当前位置:网站首页>Exploration and practice of incremental data Lake in station B
Exploration and practice of incremental data Lake in station B
2022-06-26 07:30:00 【Past memory】
1、 background
as everyone knows , The more real-time data is, the more valuable it is . live broadcast 、 recommend 、 There are more and more scenarios in audit and other fields that need near real-time data for data analysis . We have encountered many pain points in the process of exploring and practicing the incremental data lake , Such as timeliness 、 There is a problem that the storage media integrating data integration, synchronization and batch flow are not unified . This article will introduce our thinking and practical solutions to these pain points .
1.1 Time sensitive pain point
The traditional counting warehouse takes hours / Sky level partition , Only when the data is complete . However , Some users do not need data integrity , Just do some trend analysis with the latest data . therefore , The current situation cannot meet the increasingly strong data timeliness needs of users . Traditional warehouse ETL After the last task , To start the next mission . Even hourly partitions , The more hierarchical processing , The lower the timeliness of the final output of data .
1.2 Data integration synchronization pain points
The mature solution in the industry is through Alibaba datax System synchronization mysql From library data to hive surface . Periodically synchronize in full or incremental quantities . The slave library needs to be set separately to cope with the data synchronization db Requested pressure . Besides ,db High cost from the warehouse , Can not be ignored .
Incremental synchronization faces the problem of how to modify historical partition data . If a piece of data is updated , Then only incremental synchronization , There may be pre update and post update data in the two partitions . You need to merge and update the data by yourself , Can be used .
1.3 The batch stream integrated storage media is not unified
Downstream of the business, there are timeliness requirements , Also offline ETL scene .Flink sql The flow batch calculation process can be unified , But no unified storage , Still need to be real-time 、 Offline data is stored separately in kafka、hdfs.
2、 Think and plan
The incremental data Lake construction adopts Flink + Hudi. We need data lake ACID Business support 、 Stream batch read / write operation support . also , be relative to Iceberg The design of the ,Hudi Yes Upsert At the beginning of the support design, the main support scheme is upsert Ability 、 There are obvious advantages in the ability to merge small files .Append The performance is gradually improved in the version iteration . Active communities are iterating over incremental consumption 、 Flow consumption capacity . Comprehensive comparison , The final choice is based on Hudi Build an incremental data lake ecosystem .
3、HUDI Kernel optimization
Hudi cow The mode needs to be merged every time it is written , Yes io Zoom in on the problem .Hudi 0.8 I'm in support of mor Pattern , Only some data files that need to be updated are updated .
But this will cause data quality problems , Mainly data loss in some extreme cases 、 Duplicate data 、 Data latency issues . We found some problems in the actual test production process , Try to solve it and give feedback to the community .
3.1 Underlying data reliability optimization
Hudi compaction Approximate code structure

StreamWriteOperatorCoordinator In operator notifyCheckpointComplete Logic :
Commit the current transaction and transfer the metadata deltacommit write in hdfs
Call scheduling to generate compant Carry out the plan and will compact.requested Metadata writing hdfs
Start the next transaction
CompactionPlanOperator In operator notifyCheckpointComplete Logic :
stay 0.9 In the version sheduleCompation Method to get the last compact Implementation plan
take compact.requested The execution plan is translated into CompactionPlanEvent Issue to downstream
CompactFuncation
processElement Finally, execute doCompaction Complete the merger
3.1.1 log Skip the bad block bug, Cause data loss

hudi log The files are made up of block Block composition , One log There may be more than one deltacommit Block information written , Each block passes through MAGIC Segmentation , The contents of each block are shown in the figure above . among Block Header Each block's deltacommit instantTime, stay compact Will scan and read the blocks to be merged .HoodieLogFileReader It's for reading log file , Will log The file is converted into block objects . First it will read MAGIC Separate , If it exists, the total size of the next location block will be read , Determine whether it exceeds the total size of the current file to define whether it is a bad block , Detecting a bad block skips the contents of the bad block and creates a bad block object HoodieCorruptBlock, The bad block skipped is from the current block total size The location is retrieved later MAGIC(#HUDI#), Each read 1 Megabytes , Read until the next MAGIC Until split , find MAGIC Then jump to the current MAGIC Location , You can then read the complete block information .
The position of the bad block mentioned above is from block total size Location retrieved later , In extreme cases, files are written only MAGIC If the content has not been written to the content task, an exception will occur , A continuous... Is written MAGIC, In the process of reading MAGIC treat as Block Total size Read , During the retrieval process, the next normal block will be skipped , Return as a bad block . In the process of merging, this part of block data is lost . The bad block position skipped here should be from MAGIC Then start searching instead of block total size after , Continuous... Occurs while reading MAGIC The normal block will not be skipped .
relevant pr:https://github.com/apache/hudi/pull/4015
3.1.2 compaction And rolled back log Merge , Resulting in data duplication
stay HoodieMergedLogRecordScanner Will scan for valid block information , In extreme cases log Block writes for file writes are complete , however deltacommit The task before metadata submission failed , also log The block information in is also better than deltacommit Metadata instant Time Still small , At this point, the blocks that will be considered valid are merged . because deltacommit The metadata was not written successfully ,check point Restart to play back the previous data . Assigned during playback flieId It may be different , When this part of data is merged, data duplication will be found and fileId Different phenomena .
Scanning log Whether it is a valid block , If the current timeline is smaller than the metadata of the existing timeline that is not archived , Add archived timelines , Determine whether it is a valid block by collaboration , No longer only non archived timelines are used as filter criteria .
relevant pr:https://github.com/apache/hudi/pull/5052
3.1.3 Data discontinuity scenario , The last data does not trigger compaction, Lead to RO Table data delay
Dispatch in the above process compaction The execution plan cannot be triggered until the last transaction is successfully committed , If a piece of data is not written ,compact Even if the time condition or commit The number condition will not be formed compact Implementation plan . Upstream does not implement the plan downstream Compaction The operator does not trigger a merge , The user is looking for ro surface , Some data will not be found .
Must be removed commitInstant Only after the submission is successful can the generation be scheduled compact Execution plan binding , Every time checkpoint After that, check whether the conditions are met to trigger and generate Compaction Implementation plan , Avoid that the latest data cannot be merged . When there is no new data written to the scene, the metadata is only deltacommit.requested and deltacommit.inflight Metadata cannot be used directly when the current time is compact instantTime. The upstream may write data at any time to avoid merging unfinished data , It's generating compact The execution plan will also check the metadata deltacommit and compact Metadata avoids merging unfinished data . here compact instantTime Can be for the recently unfinished deltacommit instantTime And the latest completion compact Time between . This produces compaction The execution plan metadata is completed downstream compact The merger will not be delayed .
relevant pr:https://github.com/apache/hudi/pull/3928
3.1.4 CompactionPlanOperator Only take the last time each time compaction, Cause data delay
stay StreamWriteOperatorCoordinator operator notifyCheckpointComplete In this way compact Implementation plan , stay CompactionPlanOperator operator notifyCheckpointComplete In the method, the consumption execution plan is distributed to consolidate data . In extreme cases, if set compact The strategy is a commit It triggers compact Merge operation , So in two operators notifyCheckpointComplete Will continue to produce and consume compact Implementation plan , Once the end of the consumption compact An exception occurred and the task failed , It will pile up a lot compact.requested Implementation plan , And every time CompactionPlanOperator Only one execution plan metadata will be obtained , In this way, the data will be stacked and delayed , There is always a part of the implementation plan that cannot be implemented . stay 0.8 Take the last version compaction Implementation plan , It will be new commit Has been merging , The old data has been unable to be merged, resulting in the illusion of lost data . The follow-up community will get the latest one , If the downstream fails for some reason compact Execute plan squeeze , Data latency is going to get bigger and bigger .
CompactionPlanOperator Get all compact The execution plan is translated into CompactionPlanEvent Issue to downstream , take CompactFunction Method to the default synchronization mode . The bottom layer in asynchronous mode uses newSingleThreadExecutor The thread pool avoids holding a large number of objects in the synchronized process queue .
relevant pr:https://issues.apache.org/jira/browse/HUDI-3618
3.1.5 log There is no timeline block in ,parquet File regeneration , Previous records are missing

compact The execution plan contains multiple HoodieCompactionOperation, Every HoodieCompactionOperation contain log Document and parquet file , But maybe only logFlies It indicates that only new data is added . Doing it compact When you merge, you get HoodieCompactionOperation Medium log Document and parquet file information , structure HoodieMergedLogRecordScanner take log The block data in the file that meets the merging requirements is flushed in ExternalSpillableMap in , stay merge Stage basis parquet Data and ExternalSpillableMap The data is compared and merged to form a new parquet file , New documents instantTime by compact Of instantTime.
stay HoodieMergedLogRecordScanner Medium scan log file In file , Need to meet the timeline requirements log Piece of information , If no matching block is scanned to , Follow up merge The operation will not run , new parquet There is no file version . The next time compact Obtained from the execution plan of FileSlice There will only be log File without parquet file , In execution compact runMerge It will be written to when the new operation is added , Not merged with the previous parquet All data before data merging is lost , new parquet Only the next time in the file log Data generated , Cause data loss .
Whether the scanning meets the requirements or not , Block information is forced to be written to the new parquet file , So next time compact Obtained from the merge execution plan FileSlice There will be log Document and parquet file , It can be done normally handleUpdate Merge , Ensure that data is not lost .
3.2 Table Service Optimize
3.2.1 independent table service -- compaction plugin
background :
At present, the community provides a variety of table service programs , But in actual production application , Especially in the process of platformization , Will face a variety of problems .
Analysis of the original plan :
In order to compare the characteristics of each scheme , We are based on hudi v0.9 Provide table services for analysis .
First , We disassemble the table service into scheduling + perform 2 The process of stages .
According to whether to execute immediately after dispatching , Scheduling can be divided into inline Dispatch ( That is to say, execute immediately after dispatching ) And async Dispatch ( That is, after scheduling, only plan, Not immediately ) Two kinds of ,
Depending on how the call is executed , Can be divided into sync perform ( Synchronous execution )、async perform ( Through the corresponding service Asynchronous execution , Such as AsyncCleanService) Two kinds of ,
Besides , Relative to writing job, Table service as a data choreography job, It is essentially different from writing job Of , Depending on whether these services are embedded in the write job in , We call them embedded patterns and standalone Mode two modes .
following , For the community Flink on Hudi To analyze various table service schemes :
Scheme 1 Embedded synchronous mode : stay ingestion In homework ,inline schedule + sync compact/cluster & inline schedule clean + async clean

The problem with this pattern is obvious : After each write , Immediately schedule and execute through inline compact Homework , Start a new one after it is finished instant, In the process, it directly affects the performance of data writing , It will not be used in actual production .
Option two Embedded asynchronous mode : stay ingestion In homework , async schedule + sync/async compact/cluster && inline schedule + sync/async clean

It's different from plan one , This mode will consume more resources compact/cluster And other operations are asynchronized to special operators ,ingestion The process retains only light scheduling operations , Yes clean Operation adds synchronization / Asynchronous selection .
But there are still shortcomings ,ingestion Streaming of jobs , Superimpose intermittent batch processing of the table service , The addition of the resource consumption curve causes a lot of impulse burrs , Even a lot of homework oom The culprit of , This makes it necessary to reserve enough resources for job configuration , Waste high priority resources in idle time .
Option three standalone Pattern :ingestion Homework + compact/cluster Job mix
At present, the scheme is not perfect , Refer to scheme 1 for the written operation process , Yes compact/cluster/clean etc. action Provide separate choreography , With compact For example ,HoodieFlinkCompactor The process is as follows :

The scheme abstracts out a separate data arrangement job , Isolated from the job level , It overcomes the disadvantages of scheme II , From the perspective of platformization , In line with our needs .
When the direction is selected , We need to face the current defects of the scheme , Including the following :
1. In the single writer Under the model , Arranging homework schedule Mode not available , Will some timeline Consistency issues , Cause data loss .
be relative to ingestion Homework ,compact/cluster job It's essentially another writer, many writer Under concurrency , In an unlocked state timeline Consistency is not guaranteed , In extreme cases, data loss may occur , As shown in the figure below :

2. The write job and the orchestration job do not standalone Collaboration capability under mode .
First , yes clean action The problem of , although hudi The kernel capabilities are sound , However, at present, the table service level only exposes inline Dispatch + Method of execution , As a result, both write and orchestration jobs will contain clean, The architecture is too chaotic and uncontrollable ;
secondly , Arrange your homework CompactPlanSource And embedded mode write job CompactPlan Are two different operators ,dag Not maintaining linearity , It is not conducive to switching between different modes ;
Besides , There is also the problem that job scheduling does not have the ability to receive external policies , Unable to platform , Integrated company intelligent scheduling 、 Expert diagnosis and other systems .
Optimization plan :
First , solve timeline Consistency issues , at present hudi The community already has occ( Optimistic concurrency control ) Support of operation mode , Distributed locks are introduced (hive metastore、zookeeper). but flink The relevant support of the module is still in the initial stage , We are also conducting corresponding application tests internally , However, it is found that there are still many problems to be solved before production and application .
Because the scheduling operation itself is light , For the time being, the table will serve scheduler Keep in write job , Still keep the order writer The model runs , To avoid more writer problem .
secondly , Targeted optimization hudi The underlying table service scheduling mechanism , take clean action It is also disassembled into scheduling + The use paradigm of execution , adopt inlineScheduleEnabled To configure , The default is true Backward compatibility , stay standalone In mode ,inlineScheduleEnabled by false.
then , Refactoring write jobs and orchestration jobs , Perfect the 3 Support for three operating modes . Specific include :
Table service for write jobs scheduler Optimize , Provide DynamicConfigProvider Support external policy integration ; rewrite Clean operator , Support switching of multiple operation modes ;
To arrange homework , Refactor the job so that the job dag It is linear with the embedded mode ; Support sheet instant, Full batch and service Resident mode ; Optimize configuration transfer between write and orchestration jobs , It can be started and stopped arbitrarily to meet the requirements of the hosting task ;
Refactored write and orchestration jobs ( With compact For example ) as follows :

3.2.2 metaStore Resolve partition ready problem
Incremental data warehouse , You need to support minute level data visibility in near real-time business scenarios , You need to create... When writing data hiveMetaStore Zone information .
Offline dependency is built hiveMetaStore Partitioning is the semantics of data integrity . How to solve it is a problem .

Task scheduling , Depending on the scheduling system . In the data ready after , Inform the dispatching system , You can schedule downstream tasks . It doesn't have much to do with the discussion of construction zones .

Offline dependency hiveMetaStore problem , We transform hiveMetaStore , Give the partition a new commit attribute , If the data is not ready be commit by false, Partition is not visible . Keep the original semantics unchanged .
about adhoc Come on , belt hint includeUnCommit=true Identity query , Data can be queried before data completion .
For offline , When partition commit Property is set to true, To find the partition . Meet the semantics that partition visibility means data integrity .

about flink job Come on , When data is first written , Create partitions , And give partitions commit=false label , bring adhoc The newly written data can be found .
After processing partition data , Judge partition data ready after , Update partition commit=true. here , data ready, The partition is visible offline , Satisfy “ Visible partition means complete data ” The semantics of the .
4、 Scene landing practice
4.1 Incremental data warehouse
Traditional warehouse TL After the last task , To start the next mission . Even hourly partitions , The more hierarchical processing , The lower the timeliness of the final output of data .

Adopt incremental calculation method , Each calculation reads the last increment . So when the upstream data is complete , It only needs to calculate the time of the last increment , It can improve the timeliness of data completion .
At the same time, the first batch of data is written to ods After a layer, it can be incrementally calculated to the next layer until the output , The data is visible , Greatly improve the visibility and timeliness of data .
The concrete way of implementation is : adopt hudi source,flink The incremental consumption hudi data . Support cross layer incremental calculation of data warehouse , Such as ods → dwd → ads All use hudi Series connection . Support to work with other data sources join、groupby, Final output continues to fall hudi.

There are high timeliness demands for audit data, etc , This scheme can be adopted to accelerate data output , Improve data visibility and timeliness .
4.2 CDC To HUDI
4.2.1 Problems faced
1. The original datax Synchronization mode In a nutshell select * , Yes mysql It is a slow query , There is a risk of blocking the service library , Therefore, it needs to be developed separately mysql Meet the warehousing requirements from the warehouse , There is a higher mysql Machine cost from the warehouse , It is one of the objects of cost reduction and efficiency increase .
2. The original synchronization method can not meet the increasing demand for timeliness , Only days are supported / Hour synchronization , Cannot support visible granularity of data up to minute level .
3. The original synchronization mode is hive surface , Do not have update Ability , If a record goes through update, It is possible to mtime This data exists for all time partitions , Business use needs to be de duplicated , High use cost .
4.2.2 Solutions
adopt flink cdc consumption mysql The incremental + Full data , branch chunk Conduct select, There is no need to open a separate warehouse mysql Slave Library .
fall hudi Support update、delete, amount to hudi Table is mysql Image of table .
It also supports minute level visibility , Meet the demands of business timeliness .
4.2.3 The overall architecture

One db The library uses a flink cdc job Conduct mysql Data synchronization , The data of a table is shunted to a kafka topic in , By a flink job Consume one kafka topic, Fall on hudi In the table .
4.2.4 Data quality assurance - No loss, no weight
flink cdc source
In a nutshell : Total quantity + The incremental adopt changlog stream Method to transfer data changes to downstream .
Full volume stage : branch chunk Read , select * + binlog correct , Read out and transmit the full data to the downstream without lock .
Incremental phase : Disguised as a slave Library , Read binlog Data is transferred to downstream .

flink
adopt flink checkpoint Mechanism , Record the processed data points to checkpoint in , If subsequent exceptions occur, start from checkpoint It can ensure that the data is not lost or duplicated .
kafka
kafka client Turn on ack = all , When all copies receive data , only ack, Make sure you don't lose data .
kafka server Guarantee replicas Greater than 1, Avoid dirty elections .
It won't open here kafka Business ( The high cost ), Guarantee at least once that will do . From downstream hudi Do not repeat .
hudi sink
hudi sink Also based on flink checkpoint The implementation is similar to the two-phase submission method , Implement data writing hudi The table is not lost .
By adding flink cdc Generated monotonically increasing “ Version field ” Compare , Write a single record with a higher version , Low abandon . At the same time, we should solve the problems of de duplication and disorderly consumption .
4.2.5 Field changes
mysql The business library has made field changes 、 How to add a new field ?
Problems faced
1. The new fields in the data platform are Security access issues , Need user confirmation , Whether encryption warehousing is required .
2. Field type change , Users are required to confirm whether downstream tasks are compatible .
3. hudi Of column evalution Limited ability , such as int turn string Type cannot support .
Solutions
And dba Appointment , Some changes can be approved automatically ( For example, add a new field 、int Type transfer long etc. ) adopt . And asynchronous notification berserker(b Station big data platform system ), from berserker change ①hudi Table information , as well as ② to update flink job Information .
Beyond the agreed change ( Such as int turn varchar etc. ), Go through manual approval , need berserker confirm ① hudi Table change completed 、② write in hudi Of flink job After the change is completed , Let it go again mysql ddl Change work order .
We transformed Flink cdc job, Perceptible mysql Field changes , Downstream kafka Send changed data , Not subject to approval , Temporarily save the changed data kafka topic in , this kafka Invisible to users . Downstream write hudi Do not change the task and consume as usual , Do not write new fields , After the user confirms that the data can be warehoused , Again from kafka Playback data , Supplementary write new field .
programme

mysql Field type and hudi There is a mismatch between types .flink job consumption kafka Define field types and hudi Table definition fields do not correspond to , need berserker I'm fighting flink sql When , The logic of the extra spell transformation .
Flink cdc sql Automatic perception of field changes
flink cdc Native sql It needs to be defined mysql Table field information , So when mysql When a field change occurs , It is inevitable that automatic perception cannot be achieved , And transfer the changed data to the downstream .
Native flink cdc source All the monitored data will be deserialized according to sql ddl Define to do column Transformation and analysis , With row To the downstream .
We are cdc-source A new type of format The way :changelog bytes Serialization mode . The format When deserializing data, it is no longer necessary to column Transformation and analysis , It's about putting all of column Convert directly to changelog-json Binary transmission , The outer layer directly encapsulates the binary data into row And then to the downstream . Transparent to downstream , The downstream hudi In the consumer kafka Data can be accessed directly through changelog-json Deserialization for data parsing .
And because of this change, it reduces one time column The transformation and parsing of , Through the actual test, it is found that in addition to automatic perception schema In addition to change, it can also improve 1 Times of throughput .
4.3 real time DQC
dqc kafka There are several pain points in monitoring :
be based on kafka The real-time dqc It is difficult to make a year-on-year and month on month index judgment .
dqc Real time links are developed separately , And offline dqc Not universal . Maintenance costs are high .
Multiple monitoring rules for the same flow , Yes, multiple flink job, Every job Calculate an indicator . It can't be reused , Resources are expensive .
framework

take kafka data dump To hudi After the table , Provide dqc data verification . It does not affect the production of seconds / Sub second data aging , It can also solve the above pain points .
hudi Provide minute level monitoring , It can meet real-time requirements dqc Monitoring appeals . Time is too short , Instead, false alarms may be generated due to data fluctuations .
hudi With hive In the form of a table , Make real-time dqc Can and offline dqc Logic is consistent , It is easy to carry out the same ring comparison alarm , Easy to develop and maintain .
real time DQC on Hudi Make real-time link data easier to observe .
4.4 Real time materialization
background
Some business parties need to perform a second level aggregate query on the real-time output data .
Such as real-time Kanban requirements , It takes one data point per minute to show DAU curve , And other multi indicator aggregation query scenarios .
At the same time, the result data should be written to update Storage , Real time updates .
difficulty
In a large data scale , Dozens or hundreds of aggregate calculation results are generated based on details , Second level return required , Next to impossible .
Currently, the company supports update The main types of storage are redis/mysql, The import of calculation results means that the data is out of warehouse , Divorced from hdfs Storage system , Also use the corresponding client The query , Development costs are high .
The existing hdfs In system computing acceleration schemes such as materialization 、 Precomputation is mostly based on offline scenarios , The ability to provide materialized query for real-time data is weak .
The goal is
Support hdfs Within the system update Storage . So that the data does not need to be exported to external storage , You can use it directly olap Engine efficient query .
adopt sql You can simply define a real-time materialized table . When querying, it passes sql analysis , If the materialized table query is hit, multiple aggregate query results can be returned at the second level .
programme
be based on flink + hudi The ability to provide real-time materialization .
adopt sql Customize materialized logic to be based on hudi Physicochemical table of . Write detailed data to details hudi In the table , And pull up one flink job Perform real-time aggregation calculations , Calculate the result upsert To materialized hudi In the table .
Pass... When querying sql analysis , If the rule hits the materialized table , Query the data in the materialized table , So as to speed up the query .
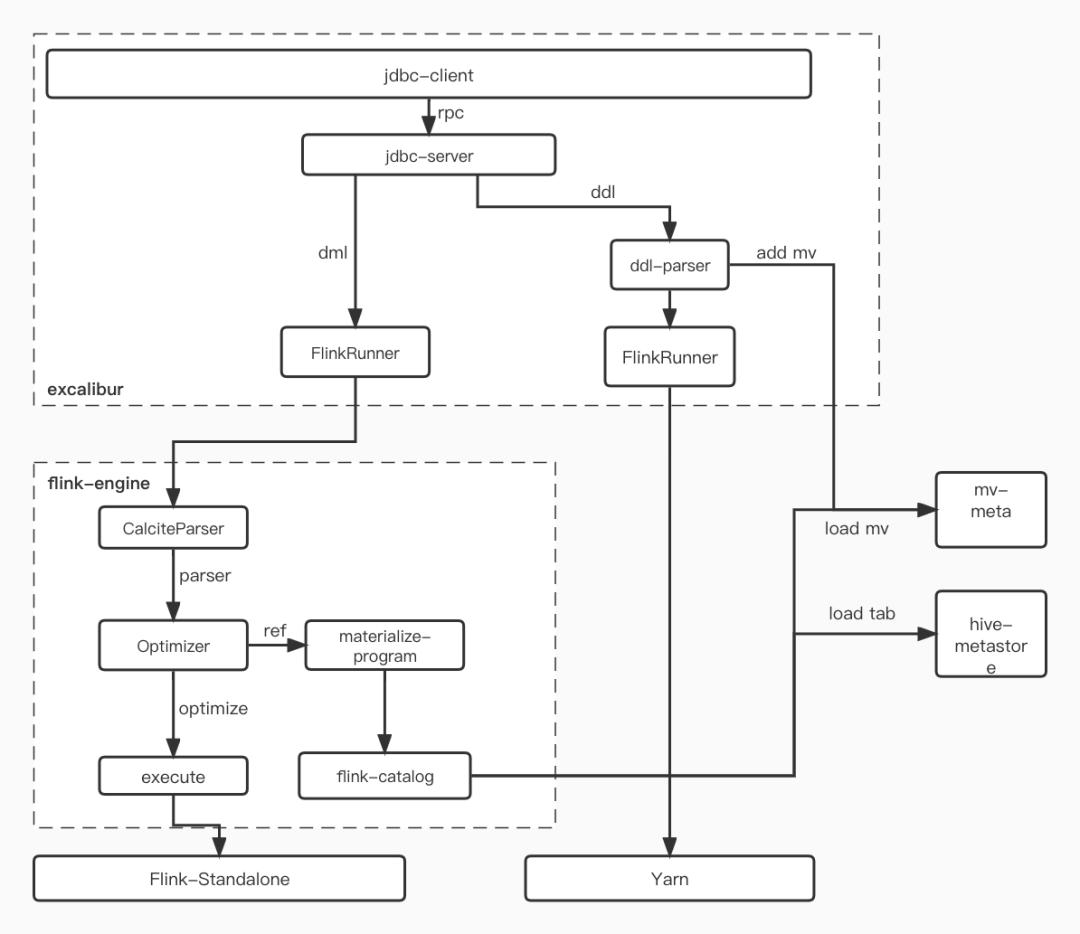
5、 Future outlook
5.1 HUDI Kernel capability enhancement and stability optimization
Hudi timeline Support Optimistic locking resolves concurrency conflicts , Support multiple streams to write a table at the same time . From the bottom layer, new data and supplementary data can be written at the same time hudi.
Support richer schema evalution. Avoid rebuilding tables 、 Heavy operation of re importing data .
Hudi meta server, Unified real-time table offline table , Support instance Version information . Support flink sql Upper use time travel, Meet the demands of taking data snapshots
Hudi manager According to different tables, deploy on demand compaction、clustering、clean. For offline ETL Table of , Low peak period compaction, Cutting peaks and filling valleys in resources . For the table of near line analysis , positive compaction as well as clustering, Reduce the number of query ingested files , Increase query speed .
5.2 Switch the weak real-time scene from Kafka To HUDI
Realize unified storage of stream and batch in weak real-time scenarios .Kafka When the burst traffic and pull historical data reach the performance bottleneck , It is difficult to allocate read / write load for emergency expansion . You can use minute level weak real-time scenarios , from Kafka Switch to HUDI, utilize HUDI Ability to read incremental data , Meet business needs , also HUDI The ability to rapidly expand replicas based on distributed file systems , Meet the demand for emergency capacity expansion .
边栏推荐
- Massive log collection tool flume
- 13. Mismatch simulation of power synthesis for ads usage recording
- . Net 20th anniversary! Microsoft sends a document to celebrate
- 【推荐一款实体类转换工具 MapStruct,性能强劲,简单易上手 】
- 一项听起来大胆,并且非常牛逼的操作——复刻一个 Netflix
- Blue Bridge Cup embedded learning summary (new version)
- Liangshui Xianmu shows his personal awareness as a unity3d worker
- [yolov4] matlab simulation of network target detection based on yolov4 deep learning
- 大厂面试TCP协议经典十五连问!22张图让你彻底弄明白
- Error reported by using two-dimensional array [[]] in thymeleaf: could not parse as expression
猜你喜欢

Jemter 压力测试 -可视化工具-【使用篇】

Crosslinked metalloporphyrin based polyimide ppbpi-h) PPBP Mn; PBP-Fe; PPBPI-Fe-CR; Ppbpi Mn CR product - supplied by Qiyue
3D porphyrin MOF (mof-p5) / 3D porphyrin MOF (mof-p4) / 2D cobalt porphyrin MOF (ppf-1-co) / 2D porphyrin COF (POR COF) / supplied by Qiyue
![[recommend 10 easy idea plug-ins with less tedious and repetitive code]](/img/74/69ca02e3d83404f7b0df07c308a59d.png)
[recommend 10 easy idea plug-ins with less tedious and repetitive code]

Big factory interview TCP protocol classic 15 consecutive questions! 22 pictures to make you fully understand
大厂面试TCP协议经典十五连问!22张图让你彻底弄明白
i3wm 获取window class

How MySQL implements the RC transaction isolation level
Redis系列——5种常见数据类型day1-3

少年,你可知 Kotlin 协程最初的样子?
随机推荐
Error reported by using two-dimensional array [[]] in thymeleaf: could not parse as expression
ES cluster_ block_ exception read_ only_ allow_ Delete question
Redis series - redis startup, client day1-2
Here comes the apple ar/vr device exclusive system! Or named realityos
MySQL storage and custom functions
When asked during the interview, can redis master-slave copy not answer? These 13 pictures let you understand thoroughly
Cocoscreator plays spine animation
Shell programming - user information management
卡尔曼滤波器_Recursive Processing
少年,你可知 Kotlin 协程最初的样子?
报错问题Parameter index out of range(0 < 1) (1 > number of parameters,which is 0
【推荐一款实体类转换工具 MapStruct,性能强劲,简单易上手 】
$a && $b = $c what???
Jemter stress test - visualization tool - [usage]
QTreeWidget And QTableWidget
es 中 mapping 简介
How MySQL implements the RC transaction isolation level
异地北京办理居住证详细材料
MySQL 'replace into' 的坑 自增id,备机会有问题
$a && $b = $c what???