当前位置:网站首页>Beginner crawler notes (collecting data)
Beginner crawler notes (collecting data)
2022-08-04 15:39:00 【Sweat always outweighs talent】
import urllib.requestdef main():#1. Crawl the web (parse the data one by one in this)baseurl = 'https://movie.douban.com/top250?start='datalist = getData(baseurl)#2. Save dataprint()#crawl the webdef getData(baseurl):#First you need to get a page of data, and then use a loop to get the information of each pagedatalist = []for i in range(0,10):url = baseurl + str(i*25)html = askURL(url)return datalist#Request web pagedef askURL(url):header = {"User-Agent": "Mozilla/5.0(Linux;Android6.0;Nexus5 Build / MRA58N) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 103.0.5060.134MobileSafari / 537.36Edg / 103.0.1264.77"}request = urllib.request.Request(url, headers = header)html = ""try :response = urllib.request.urlopen(request)html = response.read().decode()print(html)except urllib.error.URLerror as e:if hasattr(e,"code"):print(e.code)if hasattr(e,"reason"):print(e.reason)return htmlif __name__ == '__main__':main()The code has only completed the task of collecting data, it has not been perfected, and will continue to be updated in the future!!!(The source of the tutorial and station B, if there is any offense, please contact me to delete it by private message)
‘
边栏推荐
- C# TextBlock 上标
- 小程序|炎炎夏日、清爽一夏、头像大换装
- 素士科创板IPO撤单,雷军失去“电动牙刷第一股”
- 直播回放含 PPT 下载|基于 Flink & DeepRec 构建 Online Deep Learning
- An article to answer what is the product library of the DevOps platform
- 一文解答DevOps平台的制品库是什么
- How to monitor code cyclomatic complexity by refactoring indicators
- 为什么Redis默认序列化器处理之后的key会带有乱码?
- 图解 SQL,这也太形象了吧!
- Codeforces Round #811 A~F
猜你喜欢




随机推荐
小程序|炎炎夏日、清爽一夏、头像大换装
弄懂#if #ifdef #if defined
洛谷题解P4326 求圆的面积
游戏网络 UDP+FEC+KCP
2022 Hangzhou Electric Multi-School 4
解决dataset.mnist无法加载进去的情况
【Es6中的promise】
《电磁兼容防护EMC》学习笔记
RepVGG学习笔记
2022杭电多校3
numpy入门详细代码
攻防视角下,初创企业安全实战经验分享
性能提升400倍丨外汇掉期估值计算优化案例
inter-process communication
一文详解什么是软件部署
IP第十五天笔记
多商户商城系统功能拆解24讲-平台端分销会员
RSA306B,500,600系列API接口代码
(2022杭电多校五)C - Slipper (dijkstra+虚拟结点)
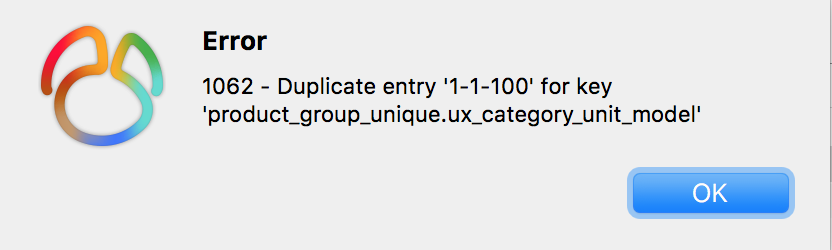
Why, when you added a unique index or create duplicate data?