当前位置:网站首页>4D line-by-line analysis and implementation of Transformer, and German translation into English (3)
4D line-by-line analysis and implementation of Transformer, and German translation into English (3)
2022-08-01 04:50:00 【iioSnail】
本文由于长度限制,共分为三篇:
- 万字逐行解析与实现Transformer,并进行German to English实战(一)
- 万字逐行解析与实现Transformer,并进行German to English实战(二)
- 万字逐行解析与实现Transformer,并进行German to English实战(三)
你也可以在该项目找到本文的源码.
Part 3: 实战:German to English
Now let's go to a practical case,我们使用Multi30k German-English 翻译任务.Although this task is much smaller than that in the paperWMT任务,But also enough to shed light on the whole system.
数据加载
我们将使用torchtext进行数据加载,并使用spacy进行分词.spacy可以参考这篇文章.
Be sure to use both versions when loading datasets
torchdata==0.3.0, torchtext==0.12,否则会加载失败.
加载分词模型,如果你还没有下载,Please use the following code to download(also in the code):
python -m spacy download de_core_news_sm
python -m spacy download en_core_web_sm
If the download fails using the command in China,Please use offline download.(Note that the version needs to be3.2.0)de_core_news_sm下载链接,en_core_web_sm下载链接
def load_tokenizers():
""" 加载spacy分词模型 :return: Returns the German word segmentation model and the English word segmentation model """
try:
spacy_de = spacy.load("de_core_news_sm")
except IOError:
# 如果报错,Indicates that the word segmentation model has not been installed,Reload after installation
os.system("python -m spacy download de_core_news_sm")
spacy_de = spacy.load("de_core_news_sm")
try:
spacy_en = spacy.load("en_core_web_sm")
except IOError:
os.system("python -m spacy download en_core_web_sm")
spacy_en = spacy.load("en_core_web_sm")
# Returns the German word segmentation model and the English word segmentation model
return spacy_de, spacy_en
def tokenize(text, tokenizer):
""" 对text文本进行分词 :param text: The text to tokenize,例如“I love you” :param tokenizer: 分词模型,例如:spacy_en :return: 分词结果,例如 ["I", "love", "you"] """
return [tok.text for tok in tokenizer.tokenizer(text)]
def yield_tokens(data_iter, tokenizer, index):
""" yield一个token list :param data_iter: Iterable object containing sentence pairs.例如: [("I love you", "我爱你"), ...] :param tokenizer: 分词模型.例如spacy_en :param index: Which language of the sentence pair is to be tokenized, 例如0Indicates word segmentation of the English in the above example :return: yieldThe word segmentation result of this round,例如['I', 'love', 'you'] """
for from_to_tuple in data_iter:
yield tokenizer(from_to_tuple[index])
def build_vocabulary(spacy_de, spacy_en):
""" Build German and English dictionaries :return: Returns German dictionaries and English dictionaries,均为:Vocab对象 VocabThe official address of the subject is :https://pytorch.org/text/stable/vocab.html#vocab """
# Build a German word segmentation method
def tokenize_de(text):
return tokenize(text, spacy_de)
# Build an English word segmentation method
def tokenize_en(text):
return tokenize(text, spacy_en)
print("Building German Vocabulary ...")
""" 其中train, val, test都是可迭代对象. 例如:next(iter(train)) 返回一个tuple,为: ('Zwei junge weiße Männer sind im Freien in der Nähe vieler Büsche.', 'Two young, White males are outside near many bushes.') """
train, val, test = datasets.Multi30k(language_pair=("de", "en"))
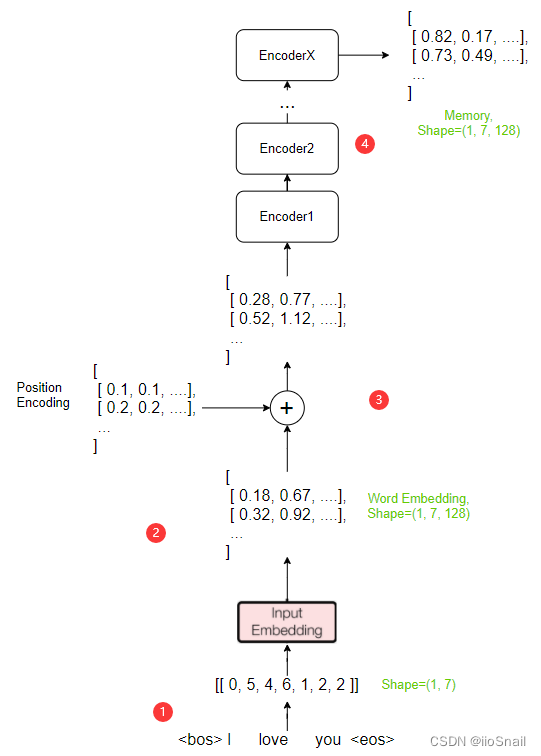
""" build_vocab_from_iterator:Generates a dictionary from an iterable object. 其返回一个Vocab对象,官方地址为:https://pytorch.org/text/stable/vocab.html#vocab It receives three parameters 1. iterator,You need to pass in an iterable object.It contains the data of good words,例如: [("I", "love", "you"), ("you", "love", "me")] 2. min_freq,最小频率,When the frequency of a word reaches the minimum frequency, it will be used into the dictionary.例如,如果min_freq=2,In the above example only“you” will be counted in the dictionary,Because all other words appear only once. 3.specials, 特殊词汇,例如'<bos>', '<unk>'等.Special words are added top of the dictionary. Suppose we call is: vocab = build_vocab_from_iterator( [("I", "love", "you"), ("you", "love", "me")], min_freq=1, specials=["<s>", "</s>"], ) vocabThe corresponding dictionary is :{0:<s>, 1:</s>, 2:love, 3:you, 4:I, 5:me} """
vocab_src = build_vocab_from_iterator(
yield_tokens(train + val + test, tokenize_de, index=0),
min_freq=2,
specials=["<s>", "</s>", "<blank>", "<unk>"],
)
# Start building an English dictionary,与上面一样
print("Building English Vocabulary ...")
train, val, test = datasets.Multi30k(language_pair=("de", "en"))
vocab_tgt = build_vocab_from_iterator(
yield_tokens(train + val + test, tokenize_en, index=1),
min_freq=2,
specials=["<s>", "</s>", "<blank>", "<unk>"],
)
# 设置默认index为`<unk>`,Afterwards, those words that are not known will be automatically classified`<unk>`
vocab_src.set_default_index(vocab_src["<unk>"])
vocab_tgt.set_default_index(vocab_tgt["<unk>"])
# Returns the constructed German dictionary and English dictionary
return vocab_src, vocab_tgt
def load_vocab(spacy_de, spacy_en):
""" Load German dictionaries and English dictionaries.Since the process of building a dictionary takes a certain amount of time, So the method is rightbuild_vocabulary的进一步封装,增加了缓存机制. :return: Returns German dictionaries and English dictionaries,均为Vocab对象 """
# If no cache file exists,Description is the first time the dictionary is built
if not exists("vocab.pt"):
# 构建词典,and write to the cache file
vocab_src, vocab_tgt = build_vocabulary(spacy_de, spacy_en)
torch.save((vocab_src, vocab_tgt), "vocab.pt")
else:
# 如果存在缓存文件,直接加载
vocab_src, vocab_tgt = torch.load("vocab.pt")
# 输出些日志:
print("Finished.\nVocabulary sizes:")
print("vocab_src size:", len(vocab_src))
print("vocab_tgt size:", len(vocab_tgt))
return vocab_src, vocab_tgt
# 全局参数,Will be used later
# Load German and English tokenizers
spacy_de, spacy_en = load_tokenizers()
# Load the German dictionary(source dictionary)and English dictionary(target dictionary)
vocab_src, vocab_tgt = load_vocab(spacy_de, spacy_en)
Building German Vocabulary ...
Building English Vocabulary ...
Finished.
Vocabulary sizes:
vocab_src size: 8315
vocab_tgt size: 6384
Iterators
def collate_batch(
batch,
src_pipeline,
tgt_pipeline,
src_vocab,
tgt_vocab,
device,
max_padding=128,
pad_id=2,
):
""" Dataloader中的collate_fn函数.该函数的作用是:Process text sentences into numerical sentences,然后pad到固定长度,最终batch到一起 :param batch: 一个batchstatement pair.例如: [('Ein Kleinkind ...', 'A toddler in ...'), # [(德语), (英语) .... # ... ...] # ... ] :param src_pipeline: German tokenizer,也就是tokenize_de方法,后面会定义 其实就是对spacy_de的封装 :param tgt_pipeline: 英语分词器,也就是tokenize_en方法 :param src_vocab: German dictionary,Vocab对象 :param tgt_vocab: 英语词典,Vocab对象 :param device: cpu或cuda :param max_padding: 句子的长度.padSentences of insufficient length and sentences that are too long to be trimmed, The purpose is to allow sentences of different lengths to form onetensor :param pad_id: '<blank>'在词典中对应的index :return: src和tgt.After processingbatch后的句子.例如: src为:[[0, 4354, 314, ..., 1, 2, 2, ..., 2], [0, 4905, 8567, ..., 1, 2, 2, ..., 2]] 其中0是<bos>, 1是<eos>, 2是<blank> src的Shape为(batch_size, max_padding) tgt同理. """
# 定义'<bos>'的index,in the dictionary as0,所以这里也是0
bs_id = torch.tensor([0], device=device) # <s> token id
# 定义'<eos>'的index
eos_id = torch.tensor([1], device=device) # </s> token id
# Used to store processed onessrc和tgt
src_list, tgt_list = [], []
# Loop over sentence pairs
for (_src, _tgt) in batch:
""" _src: German sentences,例如:Ein Junge wirft Blätter in die Luft. _tgt: 英语句子,例如:A boy throws leaves into the air. """
""" 将句子进行分词,and convert the words into corresponding onesindex.例如: "I love you" -> ["I", "love", "you"] -> [1136, 2468, 1349] -> [0, 1136, 2468, 1349, 1] 其中0,1是<bos>和<eos>. Vocab对象可以将listThe words in are converted toindex,例如: `vocab_tgt(["I", "love", "you"])` 的输出为: [1136, 2468, 1349] """
processed_src = torch.cat(
# 将<bos>,句子index和<eos>拼到一块
[
bs_id,
torch.tensor(
# 进行分词后,转换为index.
src_vocab(src_pipeline(_src)),
dtype=torch.int64,
device=device,
),
eos_id,
],
0,
)
processed_tgt = torch.cat(
[
bs_id,
torch.tensor(
tgt_vocab(tgt_pipeline(_tgt)),
dtype=torch.int64,
device=device,
),
eos_id,
],
0,
)
""" Fill in sentences with insufficient lengthmax_padding的长度的,Then add tolist中 pad:假设processed_src为[0, 1136, 2468, 1349, 1] 第二个参数为: (0, 72-5) 第三个参数为:2 则pad的意思表示,给processed_src左边填充0个2,右边填充67个2. 最终结果为:[0, 1136, 2468, 1349, 1, 2, 2, 2, ..., 2] """
src_list.append(
pad(
processed_src,
(0, max_padding - len(processed_src),),
value=pad_id,
)
)
tgt_list.append(
pad(
processed_tgt,
(0, max_padding - len(processed_tgt),),
value=pad_id,
)
)
# 将多个srcSentences are stacked together
src = torch.stack(src_list)
tgt = torch.stack(tgt_list)
# 返回batch后的结果
return (src, tgt)
def create_dataloaders(
device,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
batch_size=12000,
max_padding=128
):
""" 创建train_dataloader和valid_dataloader :param device: cpu或cuda :param vocab_src: source dictionary,In this case, a German dictionary :param vocab_tgt: target dictionary,In this case, an English dictionary :param spacy_de: German tokenizer :param spacy_en: 英语分词器 :param batch_size: batch_size :param max_padding: 句子的最大长度 :return: train_dataloader和valid_dataloader """
# Define the German tokenizer
def tokenize_de(text):
return tokenize(text, spacy_de)
# Define the English tokenizer
def tokenize_en(text):
return tokenize(text, spacy_en)
# Create batch tools,i.e. how should a batch of data be aggregated into oneBatch
def collate_fn(batch):
return collate_batch(
batch,
tokenize_de,
tokenize_en,
vocab_src,
vocab_tgt,
device,
max_padding=max_padding,
pad_id=vocab_src.get_stoi()["<blank>"],
)
# 加载数据集
train_iter, valid_iter, test_iter = datasets.Multi30k(
language_pair=("de", "en")
)
""" 将Iterator类型的Dataset转为Map类型的Dataset.如果你不熟悉,可以参考: https://blog.csdn.net/zhaohongfei_358/article/details/122742656 经过测试,It turns out that it doesn't actually turn.效果没差别 """
train_iter_map = to_map_style_dataset(train_iter)
valid_iter_map = to_map_style_dataset(valid_iter)
# 构建DataLoader,若DataLoader不熟悉,请参考文章:
# https://blog.csdn.net/zhaohongfei_358/article/details/122742656
train_dataloader = DataLoader(
train_iter_map,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_fn,
)
valid_dataloader = DataLoader(
valid_iter_map,
batch_size=batch_size,
shuffle=True,
collate_fn=collate_fn,
)
return train_dataloader, valid_dataloader
训练模型
def train_worker(
device,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
config,
is_distributed=False,
):
""" 训练模型 :param device: cpu或cuda :param vocab_src: source dictionary,In this case, a German dictionary :param vocab_tgt: target dictionary,In this case, an English dictionary :param spacy_de: German tokenizer :param spacy_en: 英语分词器 :param config: One holds configuration parametersdict,Like learning rate or something """
print(f"Train worker process using device: {
device} for training")
# Find the target dictionary‘<blank>’所对应的index
pad_idx = vocab_tgt["<blank>"]
# Set the word vector size.
d_model = 512
# 构建模型,Layer数为6
model = make_model(len(vocab_src), len(vocab_tgt), N=6)
model.to(device)
# 定义损失函数
criterion = LabelSmoothing(
size=len(vocab_tgt), padding_idx=pad_idx, smoothing=0.1
)
criterion.to(device)
# 创建train_dataloader和valid_dataloader
train_dataloader, valid_dataloader = create_dataloaders(
device,
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
batch_size=config["batch_size"],
max_padding=config["max_padding"]
)
# 创建Adam优化器
optimizer = torch.optim.Adam(
model.parameters(), lr=config["base_lr"], betas=(0.9, 0.98), eps=1e-9
)
# 定义Warmup学习率策略
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, d_model, factor=1, warmup=config["warmup"]
),
)
# 创建train_state,Save the training state
train_state = TrainState()
# 开始训练
for epoch in range(config["num_epochs"]):
model.train()
print(f"[Epoch {
epoch} Training ====", flush=True)
_, train_state = run_epoch(
(Batch(b[0], b[1], pad_idx) for b in train_dataloader),
model,
SimpleLossCompute(model.generator, criterion),
optimizer,
lr_scheduler,
mode="train+log",
accum_iter=config["accum_iter"],
train_state=train_state,
)
""" 展示GPU使用情况,例如: | ID | GPU | MEM | ------------------ | 0 | 11% | 6% | """
if torch.cuda.is_available():
GPUtil.showUtilization()
# 每训练一个epoch保存一次模型
file_path = "%s%.2d.pt" % (config["file_prefix"], epoch)
torch.save(model.state_dict(), file_path)
if torch.cuda.is_available():
torch.cuda.empty_cache()
# 在一个epoch后,进行模型验证
print(f"[Epoch {
epoch} Validation ====")
model.eval()
# Run the data in the validation set,看看loss有多少
sloss = run_epoch(
(Batch(b[0], b[1], pad_idx) for b in valid_dataloader),
model,
SimpleLossCompute(model.generator, criterion),
DummyOptimizer(),
DummyScheduler(),
mode="eval",
)
# 打印验证集的Loss
print("Validation Loss:", sloss[0].data)
if torch.cuda.is_available():
torch.cuda.empty_cache()
# 全部epoch训练完毕后,保存模型
file_path = "%sfinal.pt" % config["file_prefix"]
torch.save(model.state_dict(), file_path)
def load_trained_model():
""" Load a model or train a model. If no model is found,Indicates that there is no training,则进行训练 :return: Transformer对象,即EncoderDecoder类对象 """
# Define some model training parameters
config = {
"batch_size": 32,
"num_epochs": 8, # epoch数量
"accum_iter": 10, # 每10个batch更新一次模型参数
"base_lr": 1.0, # 基础学习率,according to this learning ratewarmup
"max_padding": 72, # 句子的最大长度
"warmup": 3000, # Warmup3000次,也就是从第3000The learning rate starts to decrease
"file_prefix": "multi30k_model_", # Model file prefix name
}
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model_path = "multi30k_model_final.pt"
# 如果模型不存在,then train a model
if not exists(model_path):
train_worker(device, vocab_src, vocab_tgt, spacy_de, spacy_en, config)
# 初始化模型实例
model = make_model(len(vocab_src), len(vocab_tgt), N=6)
# 加载模型参数
model.load_state_dict(torch.load("multi30k_model_final.pt"))
return model
# Load or train the model
model = load_trained_model()
Train worker process using device: cuda for training
[Epoch 0 Training ====
Epoch Step: 1 | Accumulation Step: 1 | Loss: 7.65 | Tokens / Sec: 2701.9 | Learning Rate: 5.4e-07
...略
Epoch Step: 881 | Accumulation Step: 89 | Loss: 1.03 | Tokens / Sec: 2758.8 | Learning Rate: 5.2e-04
| ID | GPU | MEM |
------------------
| 0 | 57% | 29% |
[Epoch 7 Validation ====
Validation Loss: tensor(1.4455, device='cuda:0')
测试结果
At the end we can simply test our model using the validation set
# Load data and model for output checks
def check_outputs(
valid_dataloader,
model,
vocab_src,
vocab_tgt,
n_examples=15,
pad_idx=2,
eos_string="</s>",
):
results = [()] * n_examples
for idx in range(n_examples):
print("\nExample %d ========\n" % idx)
b = next(iter(valid_dataloader))
rb = Batch(b[0], b[1], pad_idx)
greedy_decode(model, rb.src, rb.src_mask, 64, 0)[0]
src_tokens = [
vocab_src.get_itos()[x] for x in rb.src[0] if x != pad_idx
]
tgt_tokens = [
vocab_tgt.get_itos()[x] for x in rb.tgt[0] if x != pad_idx
]
print(
"Source Text (Input) : "
+ " ".join(src_tokens).replace("\n", "")
)
print(
"Target Text (Ground Truth) : "
+ " ".join(tgt_tokens).replace("\n", "")
)
model_out = greedy_decode(model, rb.src, rb.src_mask, 72, 0)[0]
model_txt = (
" ".join(
[vocab_tgt.get_itos()[x] for x in model_out if x != pad_idx]
).split(eos_string, 1)[0]
+ eos_string
)
print("Model Output : " + model_txt.replace("\n", ""))
results[idx] = (rb, src_tokens, tgt_tokens, model_out, model_txt)
return results
def run_model_example(n_examples=5):
global vocab_src, vocab_tgt, spacy_de, spacy_en
print("Preparing Data ...")
_, valid_dataloader = create_dataloaders(
torch.device("cpu"),
vocab_src,
vocab_tgt,
spacy_de,
spacy_en,
batch_size=1,
is_distributed=False,
)
print("Loading Trained Model ...")
model = make_model(len(vocab_src), len(vocab_tgt), N=6)
model.load_state_dict(
torch.load("multi30k_model_final.pt", map_location=torch.device("cpu"))
)
print("Checking Model Outputs:")
example_data = check_outputs(
valid_dataloader, model, vocab_src, vocab_tgt, n_examples=n_examples
)
return model, example_data
run_model_example()
-------完结,撒花--------
边栏推荐
- ICML2022 | Deep Dive into Permutation-Sensitive Graph Neural Networks
- Game Theory (Depu) and Sun Tzu's Art of War (42/100)
- LeetCode 387. 字符串中的第一个唯一字符
- 基于STM32设计的UNO卡牌游戏(双人、多人对战)
- Write a method to flatten an array and deduplicate and sort it incrementally
- 2022-07-31: Given a graph with n points and m directed edges, you can use magic to turn directed edges into undirected edges, such as directed edges from A to B, with a weight of 7.After casting the m
- II. Binary tree to Offer 68 - recent common ancestor
- Swastika line-by-line parsing and realization of the Transformer, and German translation practice (2)
- 【无标题】
- Passive anti-islanding-UVP/OVP and UFP/OFP passive anti-islanding model simulation based on simulink
猜你喜欢






随机推荐
数据比对功能调研总结
Swastika line-by-line parsing and realization of the Transformer, and German translation practice (2)
Dynamic Programming 01 Backpack
【愚公系列】2022年07月 Go教学课程 024-函数
挑战52天背完小猪佩奇(第01天)
一个往年的朋友
Excel record of integer programming optimization model to solve the problem
typescript19-对象可选参数
PMP 项目沟通管理
基于STM32设计的UNO卡牌游戏(双人、多人对战)
(Codeforce 757)E. Bash Plays with Functions(积性函数)
云服务器下载安装mongo数据库并远程连接详细图文版本(全)
typescript21 - Comparison of Interfaces and Type Aliases
律师解读 | 枪炮还是玫瑰?从大厂之争谈元宇宙互操作性
Game Theory (Depu) and Sun Tzu's Art of War (42/100)
时时刻刻保持敬畏之心
报错:AttributeError: module ‘matplotlib’ has no attribute ‘figure’
LeetCode 9. 回文数
The Flow Of Percona Toolkit pt-table-checksum
状态压缩dp