当前位置:网站首页>[Go through 7] Notes from the first section of the fully connected neural network video
[Go through 7] Notes from the first section of the fully connected neural network video
2022-08-05 05:25:00 【Mosu playing computer】
Article table of contents
Today is dp
June 25, 2022 Check out 7
Fully Connected Neural Network
Cascade multiple linear classifiers
The weight is the template

If in a linear classifier, the number of w lines isFixed, it is the same as the number of categories.So learn horses, learn two ends (obviously wrong)
But if you are in a full connection, you only require that w2 is fixed, w1 is casual, create 100 lines, 100 templates, and 10 of them are dividedIt is used to learn horses, learn single-headed horses, and then use the activation function to select them.That's right.
Name
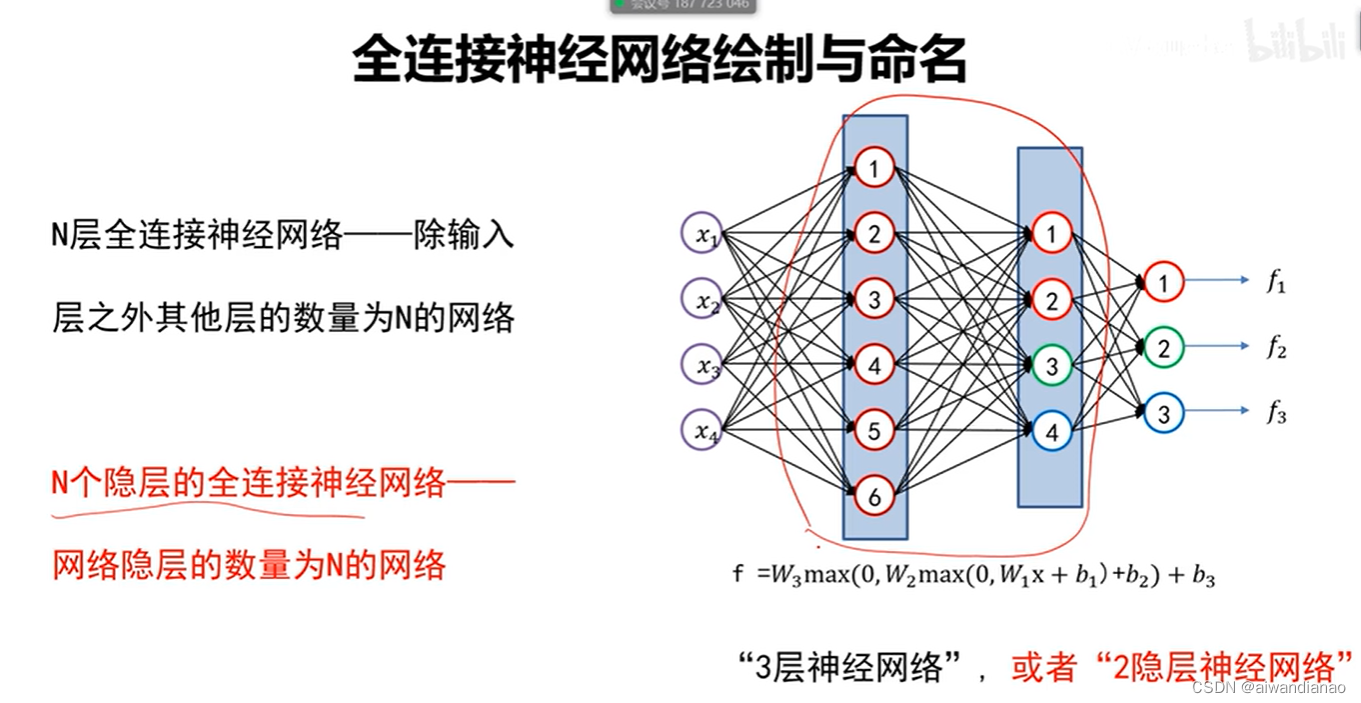
Generally speaking, the former
Activation function
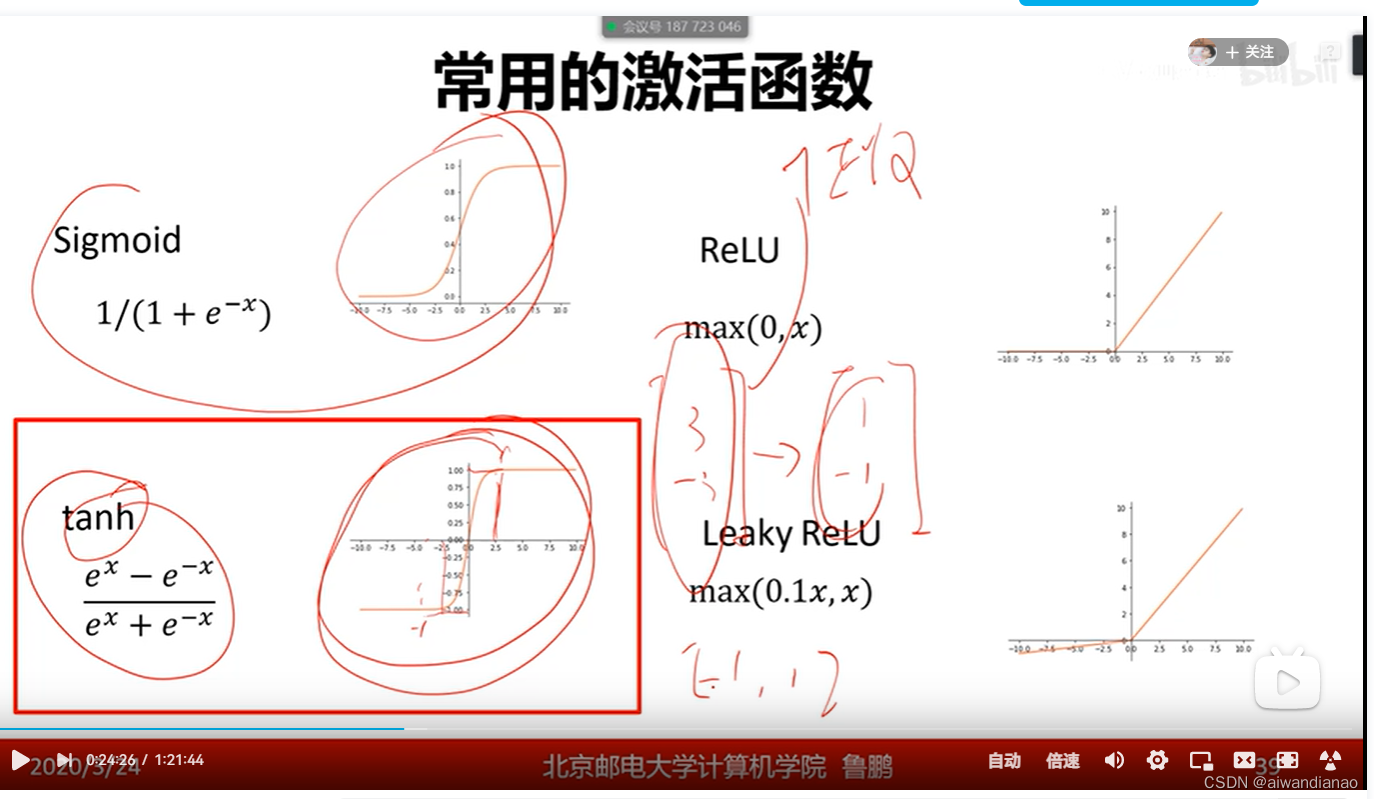
sigmoid is between 0-1
tanh is between -1 and 1, and it is symmetrical
softmax
We can set the output class according to the maximum value of the last value, but if we need to know how much predicted probability is, we need softmax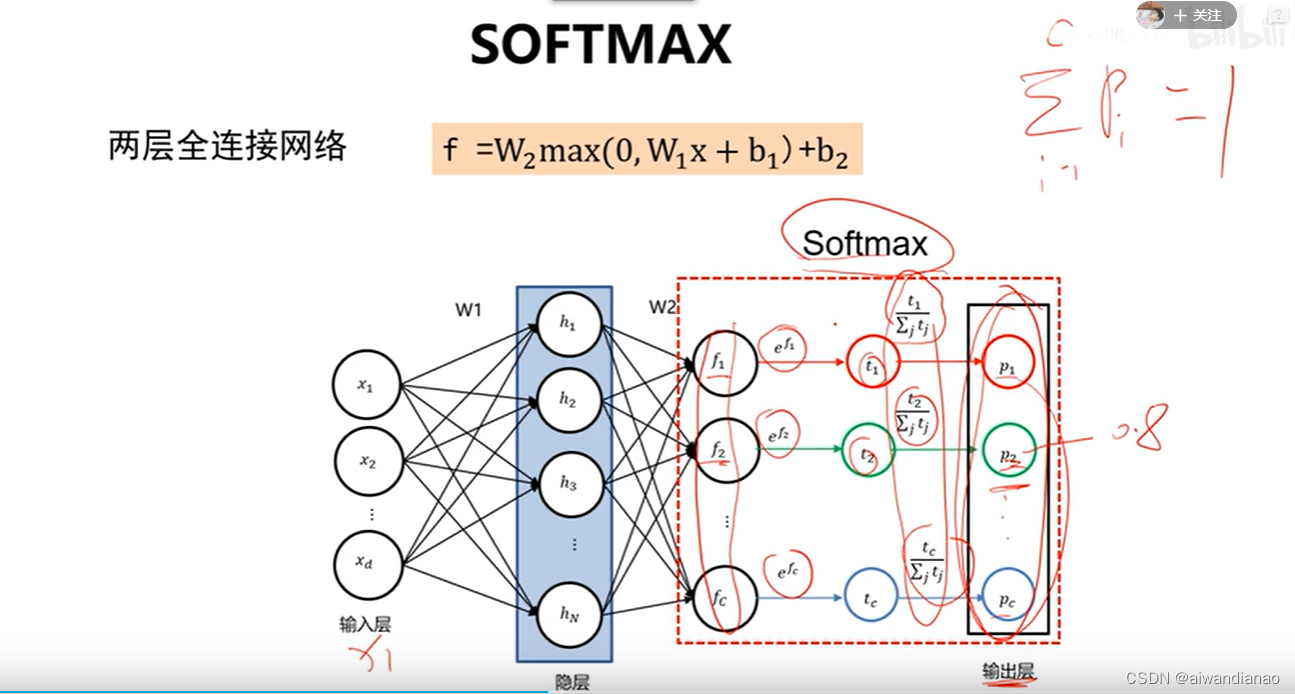
Take e to the power of the exponent, then normalize it
Cross-entropy loss
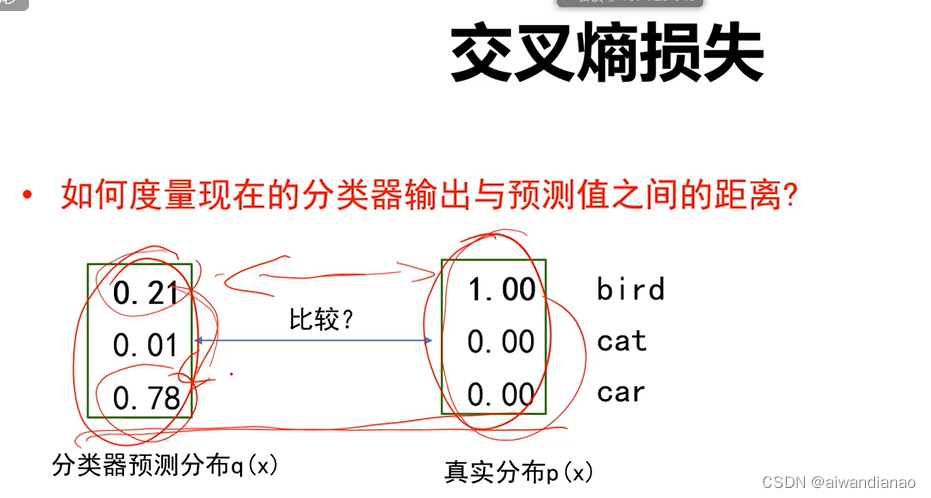 Cross-entropy loss is used to compare the difference between distributionsSimilarity , can not say distance, distance is AB BA is the same, has exchange, but entropy is not necessarily
Cross-entropy loss is used to compare the difference between distributionsSimilarity , can not say distance, distance is AB BA is the same, has exchange, but entropy is not necessarily 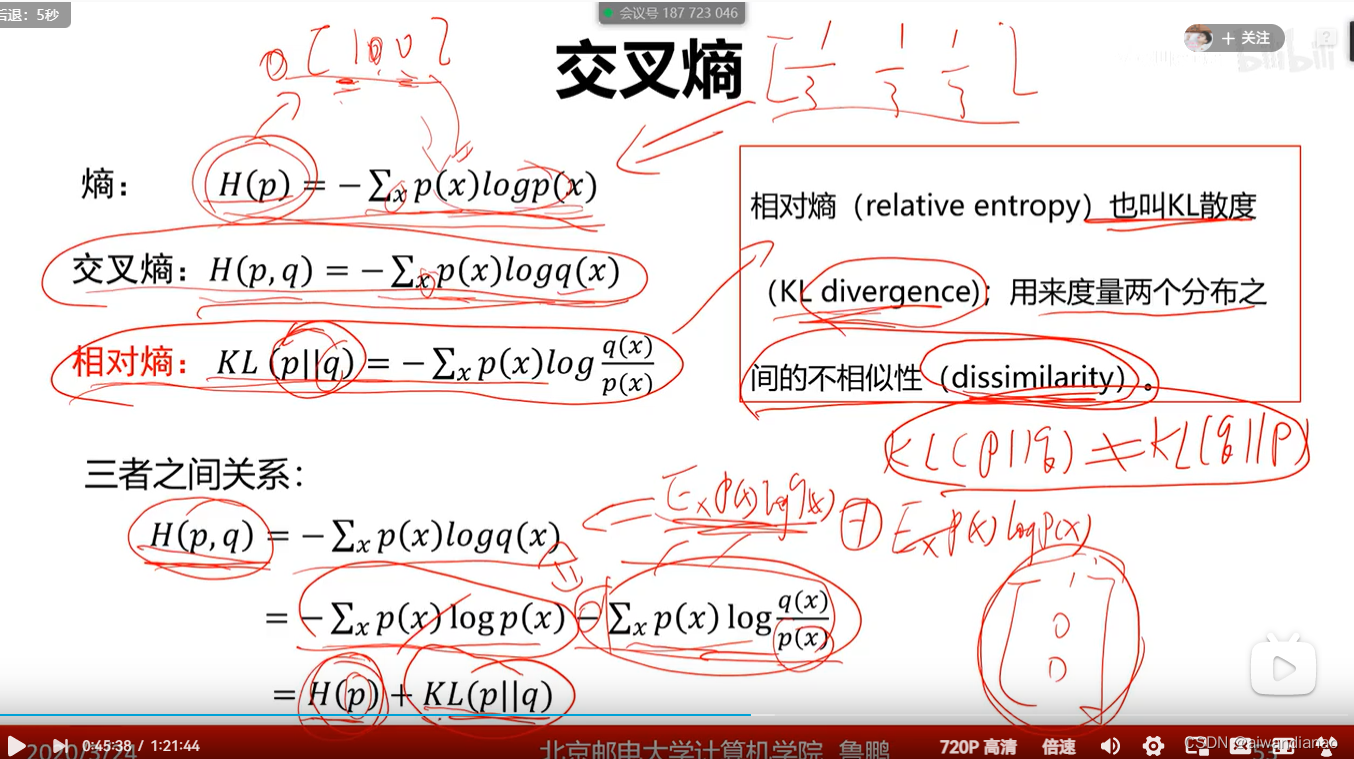
And H[p] is the ground truth, the information it reflects is not confusing at all, so the entropy is 0.Cross entropy is 0+relative entropy.After simplification, it is the -log of the correct classification score.
But when the H[p] standard is not one-hot encoding, it is necessary to honestly use the relative entropy (KL divergence).
The teacher mentioned here: It may be in trainingAt the same time, there is a situation where "loss has not decreased, but accuracy has increased".Just like the example in the lower right corner of the figure above (assuming the third column is the correct classification),
0.35 0.33 0.32 (obviously not correct)
0.333 0.332 0.334 (correct)
For the correct classification-log 0.35 and -log0.333 are actually not much different, but his probability has become larger, and he stands out with a small improvement (0.334>0.333)
Calculation graph
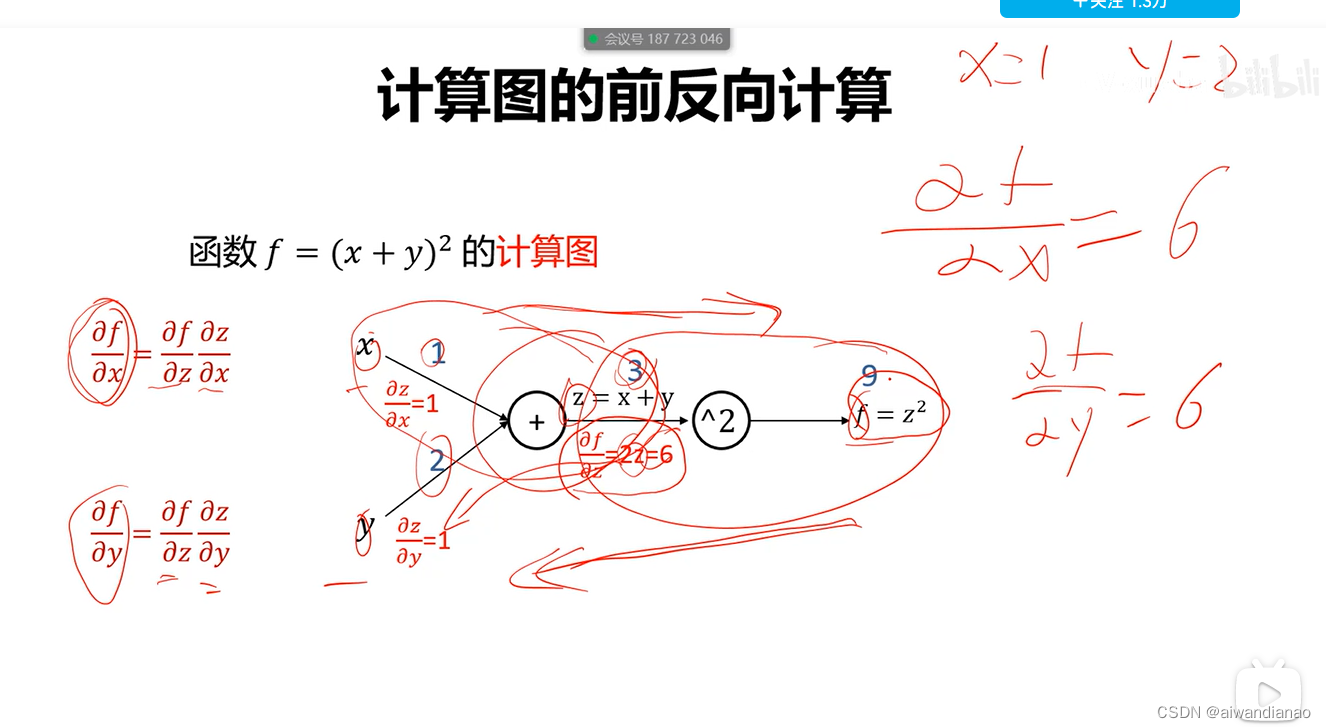 The positive value is the value, the negative direction is the gradient, chain derivationMultiplyable
The positive value is the value, the negative direction is the gradient, chain derivationMultiplyable
Each node of the computational graph stores forward-propagation values and a reverse Jacobian matrix for forward and back-propagation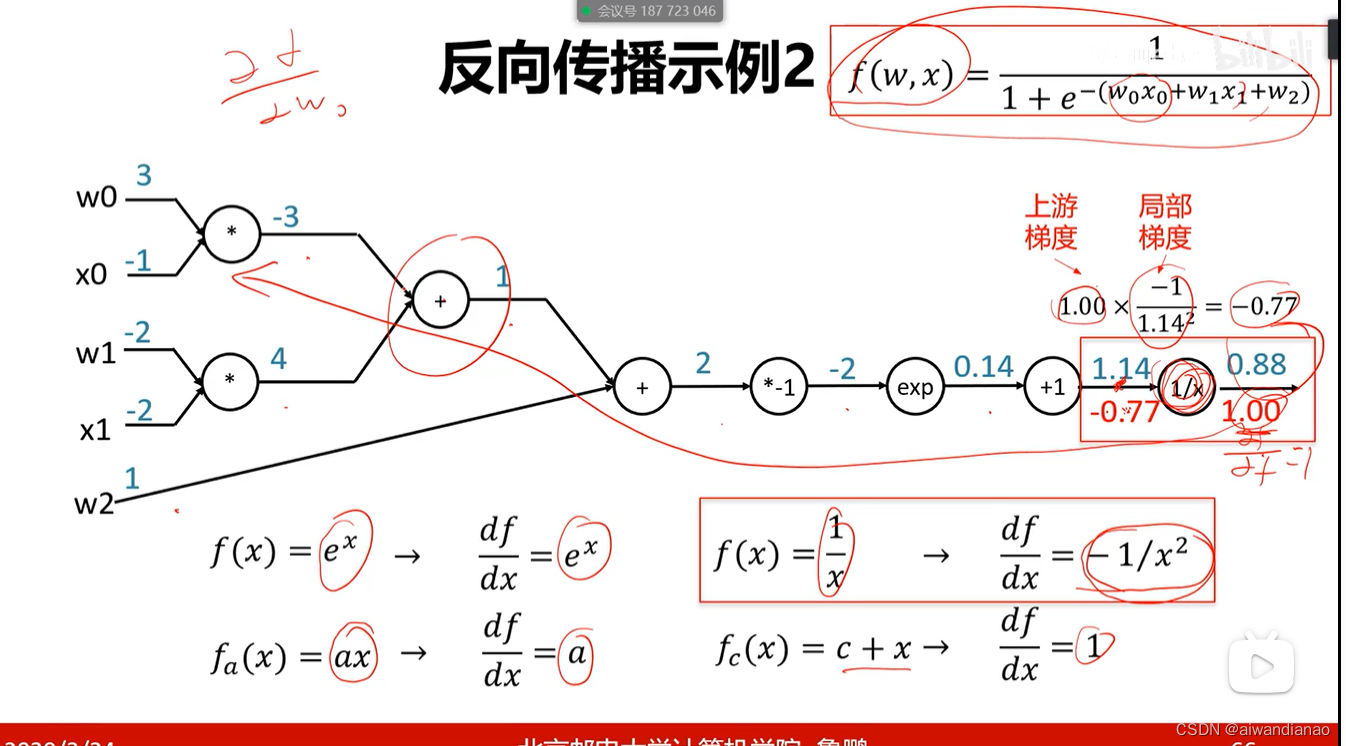
Granularity
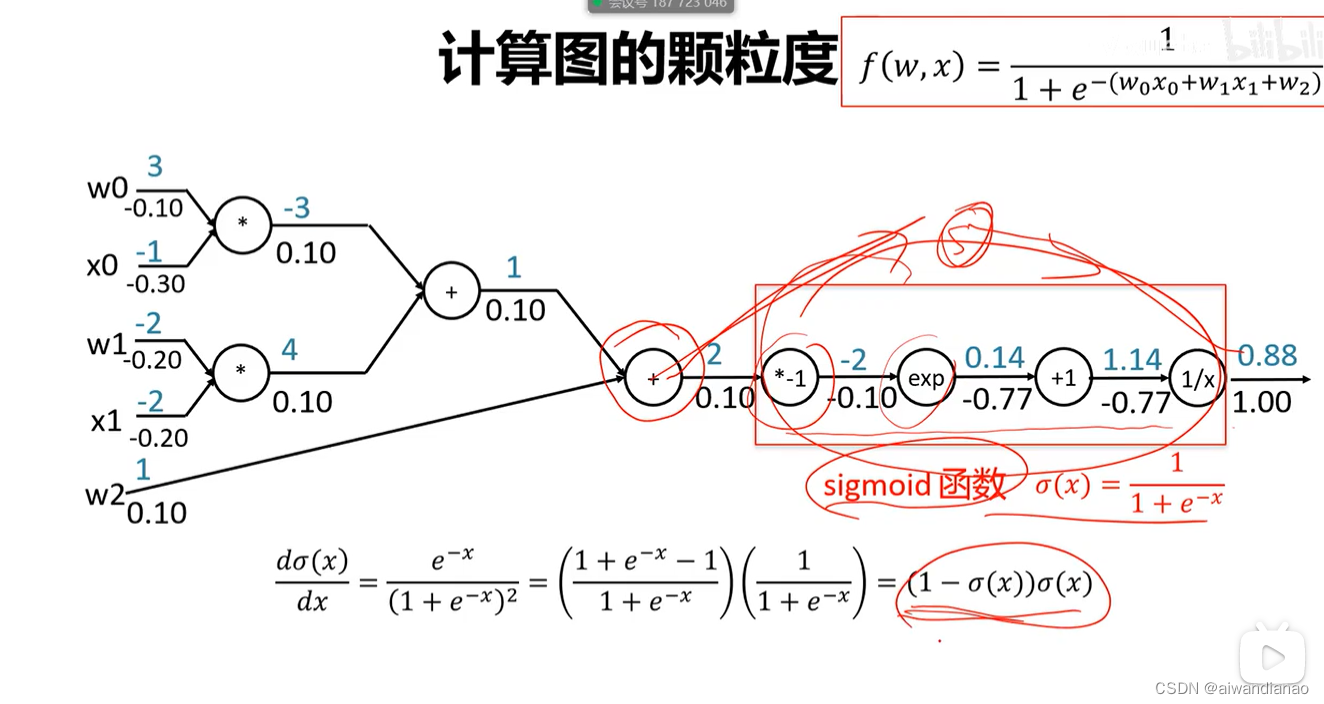
A series of gates can be connected together to formA function gate like sigmoid has a large granularity, but has few calculation steps and is fast in operation.
Caffe someone wrote these functions, so it is fast; TensorFlow is a small gate, so the parameter return, slow (later improved)
Common door units
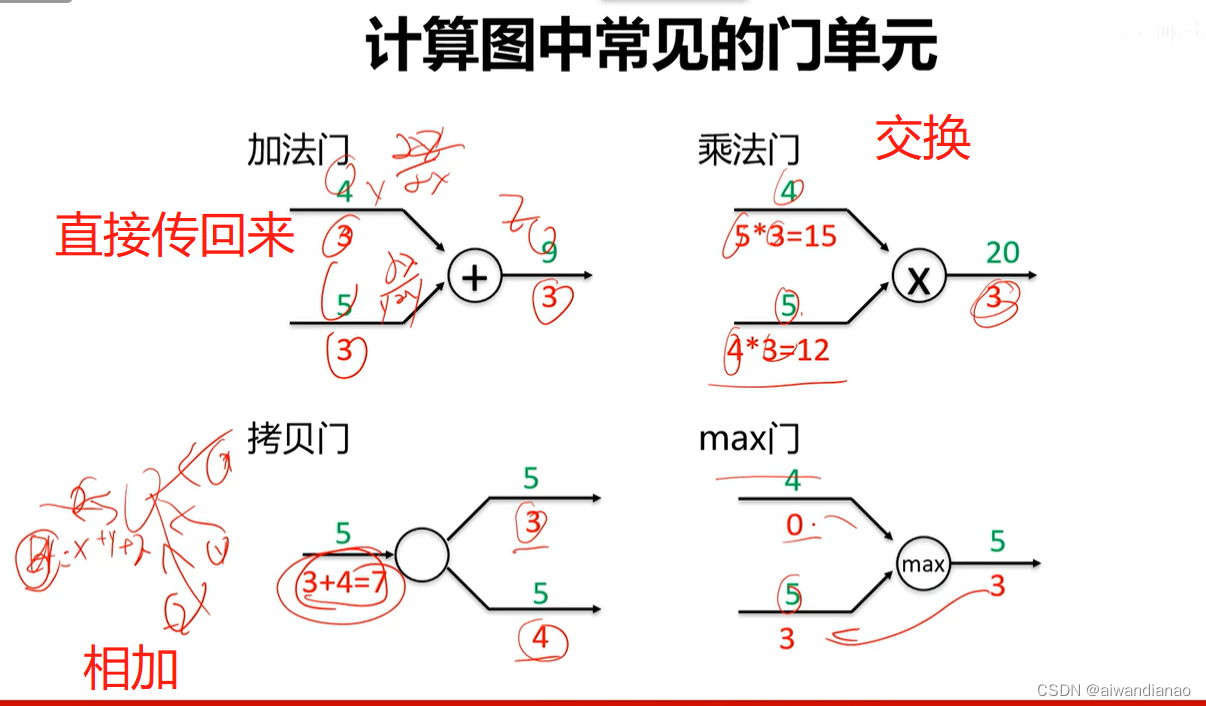
max is the larger number, and it will be passed to whoever.
Today, I watched the video of the third section, but unfortunately the notes I read in the pdf were squeezed out.I didn't stay, otherwise I can compare it and add it.
Send
I didn't sleep well this morning, got up with a golden shovel, then ate, rushed into the study room in the rain, was happy here, did whatever I wanted, and left at night for an hour of fast study.Hurry up.
边栏推荐
- [Go through 3] Convolution & Image Noise & Edge & Texture
- 【过一下6】机器视觉视频 【过一下2被挤掉了】
- human weakness
- The difference between span tag and p
- "Recursion" recursion concept and typical examples
- Distributed systems revisited: there will never be a perfect consistency scheme...
- 数据库 单表查询
- 【过一下7】全连接神经网络视频第一节的笔记
- 软件设计 实验四 桥接模式实验
- What field type of MySQL database table has the largest storage length?
猜你喜欢

The mall background management system based on Web design and implementation
How can Flutter parent and child components receive click events
vscode+pytorch使用经验记录(个人记录+不定时更新)

多线程查询结果,添加List集合
第二讲 Linear Model 线性模型

Error creating bean with name 'configDataContextRefresher' defined in class path resource
2022 Hangzhou Electric Multi-School 1st Session 01

A blog clears the Redis technology stack
Multi-threaded query results, add List collection
Geek卸载工具
随机推荐
phone call function
Flutter learning 2-dart learning
Flutter学习-开篇
Database experiment five backup and recovery
[WeChat applet] WXML template syntax - conditional rendering
u-boot debugging and positioning means
2022牛客多校第四场C.Easy Counting Problem(EGF+NTT)
开发一套高容错分布式系统
Transformation 和 Action 常用算子
多线程查询结果,添加List集合
OFDM 十六讲 5 -Discrete Convolution, ISI and ICI on DMT/OFDM Systems
判断语句_switch与case
LeetCode: 1403. Minimum subsequence in non-increasing order [greedy]
「PHP8入门指南」PHP简明介绍
[Software Exam System Architect] Software Architecture Design ③ Domain-Specific Software Architecture (DSSA)
2022 The 4th C.Easy Counting Problem (EGF+NTT)
【cesium】Load and locate 3D Tileset
MySQL基础(一)---基础认知及操作
Qt制作18帧丘比特表白意中人、是你的丘比特嘛!!!
Structured light 3D reconstruction (1) Striped structured light 3D reconstruction