当前位置:网站首页>Data science [9]: SVD (2)
Data science [9]: SVD (2)
2022-07-02 06:20:00 【swy_ swy_ swy】
Data Science 【 Nine 】:SVD( Two )
Data preparation
We study text data this time . We can sklearn.datasets get fetch_20newsgroups, namely 20 News text sets in different categories ; Here we choose four categories .
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from nltk.stem.snowball import SnowballStemmer
categories = ['alt.atheism', 'soc.religion.christian', 'comp.graphics', 'sci.med']
news_data = fetch_20newsgroups(subset='train', categories=categories)
participle
Each article can be regarded as a string . This string consists of spaces 、 Line breaks and word composition . It should be noted that , The same word may have many variations , For example, tense 、 The plural 、 Change grid and so on , It depends on the language . From many deformations “ extract ” words , It is the participle . We can call SnowballStemmer() Realization :
stemmer = SnowballStemmer('english')
stemmed_articles = []
for article in news_data.data:
stemmed_words = []
for word in article.split():
stemmed_words.append(stemmer.stem(word))
stemmed_articles.append(" ".join(stemmed_words))
The importance of words
Given a word and a text set , How to quantify the importance of this word ? One indicator is tf-idf features .tf-idf Features consist of two parts , Respectively :
- TF(t, a): words t In the article a The ratio appearing in , namely t Number of occurrences / The total number of words in the article .
- IDF(t, s): The number of articles in the article collection is higher than the occurrence of words t Logarithm of the number of articles , namely log10( The total number of articles / The number of articles with this word )
- tf-idf: TF And IDF The product of the .
By the above definition , We know that in a text set , For each text, there is an eigenvector .
We can use from sklearn.feature_extraction.text import TfidfVectorizer To obtain a tf-idf Eigenvector .
import pandas as pd
tfidfvctr = TfidfVectorizer(max_df = 0.25, min_df = 0.05)
tfidf_mat = tfidfvctr.fit_transform(stemmed_articles)
tfidf_df = pd.DataFrame(tfidf_mat.toarray())
tfidf_df.to_csv("tfidf.csv", index=False)
Yes tf-idf Use SVD Dimension reduction
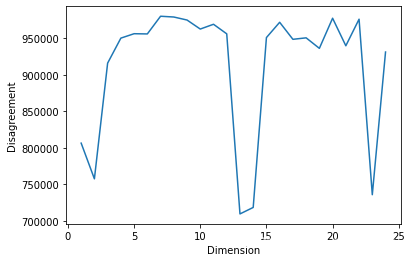
What we got above SVD Matrix dimensionality reduction , Preserve eigenvalues of different ranks , And pass disagreemet distance Evaluate clustering effect .
disagreement_distance = []
original_dataset = pd.read_csv("tfidf.csv", low_memory=False).values
for k in range(1,25):
dim_reduced_dataset = PCA(k).fit_transform(original_dataset)
kmeans = KMeans(n_clusters=4, init='k-means++', max_iter=100, n_init=10, random_state=0)
kmeans.fit_predict(dim_reduced_dataset)
labelsk = kmeans.labels_
disagreement_distance.append(disagreement_dist(labelsk, news_data.target))
plt.plot(range(1,25), disagreement_distance)
plt.ylabel('Disagreement')
plt.xlabel('Dimension')
plt.show()
边栏推荐
- 深入学习JVM底层(三):垃圾回收器与内存分配策略
- LeetCode 40. Combined sum II
- Database learning summary 5
- 【程序员的自我修养]—找工作反思篇二
- Flutter hybrid development: develop a simple quick start framework | developers say · dtalk
- Linear DP (split)
- Top 10 classic MySQL errors
- Replace Django database with MySQL (attributeerror: 'STR' object has no attribute 'decode')
- 借力 Google Cloud 基础设施和着陆区,构建企业级云原生卓越运营能力
- LeetCode 27. 移除元素
猜你喜欢

Compte à rebours de 3 jours pour l'inscription à l'accélérateur de démarrage Google Sea, Guide de démarrage collecté à l'avance!
Ruijie ebgp configuration case

Amazon AWS data Lake Work Pit 1
Step by step | help you easily submit Google play data security form
深入了解JUC并发(二)并发理论
穀歌出海創業加速器報名倒計時 3 天,創業人闖關指南提前收藏!
浏览器原理思维导图

介绍两款代码自动生成器,帮助提升工作效率
谷歌出海创业加速器报名倒计时 3 天,创业人闯关指南提前收藏!

Linear DP (split)
随机推荐
一起学习SQL中各种join以及它们的区别
How to use mitmproxy
Format check JS
Redis---1.数据结构特点与操作
Monitoring uplink of VRRP
Web page user step-by-step operation guide plug-in driver js
Don't use the new WP collection. Don't use WordPress collection without update
从设计交付到开发,轻松畅快高效率!
Shenji Bailian 3.52-prim
LeetCode 90. Subset II
In depth understanding of JUC concurrency (I) what is JUC
CNN visualization technology -- detailed explanation of cam & grad cam and concise implementation of pytorch
Google Play Academy 组队 PK 赛,正式开赛!
亚马逊aws数据湖工作之坑1
Detailed notes of ES6
Hydration failed because the initial UI does not match what was rendered on the server.问题原因之一
来自读者们的 I/O 观后感|有奖征集获奖名单
递归(迷宫问题、8皇后问题)
Database learning summary 5
【每日一题】—华为机试01