当前位置:网站首页>Swin-Transformer(2021-08)
Swin-Transformer(2021-08)
2022-06-30 19:06:00 【Gy Zhao】
brief introduction
Until I write this note , be based on Swin Our model still dominates the list Object Detection Wait for multiple lists .
Many blogs have introduced it in great detail , Here I only record the puzzles I encountered during my study .
Swin And ViT Comparison of ,ViT take image Divided into fixed size patch, With patch In units attention Calculation , In the process of calculation feature map The resolution is unchanged , also ViT In order to keep up with NLP The consistency of , Added an additional class token, Finally used for classification . therefore ViT Not suitable for downstream tasks such as detection , Unable to extract multi-scale features .
to want to transformer For visual tasks such as detection , One is imitation CNN, take transformer Transformed into a hierarchical structure , One is to use pure transformer Structure to explore .
Swin Obviously belongs to the former , use Local window self attention and shift window In a clever way Hierarchical structure , It can be used as a general purpose in the visual field backbone Use .

Above, Swin-T Structure diagram , The input image first passes through Patch Partitiion and Linear Embedding Turn into token Vector sequence of form , Then input Swin Transformer Block in , Every Block All by one window–Multi-Head self Attention and Shift-Window Multi-head self-attention form , So it's always even .
window partition Window partition
take (B, H, W, C) Divided into (num_windows*B, window_size, window_size, C) Of windows
def window_partition(x, window_size):
""" Args: x: (B, H, W, C) window_size (int): window size Returns: windows: (num_windows*B, window_size, window_size, C) """
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
#view() Must be directed at contiguous Data storage format
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
# Restore the original input x
def window_reverse(windows, window_size, H, W):
""" Args: windows: (num_windows*B, window_size, window_size, C) window_size (int): Window size H (int): Height of image W (int): Width of image Returns: x: (B, H, W, C) """
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
The test runs as follows
x = torch.randn(1,224,224,3)
p =window_partition(x,7)
print(p.size())
o = window_reverse(p,7,224,224)
print(o.size())
***output
torch.Size([1024, 7, 7, 3])
torch.Size([1, 224, 224, 3])***
partition Is to enter image Convert to specify window size Of patch vector , Here is the will (1 ,224,224,3) Of batch Convert to 1024 Window size is (7,7) Of patch.
reverse The function is partition The inverse function of
PatchEmbedding
[B C H W]->[B ,Ph*Pw,96]
import torch
from torch import nn
from timm.models.layers import to_2tuple
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding Args: img_size (int): Image size. Default: 224. patch_size (int): Patch token size. Default: 4. in_chans (int): Number of input image channels. Default: 3. embed_dim (int): Number of linear projection output channels. Default: 96. norm_layer (nn.Module, optional): Normalization layer. Default: None """
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size) #(224,224)
patch_size = to_2tuple(patch_size) #patch size (4,4)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]] #(56,56)
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution # Resolution refers to patch Count
self.num_patches = patches_resolution[0] * patches_resolution[1] #56*56=3136
self.in_chans = in_chans
self.embed_dim = embed_dim
# Use 2d Convolution is carried out patch Divide , Input channe The default is 3
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size) #output:(batch,96,56,56)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
# The limit image size must be 224*224
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({
H}*{
W}) doesn't match model ({
self.img_size[0]}*{
self.img_size[1]})."
#B C h W -> b embed h*w ->b h*W embed obtain Patch Embeding shape
x = self.proj(x) #Patch Divide [1,96,56,56]
x=x.flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
x = torch.randn(1,3,224,224)
PM = PatchEmbed()
out = PM(x)
print(out.shape)
**output
torch.Size([1, 3136, 96])**
PatchMerging
[B,H*W,C]->[B,H/2,W/2,2C]
PatchMerging Equivalent to down sampling in convolution , Reduce feature map The resolution of the , At the same time increase channel Dimensions , Here the resolution H,W All reduced to half of the original ( Overall decrease 4 times ),channel The number has doubled .
class PatchMerging(nn.Module):
r""" Patch Merging Layer. Args: input_resolution (tuple[int]): Resolution of input feature. dim (int): Number of input channels. norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm """
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
""" x: B, H*W, C """
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size" # Limit input x The second dimension of is related to H,W matching
assert H % 2 == 0 and W % 2 == 0, f"x size ({
H}*{
W}) are not even."
x = x.view(B, H, W, C)
# according to H W The interval is 2 , A combination of two common 4 Group
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
print("\n",x0,"\n",x1,"\n",x2,"\n",x3)
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C # The resolution of the feature map is reduced by half
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C At this point, the channel dimension becomes the original 4 times
x = self.norm(x)
x = self.reduction(x) #4C -> 2C adopt linear The channel dimension consists of 4 Times become the original 2 times
return x
def extra_repr(self) -> str:
return f"input_resolution={
self.input_resolution}, dim={
self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops
PM = PatchMerging(input_resolution=(4,4),dim=3)
x = torch.arange(48,dtype=torch.float).view(1,16,3)
o=PM(x)
print(o.shape)
output:
***tensor([[[[ 0., 1., 2.],
[ 6., 7., 8.]],
[[24., 25., 26.],
[30., 31., 32.]]]])***
***tensor([[[[12., 13., 14.],
[18., 19., 20.]],
[[36., 37., 38.],
[42., 43., 44.]]]])***
***tensor([[[[ 3., 4., 5.],
[ 9., 10., 11.]],
[[27., 28., 29.],
[33., 34., 35.]]]])***
***tensor([[[[15., 16., 17.],
[21., 22., 23.]],
[[39., 40., 41.],
[45., 46., 47.]]]])***
**torch.Size([1, 4, 6])**
Window Attention

Window self attention calculation , Limited to one window in , The formula is compared with the previous attention Added an additional B- Relative position offset (relative postional bias)
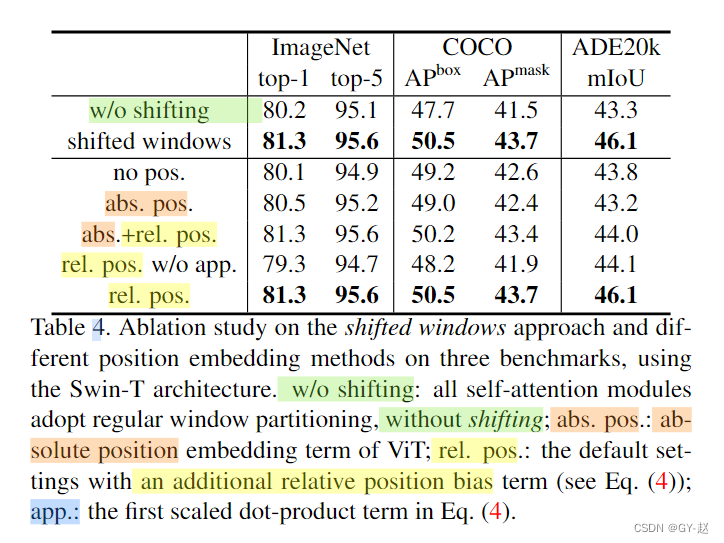
From the results given in the paper , The result of relative position offset is better than other methods .
mask shift-window visualization

In a more intuitive way , Colored results need to be preserved by self - attention calculation , Other white parts need to be ignored (mask) The place of , You can refer to the results generated from the following code, which are consistent with this figure .
#attn mask Part of the test code
# Assume that the input image by 4X4 size , Divided into 4 individual window, Every window by 2X2 size
input_resolution =(4,4)
window_size =2
shift_size=1 #shift_size That is to say [M/2] Round down
def window_partition(x, window_size):#[B H W C]->[BHW/(window size)^2 , window size,winsow size,C ]
""" Args: x: (B, H, W, C) window_size (int): window size Returns: windows: (num_windows*B, window_size, window_size, C) """
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
if shift_size > 0:
# calculate attention mask for SW-MSA
H, W = input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
# Pre planned partition location index -slice(start,stop,step)
h_slices = (slice(0, -window_size),
slice(-window_size, -shift_size),
slice(-shift_size, None))
w_slices = (slice(0, -window_size),
slice(-window_size, -shift_size),
slice(-shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, window_size * window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
print(attn_mask)
output
tensor([[[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.],
[ 0., 0., 0., 0.]],
[[ 0., -100., 0., -100.],
[-100., 0., -100., 0.],
[ 0., -100., 0., -100.],
[-100., 0., -100., 0.]],
[[ 0., 0., -100., -100.],
[ 0., 0., -100., -100.],
[-100., -100., 0., 0.],
[-100., -100., 0., 0.]],
[[ 0., -100., -100., -100.],
[-100., 0., -100., -100.],
[-100., -100., 0., -100.],
[-100., -100., -100., 0.]]])
#mask shift window Visual code
import torch
import matplotlib.pyplot as plt
def window_partition(x, window_size):
""" Args: x: (B, H, W, C) window_size (int): window size Returns: windows: (num_windows*B, window_size, window_size, C) """
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
window_size = 7
shift_size = 3
H, W = 14, 14
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
h_slices = (slice(0, -window_size),
slice(-window_size, -shift_size),
slice(-shift_size, None))
w_slices = (slice(0, -window_size),
slice(-window_size, -shift_size),
slice(-shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, window_size * window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
plt.matshow(img_mask[0, :, :, 0].numpy())
plt.matshow(attn_mask[0].numpy())
plt.matshow(attn_mask[1].numpy())
plt.matshow(attn_mask[2].numpy())
plt.matshow(attn_mask[3].numpy())
plt.show()

Swin-X Parameter configuration list
 Inclusion relation :Swin_transformer(Basic_layer(Swin_Block))
Inclusion relation :Swin_transformer(Basic_layer(Swin_Block))
reference( Recommended reading ):
1.https://zhuanlan.zhihu.com/p/367111046
2. https://hub.fastgit.xyz/microsoft/Swin-Transformer/issues/38
3. https://zhuanlan.zhihu.com/p/430047908 - Very clear
4. https://blog.csdn.net/qq_37541097/article/details/121119988
5. https://blog.csdn.net/qq_39478403/article/details/120042232
边栏推荐
- 煤炭行业数智化供应商管理系统解决方案:数据驱动,供应商智慧平台助力企业降本增效
- What if the apple watch fails to power on? Apple watch can not boot solution!
- Large file transfer software based on UDP protocol
- Reading notes of "high EQ means being able to talk"
- 开发那些事儿:Linux系统中如何安装离线版本MySQL?
- Memory Limit Exceeded
- Digital intelligent supplier management system solution for coal industry: data driven, supplier intelligent platform helps enterprises reduce costs and increase efficiency
- 电子元器件行业在线采购系统精准匹配采购需求,撬动电子产业数字化发展
- Hospital online consultation applet source code Internet hospital source code smart hospital source code
- mysql修改数据类型_MySQL修改字段类型[通俗易懂]
猜你喜欢

MRO industrial products procurement management system: enable MRO enterprise procurement nodes to build a new digital procurement system

Infineon - GTM architecture -generic timer module

Geoffrey Hinton: my 50 years of in-depth study and Research on mental skills

20220528【聊聊假芯片】贪便宜往往吃大亏,盘点下那些假的内存卡和固态硬盘

ONEFLOW source code parsing: automatic inference of operator signature

MySQL transaction concurrency and mvcc mechanism

正则表达式(正则匹配)

屏幕显示技术进化史
![Delete duplicate elements in the sorting linked list ii[unified operation of linked list nodes --dummyhead]](/img/dd/7df8f11333125290b4b30183cfff64.png)
Delete duplicate elements in the sorting linked list ii[unified operation of linked list nodes --dummyhead]

Personally test the size of flutter after packaging APK, quite satisfied
随机推荐
医院在线问诊小程序源码 互联网医院源码 智慧医院源码
Do you really understand the persistence mechanism of redis?
PyTorch学习(三)
Small program container technology to promote the operation efficiency of the park
System integration project management engineer certification high frequency examination site: prepare project scope management plan
传统微服务框架如何无缝过渡到服务网格 ASM
【TiDB】TiCDC canal_ Practical application of JSON
Tensorflow2 ten must know for deep learning
The easynvr platform equipment channels are all online. What is the reason for the "network request failure" in the operation?
医疗行业企业供应链系统解决方案:实现医疗数智化供应链协同可视
Electronic components bidding and purchasing Mall: optimize traditional purchasing business and speed up enterprise digital upgrading
不同制造工艺对PCB上的焊盘的影响和要求
php利用队列解决迷宫问题
Personally test the size of flutter after packaging APK, quite satisfied
Courage to be hated: Adler's philosophy class: the father of self inspiration
屏幕显示技术进化史
Redis入门到精通01
期货怎么开户安全些?现在哪些期货公司靠谱些?
开发那些事儿:Linux系统中如何安装离线版本MySQL?
基于STM32F1的环境光与微距离检测系统