当前位置:网站首页>Deep learning plus
Deep learning plus
2022-07-05 16:44:00 【Small margin, rush】
Continuous updating
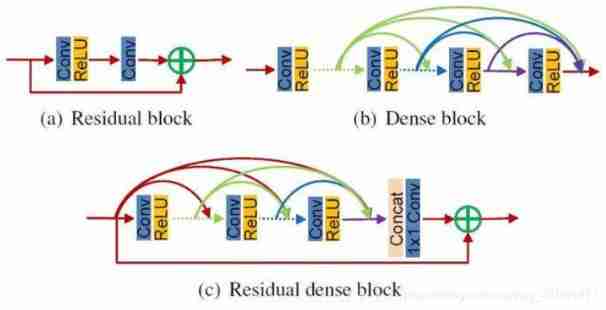
1. Residual dense network RDN
Thesis link :https://arxiv.org/abs/1802.08797
The essence : Image super-resolution network utilizing all layered features - Single image super-resolution (SISR) Aimed at low resolution (LR) High resolution with good vision is generated on the basis of measurement (HR) Images .
2. Cross entropy error
Cross entropy describes the distance between two probability distributions , The closer the cross entropy is, the closer the two are
Use... For classification One Hot Label + Cross Entropy Loss
Training The process , Use... For classification Cross Entropy Loss, Go back to the question Mean Squared Error.
3. Batch gradient descent
Update the gradient every time you use all the training sets
Calculate the loss function each time using all the training set samples loss_function Gradient of params_grad, Then use the learning rate learning_rate Update each parameter of the model in the opposite direction of the gradient params
Batch gradient descent uses the entire training set for each learning , So the advantage is that every update will be in the right direction , Finally, it can be guaranteed to converge to the extreme point ( The convex function converges to the global extreme point , Nonconvex functions may converge to local extremum ), But its disadvantage is that each study time is too long , And if the training set is large enough to consume a lot of memory , And the full gradient descent can not update the model parameters on line
4. Stochastic gradient descent
Random gradient descent algorithm randomly selects one sample from the training set every time to learn , Learning is very fast , And can be updated online .
The random gradient decreases the most The disadvantage is that each update may not be in the right direction , So it can bring about optimization fluctuation ( Disturbance )
5. Small batch gradient descent
Small batch gradient descent combines batch gradient descent and random gradient descent , There is a balance between the speed of each update and the number of updates , Each update is randomly selected from the training set m,m<n Learn from samples
6. An optimization method
Moment: It simulates the inertia of an object in motion , It is to keep the direction of the previous update to a certain extent when updating , At the same time, take advantage of the current batch Fine tune the gradient of the final update direction . thus , It can increase stability to a certain extent , So that we can learn faster , And there is a certain ability to get rid of the local optimum

Adagrad: There is a constraint on the learning rate
RMSprop:RMSprop It can be counted as Adadelta A special case of , Depends on the global learning rate
Adam(Adaptive Moment Estimation) It's essentially a momentum term RMSprop, It uses the first-order moment estimation and the second-order moment estimation of the gradient to dynamically adjust the learning rate of each parameter .Adam The main advantage is that after bias correction , The learning rate of each iteration has a certain range , Make the parameters more stable .
7.BatchNormalization The role of
By means of standardization , Pull more and more biased distribution back to standardized distribution , Make the input value of the activation function fall in the area where the activation function is sensitive to the input , So that the gradient becomes larger , Speed up learning convergence , Avoid the problem of gradients disappearing .
In the neural network , When the learning speed of the front hidden layer is lower than that of the back hidden layer , That is, as the number of hidden layers increases , The accuracy of classification has declined .
8. 1*1 The convolution of
Realize cross channel interaction and information integration , To reduce the channel number of convolution kernel and increase the dimension , Can achieve more than one feature map The linear combination of , And it can achieve the equivalent effect with full connection layer
Dimension reduction : When the input is 6x6x32 when ,1x1 The form of convolution is 1x1x32, When there is only one 1x1 Convolution kernel , The output is 6x6x1
1x1 Convolution generally only changes the number of output channels (channels), Without changing the width and height of the output

9. Depth of understanding channel
tensorflow Given in , For input samples channels The meaning of . General RGB picture ,channels The number is 3 ( red 、 green 、 blue ); and monochrome picture ,channels The number is 1 .
mxnet Mentioned in , commonly channels The meaning is , The number of convolution kernels in each convolution layer .
Suppose the existing one is 6×6×3 Sample pictures of , Use 3×3×3 Convolution kernel (filter) Convolution operation . At this point, enter the name of the picture channels by 3, and Convolution kernel Of in_channels And Of data requiring convolution channels Agreement
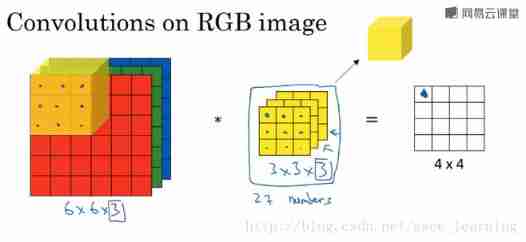
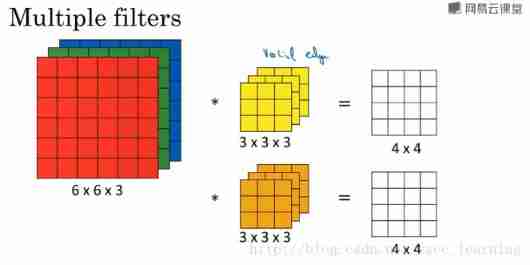
- Of the original input image sample
channels, Depending on the picture type , such as RGB;- Output after convolution operation
out_channels, Depending on the number of convolution kernels . At this timeout_channelsIt will also be used as the convolution kernel for the next convolutionin_channels;- In convolution kernel
in_channels, just 2 It's already said in , It's the result of the last convolutionout_channels, If you're doing convolution for the first time , Namely 1 In the sample picturechannels.
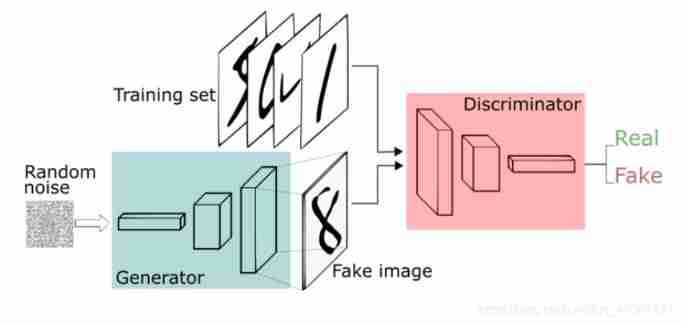
10.GAN
2014Goodfellow Put forward GAN,GAN The main structure of the includes a generator G(Generator) And a Judging device D. In the process of training , Generation network G The goal is to generate real pictures as much as possible to cheat the discrimination network D. and D The goal is to try to G The generated image is different from the real image . such ,G and D Constitute a dynamic “ The game process ”.(Discriminator)
 11.DCGAN
11.DCGAN
 11.DCGAN
11.DCGANDCGAN A method called transpose convolution operation is used , That is, deconvolution . Transpose convolution can be scaled up . They help us transform low resolution images into high resolution images .
DCGAN The structure of convolution neural network is changed , In order to improve the quality of samples and the speed of convergence , These changes are :
- Cancel all pooling layer .G Transpose convolution is used in the network (transposed convolutional layer) Sample up ,D Join in the network stride Instead of pooling.
- stay D and G Both of them are used batch normalization
- Get rid of FC layer , Make the network full convolution network
- G Network usage ReLU As an activation function , The last layer uses tanh
- D Network usage LeakyReLU As an activation function
12.StyleGAN
StyleGAN Not focused on creating more realistic images , But improved GANs The ability to finely control the generated image .
StyleGAN Not focusing on architecture and loss functions
13.L1,L2 Regularization
Add it after the loss function to adjust loss Output , Prevent over fitting
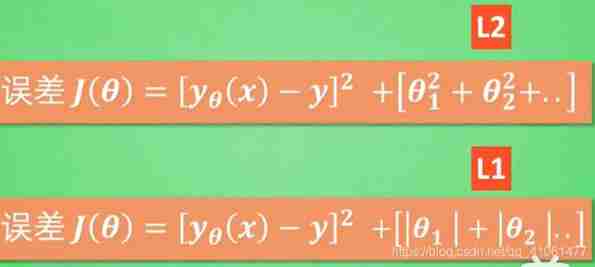
14.
边栏推荐
- Seaborn绘制11个柱状图
- Raspberry pie 4B installation pytorch1.11
- Detailed explanation of use scenarios and functions of polar coordinate sector diagram
- 详解SQL中Groupings Sets 语句的功能和底层实现逻辑
- 用键盘输入一条命令
- Basic introduction to the control of the row component displaying its children in the horizontal array (tutorial includes source code)
- [brush title] goose factory shirt problem
- [echart] resize lodash to realize chart adaptation when window is zoomed
- 求解汉诺塔问题【修改版】
- Binary tree related OJ problems
猜你喜欢
Starkware: to build ZK "universe"
PSPNet | 语义分割及场景分析

scratch五彩糖葫芦 电子学会图形化编程scratch等级考试三级真题和答案解析2022年6月
Summary of PHP pseudo protocol of cisp-pte
Today's sleep quality record 79 points

【组队 PK 赛】本周任务已开启 | 答题挑战,夯实商品详情知识

Data Lake (XIV): spark and iceberg integrated query operation

新春限定丨“牛年忘烦”礼包等你来领~
DeSci:去中心化科学是Web3.0的新趋势?
Fleet tutorial 09 basic introduction to navigationrail (tutorial includes source code)
随机推荐
Pspnet | semantic segmentation and scene analysis
ES6 deep - ES6 class class
Cartoon: what is blue-green deployment?
Flet tutorial 12 stack overlapping to build a basic introduction to graphic and text mixing (tutorial includes source code)
EDI许可证和ICP经营性证有什么区别
Android privacy sandbox developer preview 3: privacy, security and personalized experience
[echart] resize lodash to realize chart adaptation when window is zoomed
详解SQL中Groupings Sets 语句的功能和底层实现逻辑
迁移/home分区
Scratch colorful candied haws Electronic Society graphical programming scratch grade examination level 3 true questions and answers analysis June 2022
《MongoDB入门教程》第04篇 MongoDB客户端
Google Earth Engine(GEE)——Kernel核函数简单介绍以及灰度共生矩阵
Solve cmakelist find_ Package cannot find Qt5, ECM cannot be found
Cartoon: what is the eight queens problem?
Win11提示无法安全下载软件怎么办?Win11无法安全下载软件
Single merchant v4.4 has the same original intention and strength!
[brush questions] effective Sudoku
[deep learning] how does deep learning affect operations research?
StarkWare:欲构建ZK“宇宙”
Bs-xx-042 implementation of personnel management system based on SSM