当前位置:网站首页>Text to image paper intensive reading rat-gan: recursive affine transformation for text to image synthesis
Text to image paper intensive reading rat-gan: recursive affine transformation for text to image synthesis
2022-07-27 02:08:00 【Medium coke with ice】
RAT-GAN A recursive affine transformation for generating countermeasure networks is proposed (RAT), Connect all fusion blocks with recurrent neural networks , To simulate their long-term dependencies , Follow DF-GAN Is very similar . The article was published in 2022 year 4 month .
Address of thesis :https://arxiv.org/pdf/2204.10482.pdf
Code address :https://github.com/senmaoy/Recurrent-Affine-Transformation-for-Text-to-image-Synthesis
This blog is a report of intensive reading of this paper , Include some personal understanding 、 Knowledge expansion and summary .
One 、 Summary of the original
Text to image synthesis aims to generate natural images based on text description . The main difficulty of this task is to effectively integrate text information into the image synthesis process . Existing methods usually use multiple independent fusion blocks ( for example , Conditional batch normalization and instance normalization ) Adaptively fuse the appropriate text information into the synthesis process . However , Isolated fusion blocks not only conflict with each other , And it increases the difficulty of training . To solve these problems , We propose a recursive affine transformation for generative countermeasure Networks (RAT), It connects all fusion blocks with a recursive neural network , To simulate their long-term dependence . Besides , In order to improve the semantic consistency between text and synthetic image , We add a spatial attention model to the discriminator . Because we know the matching image area , The text description monitor generator synthesizes more relevant image content . stay CUB、Oxford-102 and COCO A lot of experiments on data sets show that , Compared with the most advanced model , This model has advantages .
Two 、 Why put forward RAT-GAN
GANs Usually through multiple independent fusion blocks ( Such as conditional batch normalization (CBN) And instance normalization (CIN)) Adaptively fuse the appropriate text information into the synthesis process ,DFGAN、DT-GAN、SSGAN All use CIN and CBN Integrate text information into synthetic images , But there is a serious drawback , namely They are isolated in different layers , Ignoring the global allocation of text information fused in different layers . Isolated fusion blocks are difficult to optimize , Because they don't interact with each other .
therefore , The author puts forward a kind of ** Recursive affine transformation (RAT)** To control all fusion blocks uniformly .RAT Use standard context vectors of the same shape to express the output of different layers , To achieve unified control of different layers . Then we use recurrent neural networks (RNN) Connect context vectors , To detect long-term correlation , adopt RNN, Fused blocks are not only consistent between adjacent blocks , And it reduces the difficulty of training .
3、 ... and 、RAT-GAN
3.1、 The overall framework

The overall frame diagram is shown in the above figure , And DF-GAN The more similar , Similarly, random noise passes MLP Reshape the feature vector into a specified size , And then use 5 individual RAT Blocks, After a series of affine transformations , Finally, the feature map is generated .
Discriminator and DF-GAN not quite the same , After down sampling , Combine image and text features expand Then do spatial attention and generate a global feature ( And AttnGAN Is similar to ), Then judge whether the generated image is true .
3.2 、RAT Affine block (Recurrent Affine Transformation)
3.2.1、RAT Structure of affine block
Single RAT The structure of affine block is as follows :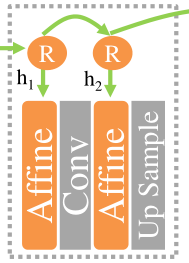
RAT Affine block body and DF-GAN and SSAGAN It's about the same , Two, too MLP, One with scaling parameters , For image feature vector c Perform channel scaling , The other has a translation parameter , For image feature vector c Perform channel translation :
Affine ( c ∣ h t ) = γ i ⋅ c + β i , γ = MLP 1 ( h t ) , β = MLP 2 ( h t ) \text { Affine }\left(c \mid h_{t}\right)=\gamma_{i} \cdot c+\beta_{i}, \gamma=\operatorname{MLP}_{1}\left(h_{t}\right), \quad \beta=\operatorname{MLP}_{2}\left(h_{t}\right) Affine (c∣ht)=γi⋅c+βi,γ=MLP1(ht),β=MLP2(ht)
3.2.2、LSTM Introduction of loop controller
The most important thing is that it introduces Loop controller mechanism (Recurrent Controller), Its use LSTM Connect context vectors , To detect long-term correlation , In the neighborhood RAT Keep consistent between blocks .
LSTM The initial state of is calculated from the noise vector : h 0 = MLP 3 ( z ) , c 0 = MLP 4 ( z ) h_{0}=\operatorname{MLP}_{3}(z), \quad c_{0}=\operatorname{MLP}_{4}(z) h0=MLP3(z),c0=MLP4(z), The updated rules are as follows :
( i t f t o t u t ) = ( σ σ σ tanh ) ( T ( s h t − 1 ) ) \left(\begin{array}{l} \mathbf{i}_{t} \\ \mathbf{f}_{t} \\ \mathbf{o}_{t} \\ u_{t} \end{array}\right)=\left(\begin{array}{c} \sigma \\ \sigma \\ \sigma \\ \tanh \end{array}\right)\left(T\left(\begin{array}{c} s \\ h_{t-1} \end{array}\right)\right) ⎝⎜⎜⎛itftotut⎠⎟⎟⎞=⎝⎜⎜⎛σσσtanh⎠⎟⎟⎞(T(sht−1))
c t = f t ⊙ c t − 1 + i t ⊙ u t h t = o t ⊙ tanh ( c t ) γ t , β t = MLP 1 t ( h t ) , MLP 2 t ( h t ) \begin{aligned} \mathbf{c}_{t} &=\mathbf{f}_{t} \odot \mathbf{c}_{t-1}+\mathbf{i}_{t} \odot u_{t} \\ h_{t} &=\mathbf{o}_{t} \odot \tanh \left(\mathbf{c}_{t}\right) \\ \gamma_{t}, \beta_{t} &=\operatorname{MLP}_{1}^{\mathrm{t}}\left(h_{t}\right), \operatorname{MLP}_{2}^{\mathrm{t}}\left(h_{t}\right) \end{aligned} cthtγt,βt=ft⊙ct−1+it⊙ut=ot⊙tanh(ct)=MLP1t(ht),MLP2t(ht)
among , i t i_t it、 f t f_t ft、 o t o_t ot Each represents the input gate 、 Forgetting gate and output gate , The principle of the above rules is mainly LSTM, The first step is to forget the door , It is to decide what information needs to be discarded in the cell state , This part of the operation is through a sigmoid Unit to deal with , The next step is to input the gate to decide what new information to add to the cell state , Finally, the output gate , The input will go through a igmoid The layer gets the judgment condition , Then pass the cell state through tanh Layer gets a -1~1 Vector of values between , The vector is multiplied by the judgment conditions obtained by the output gate to obtain the final result RNN The output of the cell . If you don't understand, you can learn LSTM Then understand ( Attached below LSTM Structure diagram ).
3.2.3、RAT Innovation of affine block
RAT Affine block No longer treat affine transformation as an isolated module . by comparison , Its use RNN To model long-term dependencies between fusion blocks , This not only forces the fusion blocks to be consistent with each other , And it also reduces the difficulty of jumping connection training .
3.3、 Matching perceptual discriminator with spatial attention
In order to improve the semantic consistency between synthetic image and text description , The author adds Spatial attention mechanism , As shown in the figure below :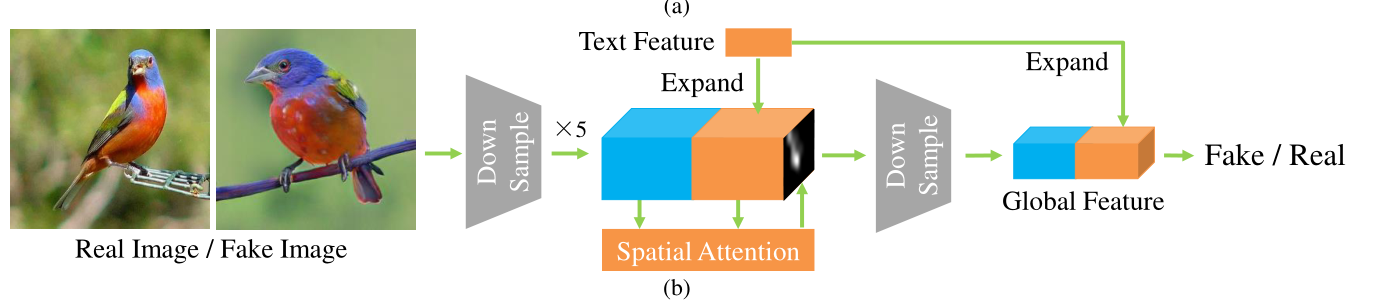
3.3.1 Spatial attention
Combined with image feature mapping P And sentence vectors S Information in , Spatial attention generates an attention mapping α, Note the mapping α Suppress the sentence vector of irrelevant areas , The formula is as follows :
x w , h = MLP ( P w , h , s ) , α w , h = 1 1 + e − x w , h ∑ w = 1 , h = 1 W , H 1 1 + e − x w , h , S w , h = s × α w , h , \begin{aligned} x_{w, h} &=\operatorname{MLP}\left(P_{w, h}, s\right), \\ \alpha_{w, h} &=\frac{\frac{1}{1+e^{-x_{w}, h}}}{\sum_{w=1, h=1}^{W, H} \frac{1}{1+e^{-x} w, h}}, \\ S_{w, h} &=s \times \alpha_{w, h}, \end{aligned} xw,hαw,hSw,h=MLP(Pw,h,s),=∑w=1,h=1W,H1+e−xw,h11+e−xw,h1,=s×αw,h,
among , From the top down , P w , h P_{w,h} Pw,h It can be understood as in coordinates (w,h) The image features of ,s It's a sentence vector , Input them together into a multilayer perceptron MLP in , Then calculate x w , h x_{w,h} xw,h By calculating the weight, it is converted into the probability of attention α w , h α_{w,h} αw,h
The final will be α Multiply it by the sentence vector , Get the weight of sentence feature matching image feature S w , h S_{w,h} Sw,h.
3.3.2、 Soft threshold function
You can see 3.3.1 The formula of α Calculation method , In the calculation α The soft threshold function method is used :
p ( x k ) = 1 1 + e − x k ∑ j = 1 K 1 1 + e − x j p\left(x_{k}\right)=\frac{\frac{1}{1+e^{-x_{k}}}}{\sum_{j=1}^{K} \frac{1}{1+e^{-x_{j}}}} p(xk)=∑j=1K1+e−xj11+e−xk1
Author and No popular softmax function , Because it maximizes the maximum probability , And inhibit other probabilities from approaching 0. The extremely small probability hinders the back propagation of the gradient , Which aggravates GAN The instability of training .
The soft threshold function can prevent the probability of attention from approaching zero , And improve the efficiency of back propagation . Spatial attention model assigns more text features to relevant image areas , This helps the discriminator determine the text - Whether the image pair matches . In antagonistic training , Stronger discriminators force the generator to synthesize more relevant image content .
3.4、 Loss function
The training target of the discriminator takes the synthetic image and mismatched image as negative samples , Use on real text pairs and matching text pairs hinge loss Of MA-GP As a loss function :
L adv D = E x ∼ p data [ max ( 0 , 1 − D ( x , s ) ) ] + 1 2 E x ∼ p G [ max ( 0 , 1 + D ( x ^ , s ) ) ] + 1 2 E x ∼ p data [ max ( 0 , 1 + D ( x , s ^ ) ) ] \begin{aligned} \mathcal{L}_{\text {adv }}^{D}=& \mathbb{E}_{x \sim p_{\text {data }}}[\max (0,1-D(x, s))] \\ &+\frac{1}{2} \mathbb{E}_{x \sim p_{G}}[\max (0,1+D(\hat{x}, s))] \\ &+\frac{1}{2} \mathbb{E}_{x \sim p_{\text {data }}}[\max (0,1+D(x, \hat{s}))] \end{aligned} Ladv D=Ex∼pdata [max(0,1−D(x,s))]+21Ex∼pG[max(0,1+D(x^,s))]+21Ex∼pdata [max(0,1+D(x,s^))]
among ,s Is the given text description , s ˆ sˆ sˆ Are mismatched text descriptions , The loss function of the generator is :
L a d v G = E x ∼ p G [ min ( D ( x , s ) ) ] \mathcal{L}_{\mathrm{adv}}^{G}=\mathbb{E}_{x \sim p_{G}}[\min (D(x, s))] LadvG=Ex∼pG[min(D(x,s))]
Four 、 experiment
4.1、 Data sets
CUB、Oxford-102、MS-COCO
4.2、 Training details
The parameters of text encoder are fixed during training , The optimizer uses Adam, The generator learning rate is 0.0001, The learning rate of the discriminator is 0.0004.
stay CUB and Oxford On ,batchsize=24,epoch=600, Single RTX3090ti Training 3 God .
stay COCO On ,batchsize=48,epoch=300, Use two RTX3090ti Training for two weeks .
4.3、 experimental result
4.3.1、 Experimental results

Different images generated under the same text :
Visualization of attention map :
4.3.2、 quantitative analysis

4.3.3、 Ablation Experiment

5、 ... and 、 summary
RAT-GAN The innovations are as follows :
- A recursive affine transformation is proposed , Connect all fusion blocks , In order to globally allocate text information in the synthesis process .
- Add spatial attention to the discriminator , Focus on the relevant image area , Therefore, the generated image is more relevant to the text description
Last
Personal profile : Graduate students in the field of artificial intelligence , At present, I mainly focus on text generation and image generation (text to image) Direction
Personal home page : Medium coke with more ice
Time limited free subscribe : Text generated images T2I special column
Stand by me : give the thumbs-up + Collection ️+ Leaving a message.
边栏推荐
- 2022年T2I文本生成图像 中文期刊论文速览-1(ECAGAN:基于通道注意力机制的文本生成图像方法+CAE-GAN:基于Transformer交叉注意力的文本生成图像技术)
- 超出隐藏显示省略号
- Autojs learning - realize image cutting
- MySQL stored procedure function
- MySQL备份恢复
- 22FTP
- Talking about server virtualization & hyper convergence & Storage
- 23nfs shared storage service
- 读写分离、主从同步一文搞定
- Initial experience of cloud database management
猜你喜欢







随机推荐
利用九天深度学习平台复现SSA-GAN
Shell programming specifications and variables
MySQL backup recovery
Homework 1-4 learning notes
(atcoder contest 144) f - fork in the road (probability DP)
解决方案:Win10如何使用bash批处理命令
MySQL common statements
[FPGA tutorial case 29] the second DDS direct digital frequency synthesizer based on FPGA - Verilog development
shell课程总结
The gradient descent method and Newton method are used to calculate the open radical
IO function of standard C library
力扣获取第二大的成绩
Ubuntu12.10 installing mysql5.5 (II)
Introduction to network - Introduction to Enterprise Networking & basic knowledge of network
解决方案:读取两个文件夹里不同名的文件,处理映射不对应的文件
Beyond hidden display ellipsis
MySQL installation
STM32 HAL库串口(UART/USART)调试经验(一)——串口通信基础知识+HAL库代码理解
a元素的伪类
7.16 多益网络笔试