当前位置:网站首页>Deberta (decoding enhanced Bert with distinguished attention)
Deberta (decoding enhanced Bert with distinguished attention)
2022-06-30 09:37:00 【A grain of sand in the vast sea of people】
Catalog
1. Brief introduction of the paper
2.1. Decoupling attention mechanism (Disentangled attention)
2.2. Enhanced mask decoder (Enhanced mask decoder)
1. Brief introduction of the paper
DeBerta (Decoding-enhanced BERT with disentangled attention), The architecture uses two new technologies to improve BERT and RoBERTa Model : It turns out that it's better than Xlnet,BERT And RoBERTa Duqiang .
And for the first time in SuperGLUE It's more than human beings on the list .
2. contribution
2.1. Decoupling attention mechanism (Disentangled attention)
why
for example ,“deep” and “learning” These two words i Appear next to each other , The dependence and influence between them are much stronger than when they appear in different sentences or are not adjacent .
So in order to solve this problem . Relative position information can be introduced
How
Each word is represented by two vectors , Code the content and location respectively , The attention weight between words is calculated by the decoupling matrix of their content and relative position .
{H_i} and {P_i|j}, Respectively represents the content code 、 And relative position coding .

The attention weight of a word pair can be calculated as the sum of four attention scores , Use a scatter matrix on its content and location as content to content 、 Content to location 、 Location to content and location to location .
Bert Only content and content are considered . stay DDeBerta in , Location to location does not provide much additional information , In our implementation, we removed from the above equation .
primary self-attention The calculation is as follows :

token i And j The relative position is calculated as follows :
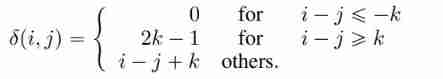
among k Represents the maximum relative distance ;
Decoupling matrix calculation details .

 Is the relative distance K Value and Q value
Is the relative distance K Value and Q value
The overall algorithm flow is shown in the following figure :

2.2. Enhanced mask decoder (Enhanced mask decoder)
Why
Example :“a new store opened beside the new mall”, If you want to predict “store” and “mall” These two words . Although the context of the two words is similar , But their syntactic functions in sentences are different .
The subject here is “store” instead of “mall”. So in order to solve this problem .DeBERTa stay softmax The absolute position of the word is embedded before the layer . Here with Bert Different .Bert The absolute position embedding vector is added when inputting
How

2.3. Anti training Method
Anti training Method to fine tune , To improve the generalization ability of the model .
Adversarial training is a regularization method to improve the generalization of the model . It does this by improving the robustness of the model to adversarial instances , Adversarial instances are created by perturbing the input slightly . The model is regularized , So when given a task - specific example , The output distribution produced by this model is the same as that produced by the anti disturbance of this example .
For NLP tasks , Perturbation is applied to word embedding rather than to the original word sequence . However , Different words and models , The value range of the embedded vector ( standard ) Is different . In a large model with billions of parameters , The variance will increase , Thus leading to the instability of antagonistic training .
Inspired by layer normalization , We have put forward SiFT(Scale-invariant-Fine-Tuning) Algorithm , The stability of training is improved by applying perturbation to normalized word embedding . say concretely , In our experiment , When the DeBERTa Downstream of NLP When the task is fine tuned ,SiFT Firstly, the word embedding vector is normalized to a random vector , Then the normalized embedding vector is perturbed . We found that , Normalization greatly improves the performance of the fine tuning model . This kind of improvement is in the larger DeBERTa More prominent in the model .
3. experimental result
Pre training data set size
It can be seen that the least is Bert, The second is DeBERTA 了 ,XLNet most

stay Large models result


stay Base Models Result

4 Other

The picture is from microsoft Official website . You can see it clearly Enhanced Mask Decoder And Disentangled attention(Relative Position Embedding)
5 Code
build_relative_position Method in da_util.py Returns a relative position matrix .

If query_size =4 and key_size= 4 when , Back to shape yes (1,4,4)
The matrix is roughly as follows :
| 0 | -1 | -2 | -3 |
| 1 | 0 | -1 | -2 |
| 2 | 1 | 0 | -1 |
| 3 | 2 | 1 | 0 |
Disentangled attention Code implementation

The calculation of relative position Code
c2p_pos = torch.clamp(relative_pos + att_span, 0, att_span*2-1)
边栏推荐
- So the toolbar can still be used like this? The toolbar uses the most complete parsing. Netizen: finally, you don't have to always customize the title bar!
- Numpy (constant)
- Script summary
- Concatapter tutorial
- 八大排序(一)
- Tclistener server and tcpclient client use -- socket listening server and socketclient use
- 【Ubuntu-redis安装】
- 3.集成eslint、prettier
- 工作小记: sendto失败 errno 22
- Harmonyos actual combat - ten thousand words long article understanding service card development process
猜你喜欢

MySQL优化

2021-10-20

Electron, which can wrap web page programs into desktop applications

Tutorial for beginners of small programs day01

八大排序(二)

Express - static resource request

Talk about how the kotlin collaboration process establishes structured concurrency

【新书推荐】MongoDB Performance Tuning

Distributed ID

Idea shortcut key settings
随机推荐
Numpy (time date and time increment)
Niuke rearrangement rule taking method
八大排序(二)
Express - static resource request
ReturnJson,让返回数据多一些自定义数据或类名
JVM tuning tool commands (notes)
AutoUpdater. Net client custom update file
Acquisition de 100% des actions de Guilin latex par Guilin Robust Medical pour combler le vide de la gamme de produits Latex
12. problem set: process, thread and JNI architecture
Niuke walks on the tree (ingenious application of parallel search)
【Ubuntu-MySQL8安装与主从复制】
Golang magic code
小程序手持弹幕的原理及实现(uni-app)
11.自定义hooks
oracle跨数据库复制数据表-dblink
JVM memory common parameter configuration set
直播带货源码开发中,如何降低直播中的延迟?
MySQL优化
Talk about the kotlin cooperation process and the difference between job and supervisorjob
Concatapter tutorial