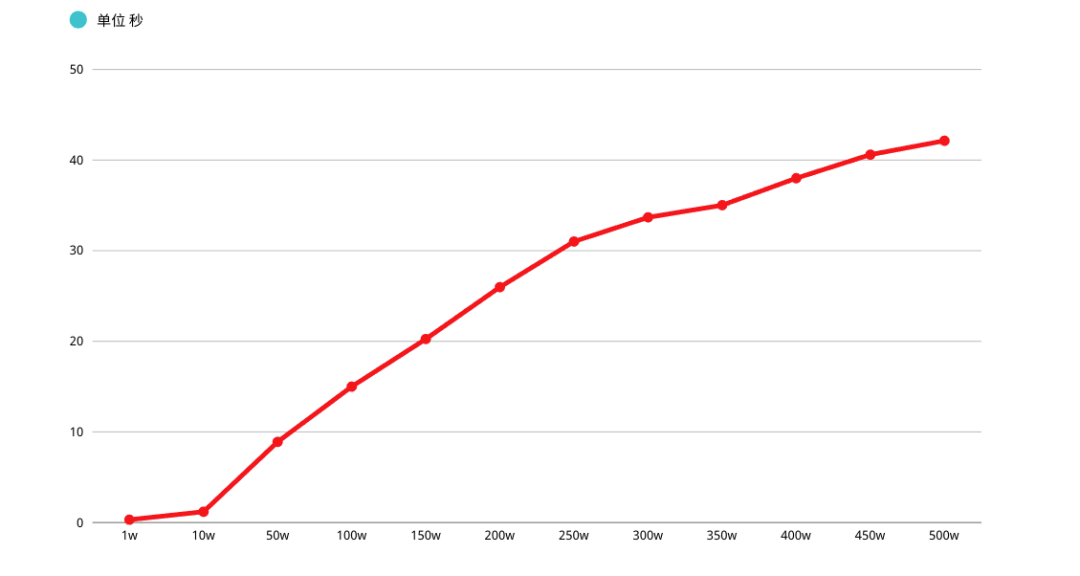
Deep paging optimization
About MySQL There are three common strategies for deep paging optimization :
1、 Sub query optimization
2、 Delayed correlation
3、 Bookmark records
The above three points can greatly improve the query efficiency , The core idea is to let MySQL Scan as few pages as possible , After obtaining the records to be accessed, return to the columns required by the original table query according to the associated columns
Sub query optimization
The sub query deep paging optimization statement is as follows :
mysql> SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE MCS_PROD_ID >= ( SELECT m1.MCS_PROD_ID FROM MCS_PROD m1 WHERE m1.UPDT_TIME >= '1970-01-01 00:00:00.0' ORDER BY m1.UPDT_TIME LIMIT 3000000, 1) LIMIT 1;+-------------+-------------------------+------------------------+| MCS_PROD_ID | MCS_CODE | MCS_NAME |+-------------+-------------------------+------------------------+| 3021401 | XA892010009391491861476 | Metal anatomical plate T Type plate A |+-------------+-------------------------+------------------------+1 row in set (0.76 sec)mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE MCS_PROD_ID >= ( SELECT m1.MCS_PROD_ID FROM MCS_PROD m1 WHERE m1.UPDT_TIME >= '1970-01-01 00:00:00.0' ORDER BY m1.UPDT_TIME LIMIT 3000000, 1) LIMIT 1;+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+--------------------------+| 1 | PRIMARY | MCS_PROD | NULL | range | PRIMARY | PRIMARY | 4 | NULL | 2296653 | 100.00 | Using where || 2 | SUBQUERY | m1 | NULL | range | MCS_PROD_1 | MCS_PROD_1 | 5 | NULL | 2296653 | 100.00 | Using where; Using index |+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+--------------------------+2 rows in set, 1 warning (0.77 sec)
According to the implementation plan , Subquery table m1 The query uses the index . First, in the Get the primary key of the clustered index on the index ID The operation of returning to the table is omitted , Then the second query is directly based on the first query ID Check later 10 Just one
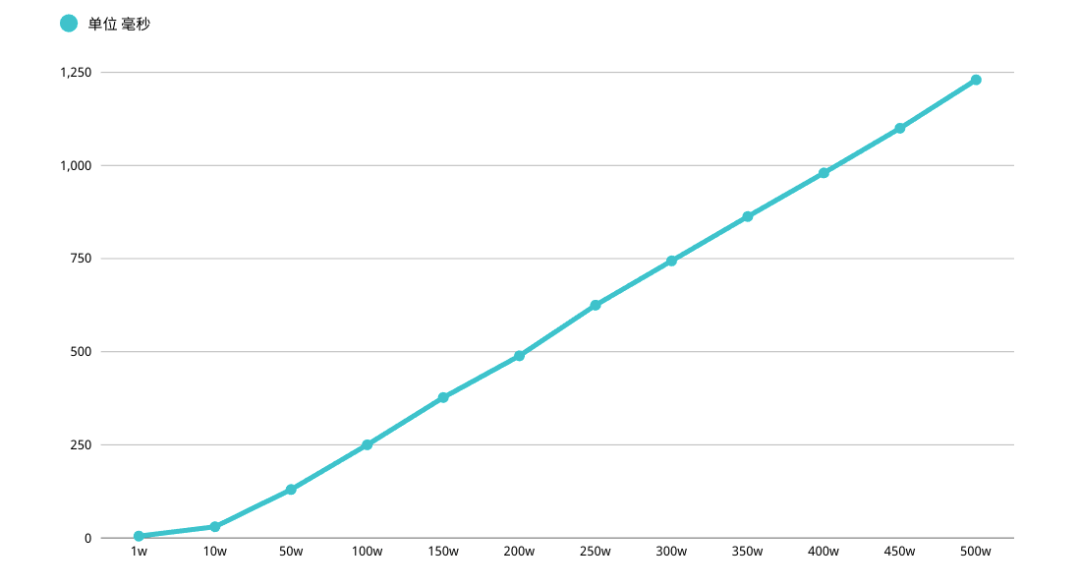
Delayed correlation
" Delayed correlation " The deep paging optimization statement is as follows :
mysql> SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD INNER JOIN (SELECT m1.MCS_PROD_ID FROM MCS_PROD m1 WHERE m1.UPDT_TIME >= '1970-01-01 00:00:00.0' ORDER BY m1.UPDT_TIME LIMIT 3000000, 1) AS MCS_PROD2 USING(MCS_PROD_ID);+-------------+-------------------------+------------------------+| MCS_PROD_ID | MCS_CODE | MCS_NAME |+-------------+-------------------------+------------------------+| 3021401 | XA892010009391491861476 | Metal anatomical plate T Type plate A |+-------------+-------------------------+------------------------+1 row in set (0.75 sec)mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD INNER JOIN (SELECT m1.MCS_PROD_ID FROM MCS_PROD m1 WHERE m1.UPDT_TIME >= '1970-01-01 00:00:00.0' ORDER BY m1.UPDT_TIME LIMIT 3000000, 1) AS MCS_PROD2 USING(MCS_PROD_ID);+----+-------------+------------+------------+--------+---------------+------------+---------+-----------------------+---------+----------+--------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+------------+------------+--------+---------------+------------+---------+-----------------------+---------+----------+--------------------------+| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 2296653 | 100.00 | NULL || 1 | PRIMARY | MCS_PROD | NULL | eq_ref | PRIMARY | PRIMARY | 4 | MCS_PROD2.MCS_PROD_ID | 1 | 100.00 | NULL || 2 | DERIVED | m1 | NULL | range | MCS_PROD_1 | MCS_PROD_1 | 5 | NULL | 2296653 | 100.00 | Using where; Using index |+----+-------------+------------+------------+--------+---------------+------------+---------+-----------------------+---------+----------+--------------------------+3 rows in set, 1 warning (0.00 sec)
The idea and performance are consistent with sub query optimization , It's just that JOIN The form of execution
Bookmark records
About LIMIT Deep paging problem , The core is OFFSET value , It will Lead to MySQL Scan a large number of unnecessary record lines and discard
We can use bookmarks first Record the location where the data was last retrieved , Next time you can start scanning directly from this position , This can Avoid using OFFEST
Suppose you need to query 3000000 The... After the row of data 1 Bar record , The query can be written like this
mysql> SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE MCS_PROD_ID < 3000000 ORDER BY UPDT_TIME LIMIT 1;+-------------+-------------------------+---------------------------------+| MCS_PROD_ID | MCS_CODE | MCS_NAME |+-------------+-------------------------+---------------------------------+| 127 | XA683240878449276581799 | Proximal femur -1 Threaded hole locking plate ( Pure titanium )YJBL01 |+-------------+-------------------------+---------------------------------+1 row in set (0.00 sec)mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME FROM MCS_PROD WHERE MCS_PROD_ID < 3000000 ORDER BY UPDT_TIME LIMIT 1;+----+-------------+----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+| 1 | SIMPLE | MCS_PROD | NULL | index | PRIMARY | MCS_PROD_1 | 5 | NULL | 2 | 50.00 | Using where |+----+-------------+----------+------------+-------+---------------+------------+---------+------+------+----------+-------------+1 row in set, 1 warning (0.00 sec)
The benefits are obvious , Query speed is super fast , The performance will be stable in milliseconds , Other rolling methods shall be considered in terms of performance
However, this method has great limitations , You need a field similar to continuous self increment , And the concept of continuity that the business can contain , As the case may be
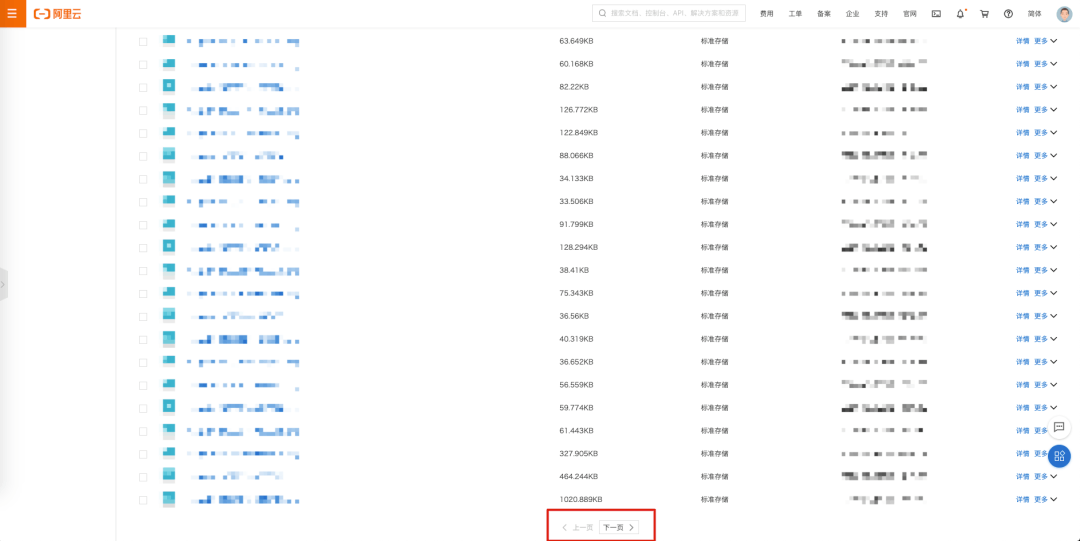
The picture above shows Alibaba cloud OSS Bucket List of files in the bucket , Dare to guess whether it can be completed in the form of bookmarking records
ORDER BY crater , Tread carefully
The following remarks may break your understanding of order by all happy YY
Let's start with the conclusion , When LIMIT OFFSET When too deep , Can make ORDER BY The normal index is invalid ( union 、 The only indexes not tested )
mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME,UPDT_TIME FROM MCS_PROD WHERE (UPDT_TIME >= '1970-01-01 00:00:00.0') ORDER BY UPDT_TIME LIMIT 100000, 1;+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+| 1 | SIMPLE | MCS_PROD | NULL | range | MCS_PROD_1 | MCS_PROD_1 | 5 | NULL | 2296653 | 100.00 | Using index condition |+----+-------------+----------+------------+-------+---------------+------------+---------+------+---------+----------+-----------------------+1 row in set, 1 warning (0.00 sec)
Let's start with this ORDER BY Execution process :
1、 initialization SORT_BUFFER, Put in MCS_PROD_ID,MCS_CODE,MCS_NAME,UPDT_TIME Four fields
2、 From the index UPDT_TIME Find the primary key that meets the conditions ID, Return to the table to query four field values SORT_BUFFER
3、 Continue the query from the index to meet UPDT_TIME Condition record , Continue with step 2
4、 Yes SORT_BUFFER According to the data in UPDT_TIME Sort
5、 After the sorting is successful, the matching LIMIT Conditional records are returned to the client
according to UPDT_TIME Sorting may be done in memory , You may also need to use external sorting , Depends on the memory and parameters required for sorting SORT_BUFFER_SIZE
SORT_BUFFER_SIZE yes MySQL Memory opened up for sorting . If the amount of sorted data is less than SORT_BUFFER_SIZE, Sorting will be done in memory . If the amount of data is too large , There's no memory , Will use disk temporary file sorting
ORDER BY Examples of index failure
OFFSET 100000 when , adopt key Extra hear , No disk temporary file sorting , This is the time to put OFFSET To adjust to 500000
The cool night is a river for you , Turn into spring mud to take care of you ... A cool song for writing this SQL Classmate , Found out Using filesort
mysql> EXPLAIN SELECT MCS_PROD_ID,MCS_CODE,MCS_NAME,UPDT_TIME FROM MCS_PROD WHERE (UPDT_TIME >= '1970-01-01 00:00:00.0') ORDER BY UPDT_TIME LIMIT 500000, 1;+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+| 1 | SIMPLE | MCS_PROD | NULL | ALL | MCS_PROD_1 | NULL | NULL | NULL | 4593306 | 50.00 | Using where; Using filesort |+----+-------------+----------+------------+------+---------------+------+---------+------+---------+----------+-----------------------------+1 row in set, 1 warning (0.00 sec)
Using filesort Indicates that it is outside the index , Additional external sorting actions are required , Performance will be seriously affected
So we should Combine the corresponding business logic to avoid routine LIMIT OFFSET, use # Deep paging optimization Modify the corresponding business section
afterword
Finally, I need to make a statement ,MySQL It is not suitable for single table large data business
because MySQL When applied to enterprise projects , Querying against library tables is not a simple condition , There may be more complex federated queries , Or there are frequent new or update operations when there is a large amount of data , Maintain indexes or data ACID There must be performance sacrifice in characteristics
If the data growth of the database table can be expected at the beginning of the design , We should conceive a reasonable reconstruction and optimization method , such as ES Cooperate with query 、 Sub database and sub table 、TiDB And other solutions
You can add authors VX,( The official account is ) Communicate and exchange technology together . In addition, we can also discuss the love and hatred of King Canyon , Wen Neng hangs up and scolds his teammates , Wu Neng goes over the tower to send his head , Horizontal endorsement of both literature and martial arts . One such teammate is needed to win ️

Reference material :
《 High performance MySQL The third edition 》
《MySQL actual combat 45 speak 》
边栏推荐
猜你喜欢
2. < tag hash table, string> supplement: Sword finger offer 50 The first character DBC that appears only once
leetcode:1139. 最大的以 1 为边界的正方形
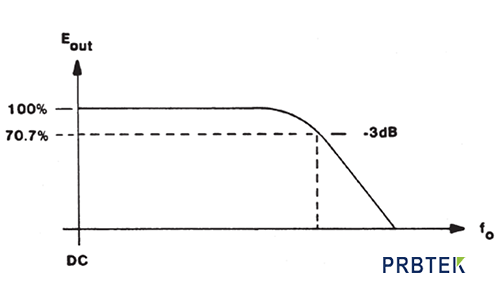
示波器探头对测量带宽的影响
The transformation based on vertx web sstore redis to realize the distributed session of vertx HTTP application
MySQL 千万数据量深分页优化, 拒绝线上故障!

How to send samples when applying for BS 476-7 display? Is it the same as the display??

教你自己训练的pytorch模型转caffe(三)
Write an interface based on flask
【案例】元素的显示与隐藏的运用--元素遮罩

Duchefa cytokinin dihydrozeatin (DHZ) instructions
随机推荐
Open source SPL eliminates tens of thousands of database intermediate tables
Duchefa cytokinin dihydrozeatin (DHZ) instructions
判断横竖屏的最佳实现
概率论机器学习的先验知识(上)
systemd-resolved 开启 debug 日志
SYSTEMd resolved enable debug log
示波器探头对测量带宽的影响
Test of incombustibility of cement adhesives BS 476-4
[case] Application of positioning - Taobao rotation map
vant 源码解析 之深层 合并对象 深拷贝
学习机器人无从下手?带你体会当下机器人热门研究方向有哪些
Monorepo management methodology and dependency security
基于vertx-web-sstore-redis的改造实现vertx http应用的分布式session
Clion configures Visual Studio (MSVC) and JOM multi-core compilation
AITM2-0002 12s或60s垂直燃烧试验
ArcGIS\QGIS无插件加载(无偏移)MapBox高清影像图
CLion配置visual studio(msvc)和JOM多核编译
MySQL ifnull usage function
基于AVFoundation实现视频录制的两种方式
请查收.NET MAUI 的最新学习资源