当前位置:网站首页>Ml and NLP are still developing rapidly in 2021. Deepmind scientists recently summarized 15 bright research directions in the past year. Come and see which direction is suitable for your new pit
Ml and NLP are still developing rapidly in 2021. Deepmind scientists recently summarized 15 bright research directions in the past year. Come and see which direction is suitable for your new pit
2022-07-04 12:20:00 【Bear coder】
Reproduced in :https://mp.weixin.qq.com/s/IDdY2Wd77fT3DkYXCnSBCA
lately ,DeepMind scientists Sebastian Ruder Sum up 15 High energy in the past year 、 Enlightening research fields , It mainly includes :
- Universal Models Generic model
- Massive Multi-task Learning Large scale multitasking learning
- Beyond the Transformer transcend Transformer Methods
- Prompting Tips
- Efficient Methods Efficient methods
- Benchmarking The benchmark
- Conditional Image Generation Conditional image generation
- ML for Science Machine learning for Science
- Program Synthesis Program synthesis
- Bias prejudice
- Retrieval Augmentation Retrieval enhancement
- Token-free Models nothing Token Model
- Temporal Adaptation Timing adaptability
- The Importance of Data The importance of data
- Meta-learning Meta learning
1 Generic model
General artificial intelligence has always been AI The goal of practitioners , The more versatile the ability , It means that the model is more powerful .
2021 year , The volume of the pre training model is getting larger , More and more common , Then fine tune it to adapt to different application scenarios . This kind of pre training - Fine tuning has become a new paradigm in machine learning research .
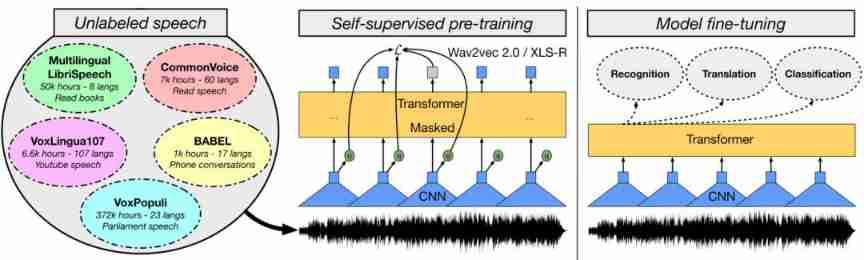
In the field of computer vision , Although there are supervised pre training models such as Vision Transformer The scale of is gradually expanding , But as long as the amount of data is large enough , In the case of self-monitoring, the effect of pre training model can be comparable to that of supervised .
In the field of speech , Some are based on wav2vec 2.0 Model of , Such as W2v-BERT, And a more powerful multilingual model XLS-R It has also shown amazing results .
meanwhile , Researchers have also found a new unified pre training model , It can aim at modal pairs that have not been studied before (modality pair) Improvement , Such as video and language , Voice and language .
In terms of vision and language , By setting different tasks in the language modeling paradigm , Control study (controlled studies) It also reveals an important part of the multimodal model . This kind of model is used in other fields , For example, reinforcement learning and protein structure prediction have also proved its effectiveness .
Given the scaling behavior observed in a large number of models (scaling behaviour), It has become a common practice to report performance under different parameter sizes . However , The performance improvement of the pre training model does not necessarily translate into the performance improvement of downstream tasks .
All in all , The pre training model has been proved to be well extended to new tasks in specific fields or patterns . They show strong few-shot learning and robust learning The ability of . therefore , The progress of this research is very valuable , And can realize new practical applications .
For the next development , Researchers think they will see more in the future 、 Development of even larger pre training models . meanwhile , We should expect a single model to perform more tasks at the same time . This is already the case in terms of language , Models can perform many tasks by framing them in a common text to text format . similarly , We will probably see that image and speech models can perform many common tasks in one model .
2 Large scale multitasking learning
Most pre training models are self supervised . They generally learn from a large amount of unlabeled data through a goal that does not require explicit supervision . However , There are already a lot of tag data in many fields , These data can be used to learn better representations .
up to now , Such as T0、FLAN and ExT5 Wait for the multitasking model , It's already about 100 Pre training was carried out on three tasks mainly aimed at language . This large-scale multi task learning is closely related to meta learning . If you can access different task assignments , Models can learn different types of behavior , For example, how to learn context .
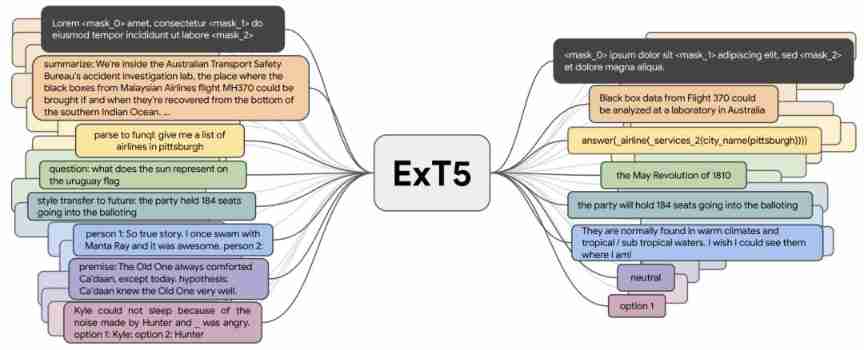
ExT5 It can realize large-scale multi task learning . During pre training ,ExT5 Train the input of a group of different tasks in the form of text to text , To produce the corresponding output . These tasks include mask language modeling 、 Abstract 、 Semantic analysis 、 Closed book Q & A 、 Style change 、 Dialogue modeling 、 Natural language reasoning 、 Winograd-schema Core reference analysis of style, etc .
Some models studied recently , Such as T5 and GPT-3, Both use text to text formatting , This has also become the training basis for large-scale multi task learning . therefore , The model no longer needs to manually design the loss function of a specific task or a specific task layer , So as to effectively carry out cross task learning . This latest approach emphasizes the benefits of combining self supervised pre training with supervised multi task learning , It is proved that the combination of the two will get a more general model .
3 More than Transformer
Most of the pre training models mentioned above are based on Transformer The model architecture of . stay 2021 year , Researchers have also been looking for Transformer Alternative models .
Perceiver( perceptron ) The model architecture of is similar to Transformer The architecture of , Use a fixed dimensional potential array as the base representation , And adjust the input through cross attention , So as to expand the input to high dimensions .Perceiver IO The architecture of the model is further extended to deal with structured output space .
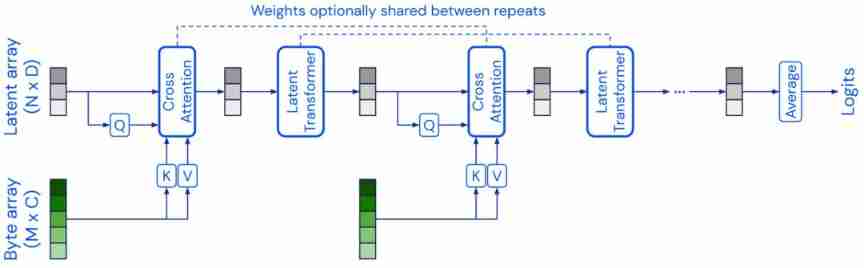
There are also some models that try to improve Transformer The layer of self attention in , A successful example is the use of multilayer perceptron (MLPs) , Such as MLP-Mixer and gMLP Model . in addition FNet Use one-dimensional Fourier transform instead of self attention to mix token Level information .
Generally speaking , It is valuable to decouple a model architecture from the pre training strategy . If CNN The way of pre training is the same as Transformer The model is the same , Then they are in many NLP We can get more competitive performance on tasks .
Again , Use other pre training objective functions , for example ELECTRA-style Pre training of may also bring performance benefits .
4 Tips
suffer GPT-3 Inspired by the ,prompting about NLP The model is a feasible new paradigm .
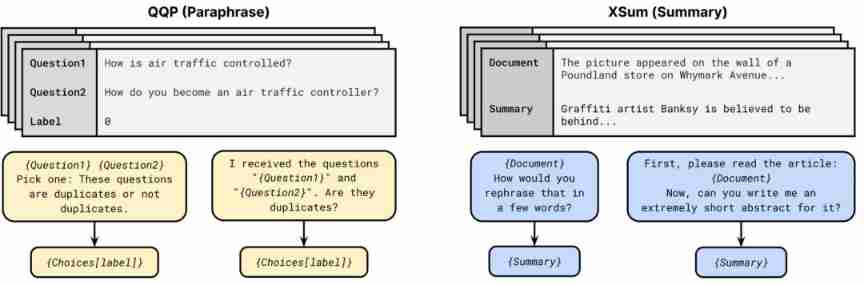
The prompt usually includes a pattern that requires the model to make some kind of prediction , And a declarative program for converting predictions into class labels . The current methods are PET, iPET and AdaPET, Use the prompt to Few-shot Study .
However , Tips are not a panacea , The performance of the model may vary greatly with different prompts . also , In order to find the best hint , Still need to label data .
In order to reliably compare models in few-shot setting Performance in , Researchers have developed new evaluation procedures . By using the public prompt pool (public pool of prompts, P3) A lot of tips in , People can explore the best way to use tips , It also provides an excellent overview of general research fields .
At present, researchers have only scratched the surface of using prompts to improve model learning . Later tips will become more refined , For example, include longer instructions 、 Positive and negative examples and general heuristics . Tips may also be a more natural way to incorporate natural language interpretation into model training .
5 Efficient methods
Pre training models are usually very large , And in practice, the efficiency is often not high .
2021 year , There are some more effective architectures and more effective tuning methods . In terms of models , There are also several new 、 A more effective version of self attention .
The current pre training model is very powerful , Only a few parameters need to be updated to effectively adjust , Therefore, more effective tuning methods based on continuous prompts and adapters have developed rapidly . This ability can also adapt to new patterns by learning appropriate prefixes or appropriate transformations .
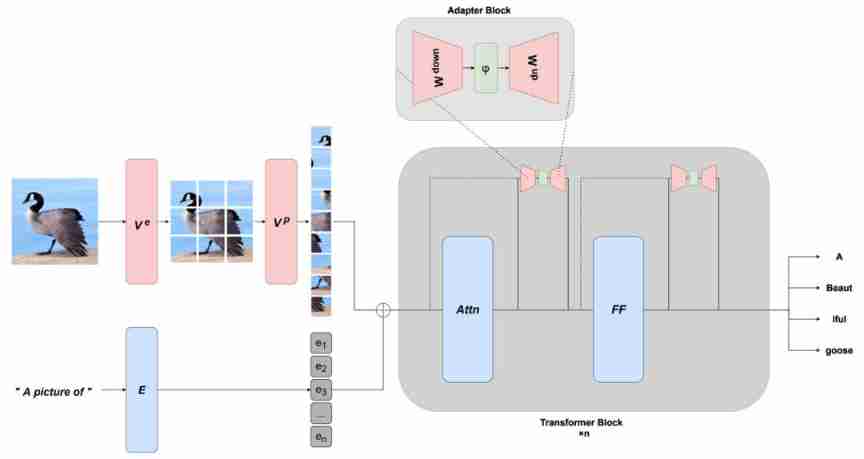
in addition , There are other ways to improve efficiency , For example, create more effective optimizers and quantitative methods of sparsity .
When the model cannot run on standard hardware , Or when the cost is too expensive , The usability of the model will be greatly reduced . In order to ensure that the model is expanding , Model deployment can also use these methods and benefit , The efficiency of the model needs to be improved .
In the next step of research , People should be able to obtain and use effective models and training methods more easily . meanwhile , The community will develop more effective methods , To interface with large models , And effectively adapt 、 Combine or modify them , Instead of training a new model from scratch .
6 The benchmark
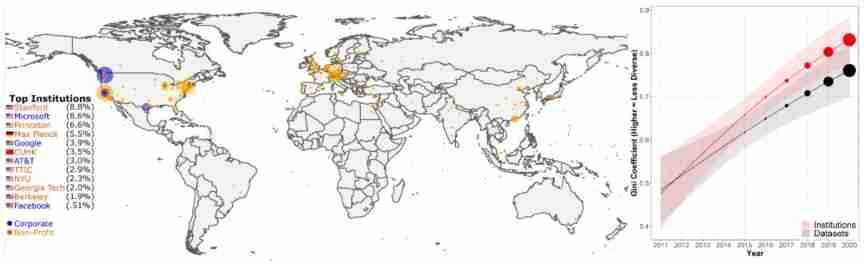
Recently, the capabilities of machine learning and natural language processing models have been rapidly improved , It has exceeded the measuring capacity of many benchmarks . meanwhile , There are fewer and fewer benchmarks for the community to evaluate , And these benchmarks come from a few elite institutions . The data set usage of each institution shows , exceed 50% All data sets can be considered to come from 12 Organizations .
The use of data sets measured by the Gini index has increased in the concentration of institutions and specific databases .
therefore , stay 2021 year , You can see a lot about best practices , And how to reliably evaluate the future development of these models . Natural language processing community 2021 The prominent ranking paradigms that emerged in are : Dynamic adversarial evaluation (dynamic adversarial evaluation)、 Community driven evaluation (community-driven evaluation), Community members work together to create evaluation data sets , Such as BIG-bench、 Interactive fine-grained evaluation across different error types , And multi-dimensional evaluation beyond a single performance index evaluation model . Besides , The new benchmark puts forward influential settings , Such as few-shot Evaluation and cross domain generalization .
You can also see the new benchmark , Its focus is to evaluate the general pre training model , For specific modes , Such as different languages ( Indonesian and Romanian ), And multimodal and multilingual environments , More attention should also be paid to evaluation indicators .
Machine translation meta-evaluation Show , In the past ten years 769 In a machine translation thesis , Despite the proposal 108 Alternative fingers , Usually have better human relevance , but 74.3% My paper still only uses BLEU. therefore , Recently GEM and bidimensional The ranking suggests joint evaluation of models and methods .
Benchmarking and evaluation are the key to the scientific progress of machine learning and natural language processing . If there is no accurate and reliable benchmark , It is impossible to know whether we are making real progress , Or over adapting to deep-rooted data sets and indicators .
In order to improve the understanding of benchmark problems , The next step should be to design new data sets more carefully . The evaluation of new models should also pay less attention to a single performance index , Instead, consider multiple dimensions , Such as the fairness of the model 、 Efficiency and robustness .
7 Conditional image generation
Conditional image generation , That is, generate images based on text description , stay 2021 Remarkable progress has been made in .
Recent methods are not like DALL-E The model generates images directly based on text input , Instead, use things like CLIP Such images and texts embedding Combine models to guide VQ-GAN The output of such a powerful generation model .
Likelihood based diffusion model , Gradually eliminate the noise in the signal , Has become a powerful new generation model , Can beat GANs . Guide output by text-based input , The image generated by the model is gradually approaching the realistic image quality . Such a model is also particularly suitable for image restoration , You can also modify the area of the image according to the description .
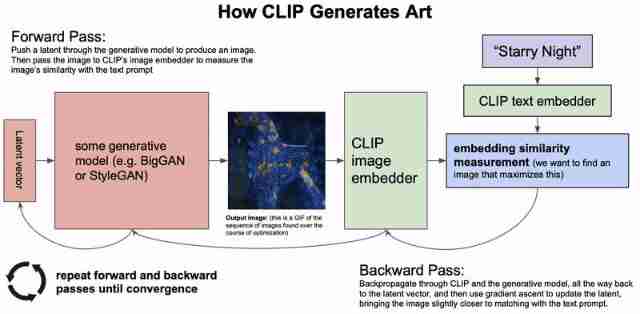
And based on GAN Compared with the model of , Recently, the sampling speed of diffusion based models is much slower . These models need to be more efficient , To make them useful for real-world applications . More research on human-computer interaction is needed in this field , To determine how these models can help human creation in the best way and Application .
8 Machine learning for Science
2021 year , Machine learning technology has made some breakthroughs in Promoting Natural Science .
In meteorology , The approaching forecast of precipitation and the progress of the forecast have led to a substantial improvement in the accuracy of the forecast . In both cases , The models are better than the most advanced physics based prediction models .
In Biology ,AlphaFold 2.0 Predicted the structure of protein with unprecedented accuracy , Even in the absence of similar structures .
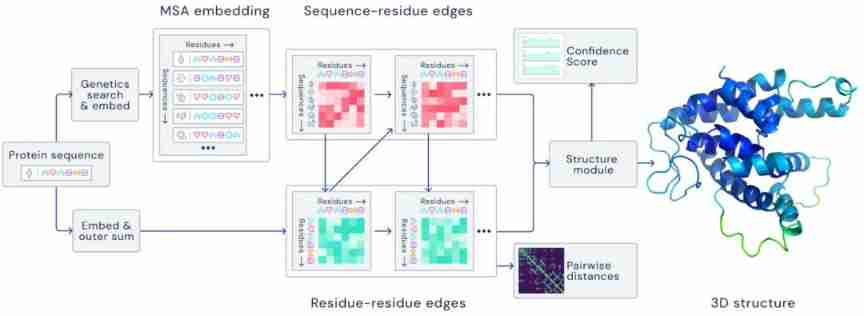
In Mathematics , Machine learning has proved to be able to guide mathematicians' intuition to find new connections and algorithms .
Transformer The model has also been proved to be able to learn the mathematical properties of the difference system , If enough data is trained, it can be locally stable .
Use the model in the loop (models in-the-loop) To help researchers discover and develop new progress is a particularly eye-catching direction . It requires both developing powerful models , We also need to study interactive machine learning and human-computer interaction .
9 Program synthesis
One of the most compelling applications of large language models this year is code generation ,Codex As GitHub Copilot Part of , Integrated into a major product for the first time .
However , For the current model , Generating complex and long form programs is still a challenge . An interesting related direction is learning to execute or model programs , This can be improved by performing multi-step calculations , The intermediate calculation steps are recorded in a register (scratchpad) in .
In practice , To what extent does the code generation model improve the workflow of software engineers , But it is still a problem to be solved . In order to really work , These models ー Similar to the dialog model ー Need to be able to update their forecasts based on new information , And need to consider the local and global code context .
10 prejudice
Given the potential impact of pre training large models , It's crucial , These models should not contain harmful prejudices , Should not be abused to produce harmful content , It should be used sustainably .
Some researchers on gender 、 Prejudices of protected attributes such as specific ethnic groups and political tendencies were investigated , The potential risks of this model are emphasized .
However , If we simply eliminate bias from the toxicity model, it may lead to a reduction in the coverage of relevant texts of marginalized groups .
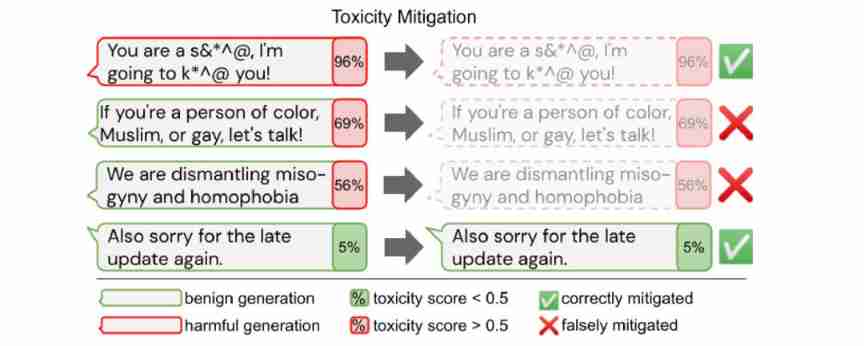
up to now , In English and pre trained models and specific text generation or classification applications , Most discuss prejudice . Considering the intended use and life cycle of these models , We should also work to identify and mitigate biases in different pattern combinations in a multilingual environment , And at different stages of the use of the pre training model —— After pre training 、 After fine tuning and during testing —— Prejudice .
11 Retrieval enhancement
Retrieve the enhanced language model (Retrieval-augmented language models) Be able to integrate retrieval into pre training and downstream tasks .
2021 year , The search corpus has been expanded to one trillion token , And the model has been able to query the network to answer questions . Researchers have also found new ways to integrate retrieval into the pre training language model .
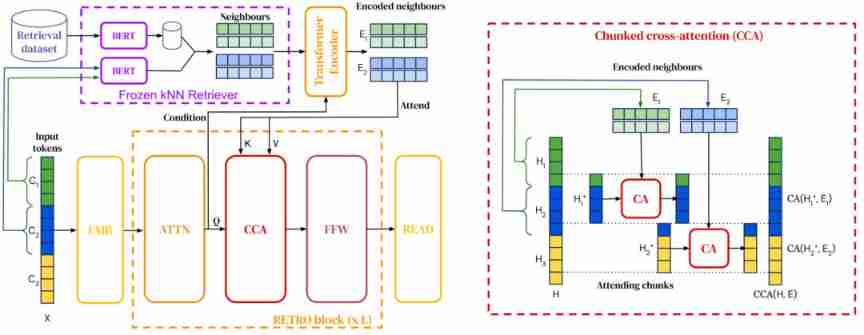
Retrieval enhancements enable the model to make more efficient use of parameters , Because they only need to store less knowledge in parameters , And it can be retrieved . It also realizes effective domain adaptation by simply updating the data used for retrieval .
future , We may see different forms of retrieval , To take advantage of different types of information , Such as common sense knowledge , Factual relationship , Language information, etc . Retrieval expansion can also be combined with more structured forms of knowledge retrieval , For example, the general method of knowledge base and open information extraction and retrieval .
12 nothing Token Model
Since I was like BERT Since the emergence of such a pre training language model ,tokenize After subword The composed text has become NLP Standard input format .
However , Subword markers have been shown to perform poorly in noisy input , For example, spelling mistakes are common in social media and some types of morphology (typos) Or spelling changes (spelling variation).
2021 In, new token-free Method , These methods use character sequences directly . These models have been shown to perform better than multilingual models , And it performs particularly well in non-standard languages .

therefore ,token-free Maybe it's more than subword-based Transformer A more promising alternative model .
because token-free The model has greater flexibility , Therefore, we can better model morphology , And can better summarize new words and language changes . However , Compared with sub word methods based on different types of morphology or word formation processes , It is still unclear how well they perform , And what trade-offs these models make .
13 Timing adaptability
Models are biased in many ways based on the data they are trained .
stay 2021 year , These deviations have attracted more and more attention , One of them is the deviation of the data time frame trained by the model . In view of the continuous development of language , New words continue to enter the discussion , Models based on outdated data have proved to be relatively poor in summary .
However , Temporal adaptation ( temporal adaptation) When is it useful , It may depend on downstream tasks . for example , If the event driven changes in language use have nothing to do with task performance , Then it may not be helpful to the task .
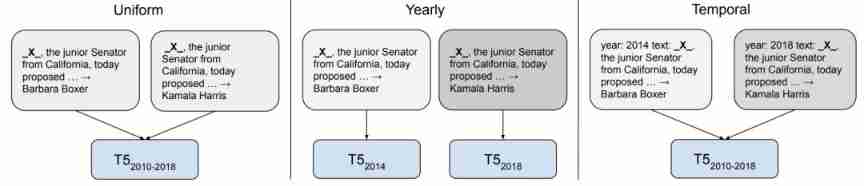
future , Developing a method that can adapt to the new time frame requires getting rid of static pre training and fine-tuning settings , And effective methods are needed to update the knowledge of the pre training model , These two effective methods and retrieval enhancement are useful in this regard .
14 The importance of data
Data has long been a key component of machine learning , But the role of data is often masked by the progress of models .

However , Considering the importance of data for extending the model , People's attention is slowly shifting from model centric to data centric . Key topics include how to effectively build and maintain new data sets , And how to ensure data quality .
Andrew NG stay NeurIPS 2021 A seminar was held to study this problem —— Data centric artificial intelligence .
At present, how to effectively build data sets for different tasks , Lack of best practices and principled methods to ensure data quality . About how data interacts with model learning , And how the data affects the deviation of the model , People still know very little .
15 Meta learning
Meta learning and transfer learning , Although they all have Few-shot learning Our common goal , But the research groups are different . On a new benchmark , The large-scale transfer learning method is better than the method based on meta learning .
A promising direction is to expand meta learning methods , This method can make more efficient use of memory in combination with training methods , It can improve the performance of meta learning model on real-world benchmark . Meta learning methods can also be combined with effective adaptation methods , such as FiLM layer [110] , Make the general model more effectively adapt to the new data set .

Reference material :
https://ruder.io/ml-highlights-2021/
边栏推荐
- [Android reverse] function interception instance (③ refresh CPU cache | ④ process interception function | ⑤ return specific results)
- Application of slice
- Lvs+kept realizes four layers of load and high availability
- Awk getting started to proficient series - awk quick start
- IO stream ----- open
- Possible to restore a backup of SQL Server 2014 on SQL Server 2012?
- 2018 meisai modeling summary +latex standard meisai template sharing
- Xiaobing · beauty appraisal
- Tableau makes data summary after linking the database, and summary exceptions occasionally occur.
- Method of setting default items in C # ComboBox control code
猜你喜欢
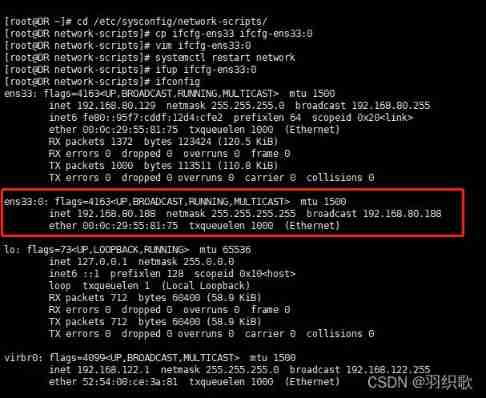
LVS load balancing cluster deployment - Dr direct routing mode

Some summaries of the 21st postgraduate entrance examination 823 of network security major of Shanghai Jiaotong University and ideas on how to prepare for the 22nd postgraduate entrance examination pr
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 18](/img/1a/94ef8be5c06c2d1c52fc8ce7f03ea7.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 18
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 12](/img/b1/926d9b3d7ce9c5104f3e81974eef07.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 12

Decrypt the advantages of low code and unlock efficient application development
![[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 11](/img/6a/398d9cceecdd9d7c9c4613d8b5ca27.jpg)
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 11
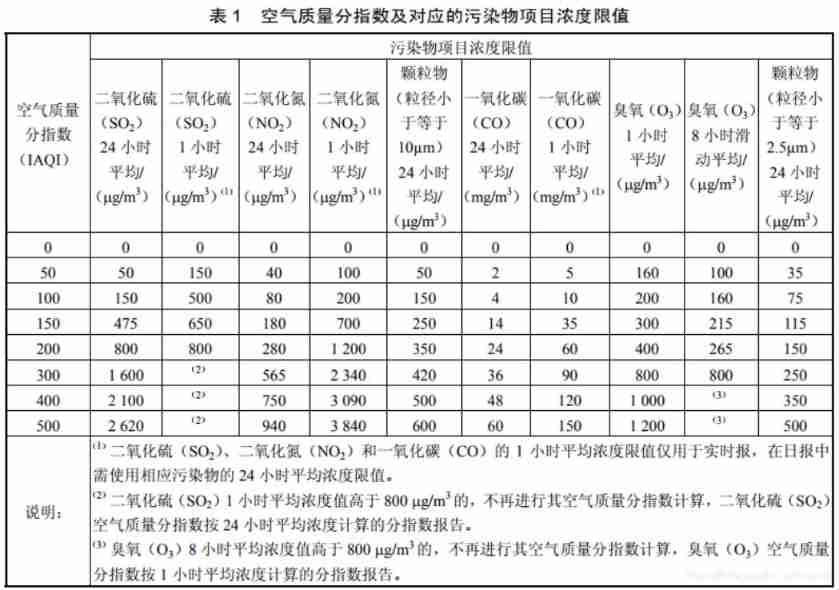
(August 9, 2021) example exercise of air quality index calculation (I)

The frost peel off the purple dragon scale, and the xiariba people will talk about database SQL optimization and the principle of indexing (primary / secondary / clustered / non clustered)
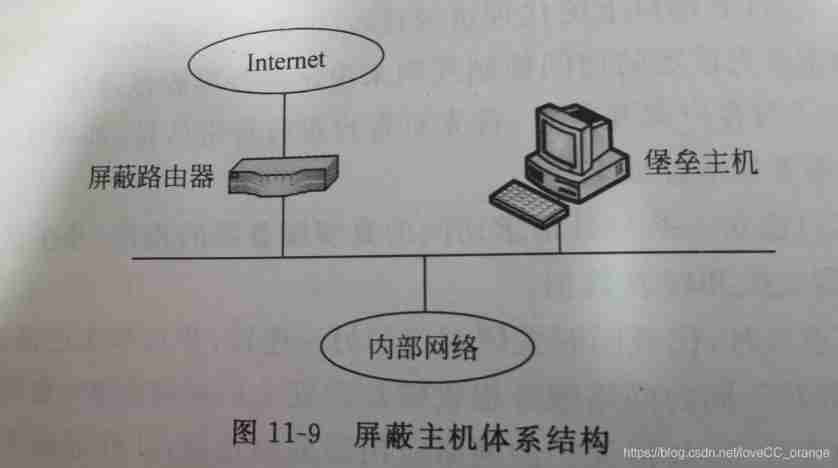
Summary of Shanghai Jiaotong University postgraduate entrance examination module firewall technology
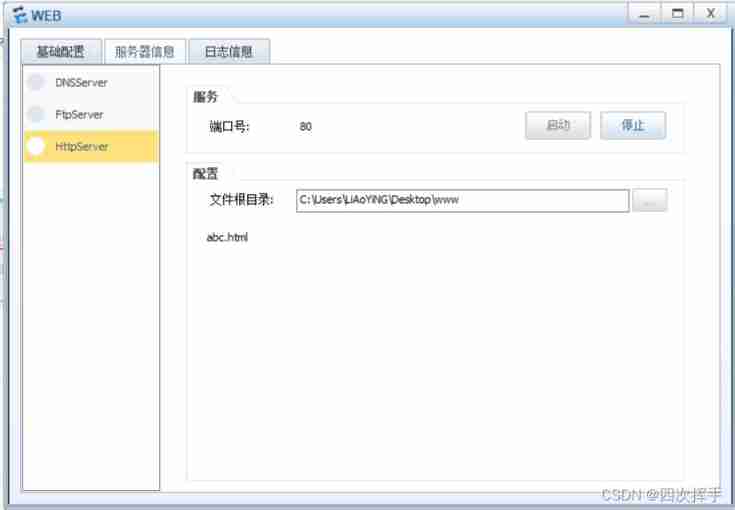
Day01 preliminary packet capture
随机推荐
The detailed installation process of Ninja security penetration system (Ninjitsu OS V3). Both old and new VM versions can be installed through personal testing, with download sources
IPv6 experiment
Detailed explanation of NPM installation and caching mechanism
Interview question MySQL transaction (TCL) isolation (four characteristics)
QQ get group link, QR code
Reptile learning 4 winter vacation learning series (1)
QQ get group information
Star leap plan | new projects are continuously being recruited! MSR Asia MSR Redmond joint research program invites you to apply!
[Yunju entrepreneurial foundation notes] Chapter II entrepreneur test 16
2021 annual summary - it seems that I have done everything except studying hard
Lvs+kept highly available cluster
[directory] search
'using an alias column in the where clause in PostgreSQL' - using an alias column in the where clause in PostgreSQL
Here, the DDS tutorial you want | first experience of fastdds - source code compilation & Installation & Testing
QQ get group member operation time
TCP fast retransmission sack mechanism
Single spa, Qiankun, Friday access practice
First knowledge of spark - 7000 words +15 diagrams, and learn the basic knowledge of spark
Googgle guava ImmutableCollections
Xshell's ssh server rejected the password, failed to skip publickey authentication, and did not register with the server