当前位置:网站首页>Realbasicvsr test pictures and videos
Realbasicvsr test pictures and videos
2022-07-07 13:11:00 【cv-daily】
Code :https://github.com/ckkelvinchan/RealBasicVSR
RealBasicVSR Test pictures and videos are always reported out of memory, Insufficient memory , But it needs testing , Modify the code .
The problem is : Test two at a time 1080p Graph , There is not enough report storage . a sheet 1080p Pictures of report errors
Traceback (most recent call last):
File "inference_realbasicvsr.py", line 167, in <module>
main()
File "inference_realbasicvsr.py", line 134, in main
outputs = model(inputs, test_mode=True)['output'].cpu()
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmcv/runner/fp16_utils.py", line 116, in new_func
return old_func(*args, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/restorers/srgan.py", line 95, in forward
return self.forward_test(lq, gt, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/restorers/real_esrgan.py", line 212, in forward_test
output = _model(lq)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/real_basicvsr_net.py", line 87, in forward
outputs = self.basicvsr(lqs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/basicvsr_net.py", line 126, in forward
flows_forward, flows_backward = self.compute_flow(lrs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/basicvsr_net.py", line 98, in compute_flow
flows_backward = self.spynet(lrs_1, lrs_2).view(n, t - 1, 2, h, w)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/basicvsr_net.py", line 346, in forward
input=self.compute_flow(ref, supp),
File "anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/basicvsr_net.py", line 281, in compute_flow
F.avg_pool2d(
RuntimeError: non-empty 3D or 4D input tensor expected but got ndim: 4
problem :
anaconda3/envs/realbasicvsr/lib/python3.8/site-packages/mmedit/models/backbones/sr_backbones/basicvsr_net.py At least two pictures are required inside . Modify the code
def compute_flow(self, lrs):
"""Compute optical flow using SPyNet for feature warping. Note that if the input is an mirror-extended sequence, 'flows_forward' is not needed, since it is equal to 'flows_backward.flip(1)'. Args: lrs (tensor): Input LR images with shape (n, t, c, h, w) Return: tuple(Tensor): Optical flow. 'flows_forward' corresponds to the flows used for forward-time propagation (current to previous). 'flows_backward' corresponds to the flows used for backward-time propagation (current to next). """
n, t, c, h, w = lrs.size()
if t==1:
lrs_1 = lrs[:, 0, :, :, :].reshape(-1, c, h, w)
lrs_2 = lrs[:, 0, :, :, :].reshape(-1, c, h, w)
flows_backward = self.spynet(lrs_1, lrs_2).view(n, 1, 2, h, w)
if self.is_mirror_extended: # flows_forward = flows_backward.flip(1)
flows_forward = None
else:
flows_forward = self.spynet(lrs_2, lrs_1).view(n, 1, 2, h, w)
else:
lrs_1 = lrs[:, :-1, :, :, :].reshape(-1, c, h, w)
lrs_2 = lrs[:, 1:, :, :, :].reshape(-1, c, h, w)
flows_backward = self.spynet(lrs_1, lrs_2).view(n, t - 1, 2, h, w)
if self.is_mirror_extended: # flows_forward = flows_backward.flip(1)
flows_forward = None
else:
flows_forward = self.spynet(lrs_2, lrs_1).view(n, t - 1, 2, h, w)
return flows_forward, flows_backward
modify inference_realbasicvsr.py
import argparse
import glob
import os
import cv2
import mmcv
import numpy as np
import torch
from mmcv.runner import load_checkpoint
from mmedit.core import tensor2img
from realbasicvsr.models.builder import build_model
VIDEO_EXTENSIONS = ('.mp4', '.mov')
def parse_args():
parser = argparse.ArgumentParser(
description='Inference script of RealBasicVSR')
parser.add_argument('config', help='test config file path')
parser.add_argument('checkpoint', help='checkpoint file')
parser.add_argument('input_dir', help='directory of the input video')
parser.add_argument('output_dir', help='directory of the output video')
parser.add_argument(
'--max_seq_len',
type=int,
default=None,
help='maximum sequence length to be processed')
parser.add_argument(
'--is_save_as_png',
type=bool,
default=True,
help='whether to save as png')
parser.add_argument(
'--fps', type=float, default=25, help='FPS of the output video')
args = parser.parse_args()
return args
def init_model(config, checkpoint=None):
"""Initialize a model from config file. Args: config (str or :obj:`mmcv.Config`): Config file path or the config object. checkpoint (str, optional): Checkpoint path. If left as None, the model will not load any weights. device (str): Which device the model will deploy. Default: 'cuda:0'. Returns: nn.Module: The constructed model. """
if isinstance(config, str):
config = mmcv.Config.fromfile(config)
elif not isinstance(config, mmcv.Config):
raise TypeError('config must be a filename or Config object, '
f'but got {
type(config)}')
config.model.pretrained = None
config.test_cfg.metrics = None
model = build_model(config.model, test_cfg=config.test_cfg)
if checkpoint is not None:
checkpoint = load_checkpoint(model, checkpoint)
model.cfg = config # save the config in the model for convenience
model.eval()
return model
def main():
args = parse_args()
# initialize the model
model = init_model(args.config, args.checkpoint)
# read images
file_extension = os.path.splitext(args.input_dir)[1]
if file_extension in VIDEO_EXTENSIONS: # input is a video file
print("11111")
video_reader = mmcv.VideoReader(args.input_dir)
inputs = []
i=0
for frame in video_reader:
if i==0 or i==1:
inputs.append(np.flip(frame, axis=2))
i=i+1
elif file_extension == '': # input is a directory
print("22222")
input_paths = sorted(glob.glob(f'{
args.input_dir}/*'))
index_img=0
for input_path in input_paths:
inputs = []
torch.cuda.empty_cache()
img = mmcv.imread(input_path, channel_order='rgb')
inputs.append(img)
for i, img in enumerate(inputs):
img = torch.from_numpy(img / 255.).permute(2, 0, 1).float()
inputs[i] = img.unsqueeze(0)
inputs = torch.stack(inputs, dim=1)
# inputs=torch.unsqueeze(inputs, 1)
print("inputs", inputs.shape)
# map to cuda, if available
cuda_flag = False
if torch.cuda.is_available():
model = model.cuda()
cuda_flag = True
with torch.no_grad():
if isinstance(args.max_seq_len, int):
outputs = []
for i in range(0, inputs.size(1), args.max_seq_len):
imgs = inputs[:, i:i + args.max_seq_len, :, :, :]
if cuda_flag:
imgs = imgs.cuda()
outputs.append(model(imgs, test_mode=True)['output'].cpu())
outputs = torch.cat(outputs, dim=1)
else:
if cuda_flag:
inputs = inputs.cuda()
outputs = model(inputs, test_mode=True)['output'].cpu()
if os.path.splitext(args.output_dir)[1] in VIDEO_EXTENSIONS:
output_dir = os.path.dirname(args.output_dir)
mmcv.mkdir_or_exist(output_dir)
h, w = outputs.shape[-2:]
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
video_writer = cv2.VideoWriter(args.output_dir, fourcc, args.fps,
(w, h))
for i in range(0, outputs.size(1)):
img = tensor2img(outputs[:, i, :, :, :])
video_writer.write(img.astype(np.uint8))
cv2.destroyAllWindows()
video_writer.release()
else:
mmcv.mkdir_or_exist(args.output_dir)
for i in range(0, outputs.size(1)):
output = tensor2img(outputs[:, i, :, :, :])
# filename = os.path.basename(input_paths[i])
filename = os.path.basename(input_paths[index_img])
print("filename", filename)
if args.is_save_as_png:
file_extension = os.path.splitext(filename)[1]
filename = filename.replace(file_extension, '.png')
mmcv.imwrite(output, f'{
args.output_dir}/{
filename}')
index_img=index_img+1
else:
print("33333")
raise ValueError('"input_dir" can only be a video or a directory.')
if __name__ == '__main__':
main()
边栏推荐
- [learning notes] segment tree selection
- Conversion from non partitioned table to partitioned table and precautions
- Query whether a field has an index with MySQL
- PACP学习笔记三:PCAP方法说明
- Go语言学习笔记-结构体(Struct)
- Initialization script
- 【无标题】
- 如何让electorn打开的新窗口在window任务栏上面
- 靠卖概念上市,认养一头牛能走多远?
- @What is the difference between resource and @autowired?
猜你喜欢
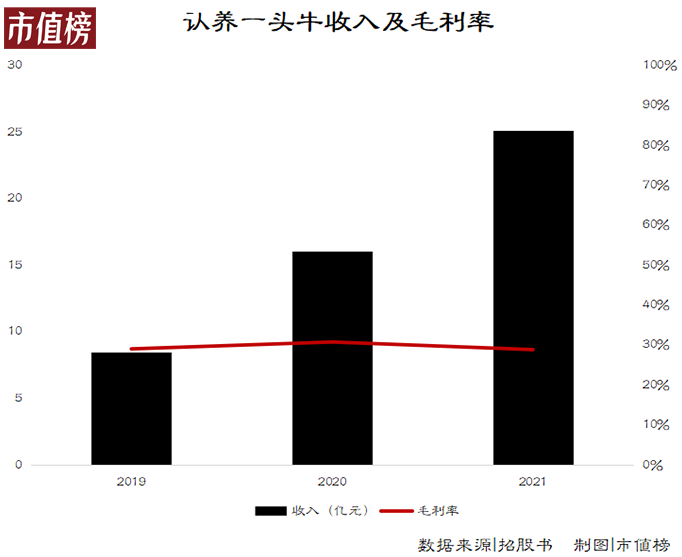
靠卖概念上市,认养一头牛能走多远?

Cinnamon Applet 入门

Star Enterprise Purdue technology layoffs: Tencent Sequoia was a shareholder who raised more than 1billion

日本政企员工喝醉丢失46万信息U盘,公开道歉又透露密码规则
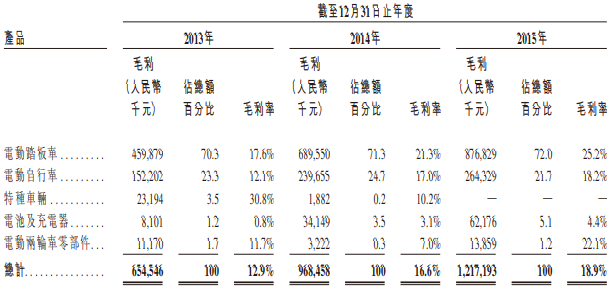
高端了8年,雅迪如今怎么样?
Vscode编辑器ESP32头文件波浪线不跳转彻底解决
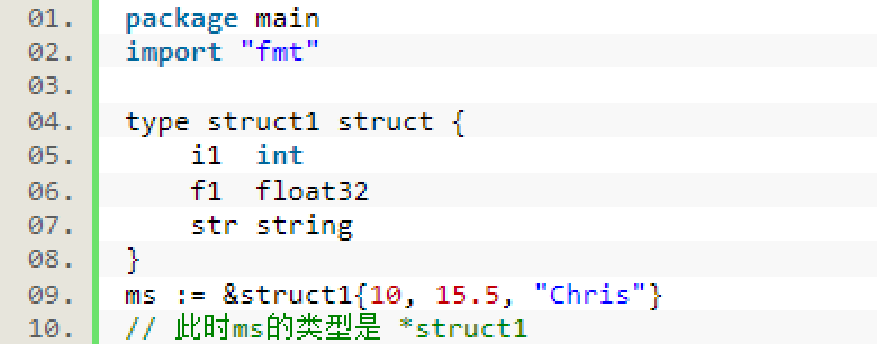
Go语言学习笔记-结构体(Struct)
详细介绍六种开源协议(程序员须知)

COSCon'22 社区召集令来啦!Open the World,邀请所有社区一起拥抱开源,打开新世界~

达晨与小米投的凌云光上市:市值153亿 为机器植入眼睛和大脑
随机推荐
MATLAB中polarscatter函数使用
RealBasicVSR测试图片、视频
通过Keil如何查看MCU的RAM与ROM使用情况
Differences between MySQL storage engine MyISAM and InnoDB
信号强度(RSSI)知识整理
Awk of three swordsmen in text processing
How to reset Google browser? Google Chrome restore default settings?
centso7 openssl 报错Verify return code: 20 (unable to get local issuer certificate)
Initialization script
JS determines whether an object is empty
日本政企员工喝醉丢失46万信息U盘,公开道歉又透露密码规则
MongoDB 分片总结
迅为iTOP-IMX6ULL开发板Pinctrl和GPIO子系统实验-修改设备树文件
高瓴投的澳斯康生物冲刺科创板:年营收4.5亿 丢掉与康希诺合作
Analysis of DHCP dynamic host setting protocol
关于 appium 启动 app 后闪退的问题 - (已解决)
国泰君安证券开户怎么开的?开户安全吗?
Grep of three swordsmen in text processing
DETR介绍
Conversion from non partitioned table to partitioned table and precautions