( One ) memory management
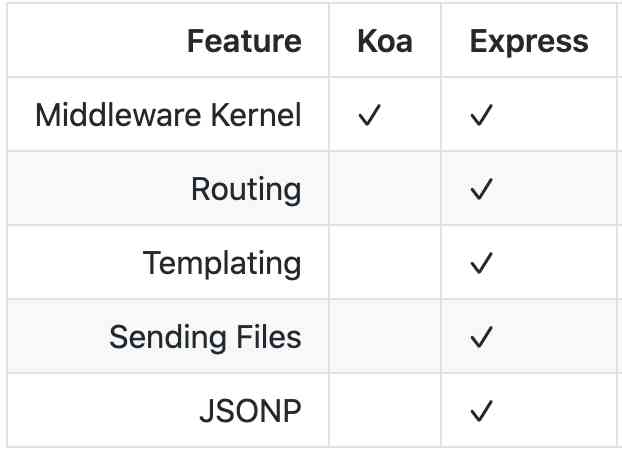
Memory management means executor Memory management for .
1. Memory classification -- Heap memory and out of heap memory
Memory is classified into Heap memory and out of heap memory . Heap memory is divided into storage storage Memory 、execution Operational memory 、other Memory . The ratio is 6:2:2
Heap memory :Executor Memory management is based on JVM Memory management .JVM Memory is heap (on-heap) Memory .Spark Pile up JVM Memory is divided in more detail , To make the most of heap memory .
Out of heap memory :spark It is also introduced out of the heap (off-heap) Memory , Create space directly in the working node's system memory . It can save heap memory
Heap memory Is subject to JVM Unified management .Gc Free memory . Out of heap memory is directly applied to and released from the node's operating system . Voluntary application and voluntary release . let me put it another way . Out of heap memory, we have full control of the application 、 The rhythm of use and release .
Heap memory is spark After the release of , wait for JVM Of GC. therefore ,spark After release , It may still not be released . and spark Think it's released . therefore , Heap memory may have an actual memory size smaller than the estimated memory size .
Storage memory storage: cache RDD And broadcast Broadcast Memory used .
Execution memory execution: Storage execution shuffle Intermediate data in .
Other Memory : A user-defined data structure or spark Internal metadata .
2. Memory allocation
(1) Static memory management
Storage memory 、 The size of execution memory and other memory is in spark Is fixed in the process of operation .6-2-2
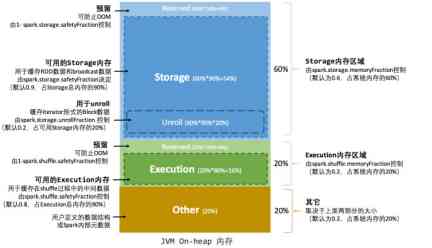
Out of heap memory statistics are accurate . There is no need to reserve space .
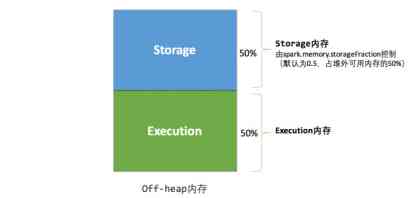
(2) Unified memory management
Storage memory and execution memory share the same space . Can dynamically occupy the other party's free area .
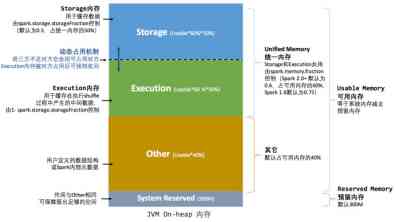
3. Storage memory management
RDD It's blood dependent ,RDD The conversion is inert , Only in Action It will only be triggered when it is operated . therefore , If one RDD Used many times , If there is no cache , You need to load many times according to blood relationship , Repeat the calculation . therefore , It is necessary to calculate repeatedly RDD, First run cache perhaps persist Method , Persist this in the cache RDD.
Cache and Persist The difference between :cache The storage level is MEMORY_ONELY Of Persist.
4. Memory management
5. Broadcast variables 、 accumulator
Broadcast variables : Broadcast variables allow the programmer to Executor A read-only variable that holds external data on , Instead of sending a copy to each task . The broadcast variable is each executor One copy . One executor All of the task Share a read-only variable .
accumulator : The accumulator is there driver End , Only variables accumulated by related operations are allowed .Spark It provides multiple nodes to perform shared operations on a shared variable .
( Two )SPARK performance tuning
1. General performance optimization
(1) Optimal resource allocation :
According to the resources of the environment , Use resources as much as possible .
(2) RDD Optimize
① Different branches , The same operation . avoid RDD Repeated calculation of .RDD The same operation of different branches should be in the parent as much as possible RDD In the first calculation . Similar to object-oriented , Methods with the same subclass should be moved up to the parent class .
② The same branch , Multiple operations . Add persistence : For multiple calculations RDD Add cache . Persist to memory .
③ RDD Do it as soon as possible Filter: And optimization sql similar , Priority is given to reducing the data set of operations .
(3) Parallelism adjustment
Parallelism refers to each stage in Task The number of . The reasonable setting of parallelism needs to match with resources .Task Should be executor in core Multiple . It is generally recommended that .Task The number is core Of 2-3 times .
(4) Use broadcast variables
If task You need to use external variables , Every task Back up a copy of the data . Waste of resources . You can broadcast these external variables . Every executor Keep a journal of . Every task Use where you are executor The variable of .
2. Operator tuning
(1) mapPartitions
Map and mapPartitions The difference between :map Function will traverse each data read .MapPartitions It will take all the data in one partition at a time , And then process it in memory .
MapPartitions One load , Easy to cause OOM.
(2) foreachPartition
ForeachPartition It is usually used to write data to a database . Use foreachPartition Common operations can be placed in each operation foreachPartition in . such as : Database connection , Each partition can be connected once . You don't need to make a connection for each data .
(3) filter And coalesce In combination with
Suppose the raw data is evenly distributed . adopt filter after ( Different partitions may filter out data of different sizes ), The amount of data is skewed . Can pass coaleasce perhaps repartition Repartition .
(4) repartition solve SparkSQL Low parallelism problem
Spark Sql Load the original file into RDD The number of partitions It's the number of original partitions . Maybe and now spark The number of resources for does not match . This is a high probability event . therefore , Need to pass through reparttition Function to repartition . Let the parallelism match the number of resources .
(5) reduceByKey Local aggregation
ReduceByKey Will be in map The client will first process the local data combine operation , And then write the data to the next stage Each task In the created file . Increase the degree of aggregation of data , Less data , To improve efficiency .
3. shuffle tuning
(1) Adjust the map End buffer size
Adjust the map End buffer size . It can reduce the number of small files over written . Less IO, In order to adjust the efficiency .
(2) adjustment reduce End pull buffer size
Reduce End buffer size adjustment , It can affect the number of times the data is pulled out . Less network transfers , To improve efficiency .
(3) adjustment reduce Pull data interval wait time
To adjust properly reduce The waiting time between pull data
4. Data skew
(1) Reduce join turn map join
Size table Join. The watch is smaller than 12M, Use... For small watches broadcast. Convert small table data to external variable data . By broadcasting variables to each executor On . stay map The stage can go on join. So as to avoid fundamentally shuffle.
(2) For individual key Corresponding to the problem of large amount of data
Can be rdd It is divided into two parts by filtering rdd. After processing separately , Re merger . scene :[ In the work , Usually key by null perhaps ”” , stay repatitions When , These special data will be repartitioned , Artificial data skew ].
5. Personal experience
(1) Calculation of the same dimension , A scan , Calculate many times at the same time
Rdd During the calculation of , Full table scanning is time consuming . therefore , Try to minimize the scanning process . That can be calculated in the same statistical dimension , Try to count in one calculation . Application scenarios 【 In the same polymerization conditions : Calculate different fields , Produce different indicators 】