当前位置:网站首页>spark:地区广告点击量排行统计(小案例)
spark:地区广告点击量排行统计(小案例)
2022-07-27 01:31:00 【一个人的牛牛】
目录
介绍:
广告点击量的好处:
(1)获得高点击率后就可以收取一部分广告收入,当然你的内容粘性越大,广告收入越高;
(2)商业网站更重要的是能够获得信息资产;
(3)获取无形资产:网站知名度,客户资料,客户数据。
注:可以获得客户资料和数据,分析客户的需求,进行定制性服务,让客户更满意;
通过分析,平台可以增加内容与服务,更改结构和工作流程。
数据准备
数据格式:
2022-5-3-22:19:30 浙江 城市6 大笨蛋 广告1
时间、省份、城市、用户、广告 中间字段使用空格分隔。
模拟数据生成
代码如下:
import java.io.{File, PrintWriter}
object DataGet {
def main(args: Array[String]): Unit = {
Data(6000)
}
def Data(n:Int):Unit ={
var sb:StringBuilder = new StringBuilder
for (i <- 1 to n){
sb.append(time + "-" + timeStamp())
sb.append(" ")
sb.append(province())
sb.append(" ")
sb.append(city())
sb.append(" ")
sb.append(user())
sb.append(" ")
sb.append(ADV())
if (i <= n - 1) {
sb.append("\n")
}
}
writeToFile(sb.toString())
}
def province(): String = {
val name = Array(
"北京","上海","贵州","河南","湖北","河北","云南","四川","浙江","江苏"
)
val s = (Math.random() * (9) + 0).toInt
name(s)
}
def city(): String = {
val cityname = Array(
"城市1","城市2","城市3","城市4","城市5","城市6","城市7"
)
val s = (Math.random() * (6) + 0).toInt
cityname(s)
}
def ADV(): String = {
val ADVname = Array(
"广告1","广告2","广告3","广告4","广告5","广告6","广告7","广告8"
)
val s = (Math.random() * (7) + 0).toInt
ADVname(s)
}
def user(): String = {
val name = Array(
"张三","李四","王二","麻子","大笨蛋","小调皮","小乖乖","小机灵"
)
val s = (Math.random() * (8) + 0).toInt
name(s)
}
def time(): String = {
var year: Int = (2022).toInt
var month: Int = (Math.random() * (12 - 1 + 1) + 1).toInt
var day: Int = (Math.random() * (31 - 1 + 1) + 1).toInt
year + "-" + month + "-" + day
}
def timeStamp(): String = {
var hour = (Math.random() * (24 - 1 + 1) + 1).toInt
var m = (Math.random() * (60 - 1 + 1) + 1).toInt
var second = (Math.random() * (60 - 1 + 1) + 1).toInt
hour + ":" + m + ":" + second
}
def writeToFile(str: String): Unit = {
val printWriter = new PrintWriter(new File("E:\\AllProject\\sparklearn\\datas\\testlog.log"))
printWriter.write(str)
printWriter.flush()
printWriter.close()
}
}需求描述&流程
统计每个省份每个广告被点击数排行的Top5。
如下图,作者懒,不想做文字解释。
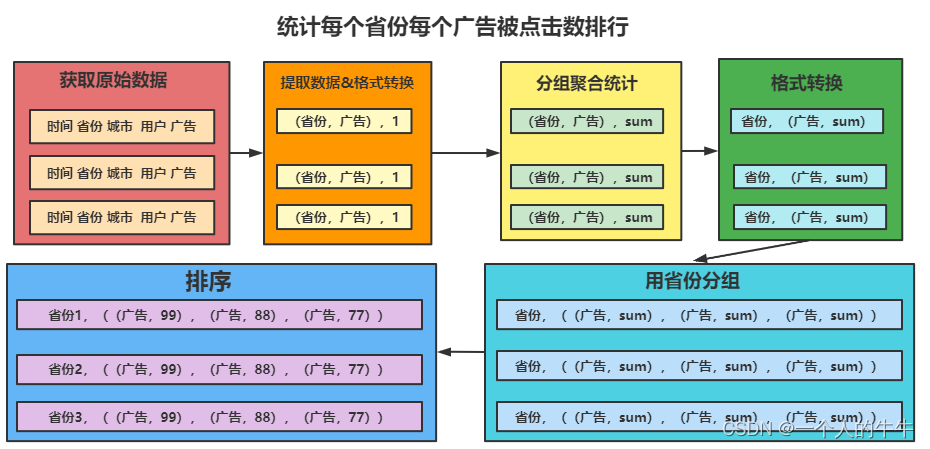
功能实现
代码如下:
import org.apache.spark.{SparkConf, SparkContext}
object case1 {
def main(args: Array[String]): Unit = {
//TODO 创建环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
//TODO 案例分析 统计出每个省份每个广告被点击数量排行的Top5
//1.获取原始数据:时间、省份、城市、用户、广告
val rdd = sc.textFile("datas/testlog.log")
//2.提取需要的数据,进行格式转换
val mapRDD = rdd.map(
line => {
val datas = line.split(" ")
((datas(1), datas(4)), 1)
}
)
//3.分组聚合
val reduceRDD = mapRDD.reduceByKey(_ + _)
//4.结果的格式转换
val newRDD = reduceRDD.map {
case (
(province, adv), sum) => {
(province, (adv, sum))
}
}
//5.用省份分组
val groupRDD = newRDD.groupByKey()
//6.排序
val resultRDD = groupRDD.mapValues(
iter => {
iter.toList.sortBy(_._2)(Ordering.Int.reverse).take(5)
}
)
//7.打印
resultRDD.collect().foreach(println)
//TODO 关闭环境
sc.stop()
}
}结果如下:

边栏推荐
- Redis四大特殊数据类型的学习和理解
- {“errcode“:44001,“errmsg“:“empty media data, hint: [1655962096234893527769663], from ip: 222.72.xxx.
- Common questions and answers of software testing interview (divergent thinking, interface, performance, concept,)
- win10/win11无损扩大C盘空间,跨盘合并C、E盘
- How big is the bandwidth of the Tiktok server for hundreds of millions of people to brush at the same time?
- 太强了,一个注解搞定接口返回数据脱敏
- sqlserver select * 能不能排除某个字段
- Integrated water conservancy video monitoring station telemetry terminal video image water level water quality water quantity flow velocity monitoring
- day6
- Worthington果胶酶的特性及测定方案
猜你喜欢

Plato Farm全新玩法,套利ePLATO稳获超高收益

Baidu cloud face recognition

After two years of graduation, I switched to software testing and got 12k+, and my dream of not taking the postgraduate entrance examination with a monthly salary of more than 10000 was realized

Comprehensive care analysis lyriq Ruige battery safety design

On the prototype of constructor

Jmeter分布式压测

A math problem cost the chip giant $500million!

Pytorch损失函数总结

Worthington果胶酶的特性及测定方案

身家破亿!86版「红孩儿」拒绝出道成学霸,已是中科院博士,名下52家公司
随机推荐
[动态规划中等题] LeetCode 198. 打家劫舍 740. 删除并获得点数
深度学习——词汇embedded、Beam Search
Skywalking系列学习之告警通知源码分析
Common events of window objects
Submodule cache cache failure
正方形数组的数目(DAY 81)
win10/win11无损扩大C盘空间,跨盘合并C、E盘
196. Delete duplicate email addresses
30分钟彻底弄懂 synchronized 锁升级过程
How to design the red table of database to optimize the performance
数模1232
Data Lake (20): Flink is compatible with iceberg, which is currently insufficient, and iceberg is compared with Hudi
2649: segment calculation
食物链(DAY 79)
[flask] the server obtains the request header information of the client
力扣(LeetCode)207. 课程表(2022.07.26)
FactoryBean的getObject调用时机
CAS deployment and successful login jump address
2513: 小勇学分数(公约数问题)
185. All employees with the top three highest wages in the Department (mandatory)