当前位置:网站首页>Transformation 和 Action 常用算子
Transformation 和 Action 常用算子
2022-08-05 05:12:00 【价值成长】
一、Transformation
| Transformation 算子 | Meaning(含义) |
|---|---|
| map(func) | 对原 RDD 中每个元素运用 func 函数,并生成新的 RDD |
| filter(func) | 对原 RDD 中每个元素使用func 函数进行过滤,并生成新的 RDD |
| flatMap(func) | 与 map 类似,但是每一个输入的 item 被映射成 0 个或多个输出的 items( func 返回类型需要为 Seq )。 |
| mapPartitions(func) | 与 map 类似,但函数单独在 RDD 的每个分区上运行, func函数的类型为 Iterator<T> => Iterator<U> ,其中 T 是 RDD 的类型,即 RDD[T] |
| mapPartitionsWithIndex(func) | 与 mapPartitions 类似,但 func 类型为 (Int, Iterator<T>) => Iterator<U> ,其中第一个参数为分区索引 |
| sample(withReplacement, fraction, seed) | 数据采样,有三个可选参数:设置是否放回(withReplacement)、采样的百分比(fraction)、随机数生成器的种子(seed); |
| union(otherDataset) | 合并两个 RDD |
| intersection(otherDataset) | 求两个 RDD 的交集 |
| distinct([numTasks])) | 去重 |
| groupByKey([numTasks]) | 按照 key 值进行分区,即在一个 (K, V) 对的 dataset 上调用时,返回一个 (K, Iterable<V>) Note: 如果分组是为了在每一个 key 上执行聚合操作(例如,sum 或 average),此时使用 reduceByKey 或 aggregateByKey 性能会更好Note: 默认情况下,并行度取决于父 RDD 的分区数。可以传入 numTasks 参数进行修改。 |
| reduceByKey(func, [numTasks]) | 按照 key 值进行分组,并对分组后的数据执行归约操作。 |
| aggregateByKey(zeroValue,numPartitions)(seqOp, combOp, [numTasks]) | 当调用(K,V)对的数据集时,返回(K,U)对的数据集,其中使用给定的组合函数和 zeroValue 聚合每个键的值。与 groupByKey 类似,reduce 任务的数量可通过第二个参数进行配置。 |
| sortByKey([ascending], [numTasks]) | 按照 key 进行排序,其中的 key 需要实现 Ordered 特质,即可比较 |
| join(otherDataset, [numTasks]) | 在一个 (K, V) 和 (K, W) 类型的 dataset 上调用时,返回一个 (K, (V, W)) pairs 的 dataset,等价于内连接操作。如果想要执行外连接,可以使用 leftOuterJoin, rightOuterJoin 和 fullOuterJoin 等算子。 |
| cogroup(otherDataset, [numTasks]) | 在一个 (K, V) 对的 dataset 上调用时,返回一个 (K, (Iterable<V>, Iterable<W>)) tuples 的 dataset。 |
| cartesian(otherDataset) | 在一个 T 和 U 类型的 dataset 上调用时,返回一个 (T, U) 类型的 dataset(即笛卡尔积)。 |
| coalesce(numPartitions) | 将 RDD 中的分区数减少为 numPartitions。 |
| repartition(numPartitions) | 随机重新调整 RDD 中的数据以创建更多或更少的分区,并在它们之间进行平衡。 |
| repartitionAndSortWithinPartitions(partitioner) | 根据给定的 partitioner(分区器)对 RDD 进行重新分区,并对分区中的数据按照 key 值进行排序。这比调用 repartition 然后再 sorting(排序)效率更高,因为它可以将排序过程推送到 shuffle 操作所在的机器。 |
二、Action
| Action(动作) | Meaning(含义) |
|---|---|
| reduce(func) | 使用函数func执行归约操作 |
| collect() | 以一个 array 数组的形式返回 dataset 的所有元素,适用于小结果集。 |
| count() | 返回 dataset 中元素的个数。 |
| first() | 返回 dataset 中的第一个元素,等价于 take(1)。 |
| take(n) | 将数据集中的前 n 个元素作为一个 array 数组返回。 |
| takeSample(withReplacement, num, [seed]) | 对一个 dataset 进行随机抽样 |
| takeOrdered(n, [ordering]) | 按自然顺序(natural order)或自定义比较器(custom comparator)排序后返回前 n 个元素。只适用于小结果集,因为所有数据都会被加载到驱动程序的内存中进行排序。 |
| saveAsTextFile(path) | 将 dataset 中的元素以文本文件的形式写入本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中。Spark 将对每个元素调用 toString 方法,将元素转换为文本文件中的一行记录。 |
| saveAsSequenceFile(path) | 将 dataset 中的元素以 Hadoop SequenceFile 的形式写入到本地文件系统、HDFS 或其它 Hadoop 支持的文件系统中。该操作要求 RDD 中的元素需要实现 Hadoop 的 Writable 接口。对于 Scala 语言而言,它可以将 Spark 中的基本数据类型自动隐式转换为对应 Writable 类型。(目前仅支持 Java and Scala) |
| saveAsObjectFile(path) | 使用 Java 序列化后存储,可以使用 SparkContext.objectFile() 进行加载。(目前仅支持 Java and Scala) |
| countByKey() | 计算每个键出现的次数。 |
| foreach(func) | 遍历 RDD 中每个元素,并对其执行fun函数 |
边栏推荐
- "Recursion" recursion concept and typical examples
- The difference between span tag and p
- 判断语句_switch与case
- Analysis of Mvi Architecture
- Flutter学习4-基本UI组件
- 1068 Find More Coins
- Community Sharing|Tencent Overseas Games builds game security operation capabilities based on JumpServer
- dedecms织梦tag标签不支持大写字母修复
- Cryptography Series: PEM and PKCS7, PKCS8, PKCS12
- Multi-threaded query results, add List collection
猜你喜欢

大学物理---质点运动学

Multi-threaded query results, add List collection
类的底层机制

Reverse theory knowledge 4

Application status of digital twin technology in power system
![[Surveying] Quick Summary - Excerpt from Gaoshu Gang](/img/35/e5c5349b8d4ccf9203c432a9aaee7b.png)
[Surveying] Quick Summary - Excerpt from Gaoshu Gang

使用二维码解决固定资产管理的难题
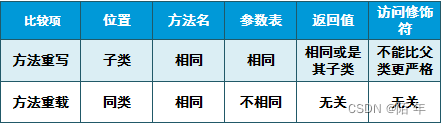
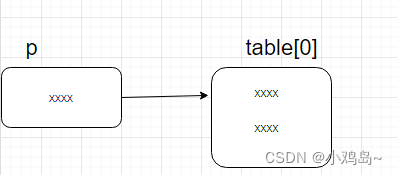
Day019 Method overriding and introduction of related classes

雷克萨斯lm的安全性到底体现在哪里?一起来看看吧
Flutter真机运行及模拟器运行
随机推荐
服务器磁盘阵列
How to identify false evidence and evidence?
"Recursion" recursion concept and typical examples
What field type of MySQL database table has the largest storage length?
WPF中DataContext作用
Dephi reverse tool Dede exports function name MAP and imports it into IDA
flex布局青蛙游戏通关攻略
Shell(4)条件控制语句
Day019 方法重写与相关类的介绍
server disk array
Qt produces 18 frames of Cupid to express his love, is it your Cupid!!!
【cesium】元素高亮显示
Flutter真机运行及模拟器运行
Requests the library deployment and common function
二叉树基本性质+oj题解析
雷克萨斯lm的安全性到底体现在哪里?一起来看看吧
Difference between for..in and for..of
淘宝账号如何快速提升到更高等级
Mini Program_Dynamic setting of tabBar theme skin
Flutter学习2-dart学习