当前位置:网站首页>spark源码-任务提交流程之-7-流程梳理总结
spark源码-任务提交流程之-7-流程梳理总结
2022-08-05 05:18:00 【zdaiqing】
spark-submit执行流程梳理
1.概述
本阶段都是基于spark-on-yarn-cluster模式进行梳理分析;
在前面的分析过程中,顺着spark-submit提交后,代码的执行顺序从前向后阶段性的进行了分析(详见参考资料);
接下来将基于前期的分析进行梳理总结;
2.启动sparkSubmit进程
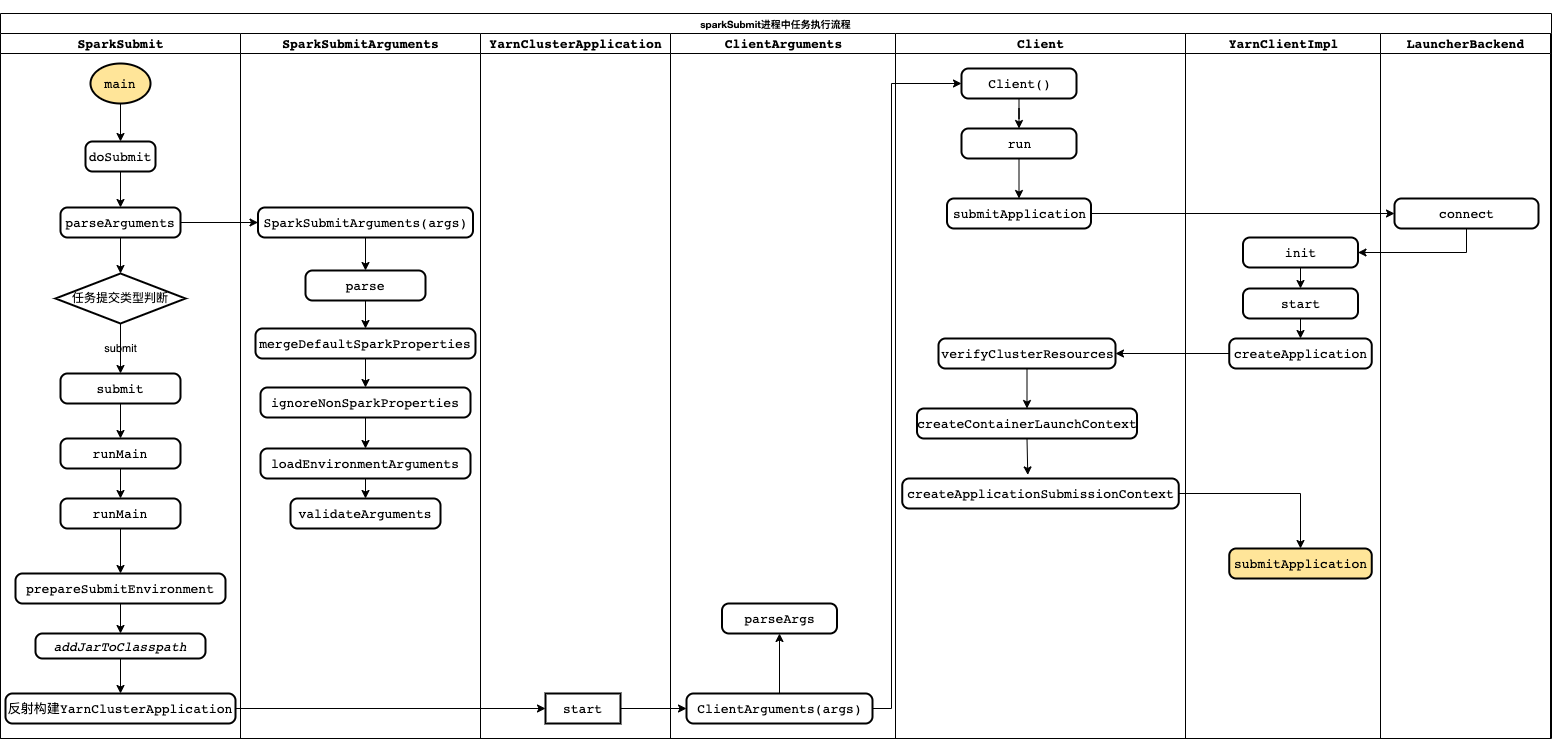
在sparkSubmit进程中:
1、调用SparkSubmitArguments对提交参数进行解析、校验、封装;
2、根据提交参数判断任务提交类型,针对spark-submit任务,走任务提交流程;
3、准备任务提交环境(jar包路径、spark集群应用类-org.apache.spark.deploy.yarn.YarnClusterApplication)、加载外部jar包;
4、根据spark集群应用类YarnClusterApplication实例化应用对象app,并调用应用对象app.start()方法启动应用;
5、由spark集群应用app构造客户端参数对象clientArguments封装客户端参数,然后启动客户端client;
6、客户端client中初始化和启动yarnClient;
7、由Client#verifyClusterResources()验证集群资源、Client#createContainerLaunchContext()封装命令,Client#createApplicationSubmissionContext()设置启动AM的上下文;
8、client调用yarnClient#submitApplication()提交应用到RM启动AM;
注意:
在由client调动Client#createContainerLaunchContext()方法设置启动AM的上下文过程中,会封装启动AM的命令,其中针对yarn-cluster模式,会封装通过/bin/java启动org.apache.spark.deploy.yarn.ApplicationMaster进程的命令;
RM选择NN根据这下命令启动AM;
3.启动ApplicationMaster进程

在AM进程中:
1、根据反射获取用户类main方法,然后实例化并启动一个driver线程,由driver线程通过反射调用用户类main方法;
2、AM向yarn的RM注册;
3、AM向RM申请资源;
4、AM轮询从RM获取的资源列表(containers),开启新线程由线程池执行;在线程中向资源NN发送指令启动ExecutorBackend进程;
注意:
driver线程是AM进程的一个线程;
driver线程负责执行用户类main方法;
在申请资源时,会构建分配器,由分配器负责资源申请与向资源发送指令;
在构建分配器后,申请资源前,会将AM节点通过rpcEnv注册到消息分发器中;
4.启动CoarseGrainedExecutorBackend进程
CoarseGrainedExecutorBackend中任务执行流程:

rpc消息通信流程:
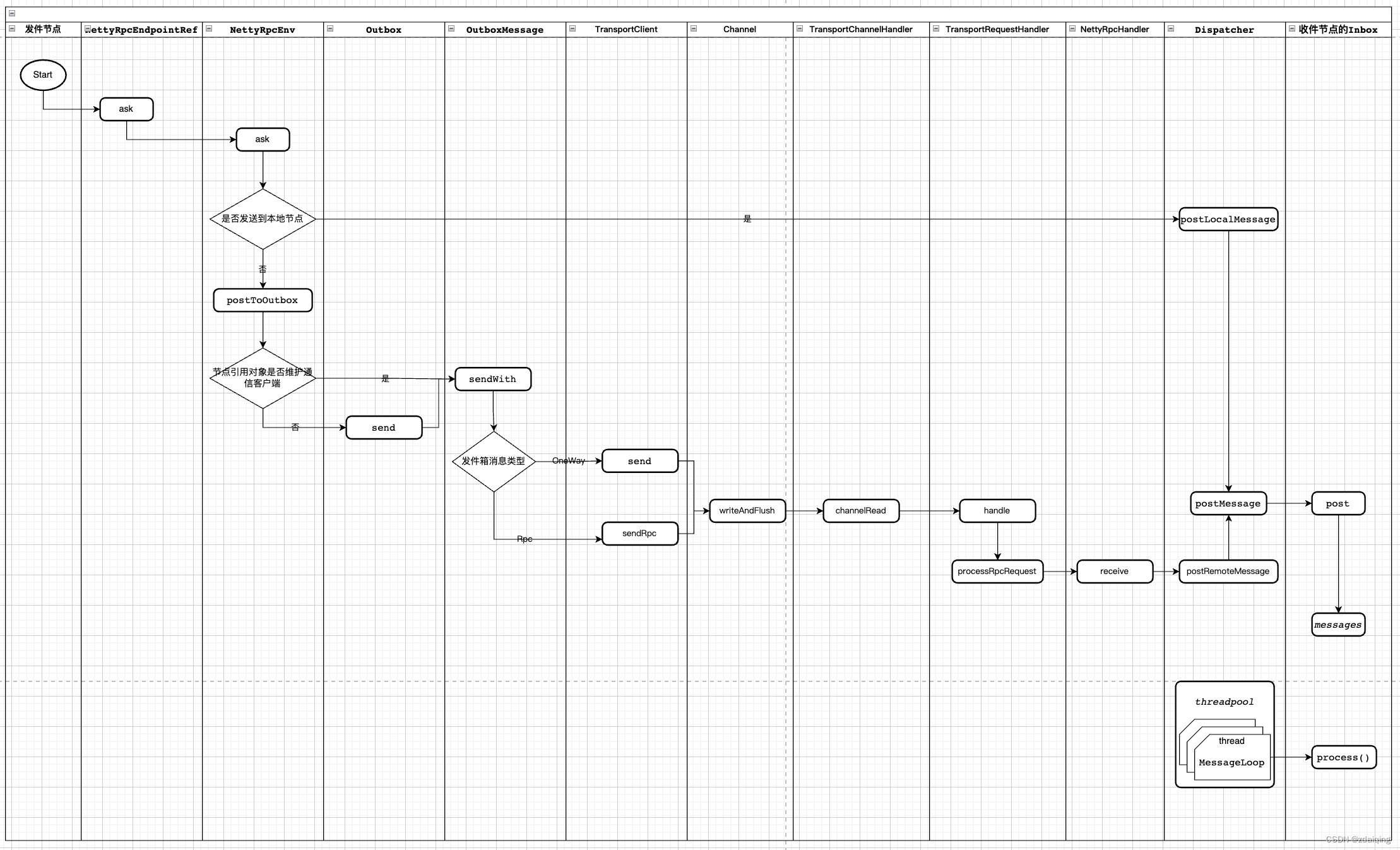
在CoarseGrainedExecutorBackend进程中:
1、获取rpcEnv对象:
在rpcEnv对象中,维护了一个消息分发器dispatcher对象;
dispatcher对象中维护了一个线程池,线程池中线程从阻塞队列中获取收件节点,处理收件节点的收件箱中消息—>调用收件节点与消息类型对应的处理方法处理消息;
2、向rpcEnv中注册Executor节点(CoarseGrainedExecutorBackend对象):
节点缓存在消息分发器缓存器中后,回向executor节点的收件箱中添加一条Onstart消息;
如1中所述,消息分发器维护的线程池会调用线程处理executor节点收件箱的消息,在Onstart消息添加进来后,即会调用executor节点(CoarseGrainedExecutorBackend对象)的onStart方法进行后续处理;
3、在executor节点的onStart方法中:
获取driver节点引用对象;
通过driver节点引用对象向driver注册executor节点;
driver节点注册executor完成后,会想executor节点回信注册成功;还会想executor节点分配任务;
4、executor节点处理driver的回信以及分配的任务:
收到回信后,实例化Executor对象;
回信处理完成后,处理driver分配的任务:给每个任务建一个线程,将线程交给Executor的线程池执行;
5.driver线程后续执行流程

在driver执行用户线程过程中:
1、首先实例化SparkContext对象;
2、初始化SparkEnv对象;在这过程中初始化RpcEnv对象;
3、在初始化RpcEnv对此过程中,构建消息分发器;针对非客户端环境,开启TransportServer;
4、初始化_schedulerBackend、_taskScheduler、_dagScheduler;
5、启动schedulerBackend、_taskScheduler,向rpcEnv注册driver节点;
6、其他DAG逻辑;
6.参考资料
spark源码-任务提交流程之-2-YarnClusterApplication
spark源码-任务提交流程之-3-ApplicationMaster
spark源码-任务提交流程之-4-container中启动executor
spark源码-任务提交流程之-5-CoarseGrainedExecutorBackend
Spark源码-任务提交流程之-6-sparkContext初始化
Spark源码-任务提交流程之-6.1-sparkContext初始化-创建spark driver端执行环境SparkEnv
Spark源码-任务提交流程之-6.2-sparkContext初始化-TaskScheduler任务调度器
边栏推荐
猜你喜欢



随机推荐
Redis设计与实现(第三部分):多机数据库的实现
D39_欧拉角与四元数
【UiPath2022+C#】UiPath 数据操作
电子产品量产工具(2)- 输入系统实现
1008 数组元素循环右移问题 (20 分)
十、视图解析原理与源码分析
无影云桌面
Unity3D中的ref、out、Params三种参数的使用
UiPath简介
2020年手机上最好的25种免费游戏
C语言—扫雷的实现
每日一题-盛最多水的容器-0716
MySQL主从复制—有手就能学会的MySQL集群搭建教程
huatuo 革命性热更新解决方案系列1·1 为什么这么NB?huatuo革命Unity热更新
每日一题-删除链表的倒数第 N 个结点-0718
【ts】typescript高阶:联合类型与交叉类型
亲身实感十多年的面试官面试的题目
栈区中越界可能造成的死循环可能
Autoware--北科天绘rfans激光雷达使用相机&激光雷达联合标定文件验证点云图像融合效果
1004 成绩排名 (20 分)