当前位置:网站首页>Teach yourself to train pytorch model to Caffe (I)
Teach yourself to train pytorch model to Caffe (I)
2022-07-05 21:09:00 【FeboReigns】
First of all, there must be a pytorch Model , I choose googelnet For example ,
We can use pytorch Provided imagenet Pre training model of .
import torchvision
googlenet = torchvision.models.googlenet(pretrained=True)
input = torch.randn(2,3,224,224)
out = googlenet(input)
# The console will download the pre training model , Find the downloaded model , Then use it directly If you want to train yourself , And then look down , Otherwise, the reading is over .
I use the framework provided by Luo Hao , Trained a cat and dog classification , The following is Luo Hao's framework github, as well as B Station teaching video
https://github.com/michuanhaohao/deep-person-reidhttps://www.bilibili.com/video/BV1Pg4y1q7sNThe first step is to prepare cat and dog data sets
link :https://pan.baidu.com/s/1HBewIgKsFD8hh3ICOnnTwA
Extraction code :ktab
By the way, download my source code directly .
link : https://pan.baidu.com/s/1l6mrSpbfNSOsbmw2FT0zYw
Extraction code : r799
come from https://blog.csdn.net/qq_43391414/article/details/118462136Then it is to change teacher Luo Hao's framework
The first step is to write first googlenet The Internet , stay models Folder new GoogLeNet.py
from __future__ import absolute_import
import torch
from torch import nn
from torch.nn import functional as F
import torchvision
__all__ = ['GoogLeNet']
class GoogLeNet(nn.Module):
def __init__(self, num_classes=2, loss={'xent'}, **kwargs):
super(GoogLeNet, self).__init__()
self.loss = loss
googlenet = torchvision.models.googlenet(pretrained=True)
# self.base = googlenet
self.base = nn.Sequential(*list(googlenet.children())[:-2])
self.classifier = nn.Linear(1024, num_classes)
self.feat_dim = 1024 # feature dimension
def forward(self, x):
x = self.base(x)
# x = F.avg_pool2d(x, x.size()[2:])
f = x.view(x.size(0), -1)
y = self.classifier(f)
return y
if not self.training:
return f
y = self.classifier(f)
if self.loss == {'xent'}:
return y
elif self.loss == {'xent', 'htri'}:
return y, f
elif self.loss == {'cent'}:
return y, f
elif self.loss == {'ring'}:
return y, f
else:
raise KeyError("Unsupported loss: {}".format(self.loss))
if __name__ == "__main__":
input = torch.randn(2,3,224,224)
model = GoogLeNet()
out = model(input)
aaa= 100stay models/__init__.py Modify the configuration
Top with
from .GoogLeNet import *
factory add
'GoogLeNet':GoogLeNet,The second step is to modify the data set related code
stay data_manage.py newly added class
class CatDog(object):
dataset_dir = 'dog_cat_dataset'
def __init__(self, root='E:\\workspace\\dataset', **kwargs):
self.dataset_dir = osp.join(root, self.dataset_dir)
self.train_dir = osp.join(self.dataset_dir, 'train')
self.test_dir = osp.join(self.dataset_dir, 'test')
self.class_num = 2
self._check_before_run()
train, num_train_imgs = self._process_dir(self.train_dir)
test, num_test_imgs = self._process_dir(self.test_dir)
num_total_imgs = num_train_imgs + num_test_imgs
print("=> Dog Cat dataset loaded")
print("Dataset statistics:")
print(" ------------------------------")
print(" subset | # images")
print(" ------------------------------")
print(" train | {:8d}".format(num_train_imgs))
print(" test | {:8d}".format(num_test_imgs))
print(" ------------------------------")
print(" total | {:8d}".format(num_total_imgs))
print(" ------------------------------")
self.train = train
self.test = test
def _check_before_run(self):
"""Check if all files are available before going deeper"""
if not osp.exists(self.dataset_dir):
raise RuntimeError("'{}' is not available".format(self.dataset_dir))
if not osp.exists(self.train_dir):
raise RuntimeError("'{}' is not available".format(self.train_dir))
if not osp.exists(self.test_dir):
raise RuntimeError("'{}' is not available".format(self.test_dir))
def _process_dir(self, dir_path):
img_paths = glob.glob(osp.join(dir_path, '*.jpg'))
dataset = []
for img_path in img_paths:
img_path = img_path.replace('\\', '/')
class_name = img_path.split(".")[0].split("/")[-1]
if not class_name in ["dog","cat"]: continue
if class_name == "dog":
class_index = 0
elif class_name == "cat":
class_index = 1
dataset.append((img_path, class_index))
num_imgs = len(dataset)
return dataset, num_imgsRevise it factory, New entry
__img_factory = {
'market1501': Market1501,
'cuhk03': CUHK03,
'dukemtmcreid': DukeMTMCreID,
'msmt17': MSMT17,
'cat_dog':CatDog,
} Some explanations :
root yes dataset_dir The path of , Above is the folder of the dataset , Look at my file structure , Just divide the training set and the test set randomly , If you use my code , The name of the folder is the same as mine .
stay dataset_loader.py New code
class DogCatDataset_test(Dataset):
"""Image Person ReID Dataset"""
def __init__(self, dataset, transform=None):
self.dataset = dataset
self.transform = transform
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
img_path, class_index = self.dataset[index]
img = read_image(img_path)
if self.transform is not None:
img = self.transform(img)
return img_path.split("/")[-1],img, class_index
class DogCatDataset(Dataset):
"""Image Person ReID Dataset"""
def __init__(self, dataset, transform=None):
self.dataset = dataset
self.transform = transform
def __len__(self):
return len(self.dataset)
def __getitem__(self, index):
img_path, class_index = self.dataset[index]
img = read_image(img_path)
if self.transform is not None:
img = self.transform(img)
return img, class_indexTraining and testing scripts :

from __future__ import print_function, absolute_import
import os
import sys
import time
import datetime
import argparse
import os.path as osp
import numpy as np
import torch
import torch.nn as nn
import torch.backends.cudnn as cudnn
from torch.utils.data import DataLoader
from torch.optim import lr_scheduler
import data_manager
from dataset_loader import ImageDataset, DogCatDataset, DogCatDataset_test
import transforms as T
import models
from losses import CrossEntropyLabelSmooth, DeepSupervision, CrossEntropy_loss
from utils import AverageMeter, Logger, save_checkpoint
from eval_metrics import evaluate
from optimizers import init_optim
parser = argparse.ArgumentParser(description='Train image model with cross entropy loss')
# Datasets
parser.add_argument('--root', type=str, default='E:\\workspace\\dataset', help="root path to data directory")
parser.add_argument('-d', '--dataset', type=str, default='cat_dog',
choices=data_manager.get_names())
parser.add_argument('-j', '--workers', default=4, type=int,
help="number of data loading workers (default: 4)")
parser.add_argument('--height', type=int, default=224,
help="height of an image (default: 256)")
parser.add_argument('--width', type=int, default=224,
help="width of an image (default: 128)")
parser.add_argument('--split-id', type=int, default=0, help="split index")
# CUHK03-specific setting
parser.add_argument('--cuhk03-labeled', action='store_true',
help="whether to use labeled images, if false, detected images are used (default: False)")
parser.add_argument('--cuhk03-classic-split', action='store_true',
help="whether to use classic split by Li et al. CVPR'14 (default: False)")
parser.add_argument('--use-metric-cuhk03', action='store_true',
help="whether to use cuhk03-metric (default: False)")
# Optimization options
parser.add_argument('--optim', type=str, default='adam', help="optimization algorithm (see optimizers.py)")
parser.add_argument('--max-epoch', default=60, type=int,
help="maximum epochs to run")
parser.add_argument('--start-epoch', default=0, type=int,
help="manual epoch number (useful on restarts)")
parser.add_argument('--train-batch', default=128, type=int,
help="train batch size")
parser.add_argument('--test-batch', default=1, type=int, help="test batch size")
parser.add_argument('--lr', '--learning-rate', default=0.0003, type=float,
help="initial learning rate")
parser.add_argument('--stepsize', default=20, type=int,
help="stepsize to decay learning rate (>0 means this is enabled)")
parser.add_argument('--gamma', default=0.1, type=float,
help="learning rate decay")
parser.add_argument('--weight-decay', default=5e-04, type=float,
help="weight decay (default: 5e-04)")
# Architecture
parser.add_argument('-a', '--arch', type=str,
default='GoogLeNet',
# default='resnet50',
choices=models.get_names())
# Miscs
parser.add_argument('--print-freq', type=int, default=10, help="print frequency")
parser.add_argument('--seed', type=int, default=1, help="manual seed")
parser.add_argument('--resume', type=str,
# default='E:/workspace/classify/checkpoint_ep60.pth',
metavar='PATH')
parser.add_argument('--evaluate',
# default=1,
action='store_true', help="evaluation only")
parser.add_argument('--eval-step', type=int, default=-1,
help="run evaluation for every N epochs (set to -1 to test after training)")
parser.add_argument('--start-eval', type=int, default=0, help="start to evaluate after specific epoch")
parser.add_argument('--save-dir', type=str, default='log_resnet_dog')
parser.add_argument('--use-cpu', action='store_true', help="use cpu")
parser.add_argument('--gpu-devices', default='0', type=str, help='gpu device ids for CUDA_VISIBLE_DEVICES')
args = parser.parse_args()
def main():
torch.manual_seed(args.seed)
os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu_devices
use_gpu = torch.cuda.is_available()
if args.use_cpu: use_gpu = False
if not args.evaluate:
sys.stdout = Logger(osp.join(args.save_dir, 'log_train.txt'))
else:
sys.stdout = Logger(osp.join(args.save_dir, 'log_test.txt'))
print("==========\nArgs:{}\n==========".format(args))
if use_gpu:
print("Currently using GPU {}".format(args.gpu_devices))
cudnn.benchmark = True
torch.cuda.manual_seed_all(args.seed)
else:
print("Currently using CPU (GPU is highly recommended)")
print("Initializing dataset {}".format(args.dataset))
dataset = data_manager.init_img_dataset(
root=args.root, name=args.dataset, split_id=args.split_id,
cuhk03_labeled=args.cuhk03_labeled, cuhk03_classic_split=args.cuhk03_classic_split,
)
transform_train = T.Compose([
T.Random2DTranslation(args.height, args.width),
T.RandomHorizontalFlip(),
T.ToTensor(),
# T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
transform_test = T.Compose([
T.Resize((args.height, args.width)),
T.ToTensor(),
# T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
pin_memory = True if use_gpu else False
trainloader = DataLoader(
DogCatDataset(dataset.train, transform=transform_train),
batch_size=args.train_batch, shuffle=True, num_workers=args.workers,
pin_memory=pin_memory, drop_last=True,
)
testloader = DataLoader(
DogCatDataset_test(dataset.test, transform=transform_test),
batch_size=args.test_batch, shuffle=False, num_workers=args.workers,
pin_memory=pin_memory, drop_last=False,
)
print("Initializing model: {}".format(args.arch))
model = models.init_model(name=args.arch, num_classes=2, loss={'xent'}, use_gpu=use_gpu)
print("Model size: {:.5f}M".format(sum(p.numel() for p in model.parameters()) / 1000000.0))
# criterion = CrossEntropyLabelSmooth(num_classes=dataset.class_num, use_gpu=use_gpu)
criterion = CrossEntropy_loss(num_classes=dataset.class_num, use_gpu=use_gpu)
optimizer = init_optim(args.optim, model.parameters(), args.lr, args.weight_decay)
if args.stepsize > 0:
scheduler = lr_scheduler.StepLR(optimizer, step_size=args.stepsize, gamma=args.gamma)
start_epoch = args.start_epoch
if args.resume:
print("Loading checkpoint from '{}'".format(args.resume))
checkpoint = torch.load(args.resume,map_location=torch.device('cpu'))
model.load_state_dict(checkpoint)
# start_epoch = checkpoint['epoch']
if use_gpu:
model = nn.DataParallel(model).cuda()
if args.evaluate:
print("Evaluate only")
test(model, testloader, use_gpu)
return
start_time = time.time()
train_time = 0
best_rank1 = -np.inf
best_epoch = 0
print("==> Start training")
for epoch in range(start_epoch, args.max_epoch):
start_train_time = time.time()
train(epoch, model, criterion, optimizer, trainloader, use_gpu)
train_time += round(time.time() - start_train_time)
if args.stepsize > 0: scheduler.step()
if use_gpu:
state_dict = model.module.state_dict()
else:
state_dict = model.state_dict()
save_checkpoint(state_dict, 0, osp.join(args.save_dir, 'checkpoint_ep' + str(epoch + 1) + '.pth'))
# if (epoch + 1) > args.start_eval and args.eval_step > 0 and (epoch + 1) % args.eval_step == 0 or (
# epoch + 1) == args.max_epoch:
# print("==> Test")
# # rank1 = test(model, testloader, use_gpu)
# # is_best = rank1 > best_rank1
# # if is_best:
# # best_rank1 = rank1
# # best_epoch = epoch + 1
#
# if use_gpu:
# state_dict = model.module.state_dict()
# else:
# state_dict = model.state_dict()
#
# save_checkpoint(state_dict, 0, osp.join(args.save_dir, 'checkpoint_ep' + str(epoch + 1) + '.pth.tar'))
elapsed = round(time.time() - start_time)
elapsed = str(datetime.timedelta(seconds=elapsed))
train_time = str(datetime.timedelta(seconds=train_time))
print("Finished. Total elapsed time (h:m:s): {}. Training time (h:m:s): {}.".format(elapsed, train_time))
def train(epoch, model, criterion, optimizer, trainloader, use_gpu):
losses = AverageMeter()
batch_time = AverageMeter()
data_time = AverageMeter()
model.train()
end = time.time()
for batch_idx, (imgs, class_index, ) in enumerate(trainloader):
if use_gpu:
imgs, class_index = imgs.cuda(), class_index.cuda()
# measure data loading time
data_time.update(time.time() - end)
outputs = model(imgs)
if isinstance(outputs, tuple):
loss = DeepSupervision(criterion, outputs, class_index)
else:
loss = criterion(outputs, class_index)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
losses.update(loss.item(), class_index.size(0))
if (batch_idx + 1) % args.print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'.format(
epoch + 1, batch_idx + 1, len(trainloader), batch_time=batch_time,
data_time=data_time, loss=losses))
def test(model, testloader,use_gpu):
batch_time = AverageMeter()
model.eval()
with torch.no_grad():
for batch_idx, (file_name,imgs, class_index) in enumerate(testloader):
if use_gpu: imgs = imgs.cuda()
end = time.time()
result = model(imgs)
batch_time.update(time.time() - end)
print(file_name,result ," true",class_index)
np.save(file_name[0],imgs.numpy())
return 0
if __name__ == '__main__':
main()parser.add_argument('--root', type=str, default='E:\\workspace\\dataset', help="root path to data directory") Change here to your own folder
Get a training result pth
How to test pth Well
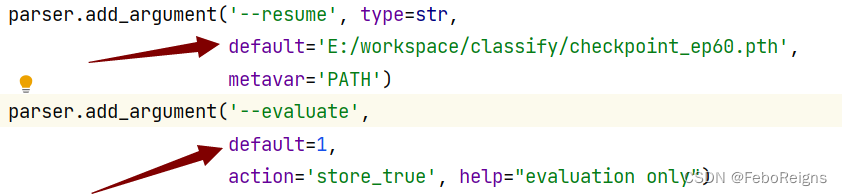
Just change it
Then rerun the script

The file name is in front of it , The following is the result of reasoning score, Feline index yes 1 ( As shown in the last column ), You can see that the data in the following column is larger , Explain the predicted pair
My code address https://gitee.com/feboreigns/classify边栏推荐
- ArcGIS栅格重采样方法介绍
- Sequence alignment
- 学习机器人无从下手?带你体会当下机器人热门研究方向有哪些
- Clion-MinGW编译后的exe文件添加ico图标
- 树莓派4B上ncnn转换出来的模型调用时总是崩溃(Segment Fault)的原因
- leetcode:1139. 最大的以 1 为边界的正方形
- Phpstudy Xiaopi's MySQL Click to start and quickly flash back. It has been solved
- int GetMonth( ) const throw( ); What does throw () mean?
- leetcode:1755. Sum of subsequences closest to the target value
- 研學旅遊實踐教育的開展助力文旅產業發展
猜你喜欢

校招期间 准备面试算法岗位 该怎么做?
EasyExcel的读写操作
EasyExcel的讀寫操作
Golang (1) | from environmental preparation to quick start

MySQL deep paging optimization with tens of millions of data, and online failure is rejected!
Learning robots have no way to start? Let me show you the current hot research directions of robots

研學旅遊實踐教育的開展助力文旅產業發展
学习机器人无从下手?带你体会当下机器人热门研究方向有哪些
Phpstudy Xiaopi's MySQL Click to start and quickly flash back. It has been solved
Clion configures Visual Studio (MSVC) and JOM multi-core compilation
随机推荐
浅聊我和一些编程语言的缘分
获取前一天的js(时间戳转换)
Write an interface based on flask
vant 源码解析 event.ts 事件处理 全局函数 addEventListener详解
Hdu2377bus pass (build more complex diagram +spfa)
XML modeling
EN 438-7 laminated sheet products for building covering decoration - CE certification
Simple getting started example of Web Service
wpf 获取datagrid 中指定行列的DataGridTemplateColumn中的控件
树莓派4B上ncnn转换出来的模型调用时总是崩溃(Segment Fault)的原因
What are the requirements of UL 2043 test for drive housing in the United States?
EasyExcel的讀寫操作
The reason why the ncnn converted model on raspberry pie 4B always crashes when called
学习机器人无从下手?带你体会当下机器人热门研究方向有哪些
【案例】元素的显示与隐藏的运用--元素遮罩
Vant source code parsing event Detailed explanation of TS event processing global function addeventlistener
ts 之 属性的修饰符public、private、protect
Golang (1) | from environmental preparation to quick start
Modifiers of attributes of TS public, private, protect
Clion configures Visual Studio (MSVC) and JOM multi-core compilation