当前位置:网站首页>Can you learn fast and well with dual stream network? Harbin Institute of Technology & Microsoft proposed a distillation dual encoder model for visual language understanding, which can achieve fast an
Can you learn fast and well with dual stream network? Harbin Institute of Technology & Microsoft proposed a distillation dual encoder model for visual language understanding, which can achieve fast an
2022-07-26 06:51:00 【I love computer vision】
Official account , Find out CV The beauty of Technology
This sharing paper 『Distilled Dual-Encoder Model for Vision-Language Understanding』, You can learn fast and well with dual stream network ? Harbin Institute of technology & Microsoft proposed a distillation dual encoder model for visual language understanding , Achieve fast and good results on multiple multimodal tasks !
The details are as follows :

Address of thesis :https://arxiv.org/abs/2112.08723
Code address :https://github.com/kugwzk/Distilled-DualEncoder
01
Abstract
In this paper, a cross modal attention distillation framework is proposed to train the dual encoder model for visual language understanding tasks , Such as visual reasoning and visual question answering . The dual encoder model has faster reasoning speed than the fusion encoder model , And it can pre calculate the image and text in the reasoning process . However , The shallow interaction module used in the dual encoder model is not enough to deal with complex visual language understanding tasks .
In order to learn the deep interaction between image and text , The author proposes a cross modal attention distillation , It uses the attention distribution of image to text and text to image fused with the encoder model to guide the dual encoder training model . Besides , The author shows , Further improvements can be achieved by applying cross modal attention distillation in the pre training and fine-tuning stages . Experimental results show that , After distillation, the double encoder model is used in visual reasoning 、 Vision entailment And visual question and answer tasks have achieved competitive performance , At the same time, it has faster reasoning speed than the fusion encoder model .
02
Motivation
Visual language (VL) The pre training model learns large-scale images - Cross modal representation of text pairs , And it can be directly fine tuned to adapt to various downstream VL Mission , For example, visual language understanding / classification ( Visual reasoning 、 Visual Q & A, etc ) Image text retrieval . Method based on cross modal interaction , These models can be divided into two categories .
The first category is Fusion encoder model , It uses effective but less efficient Transformer Encoder , For capturing image and text interactions with cross modal attention . Most models in this category rely on ready-made target detectors to extract image region features , This further hinders their efficiency . lately ,ViLT Gave up the detector , And use Vision Transformer Directly to the image patch Encoding .
It improves efficiency while , stay VL Have achieved competitive performance in understanding and retrieval tasks . However , Due to the need to encode images and text at the same time , be based on Transformer Cross modal interaction is still the bottleneck of efficiency , It limits its application in tasks with a large number of image or text candidates .
The second kind of works , Include CLIP and ALIGN, use Dual encoder architecture Encode image and text respectively . Cross modal interaction is modeled by shallow fusion modules , It's usually a multi-layer perceptron (MLP) Network or dot product , And fusion encoder model Transformer Encoder comparison , It's very light . Besides , Separate encoding supports offline computing and caching of image and text candidates , This can be well extended to a large number of candidates .
These changes reduce the faster reasoning speed in understanding and retrieval tasks , Make the model practical in real life . The dual encoder model has achieved gratifying performance in the task of image text retrieval . The dual encoder model has achieved gratifying performance in the task of image text retrieval . However , They are far behind the fusion encoder model in the task of visual language understanding that requires complex cross modal reasoning , for example NLVR2.
In this work , The author proposes a cross modal attention distillation framework to train the dual encoder visual language model . The distilled dual encoder model achieves competitive performance in visual language understanding tasks , Its reasoning speed is much faster than the fusion encoder model .
Except for soft label distillation , The author also introduces cross modal attention distillation as a dual encoder model ( Student ) Fine grained supervision , To better learn cross modal reasoning . say concretely , Use models from fusion coders ( Teachers' ) Image to text and text to image attention distribution are distilled .
The distillation framework of this paper can be applied to the pre training and fine-tuning stages . During pre training , The distillation target is applied to the tasks of image text contrast learning and image text matching . In the fine-tuning phase , Transfer the task specific knowledge of the fine tuned teacher model to the student model .
The author evaluates the model in visual language understanding task and image text retrieval task . Experimental results show that , Distillation of the dual encoder model in vision entailment、 Competitive in visual reasoning and visual question answering , At the same time, the reasoning speed is faster than the fusion algorithm 3 More than times . Encoder teacher model .
Besides , The cross modal attention distillation proposed in this paper also improves the performance of retrieval tasks , Even better than the teacher model in image retrieval . Compared with other potential features , Cross modal attention helps the dual encoder model learn better cross modal reasoning ability , stay VL Gain significant benefits from understanding tasks . Besides , The two-stage distillation model has better performance than the single-stage distillation model .
03
Method

The above figure shows the cross modal attention distillation framework used to train the dual encoder model in this paper . The author uses the fusion encoder model as a teacher , Cross modal attention knowledge and soft tags are introduced to train the dual encoder student model . Distillation goals are applicable to pre training and fine-tuning stages , And help the dual encoder model learn the interaction of different modes .
3.1 Model Overview
The distillation framework of this paper can use different fusion encoder models as teachers . In this work , In this paper ViLT Experiment as a teacher model , Because it is simple and efficient .
Input Representations
Given an image - The text is right (v, t) As input , The image Divided into patch, among yes patch The number of , (H, W) Is the input image resolution ,(P, P) Is each patch The resolution of the ,C Number of channels .
Input text t By WordPiece Marked as M Subword token Sequence , As in the BERT In the same . then , Will be special token And are added to the image patch And text subwords token In sequence .
Linear projection image patch In order to obtain patch The embedded , The final visual input embedding is calculated in the following way :

among It's a linear projection , It's learnable 1D Position insertion , Is visual type embedding , Is text input embedded .
Text input embedded By embedding words 、 Text position embedding and text type embedding are added to get :
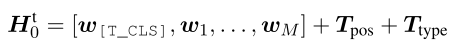
Will be used as visual and textual input for teacher and student models .
Teacher: Fusion-Encoder Model
Input representation and concat by , Then feed the vector to L Layer span mode Transformer Encoder to get context representation :

among . Cross modal Transformer The encoder fuses the representations of different modes through the multi head attention mechanism . say concretely , For the first l Each head of the layer a, , Attention distribution Calculate :

Among them, query And keys are obtained by using the hidden state of one layer on the parametric linear projection respectively . It's the size of the attention head . On the last floor token The output vector of is fed to the task specific layer to obtain the prediction .
Student: Dual-Encoder Model
The dual model is based on vision and text Transformer The encoders of are respectively embedded into the vision () And text embedding () Encoding :

On the last floor token The output vector of is used as the final representation of image and text . The author adopts shallow module f To fuse these two expressions . about VQA And other visual language understanding tasks , modular f It's a MLP The Internet . For image and text retrieval , Use the dot product function to obtain the similarity score of the picture and text pair .
3.2 Distillation Objectives
Cross-Modal Attention Distillation
In order to improve the dual encoder model to capture the deeper interaction between image and text , The author uses the cross modal attention knowledge of the fused encoder model to guide the training of the dual encoder model . say concretely , The author uses the attention distribution of image to text and text to image to train the dual encoder model .
Fuse encoder teacher model to capture cross modal intersection through multi head attention mechanism . The whole attention distribution can be divided into two parts . Author use N and M To represent the length of image and text input . The first part is monomodal attention (
402 Payment Required
), It's for the same mode token Modeling interactions within .The second part is cross modal attention , Including the attention distribution from image to text () And text to image attention distribution (). Cross modal attention distribution captures the interaction between visual and text feature vectors .
Because the separate coding of the double encoder only simulates the same mode token Interaction , Therefore, the author introduces cross modal attention distillation to encourage the dual encoder model to imitate the image and text alignment of the fused encoder model . Dual encoder model Cross mode of ( Image to text and text to image ) The distribution of attention is calculated as follows :

Where is selfattention Visual query and key of the module . It is the query and key of text input . Recalculate the teacher's cross modal attention distribution in the same way , Instead of directly splitting the original distribution of attention . The transmodal attention distillation loss is calculated as follows :

Where is Kullback-Leibler The divergence . This paper only transfers the knowledge of cross modal attention at the last level of the teacher model .
Soft Label Distillation
In addition to imitating the distribution of cross modal attention , The author also uses the prediction of the teacher model as a soft label to improve students . The loss of soft label is calculated as follows :

Among them are the predictions of students and teachers logits
3.3 Two-Stage Distillation Framework
This paper uses the proposed knowledge distillation goal to train the dual encoder student model in a two-stage framework , Including pre training distillation and fine tuning distillation . In these two stages , The fusion encoder model helps the dual encoder model learn cross modal interaction .

As shown in the table above , The author trains the model with different goals according to the characteristics of the task .
3.3.1 Pre-Training Distillation
During pre training , Double encoder student model in large-scale images - Train the text up , To learn to have images - Text matching 、 Images - General cross modal representation of text comparison and mask language modeling tasks . Pre trained fusion encoder model ViLT As a teacher model .
Image-Text Matching (ITM)
The goal of image text matching is to predict whether the input image text matches . stay ViLT after , The author uses 0.5 The probability of replacing the matched image to construct a negative pair . The author in ITM Input pair uses cross modal attention distillation loss and soft label loss to train the dual encoder model .
Image-Text Contrastive Learning (ITC)
The author passes batch Internal negative sampling introduces contrast loss , To optimize the visual and textual representation of the shared space . Given a batch Of N Images - The text is right , You can get N Matching pairs and A negative pair . Images - Text contrast learning aims to predict matching pairs from all possible pairs .
The fusion encoder model needs to jointly encode each pair to obtain soft tags , This leads to secondary time complexity . therefore , The author only considers N Cross modal attention distribution calculated by matching pairs .
Masked Language Modeling (MLM)
Masked Language Modeling The goal is to learn from all others mask Of token To recover mask token. Author use BERT in 15% Of mask probability . In order to improve the training speed , Author use ground truth Tag to train MLM Task model .
3.3.2 Fine-Tuning Distillation
In the process of fine-tuning , The author uses the fine tuned ViLT As a teacher model , And carry out cross modal attention distillation on the downstream task data .
Vision-Language Understanding
For visual language understanding tasks , Such as visual reasoning and VQA, The author uses cross modal attention distillation and soft label loss to fine tune the student model .
Image-Text Retrieval
For retrieval tasks , The author in the teacher model and ground truth Label the cross modal attention distribution under the supervision of training students , For effective training .
04
experiment

The above table shows some data sets used in this method .

The above table shows the fine-tuning results of the three tasks . Compared with the previous dual encoder model ( Such as CLIP) comparison , The model in this paper achieves better performance in three visual language understanding tasks , Average score from 57.83 Up to 73.85. As can be seen from the table above , Performing distillation in the pre training and fine-tuning stages has made a positive contribution to the dual encoder model . And ViLT Compared with the direct fine-tuning of the initialized dual encoder model , The use of cross modal attention distillation during fine-tuning brings significant improvements .

In addition to visual language understanding tasks , The author also evaluates the method of this paper on the task of image text retrieval . The dual encoder student model in this paper is trained by cross modal attention distillation and contrast loss . The above table reports on Flickr30K The result of fine-tuning the model .
The dual encoder model in this paper achieves competitive performance with faster reasoning speed . This model is even better than the fusion encoder teacher model in image retrieval (ViLT). Besides , Experimental results show that , Cross modal attention distillation also improves the model of retrieval tasks .

The author evaluates the dual encoder model and ViLT Reasoning delay in visual language understanding tasks . Both models are in a single with the same superparameter P100 GPU On the assessment . Due to the dual encoder architecture , The author's model can cache image representation to reduce redundant computation . The average reasoning time and cache time of different tasks are shown in the table above .
The dual encoder model in this paper achieves faster reasoning speed in three tasks . Precomputed image representation further improves the reasoning speed , This is very effective for a large number of images and texts in real life .

The author studied the influence of different knowledge used in distillation . During fine-tuning, experiments were carried out on visual language understanding tasks with different distillation losses . The double encoder student model is made up of ViLT Direct initialization . The above table illustrates the results of cross task .
First , It can be found that distillation with soft labels achieves better performance than real labels . However , The model trained with soft tags is in NLVR2 The accuracy of the task is still relatively low . The author further combines the intermediate representation of the fused encoder model , To improve the performance of the dual encoder model . This paper uses hidden states and different attention distributions to compare .
In three tasks , Using attention distribution brings more improvements than hidden states . The author further discusses which part of attention distribution is more critical , Including cross modal attention and monomodal attention . Imitating teachers' cross modal attention distribution has made more improvements than the single-mode part , This proves that cross modal interaction is more important for visual language understanding .
The author also found that , Using only the cross modal attention distribution is better than using the entire attention distribution ( Cross modal + Single mode ) Perform better .

The author implements the proposed knowledge distillation method at the last level of teachers and students . In order to verify the effectiveness of extracting only at the last layer , Compare it with the layer by layer strategy . The results are shown in the table above . The last distillation strategy is NLVR2 and SNLI-VE Better performance on the task . Besides , Using only the last level of attention knowledge requires less computation . therefore , Using only the last layer is a more practical way to perform this article's cross modal attention distillation .
05
summary
In this work , The author introduces a cross modal attention distillation framework to improve the performance of the dual encoder model in visual language understanding tasks . Cross modal attention knowledge fused with encoder model , Including image to text and text to image attention distribution , To guide the training of dual encoder model .
Experimental results show that , The double encoder model after distillation is NLVR2、SNLI-VE and VQA Achieve competitive performance , At the same time, it has much faster reasoning speed than the fusion encoder model .
Reference material
[1]https://arxiv.org/abs/2112.08723
[2]https://github.com/kugwzk/Distilled-DualEncoder

END
Welcome to join 「 Visual language 」 Exchange group notes :VL

边栏推荐
- 【Star项目】小帽飞机大战(三)
- TCP protocol -- message format, connection establishment, reliable transmission, congestion control
- "Niuke | daily question" inverse Polish expression
- Introduce you to JVM from architecture
- 【Star项目】小帽飞机大战(四)
- vulnhub Lampião: 1
- Uitoolkit tool template project
- 针对前面文章的整改思路
- Deep learning - CV, CNN, RNN
- Use and analysis of show profile optimized by MySQL
猜你喜欢

Sorting problem: bubble sort, select sort, insert sort
『牛客|每日一题』点击消除
『HarmonyOS』探索HarmonyOS应用

从Architecture带你认识JVM

Can C use reflection to assign values to read-only attributes?

Valid bracket sequence of "Niuke | daily question"
『牛客|每日一题』有效括号序列

The creation of "harmonyos" project and the use of virtual machines
"Harmonyos" explore harmonyos applications

buuReserve(4)
随机推荐
【硬十宝典】——7.1【动态RAM】DDR硬件设计要点
Force buckle - 4. Find the median of two positive arrays
【Star项目】小帽飞机大战(四)
123123123
堆排序(heap-sort)
What to pay attention to when using German chicks for the first time
shell编程
7. Reverse integer integer
Resume considerations
XSS labs (1-10) break through details
AcWing-每日一题
Esxi 7.0 installation supports mellanox technologies mt26448 [connectx en 10gige, PCIe 2.0 5gt/s] driver, and supports the cheapest 10GB dual fiber network card
Fastdfs supports dual IP and IPv6
MySql 执行计划
【毕业季_进击的技术er】送别过去两年迷茫的自己。重整旗鼓,大三我来啦
Summary of common usage of dev treelist
Which "digital currencies" can survive this winter? 2020-03-30
源代码加密技术发展阶段
[Web3 series development tutorial - create your first NFT (4)] what can NFTs bring to you
[Star Project] small hat aircraft War (III)