当前位置:网站首页>机器学习基础-决策树-12
机器学习基础-决策树-12
2022-07-28 11:51:00 【gemoumou】
决策树Decision Tree












决策树-例子
from sklearn.feature_extraction import DictVectorizer
from sklearn import tree
from sklearn import preprocessing
import csv
# 读入数据
Dtree = open(r'AllElectronics.csv', 'r')
reader = csv.reader(Dtree)
# 获取第一行数据
headers = reader.__next__()
print(headers)
# 定义两个列表
featureList = []
labelList = []
#
for row in reader:
# 把label存入list
labelList.append(row[-1])
rowDict = {
}
for i in range(1, len(row)-1):
#建立一个数据字典
rowDict[headers[i]] = row[i]
# 把数据字典存入list
featureList.append(rowDict)
print(featureList)

# 把数据转换成01表示
vec = DictVectorizer()
x_data = vec.fit_transform(featureList).toarray()
print("x_data: " + str(x_data))
# 打印属性名称
print(vec.get_feature_names())
# 打印标签
print("labelList: " + str(labelList))
# 把标签转换成01表示
lb = preprocessing.LabelBinarizer()
y_data = lb.fit_transform(labelList)
print("y_data: " + str(y_data))

# 创建决策树模型
model = tree.DecisionTreeClassifier(criterion='entropy')
# 输入数据建立模型
model.fit(x_data, y_data)

# 测试
x_test = x_data[0]
print("x_test: " + str(x_test))
predict = model.predict(x_test.reshape(1,-1))
print("predict: " + str(predict))












决策树-CART
from sklearn import tree
import numpy as np
# 载入数据
data = np.genfromtxt("cart.csv", delimiter=",")
x_data = data[1:,1:-1]
y_data = data[1:,-1]
# 创建决策树模型
model = tree.DecisionTreeClassifier()
# 输入数据建立模型
model.fit(x_data, y_data)

# 导出决策树
import graphviz # http://www.graphviz.org/
dot_data = tree.export_graphviz(model,
out_file = None,
feature_names = ['house_yes','house_no','single','married','divorced','income'],
class_names = ['no','yes'],
filled = True,
rounded = True,
special_characters = True)
graph = graphviz.Source(dot_data)
graph.render('cart')


决策树-线性二分类
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report
from sklearn import tree
# 载入数据
data = np.genfromtxt("LR-testSet.csv", delimiter=",")
x_data = data[:,:-1]
y_data = data[:,-1]
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()

# 创建决策树模型
model = tree.DecisionTreeClassifier()
# 输入数据建立模型
model.fit(x_data, y_data)

# 导出决策树
import graphviz # http://www.graphviz.org/
dot_data = tree.export_graphviz(model,
out_file = None,
feature_names = ['x','y'],
class_names = ['label0','label1'],
filled = True,
rounded = True,
special_characters = True)
graph = graphviz.Source(dot_data)

# 获取数据值所在的范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = model.predict(np.c_[xx.ravel(), yy.ravel()])# ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 样本散点图
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()

predictions = model.predict(x_data)
print(classification_report(predictions,y_data))

决策树-非线性二分类
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import classification_report
from sklearn import tree
from sklearn.model_selection import train_test_split
# 载入数据
data = np.genfromtxt("LR-testSet2.txt", delimiter=",")
x_data = data[:,:-1]
y_data = data[:,-1]
plt.scatter(x_data[:,0],x_data[:,1],c=y_data)
plt.show()

#分割数据
x_train,x_test,y_train,y_test = train_test_split(x_data, y_data)
# 创建决策树模型
# max_depth,树的深度
# min_samples_split 内部节点再划分所需最小样本数
model = tree.DecisionTreeClassifier(max_depth=7,min_samples_split=4)
# 输入数据建立模型
model.fit(x_train, y_train)

# 导出决策树
import graphviz # http://www.graphviz.org/
dot_data = tree.export_graphviz(model,
out_file = None,
feature_names = ['x','y'],
class_names = ['label0','label1'],
filled = True,
rounded = True,
special_characters = True)
graph = graphviz.Source(dot_data)

# 获取数据值所在的范围
x_min, x_max = x_data[:, 0].min() - 1, x_data[:, 0].max() + 1
y_min, y_max = x_data[:, 1].min() - 1, x_data[:, 1].max() + 1
# 生成网格矩阵
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.02),
np.arange(y_min, y_max, 0.02))
z = model.predict(np.c_[xx.ravel(), yy.ravel()])# ravel与flatten类似,多维数据转一维。flatten不会改变原始数据,ravel会改变原始数据
z = z.reshape(xx.shape)
# 等高线图
cs = plt.contourf(xx, yy, z)
# 样本散点图
plt.scatter(x_data[:, 0], x_data[:, 1], c=y_data)
plt.show()

predictions = model.predict(x_train)
print(classification_report(predictions,y_train))

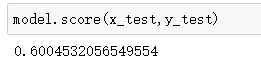
predictions = model.predict(x_test)
print(classification_report(predictions,y_test))


回归树
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree
# 载入数据
data = np.genfromtxt("data.csv", delimiter=",")
x_data = data[:,0,np.newaxis]
y_data = data[:,1,np.newaxis]
plt.scatter(x_data,y_data)
plt.show()

model = tree.DecisionTreeRegressor(max_depth=5)
model.fit(x_data, y_data)

x_test = np.linspace(20,80,100)
x_test = x_test[:,np.newaxis]
# 画图
plt.plot(x_data, y_data, 'b.')
plt.plot(x_test, model.predict(x_test), 'r')
plt.show()

# 导出决策树
import graphviz # http://www.graphviz.org/
dot_data = tree.export_graphviz(model,
out_file = None,
feature_names = ['x','y'],
class_names = ['label0','label1'],
filled = True,
rounded = True,
special_characters = True)
graph = graphviz.Source(dot_data)

回归树-预测房价
from sklearn import tree
from sklearn.datasets.california_housing import fetch_california_housing
from sklearn.model_selection import train_test_split
housing = fetch_california_housing()
print(housing.DESCR)

housing.data.shape

housing.data[0]

housing.target[0]

x_data = housing.data
y_data = housing.target
x_train,x_test,y_train,y_test = train_test_split(x_data, y_data)
model = tree.DecisionTreeRegressor()
model.fit(x_train, y_train)

边栏推荐
- Uncover why devaxpress WinForms, an interface control, discards the popular maskbox property
- LeetCode94. 二叉树的中序遍历
- Design a thread pool
- STM32F103 several special pins are used as ordinary io. Precautions and data loss of backup register 1,2
- Merge table rows - three levels of for loop traversal data
- Library automatic reservation script
- LeetCode394 字符串解码
- Unity加载Glb模型
- Aopmai biological has passed the registration: the half year revenue is 147million, and Guoshou Chengda and Dachen are shareholders
- 连通块&&食物链——(并查集小结)
猜你喜欢

机器学习实战-神经网络-21

Uncover why devaxpress WinForms, an interface control, discards the popular maskbox property

Minimally invasive electrophysiology has passed the registration: a listed enterprise with annual revenue of 190million minimally invasive mass production

Linear classifier (ccf20200901)
线性分类器(CCF20200901)

非标自动化设备企业如何借助ERP系统,做好产品质量管理?

04 pyechars geographic chart (example code + effect diagram)

机器学习实战-逻辑回归-19

MMA8452Q几种模式的初始化实例

HC-05蓝牙模块调试从模式和主模式经历
随机推荐
IO流再回顾,深入理解序列化和反序列化
机器学习基础-支持向量机 SVM-17
leetcode:704二分查找
New Oriental's single quarter revenue was 524million US dollars, a year-on-year decrease of 56.8%, and 925 learning centers were reduced
Leetcode 42. rainwater connection
Four authentic postures after suffering and trauma, Zizek
C# static的用法详解
VS code更新后不在原来位置
[cute new problem solving] climb stairs
Solution to the binary tree problem of niuke.com
VS1003 debugging routine
LeetCode206 反转链表
How can non-standard automation equipment enterprises do well in product quality management with the help of ERP system?
Sliding Window
Aopmai biological has passed the registration: the half year revenue is 147million, and Guoshou Chengda and Dachen are shareholders
Under what circumstances can the company dismiss employees
C# 泛型是什么、泛型缓存、泛型约束
STM32 loopback structure receives and processes serial port data
Insufficient permission to pull server code through Jenkins and other precautions
Block reversal (summer vacation daily question 7)