当前位置:网站首页>ERA5再分析资料下载攻略
ERA5再分析资料下载攻略
2022-07-06 02:48:00 【windawdaysss】
前言
ERA5是第五代ECMWF大气再分析全球气候数据,该数据集的第一部分现在可以公开使用(1959-现在),ERA5数据提供每小时的大气、陆地和海洋气候变量的估计值。
下载过程详述
一、下载网站说明和注册
下载网址是国外的一个网站:https://cds.climate.copernicus.eu/cdsapp#!/home, 按照下图中的步骤点(网不好可能有点卡,喝口水稍等下就行):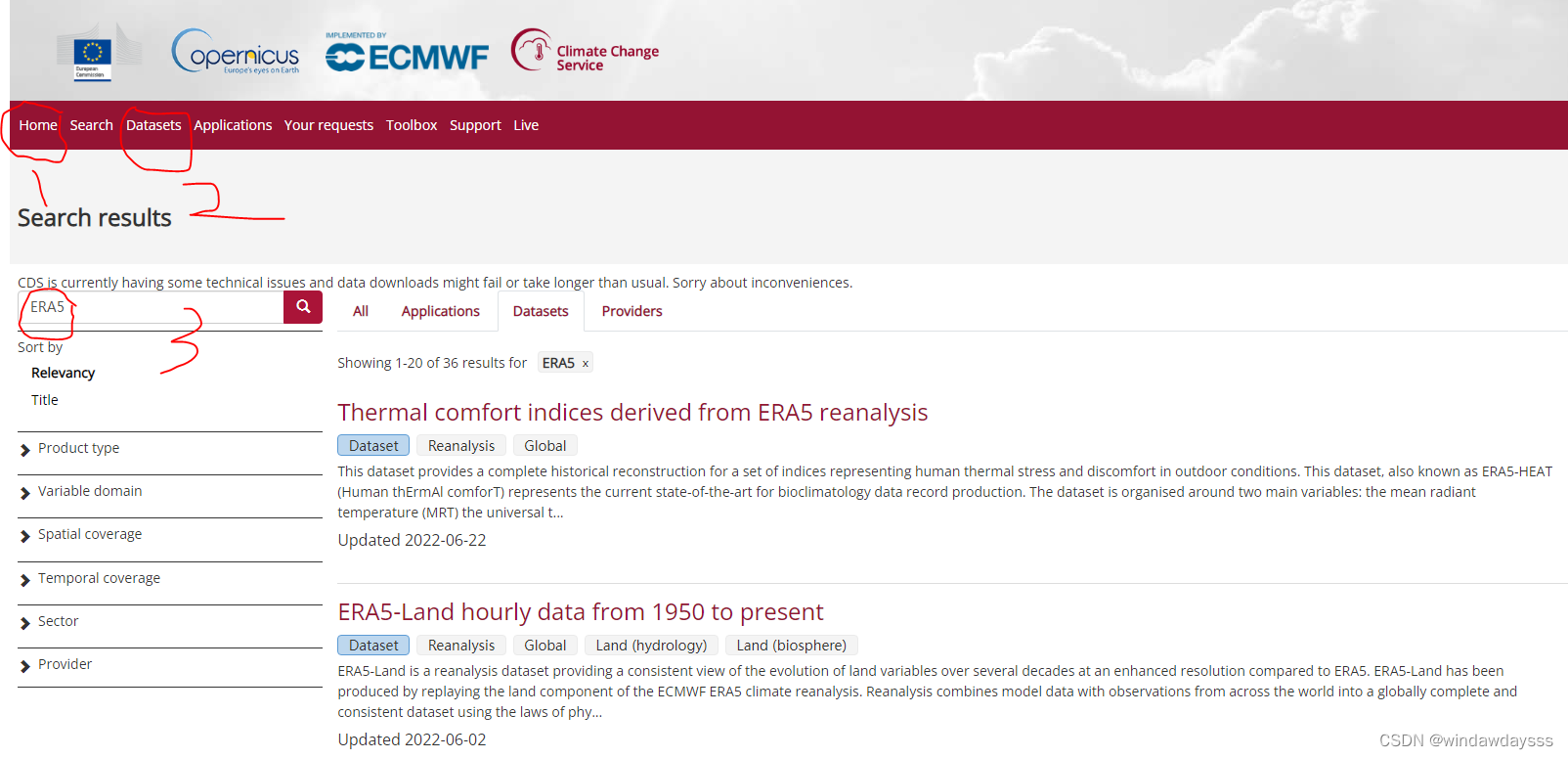
查看右侧搜寻出来的各种数据列表,选择自己想要下载的数据,如果不清楚选择的数据是否正确,可以点进去看,比如,我选择下面这个数据集:
点进去后,默认的overwiew里会介绍数据集的组成变量以及对数据的介绍等如下图示。当确定是自己想要的数据时,打开overwiew后的Download data即可。
里面有产品类型Product type,Variable,Pressure level,year……等选项,选择自己需要的即可。拉到最下面有一个区域选择,默认是全球的数据,如果想定位到自己想要的区域,比如说中国,可进行设置如下,数据格式一般选择NetCDF即可。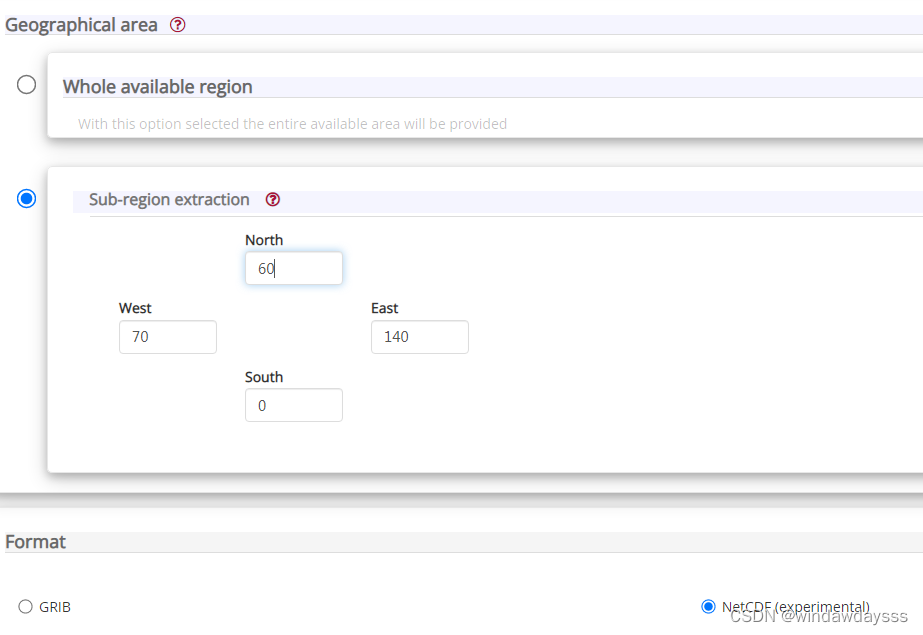
最下面左侧有show API request,点开是python脚本,右侧有login/register to submit request,需要注册或登录: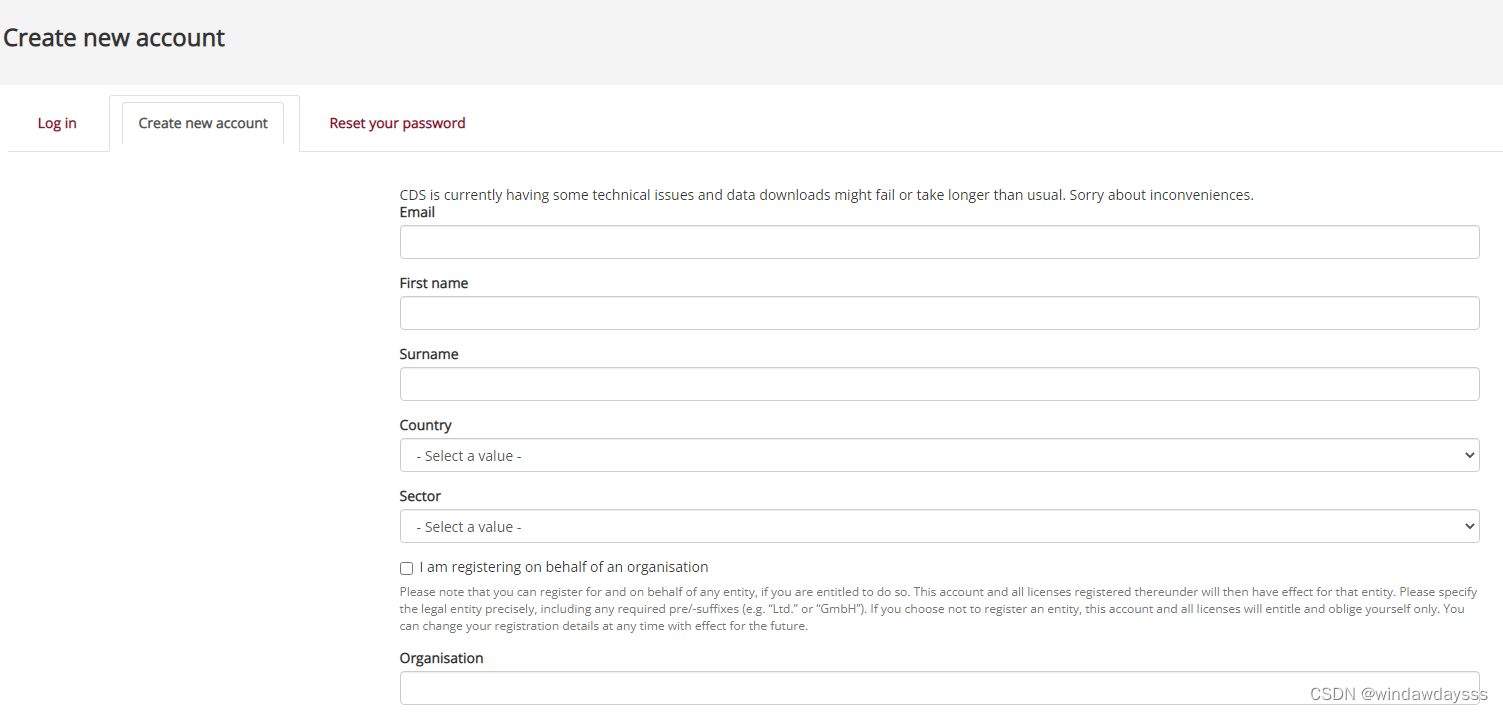
按要求注册,登录。
二、下载电脑配置
点击右上方的登录用户名,下面有API key
按如下格式,存入电脑 C:\Users\你的用户\下。具体建一个txt文本,将代码复制进去,另命名存为.cdsapirc文件,选择所有格式即可。
url: https://cds.climate.copernicus.eu/api/v2
key: UID:API key
三、批量下载设置
- IDM是 “Internet Download Manager” 的简称,是一款非常强大的下载软件。
- 安装包链接:https://pan.baidu.com/s/1iojjYOg_Y2NdMcmJahz_pw,提取码:dimq,版本为v6.36 Build 7,资源来自胡萝卜周。
- 下载好安装包后打开文件夹,双击 “idman636build7.exe” 开始安装IDM,一直点击前进,安装至默认位置即可。
- 将破解补丁复制到IDM安装目录下(默认位置为 “C:\Program Files (x86)\Internet Download Manager” ),双击运行破解补丁,点击 “破解IDM”,破解后点击 “完成” 关闭补丁。
注意:不要更新IDM,否则可能会导致软件不可用。 - 对IDM进行配置,打开软件,在主界面中找到 “选项”,打开;
- 在选项窗口中,找到 “连接” 页面,修改 “连接类型/速度”为 “较高速率连接:局域网/Wi-Fi/移动网络4G/其他”,修改 “默认最大连接数”为16,点击 “确定” 完成配置。
四、使用python脚本批量下载
安装cdsapi第三方库。
pip install cdsapi
import cdsapi
import calendar
from subprocess import call
def idmDownloader(task_url, folder_path, file_name):
""" IDM下载器 :param task_url: 下载任务地址 :param folder_path: 存放文件夹 :param file_name: 文件名 :return: """
# IDM安装目录
idm_engine = "C:\\Program Files (x86)\\Internet Download Manager\\IDMan.exe"
# 将任务添加至队列
call([idm_engine, '/d', task_url, '/p', folder_path, '/f', file_name, '/a'])
# 开始任务队列
call([idm_engine, '/s'])
if __name__ == '__main__':
c = cdsapi.Client() # 创建用户
# 数据信息字典
dic = {
'product_type': 'reanalysis', # 产品类型
'format': 'netcdf', # 数据格式
'variable': 'relative_humidity', # 变量名称
'year': '', # 年,设为空
'month': '', # 月,设为空
'day': [], # 日,设为空
'pressure_level': [
'1', '2', '3',
'5', '7', '10',
'20', '30', '50',
'70', '100', '125',
'150', '175', '200',
'225', '250', '300',
'350', '400', '450',
'500', '550', '600',
'650', '700', '750',
'775', '800', '825',
'850', '875', '900',
'925', '950', '975',
'1000'],
'time': [ # 小时
'00:00', '01:00', '02:00', '03:00', '04:00', '05:00',
'06:00', '07:00', '08:00', '09:00', '10:00', '11:00',
'12:00', '13:00', '14:00', '15:00', '16:00', '17:00',
'18:00', '19:00', '20:00', '21:00', '22:00', '23:00'
],
'area': [60, 70, 0, 140],
}
# 通过循环批量下载2016年到2020年所有月份数据
for y in range(201, 2021):
for m in range(1, 13): # 遍历月
day_num = calendar.monthrange(y, m)[1] # 根据年月,获取当月日数
# 将年、月、日更新至字典中
for d in range(1, day_num + 1):
dic['year'] = str(y)
dic['month'] = str(m).zfill(2)
dic['day'] = str(d).zfill(2)
r = c.retrieve('reanalysis-era5-pressure-levels', dic) # 文件下载器
url = r.location # 获取文件下载地址
path = r'C:\downloadData\relative_humidity' # 存放文件夹
filename = 'era5.relative_humidity.' + str(y) + str(m).zfill(2) + str(d).zfill(2) + '.nc' # 文件名
idmDownloader(url, path, filename) # 添加进IDM中下载
五、说明
运行四中的脚本后,会出现queued,意思是在排队,此时,在选择数据格式那个页面右下角点击submit form,会出现如下,等排到队,状态就成为 in progress了,正在处理下载。
经实践,一般白天上午10点后到下午三四点,下载速度相对快点,另外,周末也会好点。毕竟是老外的网站,他们在休息肯定会顺畅点。
END
参考资料
边栏推荐
- MySQL winter vacation self-study 2022 11 (5)
- Six stone management: why should leaders ignore product quality
- [matlab] access of variables and files
- RobotFramework入门(三)WebUI自动化之百度搜索
- CobaltStrike-4.4-K8修改版安装使用教程
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 23
- What should we pay attention to when using the built-in tool to check the health status in gbase 8C database?
- [Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 6
- Microsoft speech synthesis assistant v1.3 text to speech tool, real speech AI generator
- Which ecology is better, such as Mi family, graffiti, hilink, zhiting, etc? Analysis of five mainstream smart brands
猜你喜欢
故障分析 | MySQL 耗尽主机内存一例分析

Reset nodejs of the system
MySQL winter vacation self-study 2022 11 (9)

Is there a completely independent localization database technology
淘宝焦点图布局实战
![[kubernetes series] learn the exposed application of kubernetes service security](/img/61/4564230feeb988886fe595e3125ef4.png)
[kubernetes series] learn the exposed application of kubernetes service security
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 18](/img/1a/94ef8be5c06c2d1c52fc8ce7f03ea7.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 18
Solution: attributeerror: 'STR' object has no attribute 'decode‘
Pure QT version of Chinese chess: realize two-man, man-machine and network games
【若依(ruoyi)】启用迷你导航栏
随机推荐
Follow the mouse's angle and keyboard events
2345 file shredding, powerful file deletion tool, unbound pure extract version
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 11
A copy can also produce flowers
Pat 1084 broken keyboard (20 points) string find
Network Security Learning - Web vulnerabilities (Part 1)
Master data management theory and Practice
【若依(ruoyi)】启用迷你导航栏
Communication between microservices
建模规范:命名规范
Data preparation
MySQL winter vacation self-study 2022 11 (9)
故障分析 | MySQL 耗尽主机内存一例分析
Function knowledge points
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 8
Six stone management: why should leaders ignore product quality
MySQL winter vacation self-study 2022 11 (8)
Universal crud interface
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 12
MySQL winter vacation self-study 2022 11 (7)