当前位置:网站首页>2022CoCa: Contrastive Captioners are Image-Text Fountion Models
2022CoCa: Contrastive Captioners are Image-Text Fountion Models
2022-07-04 17:38:00 【weixin_42653320】
摘要
探索大规模预训练基础模型对计算机视觉具有重要意义,因为这些模型可以迅速地转移到许多下游任务。本文提出对比标注器(CoCa),一种极简的设计,预训练一个图像-文本编码器-解码器模型,并结合对比损失和标注损失,从而包含从对比方法如CLIP和生成方法如SimVLM的模型能力。与所有解码器层都处理编码器输出的标准编码-解码器transformer相比,CoCa在解码器的前半部分忽略交叉注意力来编码单模态文本表示,并将剩余的解码器层交叉处理图像编码器进行多模态图像-文本表示。我们在单模态图像和文本嵌入间应用对比损失,以及在可自动回归预测文本标记的多模态解码器输出上应用标注损失。通过共享相同的计算图,以最小的开销有效地计算了这两个训练目标。CoCa在web规模的替代文本数据和注释图像上进行端到端且从头开始的预训练,通过将所有标签简单地视为文本,无缝地统一了表示学习的自然语言监督。在实验上,CoCa在广泛的下游任务上通过零样本转移或最小的任务特定适应实现了最先进的性能,包括视觉识别、跨模态检索、多模态理解(VQA)和图像标注。
一、介绍
对于之前的预训练模型,下游任务中将解码器的输出用作多模态理解任务的联合表示。虽然预训练过的编码-解码器模型获得了更好的视觉语言结果,但它们不产生与图像嵌入对齐的纯文本表示,因此在跨模态对齐任务中不可行且效率较低。
本工作中,我们统一了单编码器、双编码器和编码器-解码器范式,并训练了一个包含所有三种方法的能力的图像-文本基础模型。我们提出一个简单的模型家族,称为对比标注器(CoCa),具有一个改进的编码器-解码器结构,训练对比损失和标注损失。如图1,我们将解码器transformer解耦为两部分,一个单模态解码器和一个多模态解码器。我们忽略单模态解码器层中的交叉注意力来编码只有文本的表示,级联多模态解码器层交叉关注图像编码器输出来学习多模态图像-文本表示。在图像编码器和单模态文本解码器的输出之间应用对比目标,在多模态解码器的输出之间应用标注目标。此外,通过将所有标签简单地作为文本处理,对图像注释数据和有噪声的图像-文本数据进行训练。图像注释文本上的生成损失提供了一个类似于单编码器交叉熵损失方法的细粒度训练信号,有效地将所有三种预训练范式纳入到一个统一的方法中。
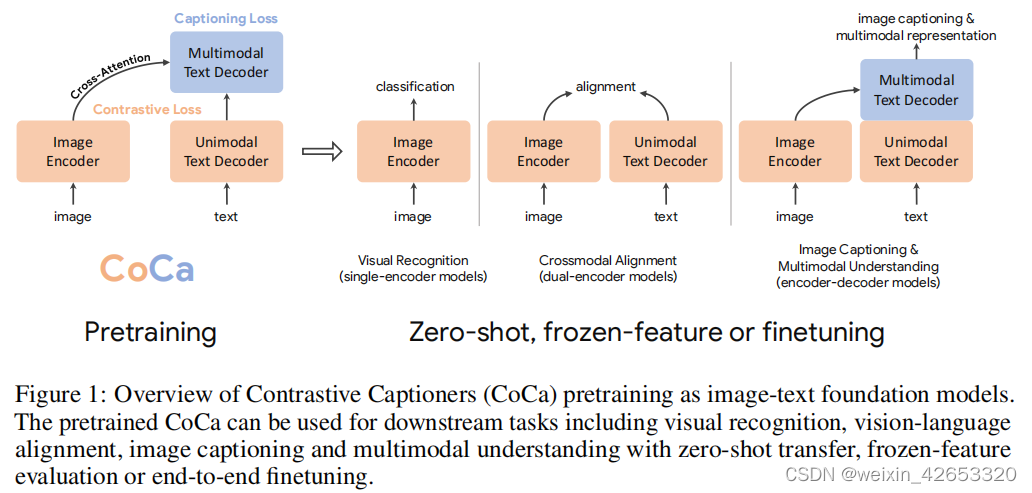
CoCa的设计是利用对比学习来学习全局表示和细粒度区域级特征的标注,从而有利于图1中损失的所有三个类别的任务。CoCa表明,使用零样本转移或最小任务特定适应,单个预训练模型可以优于许多特定模型,如CoCa在ImageNet上获得了86.3%的零样本精度,在MSCOCO和Flickr30k上获得了更好的零样本跨模态检索。使用冻结编码器,CoCa在ImageNet分类上达到90.6%,88.0%/88.5%/81.1%在动力学上达到88.0%/88.5%/81.1%-40/600/700,在实时时刻上达到47.4%。经过轻量级微调后,CoCa在ImageNet上达到91.0%,在VQA上达到82.3%,在NoCaps上达到120.6的CIDEr分数。
二、相关工作
视觉-语言预训练 早期工作(LXMERT、UNITER、VinVL)依赖于预训练目标检测模块,如Faster R-CNN来提取视觉表示。后来(ViLT和VLMo)统一了视觉和语言transformers,并从头开始训练一个多模态transformer。
图像-文本基础模型 提出的图像-文本基础模型可以包括视觉和视觉-语言的预训练。CLIP和ALIGN证明,在有噪声的图像-文本对上使用对比目标预训练的双编码器模型可以学习强图像和文本表示,用于交叉模态对齐任务和零样本图像分类。Florence进一步发展了该方法的统一对比目标,训练基础模型,可以适用于广泛的视觉和图像-文本基准。为了进一步提高零样本图像分类精度,LiT[32]和BASIC[33]首先在交叉熵的大规模图像标注数据集上进行预处理,并在有噪声的替代文本图像数据集上进行微调。[16,17,34]的另一个研究方向提出了用生成损失训练的编码-解码器模型,并在视觉语言基准中显示出强大的结果,而视觉编码器在图像分类上仍然具有竞争力。本工作,我们专注于在一个简单的预训练阶段从头开始训练一个图像-文本基础模型,以统一这些方法。虽然[35,36,37]最近的工作也探索了图像-文本的统一,但它们需要单模态和多模态模块的多个预训练阶段才能获得良好的性能。如ALBEF[36]结合了对比损失与掩蔽语言建模(MLM)和双编码器设计。然而,我们的方法是更简单的,更有效的训练,同时也支持更多的模型功能:(1)CoCa只对一批图像-文本对执行一个正向和向后传播,而ALBEF需要两个(一个是损坏的输入,另一个没有损坏);(2)CoCa只在两个目标上从头开始训练,而ALBEF从预先训练的视觉和文本编码器初始化,有额外的训练信号,包括动量模块;(3)具有生成损失的解码器架构是自然语言生成的首选,从而直接实现图像字幕和零样本学习[16]。
三、方法
首先回顾三个不同方式使用自然语言监督的基础模型:单编码器分类预训练、双编码器对比学习和编码-解码器图像标注。然后引入对比标注器(CoCa),在 一个简单的架构下同时具有对比学习和图像到标注生成的优点。进一步讨论了CoCa模型如何通过零样本转移或最小任务适应快速转移到下游任务。
3.1 自然语言监督
单编码器分类 经典的单编码器方法通过在大型众源图像注释数据集(如ImageNet[9]、it[20]或JFT[21])上进行图像分类,对视觉编码器进行预分类,其中注释文本的词汇表通常是固定的。这些图像注释通常被映射到离散的类向量,以交叉熵损失学习:
![]()
其中,p(y)是来自地面真实标签y的单热、多热或平滑的标签分布。学习到的图像编码器随后被用作下游任务的通用视觉表示提取器。
双编码器对比学习 与需要人工注释标签和数据清理的单编码器分类的预训练相比,双编码器方法利用了有噪声的网络规模的文本描述,并引入了一个可学习的文本塔来编码自由形式的文本。对两个编码器对比成对的文本与其他进行联合优化:

除了图像编码器,双编码器方法还学习了一个对齐的文本编码器,使跨模态对齐,如图像-文本检索和零样本图像分类。
编码器-解码器标注 虽然双编码器方法将文本作为一个整体进行编码,但生成方法(a.k.a.标题器)的目标是详细的粒度,并要求模型以自动回归预测y的精确标记化文本。根据标准的编码器-解码器架构,图像编码器提供潜在的编码特征(例如,使用视觉变压器[39]或ConvNets[40]),文本解码器学习在正向自回归分解下最大化成对文本y的条件似然:
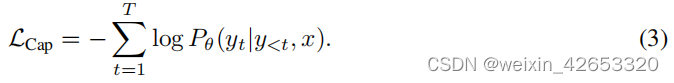
利用教师强迫[41]对编码-解码器进行训练,以并行化计算和学习效率最大化。与之前的方法不同,标注器方法产生了一个联合的图像-文本表示,可以用于视觉语言理解,并且也能够通过自然语言生成图像标注应用。
3.2 对比标注器预训练

图2表示对比标注器(CoCa):一种简单的编码器-解码器方法,无缝地结合了这三种训练模式。与标准的图像-文本编码器-解码器模型类似,CoCa通过神经网络编码器编码图像为潜在表示,如ViT(默认使用,也可以是ConvNets),并使用一个因果掩码transformer解码器解码文本。与标准解码器transformer不同,CoCa在解码器层的前半部分省略交叉注意力来编码单模态文本表示,并对其余的解码器层进行级联,交叉关注图像编码器进行多模态图像-文本表示。因此,CoCa解码器同时产生单模态和多模态文本表示,使我们能够同时应用对比和生成目标:
![]()
其中,λCon和λCap为损失加权超参数。我们注意到,当词汇表是所有标签名称的集合时,单编码器交叉熵分类目标可以被解释为应用于图像注释数据的生成方法的一种特殊情况。
解耦文本解码器和CoCa架构 标注方法优化了文本的条件可能性,而对比方法使用了无条件的文本表示。为了解决这一困境,并将这两种方法结合到一个单一的模型中,我们提出了一种简单的解耦解码器设计,通过跳过单模态解码器层中的交叉注意机制,将解码器分为单模态和多模态组件。即,底部的nuni单模态解码器层将输入文本编码为具有因果掩蔽自注意力的潜在向量,顶部的nuni多模态层进一步将因果掩蔽自注意力和交叉注意力一起应用于视觉编码器的输出。所有的解码器层都禁止标记关注未来的标记,并且可以直接使用多模态文本解码器输出用于标注目标LCap。对于对比目标LCon,我们在输入句子的末尾附加了一个可学习的[CLS]标记,并使用其相应的单模态解码器输出作为文本嵌入。我们把解码器分成两半,这样nuni=nmulti。根据ALBEF,我们用图像分辨率为288×288,补丁大小为18×18进行预训练,总共得到256个图像标记。我们最大的CoCa模型(简称“CoCa”)遵循[21]中的vit-giant设置,图像编码器中有1B参数,2.1个b参数和文本解码器。我们还探索了表1中详细介绍的“CoCa-Base和CoCa-Large”的两个较小的变体。
注意力的池化 值得注意的是,对比损失对每个图像使用一个单一的嵌入,而解码器通常处理编码器-解码器标注器[16]中的图像输出标记序列。我们的初步实验表明,一个单一的池化的图像嵌入有助于视觉识别任务作为一个全局表示,而更多的视觉标记(因此更细粒度)有利于需要区域级特征的多模态理解任务。因此,CoCa采用特定任务的注意力池化[42]来定制视觉表征,用于不同类型的训练目标和下游任务。在这里,池入器是一个简单的多头注意层,具有nquery个可学习查询,编码器输出同时作为键和值。通过这一点,模型可以学习为两个训练目标池化为不同长度的嵌入,如图2所示。任务特定的池化的使用不仅解决了对不同任务的不同需求,而且还引入了池化器作为一个自然的任务适配器。我们在生成性损失nquery=256和对比性损失nquery=1的预训练中使用了注意力的池化器。
预训练效率 解耦自回归解码器设计的一个关键优点是,它可以计算出有效地考虑的两个训练损失。由于单向语言模型是对完整的句子进行因果掩蔽训练的,解码器可以通过单次前向传播有效地生成对比损失和生成损失的输出(与双向方法[36]的两次传递相比)。因此,大部分的计算在两个损失之间共享,与标准编码器-解码器模型相比,CoCa只产生最小的开销。另一方面,虽然许多现有方法[30,32,33,35,36,37]在各种数据源和/或模式上使用多个阶段训练模型组件,但CoCa是直接与各种数据源(即注释图像和噪声替代文本图像)进行端到端预训练,将所有标签作为对比和生成目标的文本。
3.3 用于下游任务的对比标注器
零样本转移 预先训练的CoCa模型通过利用图像和文本输入,以零样本的方式执行许多任务,包括零样本图像分类、零样本图像-文本交叉检索、零样本视频-文本交叉检索。根据之前的实践[12,32],这里的“零射击”与经典的零射击学习不同,在预训练中,模型可以看到相关的监督信息,但在传输协议中没有使用监督示例。对于预训练数据,我们遵循[13,32]中引入的严格的重复数据消除程序来过滤所有的近域示例到我们的下游任务中。
冻结特征评估 如前一节所述,CoCa采用特定任务的注意力池化[42](简称池化器)为下游任务定制不同类型的视觉表示,同时共享主干编码器。这使得模型能够作为一个冻结编码器获得强大的性能,其中我们只学习一个新的池化器来聚合特征。它还可以受益于共享相同冻结图像编码器计算但不同任务特定头的多任务问题。正如在[23]中所讨论的,线性评估难以准确地测量学习到的表示,我们发现注意力池在现实应用中更实用。
用于视频动作识别的CoCa
四、实验
我们的结果是在三类下游任务中进行的:零样本转移、冻结特征评估和微调。我们还提出了消融实验包括预训练目标和结构设计。
4.1 训练设置
数据:CoCa通过将所有标签简单地当作文本,从头在web规模的替代文本数据和有注释的图像上进行预训练。我们使用带有标签名称的JFT-3B数据集[21]作为配对文本,并使用带有噪声的替代文本的ALIGN数据集[13]。我们同时从头开始训练所有模型参数,而没有预先训练具有监督交叉熵损失的图像编码器,以保证简单性和预训练效率。为了确保公平的评估,我们遵循[13,32]中引入的严格的重复数据消除程序,过滤所有近域示例(总共删除了360万幅图像)到我们的下游任务中。为了标记文本输入,我们使用了一个句子块模型[43,44],在采样的预训练数据集上训练词汇量的64k。
优化器:我们的模型是在Lingvo框架[45]中实现的,并使用GSPMD[46,47,48,49]来扩展性能。
4.2 主要结果
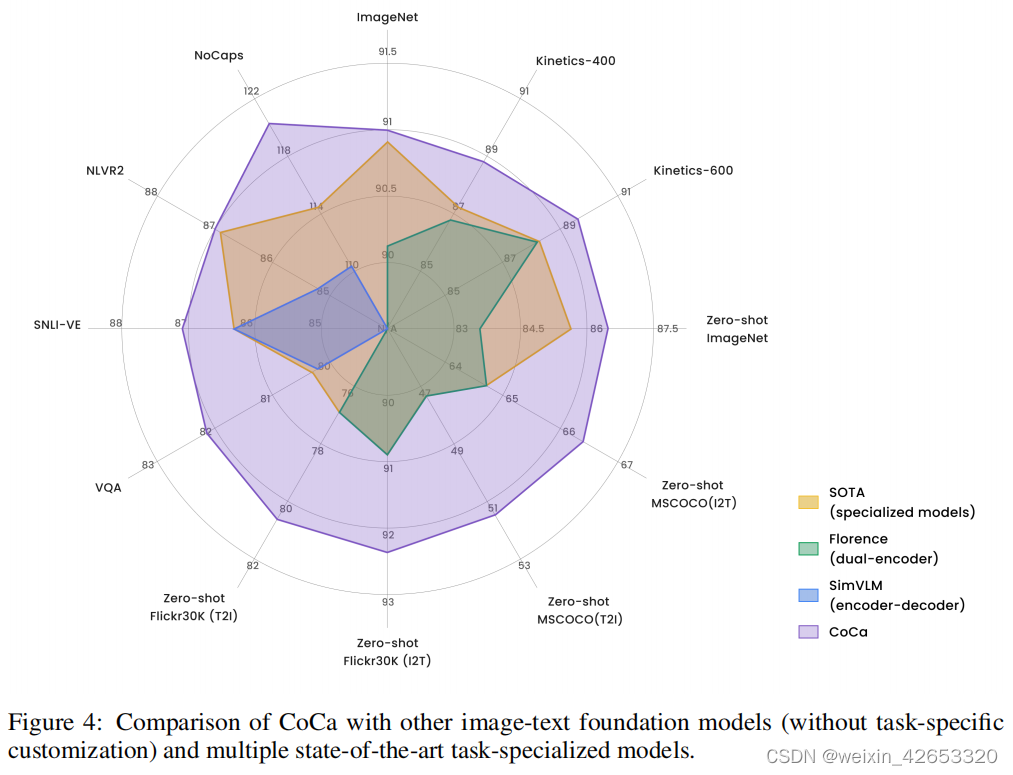
由于CoCa同时产生对齐的单模态表示和融合的多模态嵌入,因此它很容易以最小的适应性转移到所有三个任务组。图4总结了与其他双编码器和编码器-解码器基础模型和最先进的任务专用方法相比,CoCa在关键基准测试上的性能。
4.2.3 多模态理解任务
总的来说,实验结果表明,CoCa除了作为双编码器方法的视觉和检索能力外,还利用了解码器模型的好处,从而获得了强大的多模态理解和生成能力。
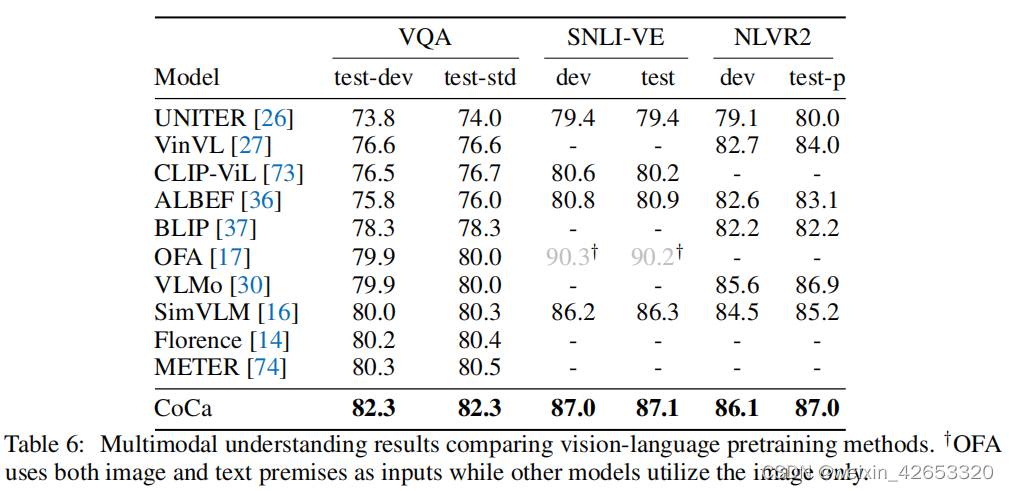
多模态理解 如[16]所示,编码器-解码器模型的输出可以联合编码图像和文本输入,并可以用于需要对这两种模式进行推理的任务。我们主要遵循[16]中的设置,并在解码器输出之上训练线性分类器来预测答案(更多细节见附录B)。我们在表6中的结果表明,CoCa优于强视觉语言预训练(VLP)基线,并在所有三个任务上获得了最先进的性能。虽然先前的双编码器模型[12,14]不包含融合层,因此对于下游的多模态理解任务需要一个额外的VL预训练阶段,但CoCa包含了三种预训练范式,并通过轻量级微调在VL任务上获得了更好的性能。
4.3 消融分析
五、更广泛的影响
这项工作提出了一种在网络规模的数据集上的图像-文本预训练方法,该方法能够以零镜头的方式或通过轻量级的微调转移到广泛的下游任务。虽然预训练的模型能够执行许多视觉和视觉语言任务,但我们注意到,我们的模型使用与以前的方法[13,21,32,33]相同的预训练数据,在实践中使用模型之前,额外的数据分析是必要的。我们展示了CoCa模型对损坏的图像更健壮,但它仍然容易受到其他图像损坏的影响,这些损坏尚未被当前的评估集或在现实场景中捕获。对于数据和模型,需要进一步的社区探索来了解更广泛的影响,包括但不限于公平、社会偏见和潜在的滥用。
六、结论
在这项工作中,我们提出了对比捕获器(CoCa),一个新的图像-文本基础模型家族,它包含了现有的视觉预训练范式与自然语言监督。CoCa在一个阶段中对来自不同数据源的图像-文本对进行了预训练,并在编码器-解码器模型中有效地结合了对比目标和字幕目标。CoCa在广泛的视觉和视觉语言问题上,通过一个单一的断点获得了一系列最先进的性能。我们的工作弥合了各种预训练方法之间的差距,我们希望它能为图像-文本基础模型激发新的方向。
边栏推荐
- 性能优化之关键渲染路径
- ESP32-C3入门教程 问题篇⑫——undefined reference to rom_temp_to_power, in function phy_get_romfunc_addr
- 利用策略模式优化if代码【策略模式】
- 力扣刷题日记/day5/2022.6.27
- 物联网应用技术的就业前景和现状
- Li Kou brush question diary /day7/6.30
- redis分布式锁的8大坑总结梳理
- Is the securities account opened by qiniu safe?
- 力扣刷题日记/day7/6.30
- [2022 Jiangxi graduate mathematical modeling] curling movement idea analysis and code implementation
猜你喜欢
物联网应用技术的就业前景和现状
Deleting nodes in binary search tree

力扣刷题日记/day3/2022.6.25
奥迪AUDI EDI INVOIC发票报文详解
Scala基础教程--15--递归
Installation and use of VMware Tools and open VM tools: solve the problems of incomplete screen and unable to transfer files of virtual machines
An example of multi module collaboration based on NCF

Improve the accuracy of 3D reconstruction of complex scenes | segmentation of UAV Remote Sensing Images Based on paddleseg

神经网络物联网是什么意思通俗的解释
ThreadLocal原理与使用
随机推荐
Interpretation of SIGMOD '22 hiengine paper
物联网应用技术的就业前景和现状
2022-07-04: what is the output of the following go language code? A:true; B:false; C: Compilation error. package main import 'fmt' func
vbs或vbe如何修改图标
Behind the ultra clear image quality of NBA Live Broadcast: an in-depth interpretation of Alibaba cloud video cloud "narrowband HD 2.0" technology
sqlserver的CDC第一次查询的能读取到数据,但后面增删改读取不到,是什么原因
模板_判断素数_开方 / 六素数法
Angry bird design based on unity
C#实现定义一套中间SQL可以跨库执行的SQL语句(案例详解)
Li Kou brush question diary /day4/6.26
Other InterSystems%net tools
英特尔集成光电研究最新进展推动共封装光学和光互连技术进步
Wanghongru research group of Institute of genomics, Chinese Academy of Agricultural Sciences is cordially invited to join
Scala基础教程--14--隐式转换
Deleting nodes in binary search tree
[opencv introduction to mastery 9] opencv video capture, image and video conversion
Caché WebSocket
Nature microbiology | viral genomes in six deep-sea sediments that can infect Archaea asgardii
从实时应用角度谈通信总线仲裁机制和网络流控
Scala basic tutorial -- 14 -- implicit conversion