当前位置:网站首页>Caffeine cache, the king of cache, has stronger performance than guava
Caffeine cache, the king of cache, has stronger performance than guava
2022-06-28 09:46:00 【Ape core】
Click on the above “ Ape core ”, choice “ Set to star ”
The background to reply "1024", I have a surprise for you in the interview
One 、 Preface
In project development , To improve system performance , Reduce IO expenses , Local caching is essential . The most common local cache is Guava and Caffeine, This article will introduce Caffeine.
Caffeine Is based on Google Guava Cache The result of design experience improvement , Compare with Guava More efficient in performance and hit rate , You can think of it as Guava Plus.
No doubt , You should remove your local cache from Guava Migrate to Caffeine, This article will focus on Guava Compare the performance of the two , Best practices for local caching , And migration strategy .
Two 、PK Guava
2.1 function
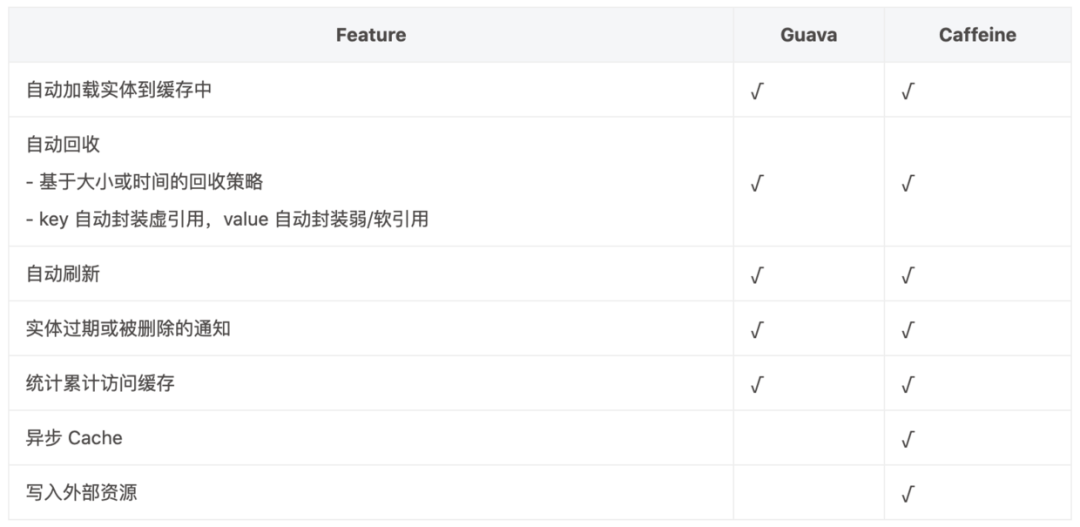
functionally ,Guava It's quite perfect , It meets most of the requirements of local caching .Caffine In addition to providing Guava Besides the existing functions , At the same time, some extended functions have been added .
2.2 performance
Guava Its read and write operations are mixed with the processing of expiration time , That's when you're at one time put There may be elimination in operation , So its read-write performance will be affected .
Caffeine In terms of reading and writing operations Guava, Mainly because Caffeine Operations on these events are asynchronous , Submit the event to the queue ( Use Disruptor RingBuffer), Then the default ForkJoinPool.commonPool(), Or self configured thread pool , Queue fetching operation , And then the subsequent elimination 、 Expiration action .
The following performance comparison comes from Caffeine Official data :
(1) In this benchmark , From the cache with the maximum size configured ,8 Threads read concurrently :

(2) In this benchmark , From the cache with the maximum size configured ,6 Threads read concurrently 、2 Two threads write concurrently :
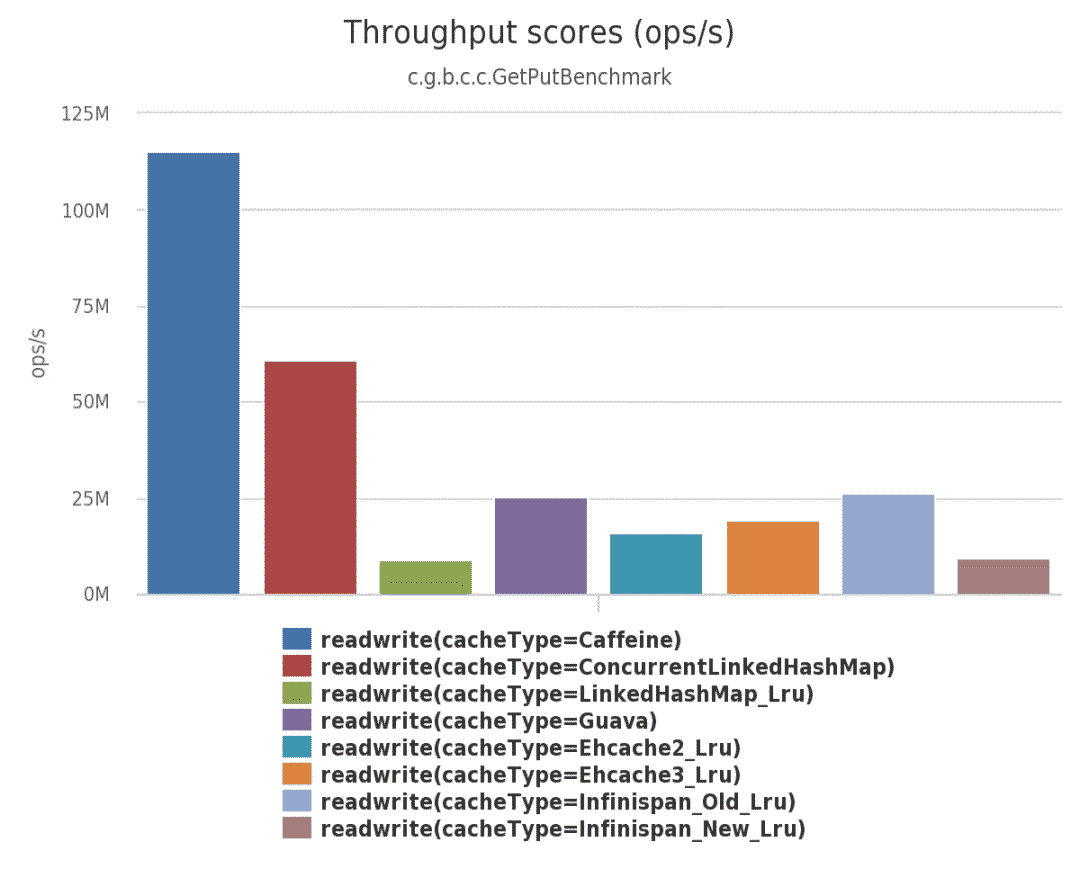
image.png
(3) In this benchmark , From the cache with the maximum size configured ,8 Two threads write concurrently :

2.3 shooting
The cache elimination strategy is to predict which data is most likely to be used again in the short term , So as to improve the cache hit rate .Guava Use S-LRU The least recently unused algorithm of segmentation ,Caffeine A combination of LRU、LFU The advantages of the algorithm :W-TinyLFU, Its characteristics are : High hit rate 、 Low memory usage .
2.3.1 LRU
Least Recently Used: If the data has been accessed recently , The probability of being visited in the future is also higher . Put this element at the head of the queue for each visit , When the queue is full, the data at the end of the queue will be eliminated , That is to say, those who have not been visited for the longest time will be eliminated .
Need to maintain access frequency information for each data item , Every visit needs to be updated , The cost is very large .
The drawback is that , If a large amount of data comes at a certain time , It's easy to squeeze hot data out of the cache , What's left is probably just one visit , Data that will not be accessed in the future or with extremely low frequency . For example, there was a sudden increase in the number of visits to takeout at noon 、 The scandal of a star on Weibo is a sudden hot event . When it's over , There may be no more visits , But because of its high frequency of access , It will not be eliminated for a long time in the future .
2.3.2 LFU
Least Frequently Used: If the data has been accessed recently , So the probability of being visited in the future is also higher . That is to eliminate the data that has been visited the least times in a certain period of time ( The principle of time locality ).
Need to use Queue To save access records , It can be used LinkedHashMap To simply implement a system based on LRU Algorithm cache .
Its advantages are , Avoided LRU The shortcomings of , Because it's based on frequency , There won't be a lot of squash coming in old , If the pattern of data access does not change over time ,LFU Can provide excellent hit rate .
The drawback is that , Sporadic 、 Periodic batch operations can lead to LRU The hit rate dropped sharply , Cache pollution is serious .
2.3.3 TinyLFU
TinyLFU seeing the name of a thing one thinks of its function , Lightweight LFU, Compared with LFU The algorithm uses less memory space to record access frequency .
TinyLFU Maintain the frequency information of recent visit records , Different from traditional LFU Maintain access records throughout the lifecycle , So he can deal with sudden hot events very well ( Over a certain period of time , These records are no longer maintained ). These access records act as a filter , When new records are added (New Item) The access frequency is higher than the cache records that will be eliminated (Cache Victim) It will be replaced when it is used . The process is as follows :
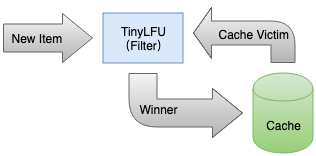
tiny-lfu-arch
Although it is the recent visit records that are maintained , But it's still very expensive ,TinyLFU adopt Count-Min Sketch Algorithm to record frequency information , It takes up less space and has a low false alarm rate , About Count-Min Sketch The algorithm can refer to the paper :pproximating Data with the Count-Min Data Structure
2.3.4 W-TinyLFU
W-TinyLFU yes Caffeine A new algorithm is proposed , It can solve the problems of inaccurate frequency statistics and access frequency attenuation . This method allows us to start from space 、 efficiency 、 And balancing the error rate of hash collision caused by the length and width of the adaptation proof .
Here's a running ERP The hit rate of various algorithms in the application database service , The experimental data come from ARC The author of the algorithm , See the official website for more scenarios of performance testing :
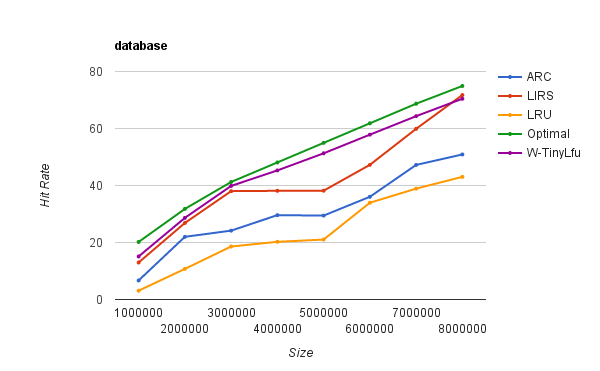
database
W-TinyLFU The algorithm is right TinyLFU Optimization of algorithm , It can solve some sparse burst access elements very well . In some scenarios where the number is small but the burst traffic is large ,TinyLFU You will not be able to save such elements , Because they can't accumulate to a high enough frequency in a short time , It's filtered out by a filter .W-TinyLFU Put the new record into Window Cache Inside , Only through TinLFU Investigation is the only way to enter Main Cache. The general flow chart is as follows :

W-TinyLFU
3、 ... and 、 Best practices
3.1 practice 1
Configuration mode : Set up maxSize、refreshAfterWrite, Not set up expireAfterWrite
Existing problems :get The cache interval exceeds refreshAfterWrite after , Trigger cache asynchronous refresh , The old value in the cache is taken
Applicable scenario :
Large amount of cache data , Limit the amount of memory used by the cache
The cache value changes , Cache refresh required
It is acceptable to have old data in the cache at any time

Set up maxSize、refreshAfterWrite, Not set up expireAfterWrite
3.2 practice 2
Configuration mode : Set up maxSize、expireAfterWrite, Not set up refreshAfterWrite
Existing problems :get The cache interval exceeds expireAfterWrite after , For this key, The thread that gets the lock will execute synchronously load, Other threads that don't get locks block and wait , Too long execution delay of lock acquisition thread will lead to too long blocking time of other threads
Applicable scenario :
Large amount of cache data , Limit the amount of memory used by the cache
The cache value changes , Cache refresh required
Old data in the cache is not acceptable
The delay of synchronous loading data is small ( Use redis etc. )

Set up maxSize、expireAfterWrite, Not set up refreshAfterWrite
3.3 practice 3
Configuration mode : Set up maxSize, Not set up refreshAfterWrite、expireAfterWrite, The timed task refreshes the data asynchronously
Existing problems : The cache needs to be refreshed asynchronously by manual timing task
Applicable scenario :
Large amount of cache data , Limit the amount of memory used by the cache
The cache value changes , Cache refresh required
Old data in the cache is not acceptable
Synchronous loading of data can be very delayed
g
Set up maxSize, Not set up refreshAfterWrite、expireAfterWrite, The timed task refreshes the data asynchronously
3.4 practice 4
Configuration mode : Set up maxSize、refreshAfterWrite、expireAfterWrite,refreshAfterWrite < expireAfterWrite
Existing problems :
get The cache interval is refreshAfterWrite and expireAfterWrite Between , Trigger cache asynchronous refresh , The old value in the cache is taken
get The cache interval is greater than expireAfterWrite, For this key, The thread that gets the lock will execute synchronously load, Other threads that don't get locks block and wait , Too long execution delay of lock acquisition thread will lead to too long blocking time of other threads
Applicable scenario :
Large amount of cache data , Limit the amount of memory used by the cache
The cache value changes , Cache refresh required
It's acceptable to have old data in a finite time cache
The delay of synchronous loading data is small ( Use redis etc. )

Set up maxSize、refreshAfterWrite、expireAfterWrite
Four 、 Migration guide
4.1 Switch to Caffeine
stay pom Introduce in the file Caffeine rely on :
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>Caffeine compatible Guava API, from Guava Switch to Caffeine, You just need to CacheBuilder.newBuilder() Change to Caffeine.newBuilder() that will do .
4.2 Get Exception
It should be noted that , In the use of Guava Of get() When the method is used , When caching load() Method returns null when , Will throw out ExecutionException. Switch to Caffeine after ,get() Method does not throw an exception , But it is allowed to return as null.
Guava One is also provided getUnchecked() Method , It doesn't need what we show to catch exceptions , But once load() Method returns null when , Will throw UncheckedExecutionException. Switch to Caffeine after , No more getUnchecked() Method , Therefore, we need to do a good job in judging empty space .

Previous recommendation
Author's brief introduction : Ape core , A simple North drift . like Use simple words to record every bit of work and life , I would like to share with you the real inner monologue in the programmer's soul . my wechat account :WooolaDunzung, official account 【 Ape core 】 Input 1024 , I have a surprise for your interview .
< END >
【 Ape core 】

Wechat scan QR code , Follow my public number .
It's not easy to share , Don't think about it , If it's a little useful , Use your hand to get rich , One key three combos : Share 、 give the thumbs-up 、 Looking at , Your encouragement is my strongest motivation to share high-quality articles ^_^
Share 、 give the thumbs-up 、 Looking at ,3 even 3 even !
边栏推荐
- Inventory of excellent note taking software: good-looking and powerful visual note taking software, knowledge map tools heptabase, hydrogen map, walling, reflect, infranodus, tiddlywiki
- 标识符的命名规则和规范
- Bron filter Course Research Report
- Thread lifecycle
- Virtual machine 14 installing win7 (Figure tutorial)
- On the influence of small program on the digitalization of media industry
- Settings of gift giving module and other custom controls in one-to-one video chat system code
- 1182: effets de la photo de groupe
- 代理模式(Proxy)
- 1182:合影效果
猜你喜欢

The concept of "tree structure" perfectly interprets the primary and secondary of things

This article explains in detail the difficult problems and solutions faced by 3D cameras
PMP examination key summary VIII - monitoring process group (2)

Bron filter Course Research Report
![1180: fractional line delimitation /p1068 [noip2009 popularization group] fractional line delimitation](/img/1a/162b060a6498e58278b6ca50e4953c.png)
1180: fractional line delimitation /p1068 [noip2009 popularization group] fractional line delimitation

Full link service tracking implementation scheme

Application of X6 in data stack index management
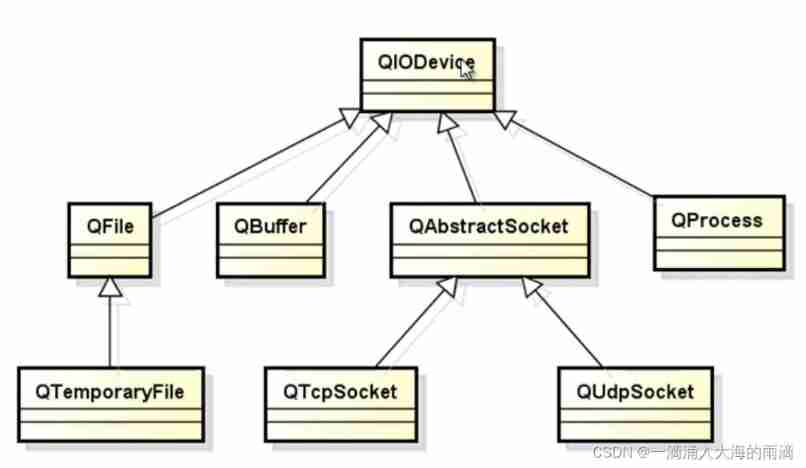
File operations in QT

自动转换之-面试题

Global exception handlers and unified return results
随机推荐
纵观jBPM从jBPM3到jBPM5以及Activiti
Key summary V of PMP examination - execution process group
桥接模式(Bridge)
Huawei OSPF single region
Decorator
1180:分数线划定/P1068 [NOIP2009 普及组] 分数线划定
Settings of gift giving module and other custom controls in one-to-one video chat system code
Sword finger offer | Fibonacci sequence
云服务器MYSQL查询速度慢
Sword finger offer | linked list transpose
微信小程序开发日志
A strange execution plan. One table in the association query is not associated with any other tables
缓存之王Caffeine Cache,性能比Guava更强
Composite pattern
When the interviewer asks you to write binarysort in two ways
MySQL的开发环境和测试环境有什么区别??
Global exception handlers and unified return results
The constructor is never executed immediately after new()!!!!!
异常处理4种方法
1181:整数奇偶排序