当前位置:网站首页>Yolov5 training custom data set (pycharm ultra detailed version)
Yolov5 training custom data set (pycharm ultra detailed version)
2022-07-05 21:36:00 【MrL_ JJ】
List of articles
Environmental preparation
clone YoLov5 Project code , Warehouse address :https://github.com/ultralytics/yolov5
git Cloning may fail , So click directly on DownLoad Zip download .zip After the file is decompressed , adopt cmd terminal , Switch to requirements.txt route , adopt pip install -r requirements.txt Command to install all the packages that the project depends on .
One 、 Make your own dataset
1. Mark the picture
There are many ways to label your dataset , In this paper LabelImg The tool annotates the image .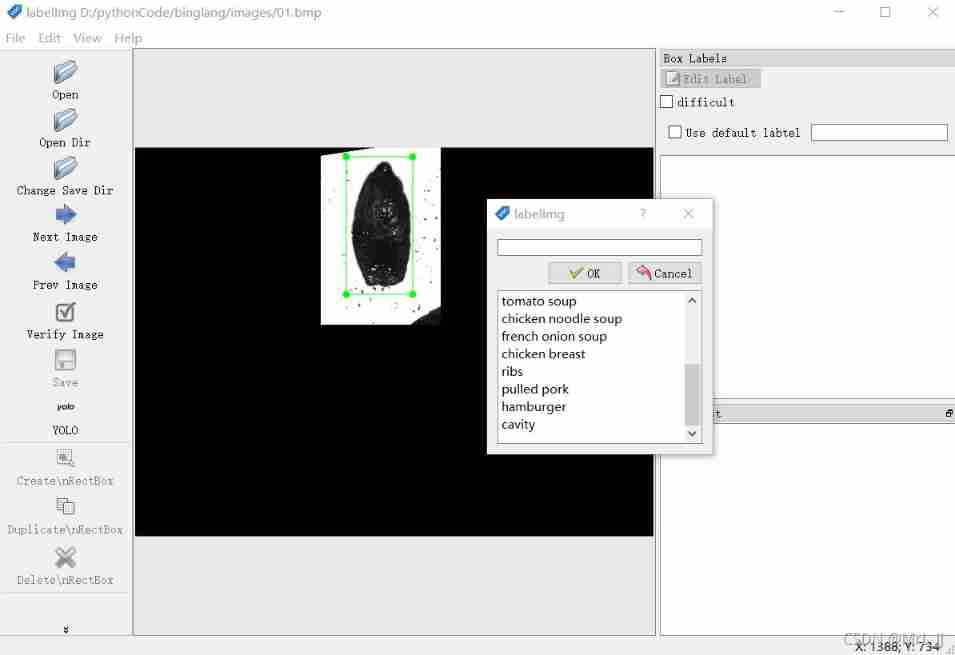
labelImg Download address :https://github.com/tzutalin/labelImg/releases
This article starts by downloading the compressed package and running it directly exe The way , Failure ( Have the opportunity to study again ). Later, I had to install the source code . except python3 Outside the above environment , It also needs to be lxml package , It can be done by pip list Check whether the computer has lxml package , If not, go through pip install lxml Can be installed .
After decompressing the compressed package , open Anaconda Prompt Switch to the decompressed LabelImg Catalog , install pyqt5:
conda install pyqt=5
pyrcc5 -o resources.py resources.qrc
Setup successfully opened labelImg Tools :
python labelImg.py
For detailed usage, please refer to online articles ,labelImg Tools can generate yolo Format , Store all documents in labels In the folder .
Each image corresponds to a txt file , Each action in the file contains information about a target , Include class, x_center, y_center, width, height Format . The content is shown in the figure below :
2. Assign training data sets and test sets
Use scripts to allocate training and test data sets , The code is as follows :
class DivideImages():
def __init__(self,imagePath,outputDir):
self.imageDir = imagePath
self.listPathFile = outputDir+"/imagesPathAll.txt"
self.outputDir = outputDir+"/"
self.makeAllImagesPath(self.imageDir)
self.DivideImagePath()
def makeAllImagesPath(self, ImageDir):
imagesList = os.listdir(ImageDir)
imagesList = [x for x in imagesList if self.IsImage(x)]
id2Name = [(osp.splitext(x)[0], x) for x in imagesList]
res = dict(id2Name)
lines = list(res.values())
with open(self.listPathFile, 'w') as f:
for x in lines:
#y = x.strip() + "\n"
y = self.imageDir + x + "\n"
f.write(y)
def IsImage(self,fileName):
""" whether filename is an image or not """
imgType = ['.bmp', '.jpg', '.jpeg', '.png', '.tif']
basename = osp.basename(fileName)
basenameExt = osp.splitext(basename)[-1]
return (basenameExt in imgType) and (not basename.startswith("."))
def DivideImagePath(self):
pathList = np.asarray(self.readImgPathFromfile(self.listPathFile))
imgSum = len(pathList)
np.random.seed(7)
np.random.shuffle(pathList)
numTest = int(imgSum * 0.15)
numTrain = imgSum - numTest
testList = pathList[:numTest]
trainList = pathList[numTest:]
with open(osp.join(self.outputDir, "test.txt"), 'w') as f:
for x in testList:
y = x.strip() + "\n"
f.write(y)
with open(osp.join(self.outputDir, "train.txt"), 'w') as f:
for x in trainList:
y = x.strip() + "\n"
f.write(y)
def readImgPathFromfile(self,filename):
with open(filename, 'r') as f:
lines = f.readlines()
lines = [x.strip() for x in lines]
return lines
if __name__ == '__main__':
# Parameters 1: Collected image files , Parameters 2: Path to generate training set and test set files
divide = DivideImages("D:/pythonCode/binglang/images","D:/pythonCode/binglang")
According to their actual situation , modify DivideImages Two arguments to the constructor .
Executing the script will generate the following two text files , The path corresponding to each picture is recorded inside .
Two 、 The configuration file
1. Configure the configuration file of the dataset
stay YOLOV5 In the catalog data Make a copy under the folder coco.yaml file , Rename to your own name , Modify the path of your dataset file 、 Number of categories and category name .
among ,train and val They are the text document paths of the previously generated training set and the test set ,nc Indicates the number of categories of the target ;names Represents a list of specific categories .
2. Configuration model file
This article chooses yolo5s edition . open yolo5s.yaml file , take nc Change the number of categories to the number of categories you need .
To times , We got labels file ,Images file ,test.py and train Text , Put it together yolov5 Of engineering documents data Folder .
3. Download the weight file
stay YOLOV5 Create one in the directory weigths Folder , And then put data/scripts Under the document download_weights.sh Put it in weights Under the document . Download the file shown below .
3、 ... and 、 Training models
modify YOLOV5 Under the table of contents train.py The parameters of the file :
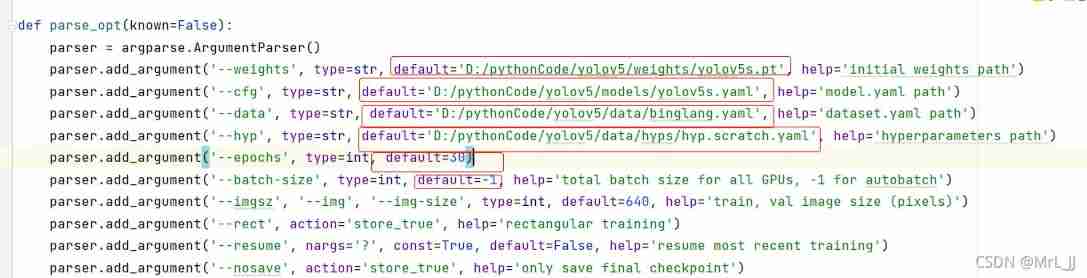
among , ‘–weigths’: Own weight file path .
‘–cfg’: The path of your model .
‘–data’: Before configuring the data set file path .
‘–epochs’: It refers to how many times the whole data set will be iterated during the training process .
‘–batch-size’: How many pictures do you see at a time before you update the weight .
‘–images-size’: Enter the width and height of the picture .
The following is the training process ,pycharm Printout information .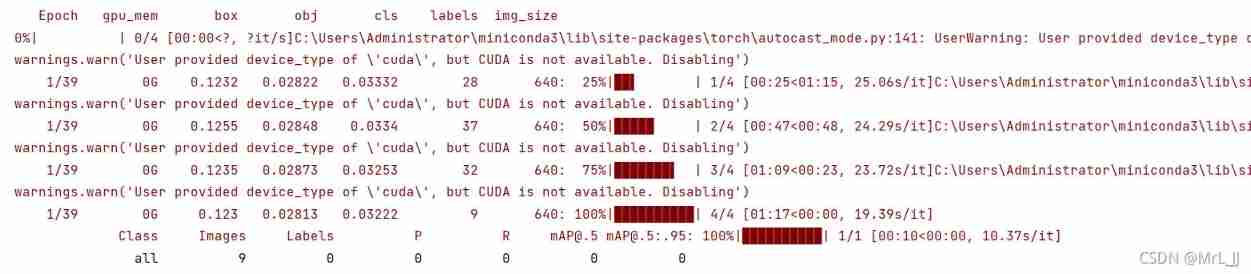
The trained model will be saved in yolov5 In the catalog runs/train/exp9/weights/last.pt and best.pt,
Four 、 The reasoning model
Last , stay YOLOV5 In the catalog detect.py Modify parameters under the file to infer the model :
among ,weights Is the most satisfactory training model ,source Is the folder path of all test images ;
conf-thres Represents the confidence threshold ; After the test, it will be in runs/detect/exp/ Generate pictures and corresponding labels: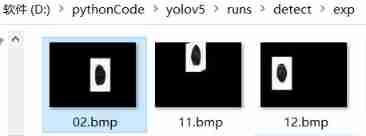

边栏推荐
- MySQL 千万数据量深分页优化, 拒绝线上故障!
- selenium 查找b或p标签的内容
- sql常用语法记录
- [daily training -- Tencent select 50] 89 Gray code (only after seeing the solution of the problem)
- leetcode:1755. Sum of subsequences closest to the target value
- kingbaseES V8R3数据安全案例之---审计记录清除案例
- Add ICO icon to clion MinGW compiled EXE file
- 校招期间 准备面试算法岗位 该怎么做?
- Recursive query of multi-level menu data
- MySQL deep paging optimization with tens of millions of data, and online failure is rejected!
猜你喜欢

怎么利用Tensorflow2进行猫狗分类识别
ArcGIS\QGIS无插件加载(无偏移)MapBox高清影像图
![[case] Application of element display and hiding -- element mask](/img/6e/6ea484a6e5d547e01dd8820af8e314.png)
[case] Application of element display and hiding -- element mask
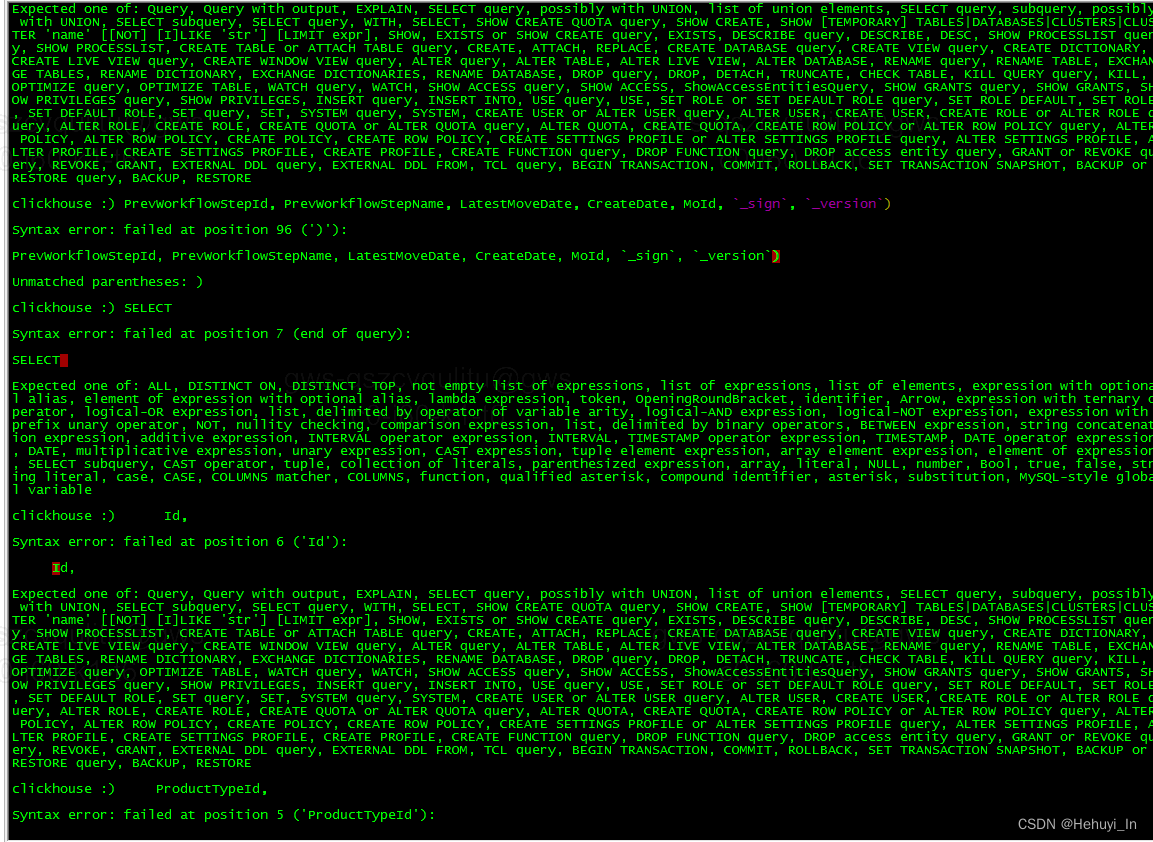
Clickhouse copy paste multi line SQL statement error
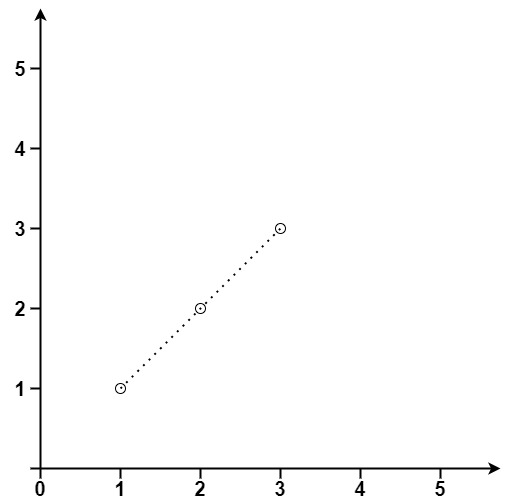
LeetCode_哈希表_困难_149. 直线上最多的点数
1.2 download and installation of the help software rstudio

Teach yourself to train pytorch model to Caffe (III)
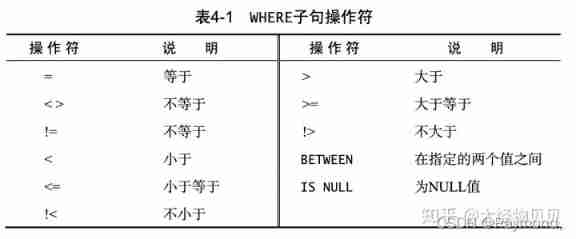
SQL knowledge leak detection
EasyExcel的讀寫操作
LeetCode_ Hash table_ Difficulties_ 149. Maximum number of points on the line
随机推荐
第05章_存储引擎
MMAP学习
Generics of TS
Detailed explanation of memset() function usage
[daily training] 729 My schedule I
Zhang Lijun: penetrating uncertainty depends on four "invariants"
selenium 获取dom内属性值的方法
Sequence alignment
Clickhouse copy paste multi line SQL statement error
leetcode:1139. The largest square bounded by 1
uni-app 蓝牙通信
Postgres establish connection and delete records
Clion configures Visual Studio (MSVC) and JOM multi-core compilation
阿里云有奖体验:用PolarDB-X搭建一个高可用系统
让开发效率飞速提升的跨端方案
張麗俊:穿透不確定性要靠四個“不變”
Simple interest mode - evil Chinese style
WPF gets the control in the datagridtemplatecolumn of the specified row and column in the DataGrid
Some things make feelings nowhere to put
KingbaseES V8R3集群维护案例之---在线添加备库管理节点