当前位置:网站首页>精解四大集合框架:List 核心知识总结
精解四大集合框架:List 核心知识总结
2022-07-31 05:08:00 【倾听铃的声】

Java 集合框架早也是个老话题了,今天主要是总结一下关于 Java 中的集合框架 List 的核心知识点。肯定有人会问,这篇写的是 List 那接下来就还有三篇?是的,java 集合框架一共会有四篇。希望通过这个系列能让你全面的 get 到 Java 集合框架的核心知识点。
目的
更希望通过这个系列的文章有所收获,不仅可以用于工作中,也可以用于面试中。
Java 集合是一个存储相同类型数据的容器,类似数组,集合可以不指定长度,但是数组必须指定长度。集合类主要从 Collection 和 Map 两个根接口派生出来,比如常用的 ArrayList、LinkedList、HashMap、HashSet、ConcurrentHashMap 等等。包目录:java.util
学过 Java 的都知道 Java 有四大集合框架,JDK 版本 1.8
List
Set
Queue
Map
常用集合 UML 类图
下面展示常用的集合框架(下面图中的两种线:虚线为实现,实线为继承)

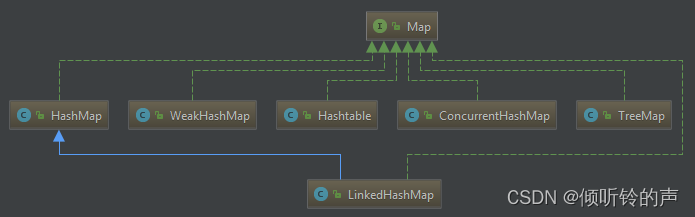
ArrayList
ArrayList 是基于动态数组实现,容量能自动增长的集合。随机访问效率高,随机插入、随机删除效率低。线程不安全,多线程环境下可以使用 Collections.synchronizedList(list) 函数返回一个线程安全的 ArrayList 类,也可以使用 concurrent 并发包下的 CopyOnWriteArrayList 类。
动态数组,是指当数组容量不足以存放新的元素时,会创建新的数组,然后把原数组中的内容复制到新数组。
主要属性:
1//存储实际数据,使用transient修饰,序列化的时不会被保存
2transient Object[] elementData;
3//元素的数量,即容量。
4private int size;
数据结构:动态数组
特征:
允许元素为 null;
查询效率高、插入、删除效率低,因为大量 copy 原来元素;
线程不安全。
使用场景:
需要快速随机访问元素
单线程环境
常用方法介绍
add(element) 流程:添加元素
1 private static final int DEFAULT_CAPACITY = 10;
2 //添加的数据e放在list的后面
3 public boolean add(E e) {
4 ensureCapacityInternal(size + 1);
5 elementData[size++] = e;
6 return true;
7 }
8 private void ensureCapacityInternal(int minCapacity) {
9 ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
10 }
11 private static int calculateCapacity(Object[] elementData, int minCapacity) {
12 if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
13 return Math.max(DEFAULT_CAPACITY, minCapacity);
14 }
15 return minCapacity;
16 }判断当前数组是否为空,如果是则创建长度为 10(默认)的数组,因为 new ArrayList 的时没有初始化;
判断是否需要扩容,如果当前数组的长度加 1(即 size+1)后是否大于当前数组长度,则进行扩容 grow();
最后在数组末尾添加元素,并 size+1。
grow() 流程:扩容
1 private void grow(int minCapacity) {
2 // overflow-conscious code
3 int oldCapacity = elementData.length;
4 int newCapacity = oldCapacity + (oldCapacity >> 1);
5 if (newCapacity - minCapacity < 0)
6 newCapacity = minCapacity;
7 if (newCapacity - MAX_ARRAY_SIZE > 0)
8 newCapacity = hugeCapacity(minCapacity);
9 // minCapacity is usually close to size, so this is a win:
10 elementData = Arrays.copyOf(elementData, newCapacity);
11 }创建新数组,长度扩大为原数组的 1.5 倍(oldCapacity >> 1 就是相当于 10>>1==10/2=5,二进制位运算);
如果扩大 1.5 倍还是不够,则根据实际长度来扩容,比如 addAll() 场景;
将原数组的数据使用 System.arraycopy(native 方法)复制到新数组中。
add(index,element) 流程:向指定下标添加元素
1 public void add(int index, E element) {
2 rangeCheckForAdd(index);
3
4 ensureCapacityInternal(size + 1); // Increments modCount!!
5 System.arraycopy(elementData, index, elementData, index + 1,
6 size - index);
7 elementData[index] = element;
8 size++;
9 }
10 private void rangeCheckForAdd(int index) {
11 if (index > size || index < 0)
12 throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
13 }检查 index 是否在数组范围内,假如数组长度是 2,则 index 必须 >=0 并且 <=2,否则报 IndexOutOfBoundsException 异常;
扩容检查;
通过拷贝方式,把数组位置为 index 至 size-1 的元素都往后移动一位,腾出位置之后放入元素,并 size+1。
set(index,element) 流程:设置新值,返回旧值
1 public E set(int index, E element) {
2 rangeCheck(index);
3
4 E oldValue = elementData(index);
5 elementData[index] = element;
6 return oldValue;
7 }
8 private void rangeCheck(int index) {
9 if (index >= size)
10 throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
11 }检查 index 是否在数组范围内,假如数组长度是 2,则 index 必须 小于<2,下标是从 0 开始的,size=2 说明下标只有 0 和 1;
保留被覆盖的值,因为最后需要返回旧的值;
新元素覆盖位置为 index 的旧元素,返回旧值。
get(index) 流程:通过下标获取 list 中的数据
1 public E get(int index) {
2 rangeCheck(index);
3 return elementData(index);
4 }
判断下标有没有越界;
直接通过数组下标来获取数组中对应的元素,get 的时间复杂度是 O(1)。
remove(index) 流程:按照下标移除 lsit 中的数据
1 public E remove(int index) {
2 rangeCheck(index);
3 modCount++;
4 E oldValue = elementData(index);
5 int numMoved = size - index - 1;
6 if (numMoved > 0)
7 System.arraycopy(elementData, index+1, elementData, index,
8 numMoved);
9 elementData[--size] = null; // clear to let GC do its work
10 return oldValue;
11 }检查指定位置是否在数组范围内,假如数组长度是 2,则 index 必须 >=0 并且 < 2;
保留要删除的值,因为最后需要返回旧的值;
计算出需要移动元素个数,再通过拷贝使数组内位置为 index+1 到 size-1 的元素往前移动一位,把数组最后一个元素设置为 null(精辟小技巧),返回旧值。
remove(object) 流程:
1 public boolean remove(Object o) {
2 if (o == null) {
3 for (int index = 0; index < size; index++)
4 if (elementData[index] == null) {
5 fastRemove(index);
6 return true;
7 }
8 } else {
9 for (int index = 0; index < size; index++)
10 if (o.equals(elementData[index])) {
11 fastRemove(index);
12 return true;
13 }
14 }
15 return false;
16 }
17 private void fastRemove(int index) {
18 modCount++;
19 int numMoved = size - index - 1;
20 if (numMoved > 0){
21 //数组拷贝
22 System.arraycopy(elementData, index+1, elementData, index,
23 numMoved);
24 }
25 //方便GC
26 elementData[--size] = null;
27 }遍历数组,比较 obejct 是否存在于数组中;
计算出需要移动元素个数,再通过拷贝使数组内位置为 index+1 到 size-1 的元素往前移动一位,把数组最后一个元素设置为 null(精辟小技巧)。
总结:
new ArrayList 创建对象时,如果没有指定集合容量则初始化为 0;如果有指定,则按照指定的大小初始化;
扩容时,先将集合扩大 1.5 倍,如果还是不够,则根据实际长度来扩容,保证都能存储所有数据,比如 addAll() 场景。
如果新扩容后数组长度大于(Integer.MAX_VALUE-8),则抛出 OutOfMemoryError。
建议在使用的时候,先评估一下要存多少数据,然后就可以大致或者准确的给 ArrayList 指定大小,这样就会避免不断多次扩容对系统带来的开销。
LinkedList
LinkedList 是可以在任何位置进行插入和移除操作的有序集合,它是基于双向链表实现的,线程不安全。LinkedList 功能比较强大,可以实现栈、队列或双向队列。
主要属性:
1//链表长度
2transient int size = 0;
3//头部节点
4transient Node<E> first;
5//尾部节点
6transient Node<E> last;
7
8/**
9* 静态内部类,存储数据的节点
10* 前驱结点、后继结点,那证明至少是双向链表
11*/
12private static class Node<E> {
13 //自身结点
14 E item;
15 //下一个节点
16 Node<E> next;
17 //上一个节点
18 Node<E> prev;
19}数据结构:双向链表
特征:
允许元素为 null;
插入和删除效率高,查询效率低;
顺序访问会非常高效,而随机访问效率(比如 get 方法)比较低;
既能实现栈 Stack(后进先出),也能实现队列(先进先出), 也能实现双向队列,因为提供了 xxxFirst()、xxxLast() 等方法;
线程不安全。
使用场景:
需要快速插入,删除元素
按照顺序访问其中的元素
单线程环境
add() 流程:
1 public boolean add(E e) {
2 linkLast(e);
3 return true;
4 }
5 void linkLast(E e) {
6 final Node<E> l = last;
7 final Node<E> newNode = new Node<>(l, e, null);
8 last = newNode;
9 if (l == null)
10 first = newNode;
11 else
12 l.next = newNode;
13 size++;
14 modCount++;
15 }创建一个新结点,结点元素 e 为传入参数,前继节点 prev 为“当前链表 last 结点”,后继节点 next 为 null;
判断当前链表 last 结点是否为空,如果是则把新建结点作为头结点,如果不是则把新结点作为 last 结点。
最后返回 true。
get(index) 流程:
1 public E get(int index) {
2 checkElementIndex(index);
3 return node(index).item;
4 }
5 /**
6 * Returns the (non-null) Node at the specified element index.
7 */
8 Node<E> node(int index) {
9 if (index < (size >> 1)) {
10 Node<E> x = first;
11 for (int i = 0; i < index; i++)
12 x = x.next;
13 return x;
14 } else {
15 Node<E> x = last;
16 for (int i = size - 1; i > index; i--)
17 x = x.prev;
18 return x;
19 }
20 }
21 private void checkElementIndex(int index) {
22 if (!isElementIndex(index))
23 throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
24 }
25 private boolean isElementIndex(int index) {
26 return index >= 0 && index < size;
27 }检查 index 是否在数组范围内,假如数组长度是 2,则 index 必须 >=0 并且 < 2;
index 小于“双向链表长度的 1/2”则从头开始往后遍历查找,否则从链表末尾开始向前遍历查找。
remove() 流程:
1 public E remove(int index) {
2 checkElementIndex(index);
3 return unlink(node(index));
4 }
5 private void checkElementIndex(int index) {
6 if (!isElementIndex(index))
7 throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
8 }
判断 first 结点是否为空,如果是则报 NoSuchElementException 异常;
如果不为空,则把待删除结点的 next 结点的 prev 属性赋值为 null,达到删除头结点的效果。
返回删除值。
Vector
Vector 是矢量队列,也是基于动态数组实现,容量可以自动扩容。跟 ArrayList 实现原理一样,但是 Vector 是线程安全,使用 Synchronized 实现线程安全,性能非常差,已被淘汰,使用 CopyOnWriteArrayList 替代 Vector。
主要属性:
1//存储实际数据
2protected Object[] elementData;
3//动态数组的实际大小
4protected int elementCount;
5//动态数组的扩容系数
6protected int capacityIncrement;
数据结构:动态数组
特征:
允许元素为 null;
查询效率高、插入、删除效率低,因为需要移动元素;
默认的初始化大小为 10,没有指定增长系数则每次都是扩容一倍,如果扩容后还不够,则直接根据参数长度来扩容;
线程安全,性能差(Synchronized),使用 CopyOnWriteArrayList 替代 Vector。
使用场景:多线程环境
为什么是线程安全的,看看下面的几个常用方法就知道了。
1 public synchronized void addElement(E obj) {
2 modCount++;
3 ensureCapacityHelper(elementCount + 1);
4 elementData[elementCount++] = obj;
5 }
6 public boolean remove(Object o) {
7 return removeElement(o);
8 }
9 public synchronized boolean removeElement(Object obj) {
10 modCount++;
11 int i = indexOf(obj);
12 if (i >= 0) {
13 removeElementAt(i);
14 return true;
15 }
16 return false;
17 }
18 public synchronized E get(int index) {
19 if (index >= elementCount)
20 throw new ArrayIndexOutOfBoundsException(index);
21
22 return elementData(index);
23 }
24 public synchronized boolean add(E e) {
25 modCount++;
26 ensureCapacityHelper(elementCount + 1);
27 elementData[elementCount++] = e;
28 return true;
29 }这几个常用方法中,方法都是使用同步锁 synchronized 修饰,所以它是线程安全的。
Stack
Stack 是栈,先进后出原则,Stack 继承 Vector,也是通过数组实现,线程安全。因为效率比较低,不推荐使用,可以使用 LinkedList(线程不安全)或者 ConcurrentLinkedDeque(线程安全)来实现先进先出的效果。
数据结构:动态数组
构造函数:只有一个默认 Stack()
特征:先进后出
实现原理:
Stack 执行 push() 时,将数据推进栈,即把数据追加到数组的末尾。
Stack 执行 peek 时,取出栈顶数据,不删除此数据,即获取数组首个元素。
Stack 执行 pop 时,取出栈顶数据,在栈顶删除数据,即删除数组首个元素。
Stack 继承于 Vector,所以 Vector 拥有的属性和功能,Stack 都拥有,比如 add()、set() 等等。
1public class Stack<E> extends Vector<E> {
2//....
3}
CopyOnWriteArrayList
CopyOnWriteArrayList 是线程安全的 ArrayList,写操作(add、set、remove 等等)时,把原数组拷贝一份出来,然后在新数组进行写操作,操作完后,再将原数组引用指向到新数组。CopyOnWriteArrayList 可以替代 Collections.synchronizedList(List list)。这个是在 JUC 包目录下的。内部使用了 AQS 实现的锁。
java.util.concurrent
数据结构:动态数组
特征:
线程安全;
读多写少,比如缓存;
不能保证实时一致性,只能保证最终一致性。
缺点:
写操作,需要拷贝数组,比较消耗内存,如果原数组容量大的情况下,可能触发频繁的 Young GC 或者 Full GC;
不能用于实时读的场景,因为读取到数据可能是旧的,可以保证最终一致性。
实现原理:
CopyOnWriteArrayList 写操作加了锁,不然多线程进行写操作时会复制多个副本;读操作没有加锁,所以可以实现并发读,但是可能读到旧的数据,比如正在执行读操作时,同时有多个写操作在进行,遇到这种场景时,就会都到旧数据。
1public class CopyOnWriteArrayList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
2 private static final long serialVersionUID = 8673264195747942595L;
3
4 /** The lock protecting all mutators */
5 final transient ReentrantLock lock = new ReentrantLock();
6 //添加数据
7 public boolean add(E e) {
8 //使用到了锁机制
9 final ReentrantLock lock = this.lock;
10 lock.lock();
11 try {
12 Object[] elements = getArray();
13 int len = elements.length;
14 Object[] newElements = Arrays.copyOf(elements, len + 1);
15 newElements[len] = e;
16 setArray(newElements);
17 return true;
18 } finally {
19 //释放锁
20 lock.unlock();
21 }
22 }
23 //移除数据
24 public E remove(int index) {
25 //锁机制
26 final ReentrantLock lock = this.lock;
27 lock.lock();
28 try {
29 Object[] elements = getArray();
30 int len = elements.length;
31 E oldValue = get(elements, index);
32 int numMoved = len - index - 1;
33 if (numMoved == 0)
34 setArray(Arrays.copyOf(elements, len - 1));
35 else {
36 Object[] newElements = new Object[len - 1];
37 System.arraycopy(elements, 0, newElements, 0, index);
38 System.arraycopy(elements, index + 1, newElements, index,
39 numMoved);
40 setArray(newElements);
41 }
42 return oldValue;
43 } finally {
44 //释放锁
45 lock.unlock();
46 }
47 }好的,以上便是今天分享的内容。希望你有所收获。
对老铁最大鼓励就是点个在看&&转发 在看||转发。可二选一。哈哈哈!
边栏推荐
- Mysql application cannot find my.ini file after installation
- Gaussian distribution and its maximum likelihood estimation
- Workflow番外篇
- MYSQL下载及安装完整教程
- Centos7 install mysql5.7
- 1. Get data - requests.get()
- MySQL8.0安装教程,在Linux环境安装MySQL8.0教程,最新教程 超详细
- Interview | Cheng Li, CTO of Alibaba: Cloud + open source together form a credible foundation for the digital world
- MySQL transaction isolation level, rounding
- MySQL常见面试题汇总(建议收藏!!!)
猜你喜欢






随机推荐
ERROR 2003 (HY000) Can't connect to MySQL server on 'localhost3306' (10061)Solution
Doris学习笔记之监控
【线性神经网络】softmax回归
MySQL transaction isolation level, rounding
MySQL事务(transaction) (有这篇就足够了..)
matlab simulink欠驱动水面船舶航迹自抗扰控制研究
城市内涝及桥洞隧道积水在线监测系统
Unity框架设计系列:Unity 如何设计网络框架
Unity手机游戏性能优化系列:针对CPU端的性能调优
Workflow番外篇
On Governance and Innovation | 2022 OpenAtom Global Open Source Summit OpenAnolis sub-forum was successfully held
MySQL transaction (transaction) (this is enough..)
Error EPERM operation not permitted, mkdir 'Dsoftwarenodejsnode_cache_cacach Two solutions
Lua,ILRuntime, HybridCLR(wolong)/huatuo hot update comparative analysis
Duplicate entry 'XXX' for key 'XXX.PRIMARY' solution.
Visual studio shortcuts that improve efficiency, summary (updated from time to time)
12个MySQL慢查询的原因分析
Temporal介绍
[py script] batch binarization processing images
ERROR 1064 (42000) You have an error in your SQL syntax; check the manual that corresponds to your