当前位置:网站首页>深度学习分类网络 -- AlexNet
深度学习分类网络 -- AlexNet
2022-07-02 05:50:00 【有时候。】
深度学习分类网络总结
- AlexNet
- VGGNet
目录
前言
AlexNet是由Hinton和其学生Alex所设计,获得了2012 ILSVRC(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军,top5错误率为15.3%,远超第二名的26.2%,证明了卷积神经网络在图像识别任务中的优越性[1]。
一、网络结构
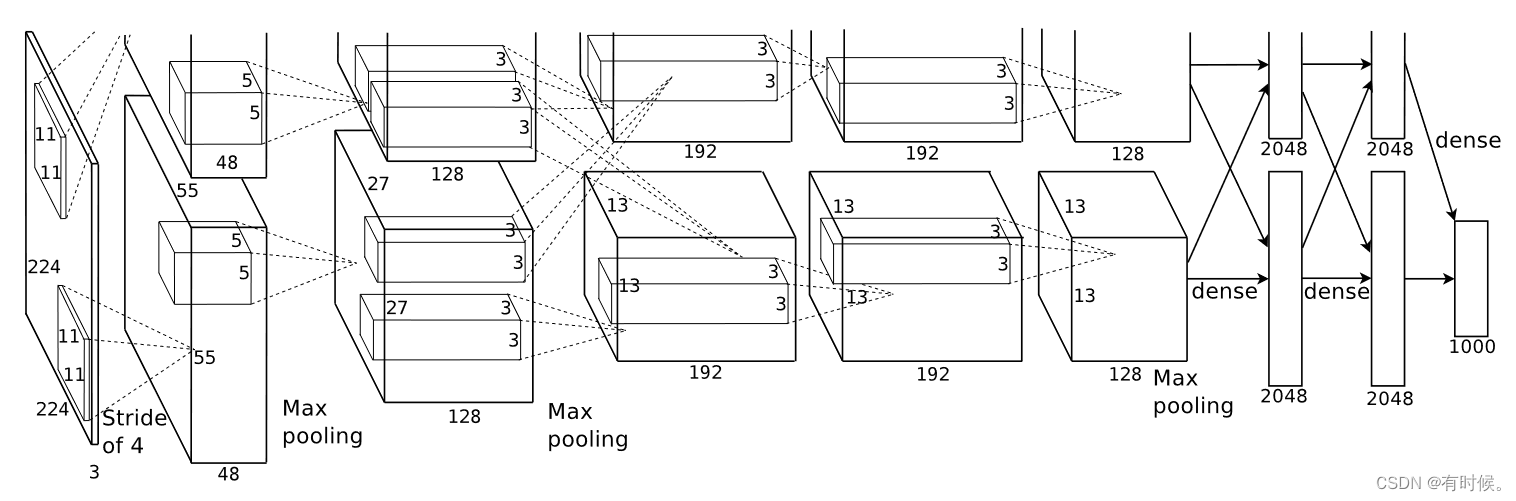
引用原论文中的网络结构图,可以看出AlexNet共有8层,5个卷积层和3个全连接层。使用torchstat工具打印pytorch官方实现的AlexNet中每层的输入输出尺寸、参数量(parameters)和计算量(FLOPs,MACs):
import torchvision.models as models
from torchstat import stat
alexnet = models.alexnet()
stat(alexnet, (3,224,224))
# 附Pytorch官方实现的AlexNet结构,与原始论文有所区别
AlexNet(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
(classifier): Sequential(
(0): Dropout(p=0.5, inplace=False)
(1): Linear(in_features=9216, out_features=4096, bias=True)
(2): ReLU(inplace=True)
(3): Dropout(p=0.5, inplace=False)
(4): Linear(in_features=4096, out_features=4096, bias=True)
(5): ReLU(inplace=True)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
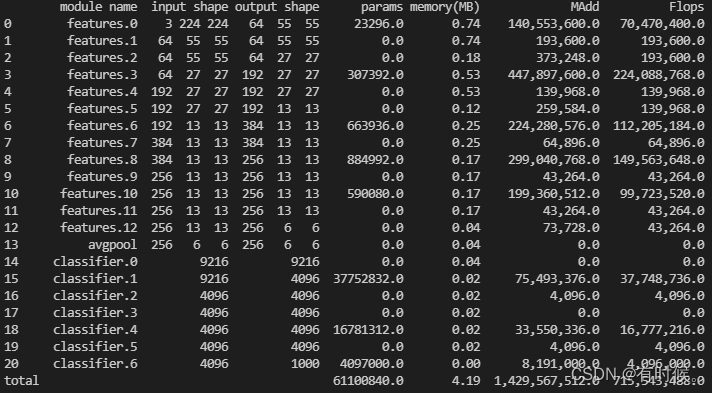
简单总结一下输入输出尺寸、参数量和计算量的计算方法:
1. 输入输出尺寸
卷积层和池化层的输出尺寸可根据下式计算: W o u t = W i n − K + 2 P S + 1 W_{out}=\frac{W_{in}-K+2P}{S}+1 Wout=SWin−K+2P+1上式中: W i n W_{in} Win为输入特征图尺寸,K为卷积核尺寸,P为padding大小, W o u t W_{out} Wout为输出特征图尺寸。
以第一个卷积层为例:输入shape为(3,224,224),卷积核为11×11,步长为4,padding为(2,2),参数代入可得: W o u t = 224 − 11 + 4 4 + 1 = 55.25 W_{out}=\frac{224-11+4}{4}+1=55.25 Wout=4224−11+4+1=55.25向下取整为55,卷积核数量为64,因此输出shape为(64,55,55)。
2. 参数量
卷积层参数量 = ( K ∗ K ∗ C i n ) ∗ C o u t + C o u t (K*K*C_{in})*C_{out}+C_{out} (K∗K∗Cin)∗Cout+Cout,全连接层看作K=1的卷积层即可。
以第一个卷积层为例:params = 11×11×3×64+64=23296
以第一个全连接层为例:params = 1×1×9216×4096+4096=37752832
3. 计算量(FLOPs,MACs/MAdd)
- FLOPs(Float Point Operations):浮点运算次数,用来衡量算法或模型的复杂度,每一个加、减、乘、除都算一次浮点运算。
- MACs(Multiply-Accumulate Operations):乘加累积操作次数,一次乘加累积操作包括一个乘法操作和一个加法操作。因此,在数值上通常有FLOPs=2*MACs这种关系。
FLOPs计算方法: 以卷积层为例,假设经过卷积后输出 C o u t C_{out} Cout个尺寸为 H o u t × W o u t H_{out}×W_{out} Hout×Wout的特征图,单个特征图中的每个值都是经过一次卷积计算而得,那么卷积层的总FLOPs= H o u t × W o u t × C o u t H_{out}×W_{out}×C_{out} Hout×Wout×Cout × 一次卷积的FLOPs。一次卷积计算可以简化为 y = w x + b y=wx+b y=wx+b,这里的 y y y就是输出特征图中的某个值, w w w为 K × K × C i n K×K×C_{in} K×K×Cin的权值矩阵, w x wx wx包含 K × K × C i n K×K×C_{in} K×K×Cin个乘法操作和 K × K × C i n − 1 K×K×C_{in}-1 K×K×Cin−1个加法操作, + b +b +b包含1个加法操作,因此一次卷积的FLOPs= ( K × K × C i n ) + ( K × K × C i n − 1 ) + 1 = 2 ∗ K 2 ∗ C i n (K×K×C_{in})+(K×K×C_{in}-1)+1=2*K^2*C_{in} (K×K×Cin)+(K×K×Cin−1)+1=2∗K2∗Cin。那么卷积层的总FLOPs可按下式计算:
F L O P s ( c o n v ) = H o u t × W o u t × C o u t × 2 × K 2 × C i n ≈ 2 × p a r a m s × H o u t × W o u t FLOPs(conv) =H_{out}×W_{out}×C_{out}×2×K^2×C_{in} \approx2×params×H_{out}×W_{out} FLOPs(conv)=Hout×Wout×Cout×2×K2×Cin≈2×params×Hout×Wout(torchstat中的FLOPs和MAdd貌似反过来了?)
二、亮点
1. ReLU激活函数
作者在论文中提到“对于梯度下降的训练时间,sigmoid和tanh这样的饱和非线性函数比非饱和非线性函数ReLU慢得多”,速度慢的原因是sigmoid和tanh函数中涉及到了指数运算,因此在AlexNet中选择ReLU函数作为激活函数。
# 绘制激活函数图像
import numpy as np
import matplotlib.pyplot as plt
plt.rc('font',family='Times New Roman', size=15)
x = np.linspace(-10,10,500)
sigmoid = 1 / (1+np.exp(-x))
tanh = (np.exp(x)-np.exp(-x)) / (np.exp(x)+np.exp(-x))
relu = np.where(x<0, 0, x)
fig = plt.figure()
ax = fig.add_subplot(211)
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['left'].set_position(('data',0))
ax.spines['bottom'].set_position(('data',0))
plt.plot(x, sigmoid, label='sigmoid')
plt.plot(x, tanh, label='tanh')
plt.grid(linestyle='-.')
plt.legend()
ax2 = fig.add_subplot(212)
ax2.spines['right'].set_visible(False)
ax2.spines['top'].set_visible(False)
ax2.spines['left'].set_position(('data',0))
ax2.spines['bottom'].set_position(('data',0))
plt.plot(x, relu, label='ReLU')
plt.grid(linestyle='-.')
plt.legend()
plt.tight_layout()
plt.show()

- 作者通过实验证明了ReLU函数相比tanh函数的优势:使用ReLU激活函数的四层CNN在CIFAR-10数据集上达到25%错误率的速度比tanh激活函数大约快6倍。(下图中实线为ReLU,虚线为tanh)
- 除了速度快,ReLU激活函数还能够避免饱和函数所引起的梯度消失问题。

2. GPU并行训练
论文中提到一个GTX 580GPU只有3GB的内存,限制了可以用其进行训练的网络的最大大小,因此将网络拆分到两个GPU上,两个GOU可以直接读取和写入彼此的内存,而不需要经过主机内存,双gpu网络比单gpu网络花费更少的训练时间。作者所采用的并行化方案是将神经元的一半放在单个GPU上,另外还使用了一个技巧:GPU只在特定层中进行通信。
3. 局部响应归一化(LRN)
受神经生物学中“侧抑制”概念(一个被兴奋的神经元能降低周围神经元活性)的启发,作者提出了局部响应归一化,计算方法如下:
式中:
b x , y i b_{x,y}^{i} bx,yi表示第 i i i个特征图在位置 ( x , y ) (x,y) (x,y)处经过局部响应归一化后的值
a x , y i a_{x,y}^{i} ax,yi表示第 i i i个特征图在位置 ( x , y ) (x,y) (x,y)处经过局部响应归一化前的值
k , α , β k,\alpha, \beta k,α,β为超参数
N N N是特征图总数, n n n表示取多少个相邻特征图,利用它们在位置 ( x , y ) (x,y) (x,y)处的值(也就是式中的 a x , y j a_{x,y}^{j} ax,yj)进行求和
Pytorch中的实现方式与原论文中有一处不同,将 α \alpha α改为了 α n \frac{\alpha}{n} nα: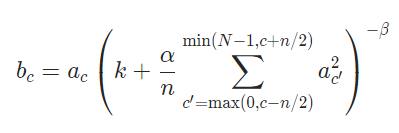
# 测试Pytorch中的LRN层
import torch
import torch.nn as nn
import torch.nn.functional as F
lrn = nn.LocalResponseNorm(size=3, alpha=1, beta=1, k=1)
input_tensor = F.relu(torch.randn((1,4,3,3))) # (batchsize, C, H, W), 4个size为3*3的特征图
output_tensor = lrn(input_tensor)
# 归一化前
tensor([[[[0.0000, 0.0000, 0.0000],
[1.5463, 1.2684, 1.5114],
[0.6285, 1.6448, 0.0000]],
[[0.5272, 0.0000, 0.3121],
[0.9505, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000]],
[[1.1392, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000],
[0.1394, 0.0000, 0.5774]],
[[1.0331, 1.0747, 0.0000],
[1.0267, 0.9921, 0.0000],
[0.0000, 0.0000, 0.0000]]]])
# 归一化后
tensor([[[[0.0000, 0.0000, 0.0000],
[0.7370, 0.8256, 0.8580],
[0.5554, 0.8649, 0.0000]],
[[0.3457, 0.0000, 0.3023],
[0.4530, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000]],
[[0.6056, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000],
[0.1385, 0.0000, 0.5197]],
[[0.5777, 0.7760, 0.0000],
[0.7598, 0.7470, 0.0000],
[0.0000, 0.0000, 0.0000]]]])
推算一下LRN的计算过程:以第二个特征图在(0,0)位置处的值0.5272为例,求和通道的下限为 m a x ( 0 , 1 − 3 / 2 ) max(0,1-3/2) max(0,1−3/2)=0,上限为 m i n ( 4 − 1 , 1 + 3 / 2 ) = 2 min(4-1,1+3/2)=2 min(4−1,1+3/2)=2,因此考虑0,1,2三个通道,代入公式有:
b 0 , 0 1 = 0.5272 1 + ( 0 + 0.527 2 2 + 1.139 2 2 ) / 3 = 0.3457 b_{0,0}^1 = \frac{0.5272}{1+(0+0.5272^2+1.1392^2)/3}=0.3457 b0,01=1+(0+0.52722+1.13922)/30.5272=0.3457
4. 重叠池化
使用小于池化窗口尺寸的步长,能够获取更丰富的特征,top1和top5错误率分别降低了0.4%和0.3%。
5. 防止过拟合
5.1 数据增强
- 从256×256图像中随即裁剪224×224,并对裁剪后的图像做平移和水平翻转。在测试时做TenCrop,平均10张图像的softmax输出作为最终输出。
- 改变RGB通道强度:对图像执行PCA,然后在原始图像的每个像素(RGB三个通道)上加上下式所计算的值
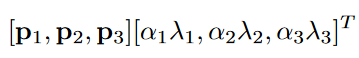
上式中: p i p_i pi和 λ i \lambda_i λi分别为每个RGB像素值的3×3协方差矩阵的特征向量和特征值, p i p_i pi的维度为3×1,因此上式计算结果为3×1,三个值分别加在像素值的RGB三个通道上。 α i \alpha_i αi是服从均值为0和标准差为0.1的高斯变量,每个训练图像随机生成一次 α i \alpha_i αi。
5.2 Dropout
Dropout技术:在神经网络的每次迭代中,以一定概率 p p p 随机丢弃神经元,使其在当前迭代中不参与前向和反向传播。
- 集成多个模型的预测结果能够有效减小测试误差,但是训练多个模型的代价太大,尤其是在大规模数据集上。
- 当网络中引入Dropout时,每次接受新的训练数据时都会采样一个新的网络结构,每次训练一个子网络,多轮训练相当于集成了多个子网络。在测试时,所有神经元都是激活状态,但是需要将它们得输出乘上丢弃概率 p p p。

6. 训练策略
6.1 SGD with momentum and weight decay
使用大动量和权重衰减的小批量随机梯度下降:batch size为128, momentum为0.9,weight decay为0.0005。
6.2 权重初始化
合适的权重初始化能在初级阶段加快网络的学习,文中将所有层的weights初始化为 w ∼ N ( 0 , 0.01 ) w\sim N(0,0.01) w∼N(0,0.01);bias分层初始化,第二、四、五层卷积层和所有全连接层的bias初始化为1,其它层初始化为0。
6.3 学习率下降
所有层的初始学习率均为0.01,当验证集上的错误率不再下降时学习率下降1/10。
7. 卷积核可视化
参考资料
[1] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]// International Conference on Neural Information Processing Systems. Curran Associates Inc. 2012:1097-1105.
[2] 【深度学习理论 卷积神经网络02】 卷积的一般知识(根据卷积核大小和步长计算输出结果形状)
[3] CNN 模型所需的计算力flops是什么?怎么计算?
[4] 【局部响应归一化】Local Response Normalization
[5] Srivastava N, Hinton G, Krizhevsky A, et al. Dropout: a simple way to prevent neural networks from overfitting[J]. The journal of machine learning research, 2014, 15(1): 1929-1958.
待填坑…
- 神经网络中的激活函数总结
- 深度学习中的归一化技术总结
- 过拟合解决方法总结
- 深度学习中的常用优化器
- 神经网络中的常用权重初始化方法
- 学习率衰减策略总结
边栏推荐
- php读文件(读取json文件,转换为数组)
- Record sentry's path of stepping on the pit
- mysql事务和隔离级别
- PHP extensions
- [paper translation] gcnet: non local networks meet squeeze exception networks and beyond
- Conglin environmental protection rushes to the scientific and Technological Innovation Board: it plans to raise 2billion yuan, with an annual profit of more than 200million yuan
- idea開發工具常用的插件合集匯總
- Youth training camp -- database operation project
- php数组转化为xml
- Basic use of form
猜你喜欢







随机推荐
数据挖掘方向研究生常用网站
Pytorch Chinese document
Spark概述
Basic use of form
PHP extensions
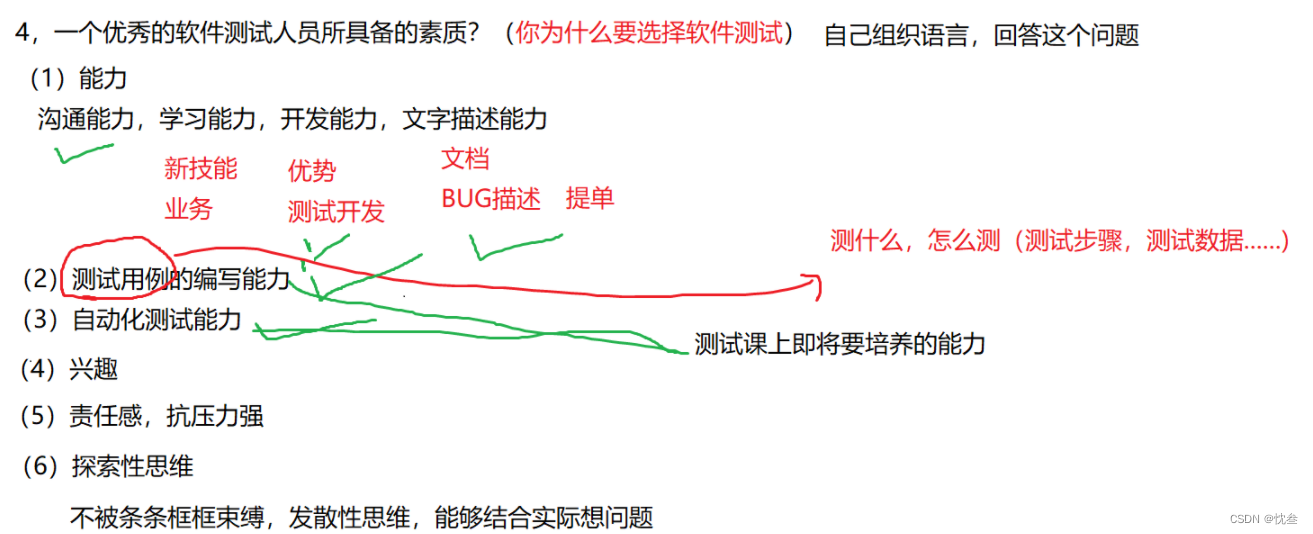
Fundamentals of software testing
Grbl software: basic knowledge of simple explanation
"Simple" infinite magic cube
php读文件(读取json文件,转换为数组)
Win10 copy files, save files... All need administrator permission, solution
如何写出好代码 — 防御式编程指南
【LeetCode】Day92-盛最多水的容器
Online music player app
软件测试 - 概念篇
php获取cpu使用率、硬盘使用、内存使用
How to write good code - Defensive Programming Guide
1036 Boys vs Girls
[technical notes-08]
Fabric. JS iText superscript and subscript
2022-2-14 learning xiangniuke project - Section 6 displays login information