当前位置:网站首页>ECCV2022 | RU&谷歌提出用CLIP进行zero-shot目标检测!
ECCV2022 | RU&谷歌提出用CLIP进行zero-shot目标检测!
2022-08-05 05:15:00 【FightingCV】

【写在前面】
构建鲁棒的通用对目标测框架需要扩展到更大的标签空间和更大的训练数据集。然而,大规模获取数千个类别的标注成本过高。作者提出了一种新方法,利用最近视觉和语言模型中丰富的语义来定位和分类未标记图像中的对象,有效地生成用于目标检测的伪标签。从通用的和类无关的区域建议(region proposal)机制开始,作者使用视觉和语言模型将图像的每个区域分类为下游任务所需的任何对象类别。作者演示了生成的伪标签在两个特定任务中的价值:开放词汇检测,其中模型需要推广到看不见的对象类别;半监督对象检测,其中可以使用额外的未标记图像来改进模型。本文的实证评估显示了伪标签在这两项任务中的有效性,在这两项任务中,本文的表现优于竞争基线,并实现了开放词汇表目标检测的SOTA。
1. 论文和代码地址

Exploiting Unlabeled Data with Vision and Language Models for Object Detection
论文地址:https://arxiv.org/abs/2207.08954[1]
代码地址:https://github.com/xiaofeng94/VL-PLM[2]
2. Motivation
目标检测的最新进展建立在大规模数据集上,这些数据集为许多物体类别提供了丰富而准确的人类标注边界框。然而,此类数据集的标注成本是巨大的。此外,自然对象类别的长尾分布使得为所有类别收集足够的标注更加困难。半监督对象检测(SSOD)和开放词汇表对象检测(OVD)是通过利用不同形式的未标记数据来降低标注成本的两项任务。在SSOD中,给出了一小部分完全标注的训练图像以及大量未标注图像。在OVD中,在所有训练图像中标注一部分所需的对象类别(基本类别),任务是在测试时检测一组新的(或未知)类别。这些对象类别可以出现在训练图像中,但不使用地面ground truth框进行标注。一种常见且成功的方法是使用未标记的数据来生层伪标签。然而,所有先前关于SSOD的工作都只利用了一小部分标记数据来生成伪标签,而大多数先前关于OVD的工作根本没有利用伪标签。
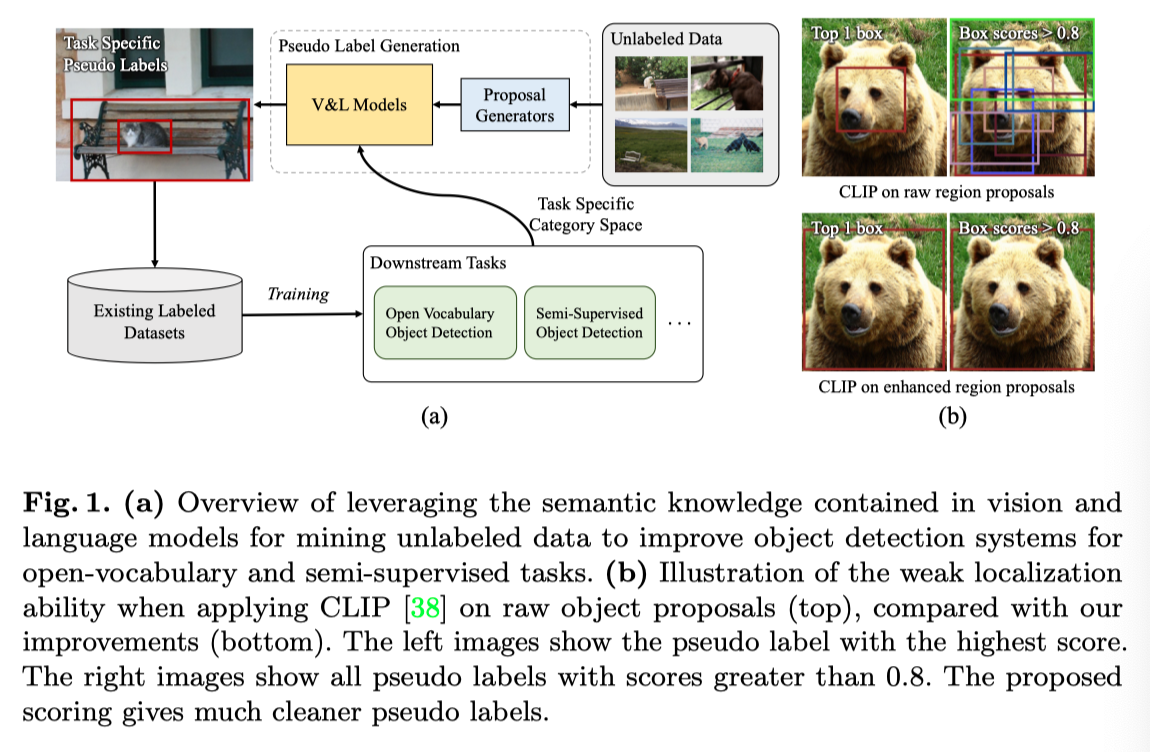
在这项工作中,作者提出了一种简单但有效的方法,使用最近提出的视觉和语言(V&L)模型挖掘未标记图像,以生成已知和未知类别的伪标签,该方法适用于SSOD和OVD两种任务。V&L模型可以从(有噪声的)图像字幕对中训练,无需人工标注,即可通过抓取图像及其文本的网站大规模获得。尽管存在噪声标注,但这些模型在各种语义任务(如zero-shot分类或图像文本检索)上表现出了优异的性能。大量多样的图像与自由形式的文本相结合,为训练健壮的通用模型提供了强大的信息源。这些特性使视觉和语言模型成为改进利用未标记数据(如OVD或SSOD)的现有目标检测pipeline的理想候选对象,见上图(a)。
具体来说,本文的方法利用最近提出的视觉和语言模型CLIP来生成用于对象检测的伪标签。首先使用两阶段类不可知proposal生成器预测区域建议,该生成器使用有限的ground truth进行训练(在OVD中仅使用已知的基类别,在SSOD中仅使用标记图像),但推广到不可见类别。对于每个区域建议,然后使用预训练的V&L模型片段获得所需对象类别(取决于任务)的概率分布。然而,如上图(b)所示,VL模型的一个主要挑战是目标定位质量相当低。为了改进定位,作者提出了两种策略,其中两阶段proposal生成器有助于VL模型:(1) 融合两阶段提案生成器的CLIP分数和对象性分数,以及(2)通过在提案生成器中重复应用定位头(第二阶段)来移除冗余提案(proposal)。最后,将生成的伪标签与原始ground truth相结合,训练最终检测器。本文的方法命名为V&L引导伪标签挖掘(VL-PLM)。
大量实验表明,VL-PLM成功地利用了未标记数据进行开放词汇检测,在COCO数据集上的新类别上优于最先进的ViLD+6.8 AP。此外,VL-PLM在SSOD中的已知类别上提高了性能,并且通过仅用本文的伪标签替换其伪标签,明显优于流行的基线STAC。此外,作者还对生成的伪标签的特性进行了各种消融研究,并分析本文提出的方法的设计选择。作者还认为,VL-PLM可以通过更好的VL模型(如ALIGN或ALBEF)进一步改进。
本文的工作贡献如下:(1)作者利用V&L模型通过在未标记数据上生成伪标签来改进目标检测框架。(2) 一种简单但有效的策略,用于提高用V&L模型CLIP评分的伪标签的定位质量。(3) COCO开放词汇检测设置上新类别的最新结果。(4) 作者展示了VL-PLM在半监督目标检测环境中的优势。
3. 方法
本文的目标是使用视觉和语言(V&L)模型挖掘未标记图像,以生成边界框形式的语义丰富的伪标签(PLs),以便对象检测器能够更好地利用未标记数据。
3.1 Training object detectors with unlabeled data
对于对象检测器,未标记的数据有许多不同的形式。在半监督目标检测中,有一组带有完整标签空间标注的完全标记的图像,以及未标记图像,其中。在开放词汇检测中,作者对带有基本类别集标注的图像进行了部分标记,但对未知/新颖类别没有标注。
从未标记数据中学习的一种流行且成功的方法是通过伪标签。最近的半监督目标检测方法遵循这种方法,首先在有限的Ground Truth数据上训练教师模型,然后为未标记的数据生成伪标签,最后训练学生模型。作者提出了一种用于对象检测的通用训练策略,以处理不同形式的未标记数据。
作者定义了一个对象检测器的通用损失函数,其参数在标记图像和未标记图像上均为:
其中,α是一个超参数,用于平衡有监督的和无监督的损失,是根据条件返回0或1的指示函数。再次注意,可以包含在和中。
目标检测最终是一个集预测问题,为了定义损失函数,需要将预测集(类概率和bounding box估计)与ground truth bounding box匹配。存在不同的选项来寻找匹配,但它主要由预测和GT框之间的相似性(IoU)定义。作者将预测i的匹配定义为,如果匹配成功,则返回GT下标j,否则返回nil。监督损失包含分类l的标准交叉熵损失和回归的L1损失。给定,作者将定义为:
其中是预测的边界框数。和是目标检测器的预测类分布和边界框。相应的(匹配的)GT定义为 和。
无监督损失的定义类似,但使用具有高置信度的伪标签作为监督信号:
这里,定义了与预测i匹配的伪标签在标签空间上的概率分布,是采用的伪标签的数量,即。分类的伪标签和box回归损失分别为。从未标记数据成功训练目标检测器的关键是准确的伪标记。
3.2 VL-PLM: Pseudo labels from vision & language models
VL语言模型在大规模数据集上进行训练,图像-文本对覆盖了一组不同的图像域和自然文本中丰富的语义。通过使用网络抓取的数据 (图像和相应的文本),可以在没有昂贵的人工注释的情况下获得图像-文本对。因此,V & L模型是为任意类别生成伪标签的理想外部知识来源,可用于下游任务,例如开放词汇或半监督对象检测。
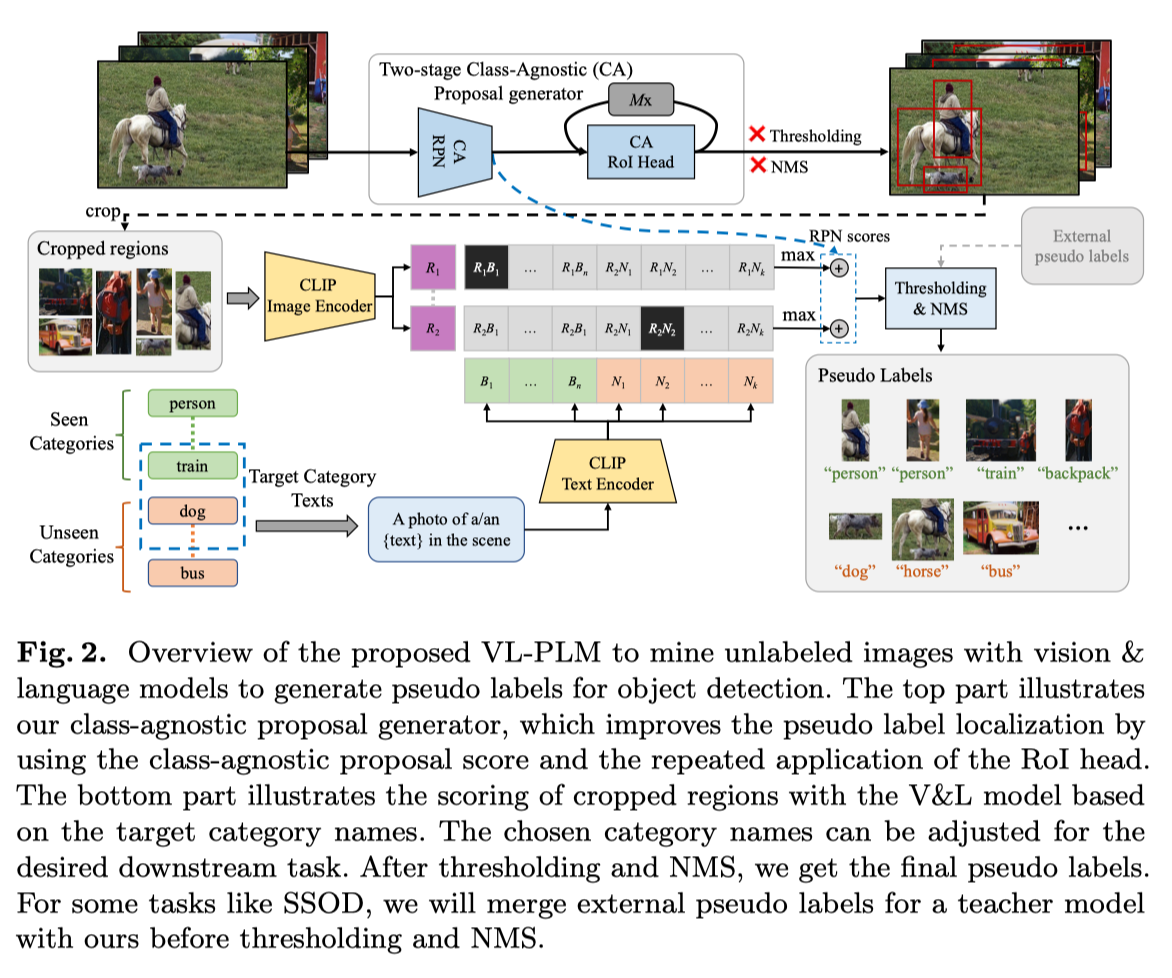
上图展示了用最近的V & L模型CLIP生成伪标签的整体流水线。首先将一个未标记的图像输入两阶段类不可知检测器以获得区域建议。然后,根据这些区域裁剪图像块,并将其输入剪辑图像编码器,以在CLIP视觉和语言空间中获得嵌入。使用相应的CLIP文本编码器和模板文本提示,为特定任务所需的类别名称生成嵌入。对于每个区域,作者通过点积计算区域嵌入和文本嵌入之间的相似性,并使用softmax获得类别上的分布。然后,作者使用来自类不可知检测器和V&L模型的分数生成最终的伪标签。
本文的框架面临两个关键挑战 :( 1) 为开放词汇检测所需的新类别生成可靠的建议(proposal),以及 (2) 克服原始CLIP模型的定位质量较差的特点。作者提出了简单但有效的解决方案,以解决以下两个挑战:
生成稳健的和类无关的区域建议:为了利用未标记数据进行开放式词汇检测等任务,建议生成器不仅应该能够定位训练期间看到的类别对象,还应该能够定位新类别的对象。虽然存在像选择性搜索这样的无监督候选者,但这些候选者通常很耗时,并且会产生许多噪声框。正如先前研究中所建议的那样,两级检测器的区域建议网络(RPN)对于新类别具有良好的泛化能力。此外,作者发现RoI头能够改进区域建议的定位。因此,作者训练了一个标准的两阶段检测器,例如Faster R-CNN,作为本文的建议生成器,使用可用的GT值,即开放词汇检测的基本类别标注和半监督检测中注释图像的小部分标注。为了进一步提高泛化能力,作者忽略了训练集的类别信息,训练了一个类无关的建议生成器。
使用V&L模型生成伪标签:在裁剪区域建议上直接应用CLIP会产生较低的定位质量。在这里,作者演示了如何通过两种方式使用本文的两阶段类不可知建议生成器来提高定位能力。首先,作者发现RPN分数是衡量区域建议定位质量的一个良好指标。作者利用这一观察结果,并将RPN分数与CLIP预测值进行平均。其次,作者去除建议生成器的阈值和NMS,并将建议框多次馈送到RoI头。作者观察到,通过重复RoI头将冗余框推近彼此。这样,可以产生位置更好的边界框,并提供更好的伪标签。
为了进一步提高伪标签的质量,作者采用了从CLIP中嵌入的多尺度区域。此外,作者采用高阈值来选取高置信度的伪标签。区域的伪标签的置信度表示为:
其中表示RPN分数。预测概率分布定义为:
这里,是被大小裁剪的区域。和分别是CLIP的图像和文本编码器,。如果$\bar{c}{i}^{u}=0R{i}$。
3.3 Using our pseudo labels for downstream tasks
最后,简要描述如何将未标记数据生成的伪标签用于本工作中关注的两个特定下游任务。
开放词汇检测:在这个任务中,检测器可以访问带有基本类别标注的图像,并且需要推广到新类别。在上述伪标签生成过程中,作者利用基本类别的数据来训练类不可知Mask R-CNN作为我们的建议生成器,并将新类别的名称作为CLIP文本编码器的输入文本。然后,作者用RestNet50 FPN训练了一个标准Mask R-CNN,该模型同时具有GT值和新的伪标签。
半监督目标检测:在该任务中,相关方法通常使用有限的标记图像集中的GT值来训练教师模型,然后与教师一起在未标记图像上生成伪标签。作者生成了这些伪标签,并将其与VL-PLM中的伪标签合并。因此,学生模型是在我们基于VL的方法和教师模型中可用的GT和伪标签上训练的。
4.实验
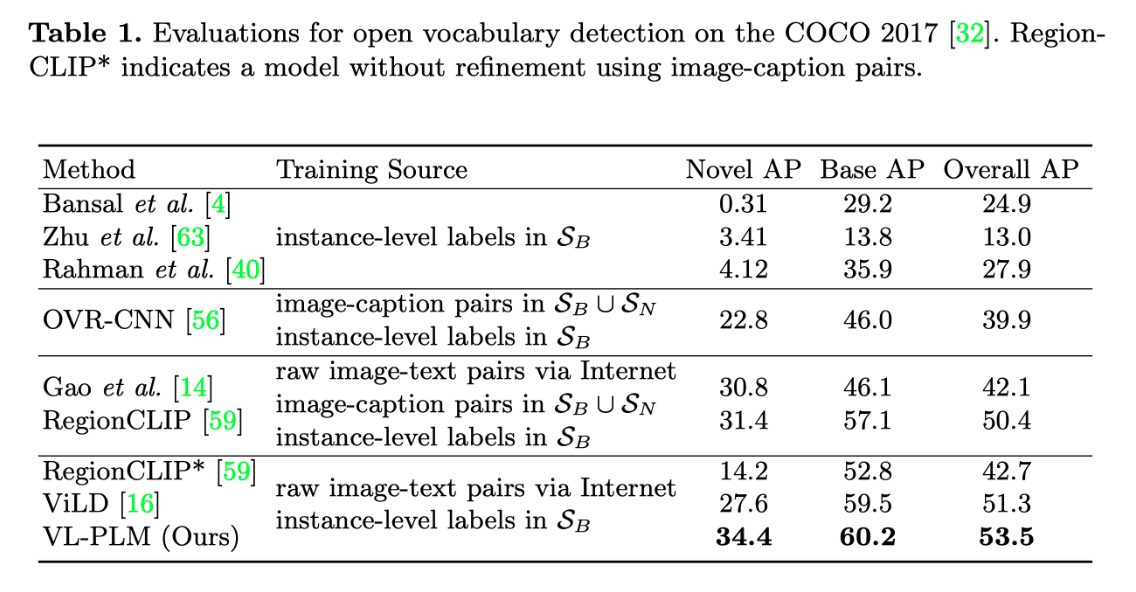
如上表所示,用VLPLM训练的检测器显著优于现有最先进的ViLD近+7%。
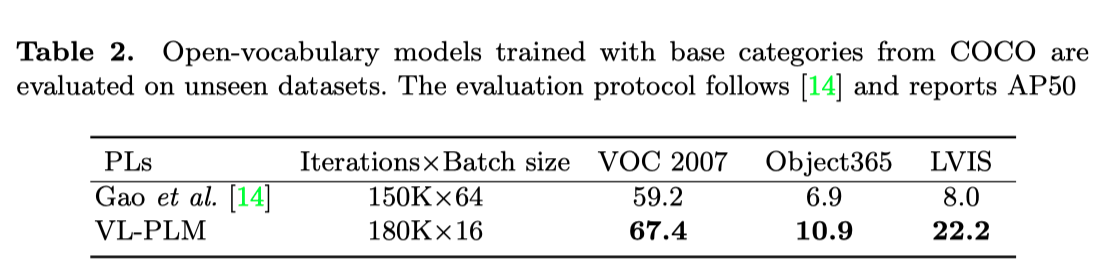
作者在三个没见过的数据集上评估了COCO训练模型:VOC 2007、Object365和LVIS。VL-PLM具有相似的迭代次数和较小的batch,其性能有显著优势。
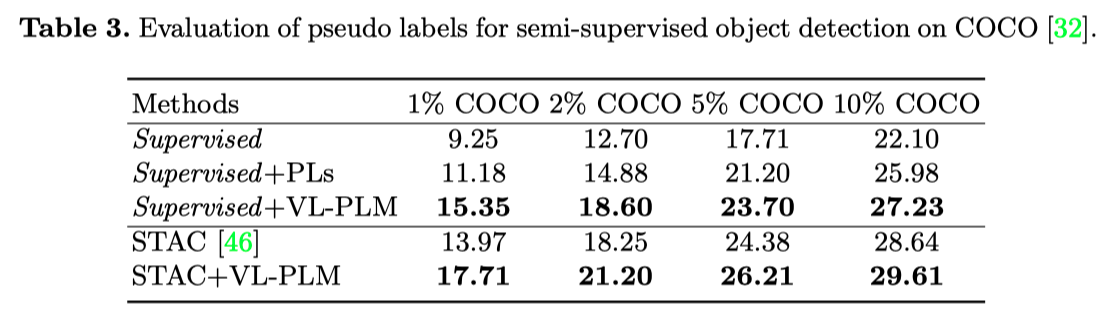
上表展示了本文方法在半监督目标检测上的实验结果。
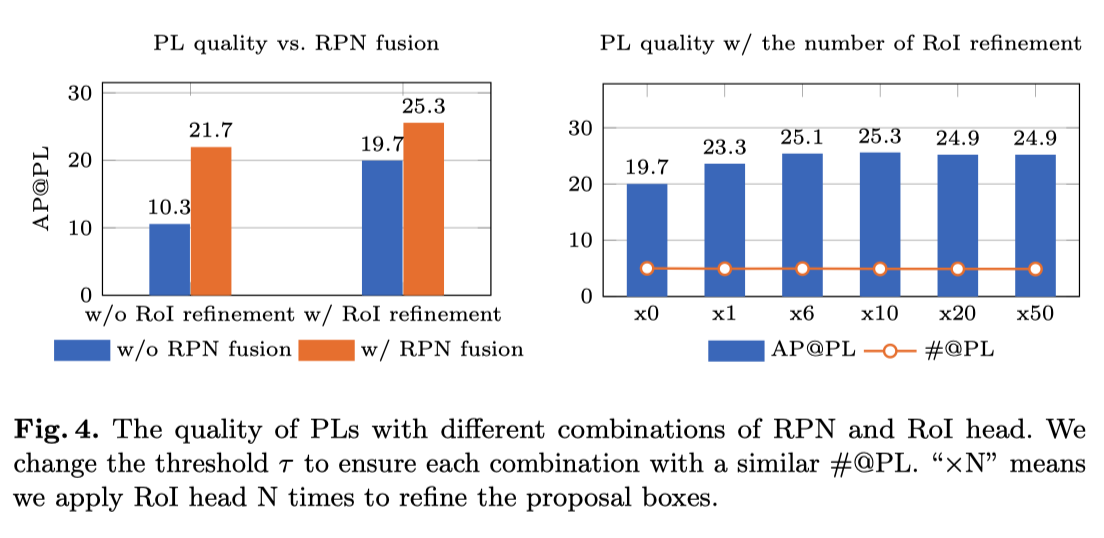
为了展示RPN和RoI头如何帮助PLs,作者在上图中评估了不同设置下PLs的质量。
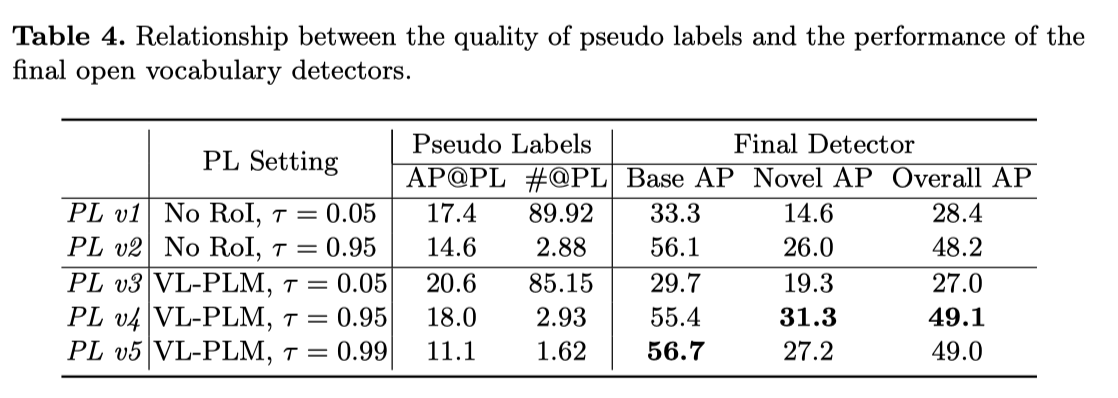
上表展示了伪标签质量和开放域目标检测的性能关系。
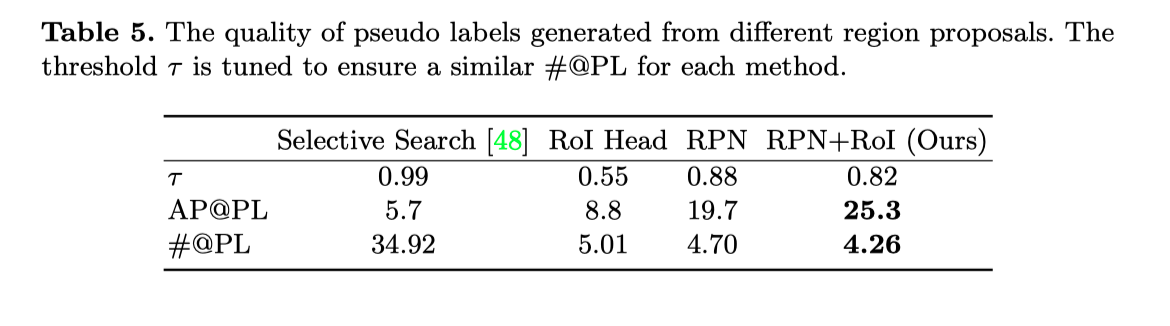
上表展示了不同region proposal方法生成的伪标签的质量结果。
5. 总结
本文演示了如何利用预训练的V&L模型挖掘不同目标检测任务(例如OVD和SSOD)的未标记数据。作者提出了一个简单而有效的V&L模型引导的伪标签挖掘框架(VL-PLM),该框架能够为特定于任务的标签空间生成伪标签。本文的实验表明,使用PLs训练标准检测器为COCO上的OVD设置了一个新的最先进水平。此外,本文的PLs可以使SSOD模型受益,尤其是在ground truth标签数量有限的情况下。
已建立深度学习公众号——FightingCV,欢迎大家关注!!!
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
加入交流群,请添加小助手wx:FightngCV666
参考资料
https://arxiv.org/abs/2207.08954: https://arxiv.org/abs/2207.08954
[2]https://github.com/xiaofeng94/VL-PLM: https://github.com/xiaofeng94/VL-PLM
本文由 mdnice 多平台发布
边栏推荐
猜你喜欢
Tensorflow踩坑笔记,记录各种报错和解决方法

如何停止flink job

Database experiment five backup and recovery
【论文精读】ROC和PR曲线的关系(The relationship between Precision-Recall and ROC curves)
![[Go through 7] Notes from the first section of the fully connected neural network video](/img/e2/1107171b52fe9dcbf454f7edcdff77.png)
[Go through 7] Notes from the first section of the fully connected neural network video
【零基础开发NFT智能合约】如何使用工具自动生成NFT智能合约带白名单可Mint无需写代码
AIDL详解
【数据库和SQL学习笔记】5.SELECT查询3:多表查询、连接查询
flink实例开发-详细使用指南
怎么更改el-table-column的边框线
随机推荐
spark-DataFrame数据插入mysql性能优化
【MySQL】数据库多表链接的查询方式
HQL statement execution process
flink项目开发-配置jar依赖,连接器,类库
【Reading】Long-term update
【数据库和SQL学习笔记】5.SELECT查询3:多表查询、连接查询
拿出接口数组对象中的所有name值,取出同一个值
Tensorflow踩坑笔记,记录各种报错和解决方法
day9-字符串作业
ES6 Set、WeakSet
js实现数组去重
JSX基础
【After a while 6】Machine vision video 【After a while 2 was squeezed out】
序列基础练习题
【Over 16】Looking back at July
[Go through 11] Random Forest and Feature Engineering
鼠标放上去变成销售效果
怎样在Disciples门徒获得收益?
解决端口占用问题
基于Flink CDC实现实时数据采集(三)-Function接口实现