当前位置:网站首页>Reptile learning 3 (winter vacation learning)
Reptile learning 3 (winter vacation learning)
2022-07-04 11:20:00 【Kosisi】
Winter reptile practice
Preface : Learn something else in winter vacation to relax , Tired of writing papers !
Course : follow B Station school
Duration :20220209-20220212
1 Basic knowledge supplement
1.1 About web request
There are two kinds of websites
The first is the website rendered by the server , Directly connect the data to the server html Integrated , Unified return to browser ; That is to say, you can see the data in the page source code .
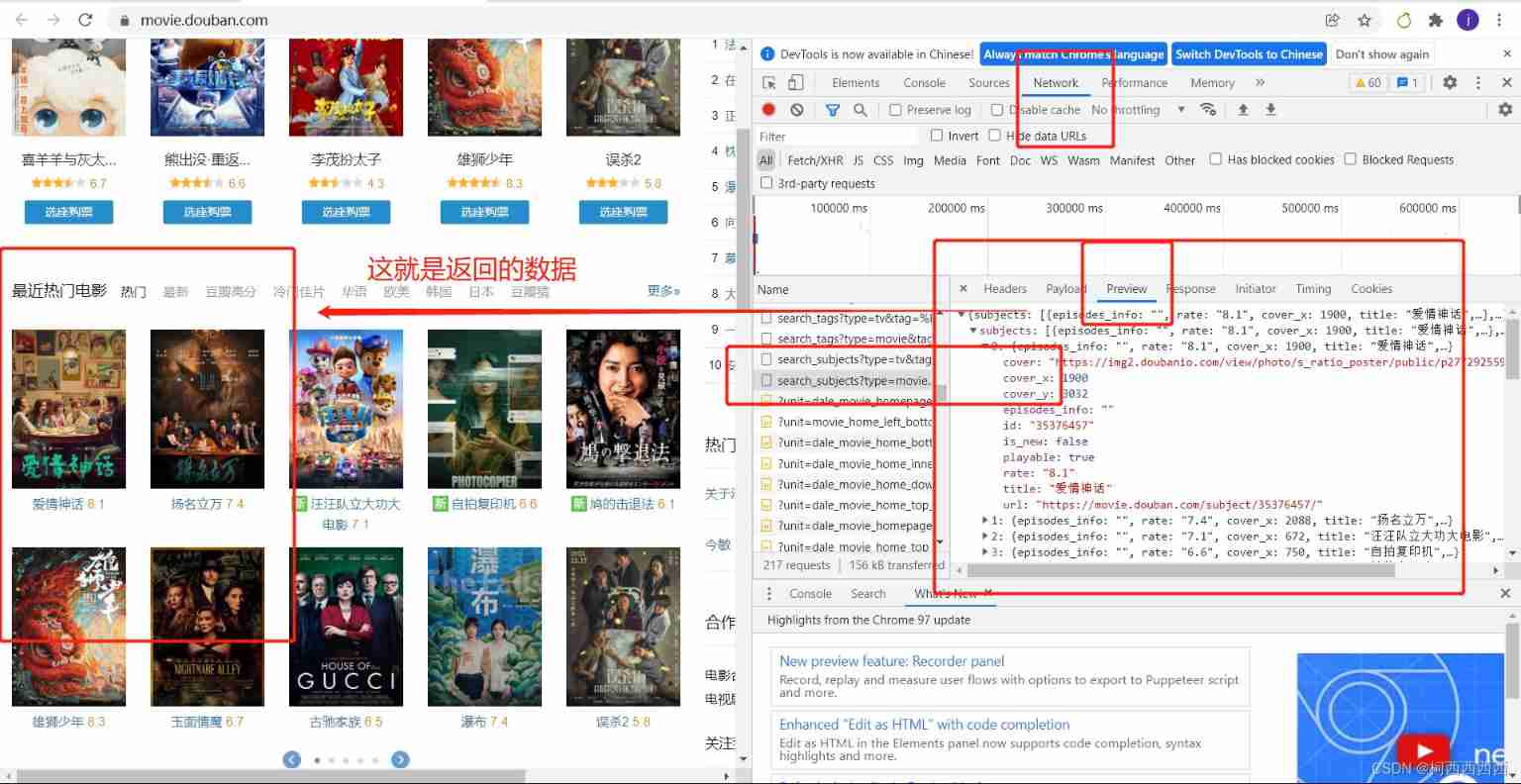
The second is the website rendered by the client , The first request returns a html skeleton , The second request for data , In the client, the skeleton and data are combined to show the data ; That is, you can't see the data in the page source code .
Proficient in using browser capture tools :
Enter the web page to check , Among them Network( Network working status ), After entering the website, all the resources you want to see will be displayed here .
notes : When looking for the returned data , Not necessarily the data is returned at one time , There may be a second request or other related operations .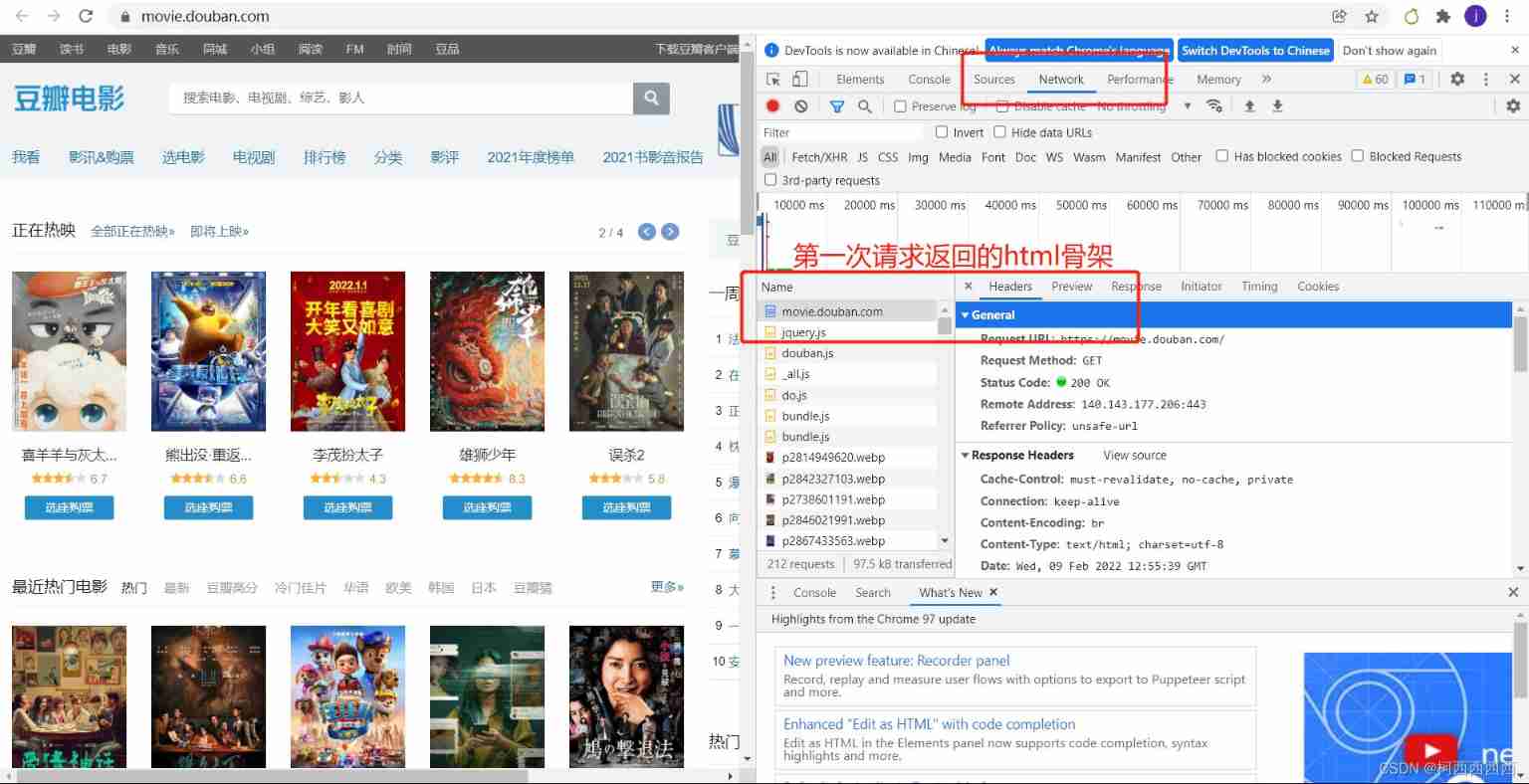
1.2 About HTTP agreement
agreement : The agreement that two computers abide by when transmitting data …
Anyway, the data between the browser and the server follows HTTP agreement ( Hypertext transfer protocol )
HTTP The protocol divides a message into three parts , Both request and response are three pieces of content
request :
Request line -> Request mode (get/post) request url Address agreement
Request header -> Put some additional information for the server to use
Request body -> Usually put some request parameters
Respond to :
Status line -> agreement Status code
Response head -> Put some additional information to be used by the client
Response body -> The content returned by the server to be used by the real client (HTML、json) etc.
Pay special attention to the request header and response header when writing crawlers , These two places generally contain some important contents ;
The status code of the response mainly indicates whether the request is successful :
200: The request is successful ;404: Page missing ;500: Server error ;302: The request is successful , But the required content corresponds to the new address , Is the redirection code .
Some of the most common important content in the request header ( Reptiles need ):
1.User-Agent: The identity of the request carrier ( What requests are sent with )
2.Referer: Anti theft chain ( Which page did the request come from ? Reverse climbing will use )
3.cookie: Local string data information ( User login information , Anti climbing token)
Some important content in the response header :
1.cookie: Local string data information ( User login information , Anti climbing token)
2. All kinds of magical and inexplicable strings ( It takes experience , It's usually token word , Prevent all kinds of attacks and anti climbing )
2 The simplest preparation of crawler
2.1 Search engine crawling continues
Search a thing randomly in Sogou's search engine , Take the search for Jay Chou as an example .
Sogou website
https://www.sogou.com/
Search the website after Jay Chou
https://www.sogou.com/web?query=%E5%91%A8%E6%9D%B0%E4%BC%A6&_asf=www.sogou.com&_ast=&w=01015002&p=40040108&ie=utf8&from=index-nologin&s_from=index&oq=&ri=0&sourceid=sugg&suguuid=&sut=0&sst0=1644417666055&lkt=0%2C0%2C0&sugsuv=1644416243719508&sugtime=1644417666055
This is to return a long string url Address , And this is what I mentioned earlier. According to experience, only the required parameters are left :
https://www.sogou.com/web?query= Jay Chou
Then try tentatively :
import requests
url = 'https://www.sogou.com/web?query= Jay Chou '
resp = requests.get(url)
print(resp.text)
The status code returned is 200, Indicates that the request was successful , But I don't see the required information in the output text , That is to say, there are problems in the previous article , The website has detected that it is using an automated program , Need to verify , Was intercepted .
At this time, the previous knowledge can be put to use , From the browser Network Get the request header , Masquerading as a browser access . The code is as follows :
import requests
url = 'https://www.sogou.com/web?query= Jay Chou '
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
resp = requests.get(url,headers=headers)
print(resp)
print(resp.text)
We can get the text content we need , But what we get is a pot of soup , If you need accurate information , We need to continue to deal with .
Similar to Baidu
2.2 Baidu translation website
Baidu translation website
https://fanyi.baidu.com/?aldtype=16047#auto/zh
Translate words february
Directly in Network Find the corresponding return data in , Return data directly from url obtain .
This example is different from the previous example , It uses POST Method ;
Tutorial code section :
import requests
url = 'https://fanyi.baidu.com/v2transapi'
q_1 = {
"query": "february"
}
resp = requests.post(url, data=q_1)
print(resp)
print(resp.json())
But there is an error when running according to the tutorial ,<Response [200]> {'errno': 997, 'errmsg': ' Unknown error ', 'query': 'february', 'from': 'en', 'to': 'zh', 'error': 997}
The website reported an error , I went to search , It seems to be caused by Baidu anti climbing nowadays . I can't give up. I directly search for Baidu translation content crawling that others can solve .
First of all, will Network Medium Form Data Parameters passed ( Ha, it should be the passed parameter ) All in the dictionary :
q_1 = {
"query": "february",
"from": "en",
"to": "zh",
"sign": "517702.198007",
"token": "2309e464003cab4c1b0598f8c279c074",
"simple_means_flag": "3",
"domain": "common"
}
2.3 Crawl the specific page of Douban
Specific page : douban -> The movie -> Movie charts -> Classified ranking -> comedy
Web address :https://movie.douban.com/typerank?type_name=%E5%96%9C%E5%89%A7&type=24&interval_id=100:90&action=
used url as follows , source :Network Select the corresponding file , among ? The next part is the submitted parameters , Extract the preceding paragraph , Parameters are listed separately , We can get what we need by modifying parameters .
url = https://movie.douban.com/typerank
Also disguised as a browser , Therefore, you need to copy the browser headers Medium user-agent, Otherwise, it will take python Crawl in the form of program , Will be anti crawled by the website ; When grammar is ok , No problem with parameters , technological process , The program framework is ok , You need to check whether it is anti - crawled by the website .
The code is as follows , Process as before :
import requests
url = "https://movie.douban.com/j/chart/top_list"
param = {
"type": 24,
"interval_id": "100:90",
"action": "",
"start": 0,
"limit": 60,
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36"
}
resp = requests.get(url, params=param, headers=headers)
print(resp.text)
Among them, modify parameters start and limit To determine the start and end of obtaining content .
There's one thing to note : At the end of the sentence resp.close() To close resp, In order to avoid being blocked by keeping in touch .
3 Data analysis
Three analytical methods :re analysis 、bs4 analysis 、xpath analysis
3.1 re analysis
Regular expressions and re The basic grammar of the module is detailed in the last note , Add a few :
1) Pay attention to distinguish one : Greedy matching and lazy matching , In the last note, the inert match was recorded as the minimum match , Inert matching is the most commonly used in our crawlers .
1 .* Greedy matching
2 .*? Inertia matching
2)re.s To make . Match all characters including line breaks
such as
import re
a = '''asdfhellopass: worldaf '''
b = re.findall('hello(.*?)world',a)
c = re.findall('hello(.*?)world',a,re.S)
print 'b is ' , b
print 'c is ' , c
Running results :
b is []
c is ['pass:\n\t123\n\t']
In regular expressions ,“.” Its function is to match division “\n” Any character other than , in other words , It's matching in one line . there “ That's ok ” In order to “\n” To make a distinction .a The string has one at the end of each line “\n”, But it's not visible .
If not used re.S Parameters , Match only within each line , If a line doesn't have , Just change the line and start over , Not across lines . While using re.S After the parameters , Regular expressions take this string as a whole , take “\n” Add to this string as a normal character , Match in the whole .
There are also similar functions :
| Modifier | describe |
|---|---|
| re.I | Make match match case insensitive |
| re.L | Do localization identification (locale-aware) matching |
| re.M | Multi-line matching , influence ^ and $ |
| re.S | send . Match all characters including line breaks |
| re.U | according to Unicode Character set parsing characters . This sign affects \w, \W, \b, \B. |
| re.X | This flag allows you to write regular expressions more easily by giving you a more flexible format . |
3)(?P< Group name > Regular ) The content of the corresponding name can be extracted from regular matching alone
import re
s = ''' <div class='jay'><span id='1'> Guo Qilin </span></div> <div class='jjj'><span id='2'> Ma Tianyu </span></div> <div class='hhh'><span id='3'> Guo Degang </span></div> <div class='yyy'><span id='4'> Yu Qian </span></div> <div class='gem'><span id='5'> Yue Yunpeng </span></div> '''
obj = re.compile(r"<div class='.*?'><span id='(?P<id>\d+)'>(?P<actor>.*?)</span></div>", re.S)
result = obj.finditer(s)
for it in result:
print(it.group('id'))
print(it.group('actor'))
Output is as follows :
1
Guo Qilin
2
Ma Tianyu
3
Guo Degang
4
Yu Qian
5
Yue Yunpeng
3.2 re Analyze the actual battle
3.2.1 Climb and take the bean petals Top 250 Ranking
Actual project : Climb and take the bean petals Top 250 Ranking
Web site address :https://movie.douban.com/top250
First, determine whether the required data is saved in the web page source code , Check the source code of the web page to make sure that the information is in the source code . The steps are to obtain the source code , Picking information through regular expressions , The code is as follows :
import re
import requests
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
resp = requests.get(url, headers=headers)
page_content = resp.text
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>',re.S)
result = obj.finditer(page_content)
for it in result:
print(it.group("name"))
This is only the name of the movie , If you want to rate the film director and actor , Then the corresponding regular expression is :
obj = re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>'
r'.*?<p class="">(?P<info>.*?)</p>'
r'.*? <span class="rating_num" property="v:average">(?P<rating>.*?)</span>', re.S)
3.2.2 Crawl to movie paradise information
Address :https://dytt89.com/
Mission : Crawling 2022 Must see all movie download links and movie titles in the hot movie column 、 actor 、 Ratings and other information 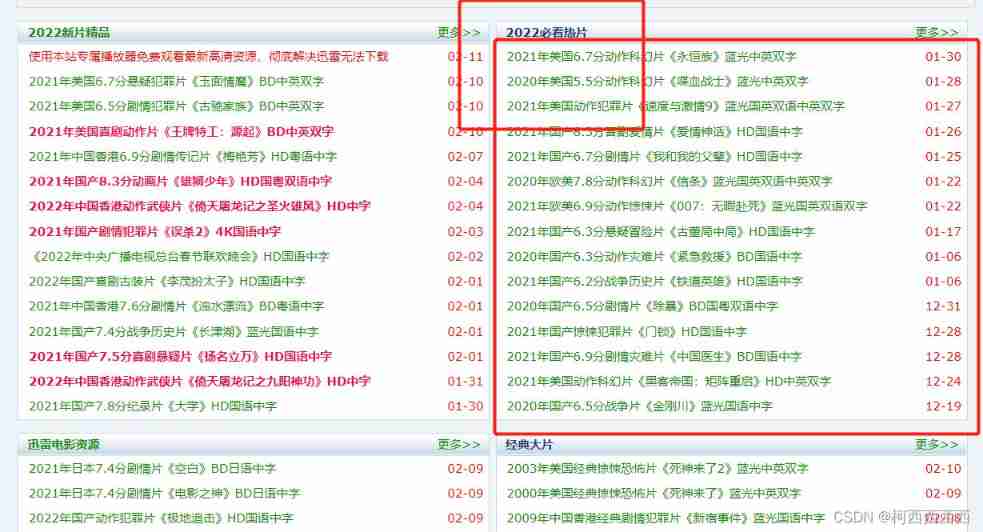
The steps are : The first step is to locate “2022 Must see hot film ” This column ; The second step , After positioning, extract the link address to the sub page ; The third step , Request the link address of the sub page , Get the information you need .
Don't read the tutorial first , Write a rough crawling program that can be realized by yourself , Can achieve , The code is as follows :
import requests
import re
url_main = "https://dytt89.com/"
resp = requests.get(url_main)
resp.encoding = 'gb2312'
# Get the homepage first ul Contents of Li
obj1 = re.compile(r"2022 Must see hot film .*?<ul>(?P<ul>.*?)</ul>", re.S)
result_1 = obj1.finditer(resp.text)
for it in result_1:
ul = it.group('ul')
# print(ul)
# from ul Choose what you need url
obj2 = re.compile(r"href='/(?P<url>.*?)' title", re.S)
href = obj2.finditer(ul)
for item in href:
# print(item.group("url"))
# Subpage url
url_son = url_main+item.group("url")
print(url_son)
# Visit the sub page address
resp2 = requests.get(url_son)
resp2.encoding = "gb2312"
# print(resp2.text)
# Pick out the regular expression of specific information ( Translated names , Original name , years )
obj3 = re.compile(r' translate name .(?P<name_trans>.*?)<br />◎ slice name (?P<name>.*?)<br />◎ year generation (?P<year>.*?)<br />', re.S)
result_2 = obj3.finditer(resp2.text)
for info in result_2:
print("--------------------------------------------")
print("name:", info.group("name"))
print("name_translation:", info.group("name_trans"))
print("years:", info.group("year"))
print("--------------------------------------------")
resp2.close()
resp.close()
I sort it out a little bit , It seems clear from the perspective of the partition function
import requests
import re
def request_url(url):
# Access the given url Webpage
# return text part
resp = requests.get(url)
resp.encoding = 'gb2312'
resp.close()
return resp.text
def get_url_son():
# Get sub pages url iterator
# The main page url
url_main = "https://dytt89.com/"
# To get the first url Required in ul Partial content
resptext_1 = request_url(url_main)
obj1 = re.compile(r"2022 Must see hot film .*?<ul>(?P<ul>.*?)</ul>", re.S)
result_1 = obj1.finditer(resptext_1)
for it in result_1:
ul = it.group('ul')
# print(it.group("ul"))
# from ul Choose what you need url
obj2 = re.compile(r"href='/(?P<url>.*?)' title", re.S)
href = obj2.finditer(ul)
return href
def get_info():
# Get the required information from the sub page
url_main = "https://dytt89.com/"
href = get_url_son()
for it in href:
url_son = url_main + it.group("url")
print(url_son)
# Visit the sub page address
resptext_2 = request_url(url_son)
# Regular expressions to get specific information
obj3 = re.compile(r' translate name .(?P<name_trans>.*?)<br />◎ slice name (?P<name>.*?)<br />◎ year generation (?P<year>.*?)<br />', re.S)
result_2 = obj3.finditer(resptext_2)
for info in result_2:
print("name:", info.group("name"))
print("name_translation:", info.group("name_trans"))
print("years:", info.group("year"))
print("--------------------------------------------")
if __name__ == '__main__':
get_info()
summary : I think this is fun , And in the initial stage of learning, regular expressions are completely sufficient . The difficulty lies in how to quickly select the best writing method of regular expressions .
3.3 bs4 Resolving instances
3.3.1 Instance of a : Movie Paradise movie information
Practice for a while bs4, Review the grammar , See the previous note for details . Follow the tutorial first :
The target site :http://www.xinfadi.com.cn/priceDetail.html
The website has been recently revised , The data is not in the source code , The website is also different , But everything is the same , I won't know anything like the last note .
As in the previous examples , Grab the bag to get url, Find target data file , And then use re analysis . Hey, No , So I don't have to practice bs4 Yes , Can't the client render work bs4, I looked at several returned data files , At least I haven't met it yet bs4 Parse the returned data file , After all, the return is not html Tag language . And obviously it's simple to use regular . I'll find one that can be used bs4 Parsed website .
There is a point of knowledge : For example, an attribute to be found is class=“hq_table”, stay find() Function , But in python in class Is the key word , So write directly
demo.find("table",class="hq_table")Will report a mistake , however find() Function gives the solution , Is in the class Underline and writedemo.find("table",class_="hq_table")Can solve , Or usedemo.find("table",attrs={"class": "hq_table"}).
The last website was rendered by the server , The information is in the page source code , Then crawl to the movie paradise website
Target website :https://dytt89.com/
Crawling content : Contents displayed in eight columns , Do not enter specific websites . Yes 2022 New film boutique 2022 Must see hot film, etc .
Write nonsense , Anyway, in the end, I output what I want , I have achieved my goal . The judgment sentence in this is mainly used to eliminate the irregular things of this website , After all, it's a pirated website , I didn't expect that even the webpage was written irregularly . Like , But the column name , But some use span label , Some use a label ; There is also a thunderbolt advertisement inserted halfway ; Can only rely on if Statement excluded . will , I almost want to use regular expressions halfway , But with practice bs4 At first , I still wrote down .
import requests
from bs4 import BeautifulSoup
import bs4
url = 'https://dytt89.com/'
# visit url
resp = requests.get(url)
resp.encoding = 'gb2312'
# print(resp.text)
page = BeautifulSoup(resp.text, "html.parser")
# Grab the target div label
for div_aim in page.find_all("div", attrs={
"class": "co_area2"}):
# Remove other information of non label classes of other nodes , Like strings
if isinstance(div_aim, bs4.element.Tag):
# Choose one of them a label
a_content = div_aim('a')
# Get the title of each column
# Get the content marked by the label text
title = div_aim('span')[0].text
print(title)
# Get the corresponding links for each column
title_href = div_aim.find_all('a')[0].attrs
if 'www' not in title_href['href']:
title_url = 'https://dytt89.com'+title_href['href']
else:
title_url = title_href['href']
# print(type(title_href))
# print(title_href['href'])
print(title_url)
# First the a Output the content in the tag
for li in div_aim.find_all('li'):
if ' This station ' not in li.text:
print(li.text)
# lookup li In the tag a label
# Then look for a The attribute value of the tag is output as a dictionary
# Pass key href Output
mid_href = li('a')[0].attrs['href']
movie_url = 'https://dytt89.com'+mid_href
print(movie_url)
3.3.2 Real column II : Crawling pictures
I didn't expect an example to follow , good heavens , It turns out that the above is the basic use of the Library . And the original example of reptile is really to teach crawling to take pictures of little sister ? The stem that cannot pass .
Instance target : The main page of aesthetic wallpaper enters the sub page of each picture , Get big HD pictures .
Instance target URL :https://www.umeitu.com/bizhitupian/weimeibizhi/
The idea is to get the source code of the page , Extract the title of the picture , The address of the picture sub page ; Find the download link in the sub page .
import requests
from bs4 import BeautifulSoup
import time
main_url = 'https://www.umeitu.com/bizhitupian/weimeibizhi/'
main_resp = requests.get(main_url)
main_resp.encoding = main_resp.apparent_encoding
main_resp.close()
# print(main_resp.text)
main_page = BeautifulSoup(main_resp.text, 'html.parser')
# Target tag a
# # Law two
# for a in main_page.find('div', class_="TypeList").find_all('a'):
# print(a.get('href'))
for a_aim in main_page.find_all('a', attrs={
'class': "TypeBigPics"}):
# Output picture Title
print(a_aim.text)
# The link corresponding to the picture
img_url = 'https://www.umeitu.com' + a_aim.attrs['href']
print(img_url)
# Visit the picture link
img_resp = requests.get(img_url)
img_resp.encoding = img_resp.apparent_encoding
img_resp.close()
# print(img_resp.text)
# Get from the sub page img label , That is, the corresponding picture download link
img_page = BeautifulSoup(img_resp.text, 'html.parser')
div_aim_child = img_page.find('div', class_="ImageBody")
img_aim_child = div_aim_child.find('img')
cite = img_aim_child.get('src')
print(cite)
# Download the pictures
img_resp = requests.get(cite)
# img_resp.content Got bytes
img_name = a_aim.text+'.jpg'
with open(img_name, mode='wb') as f:
f.write(img_resp.content)
print('over!')
# Prevent access too often ,IP Be banned
time.sleep(1)
3.4 Xpath analysis
3.4.1 grammar
The tutorial is simpler than the other two 、 Efficient
xpath Is in XML file (HTML yes XML A subset of ) A language for searching content in
Search according to node labels and node relationships
Get ready : install lxml modular
1、/ Represents a hierarchical relationship , first / Root node
Such as :result = tree.xpath("/book") Indicates that the root node is retrieved
If you want to get the content of the root node, the format is as follows :result = tree.xpath("/book/text()")
2、// Represents the descendant node
For example, the next node is name, Access the content result = tree.xpath("/book/name/text()
To visit book All the descendants of the node after the node nick Content of node :result = tree.xpath("/book//nick/text()
1)// Element tag name
for example : //div, Find all in the page div
2)// Element tag name [@ Property name =‘ The specific content ’]
for example : //div[@class='box'], lookup class by box Of div
3)// Element tag name [ The first i individual ]
for example : //div[@class='box'][2], Find the qualified number 2 individual div
4)// Elements 1/ Elements 2/ Elements 3…
for example : //ul/li/div/a/img, lookup ul Under the li Under the div Under the a Under the img label
5)// Elements 1/@ Property name
for example ://ul/li/div/a/img/@src, lookup ul Under the li Under the div Under the a Under the img Labeled src attribute
6)// Elements //text()
for example ://div[@class='box']//text(), obtain class by div All text under
3、* Represents any node , As a wildcard .
‘//*[@ attribute =' value ']
for example ://*[@name='lisi'] Find all name by lisi The elements of
4、[contain(@ Property name ,‘ Related property values ’)]
// Elements [contains(@ Property name ,‘ Related property values ’)]
for example ://div[contains(@class,'zhangsan')] lookup class Contained in the zhangsan Of div
5、 Positioning mode
- adopt ID location ,
//*[@id='kw'] - adopt Class location ,
//*[@class='class_name'] - adopt Name location ,
//*[@name='name'] - Attribute positioning function , @ Represents positioning by attributes , It can be followed by any attribute in the label ,
//*[@other='attribute'] - When the attributes of the tag are repeated , You can filter through tags , take * Replace with tag name , Then you can filter according to the label ,
//input[@placeholder=' user name '] - When the label repeats , You can filter by level , namely ‘/’ Step by step ; If the hierarchy is repeated , It can be located through the attributes of a single level , Such as
//form/div[@class='login-user']/input - If the labels of sibling elements are the same , It can be filtered by index .
//select[@name='city'][1]/option[1], notes :xpath Index from 1 Start . - Logic operation positioning ,and or or
adopt and To narrow the scope of filtration , Only when the conditions are met can we locate ,//select[@name='city' and @size='4' and @multiple="multiple"];or On the contrary , As long as these filters , One of them appeared so long that it matched ,//select[@name='city' or @size='4']
3.4.2 Basic usage
Tips : In the face of such a large website , complex html, It's complicated to find the information tag you want , You can check through the browser , After finding the label , Can be in element in copy choice xpth copy You can directly copy xpath In the form of .
Common grammatical framework :
from lxml import etree
# etree Can be loaded directly html file
tree = etree.parser("xxx.html")
li_list = tree.xpath("/html/body/ol/li")
for li in li_list:
# From every one li We have extracted a The text message of the label
# . Simply means starting from the current node , Relative search
result_1 = li.xpath("./a/text()")
# obtain a In the tag href Property value
result_2 = li.xpath("./a/@href")
# Or use the following method directly , no need for loop
result_3 = tree.xpath("/html/boby/ol/li/a/@href")
3.4.3 actual combat
Website :https://beijing.zbj.com/search/f/?kw=saas
The goal is : Search for saas service , Then get the information of the service provider
technological process : Get the page source code ; Extract and parse data ; The extraction method is carried out according to the service providers one by one , Here's the picture , It is divided into 1 2 3 In turn .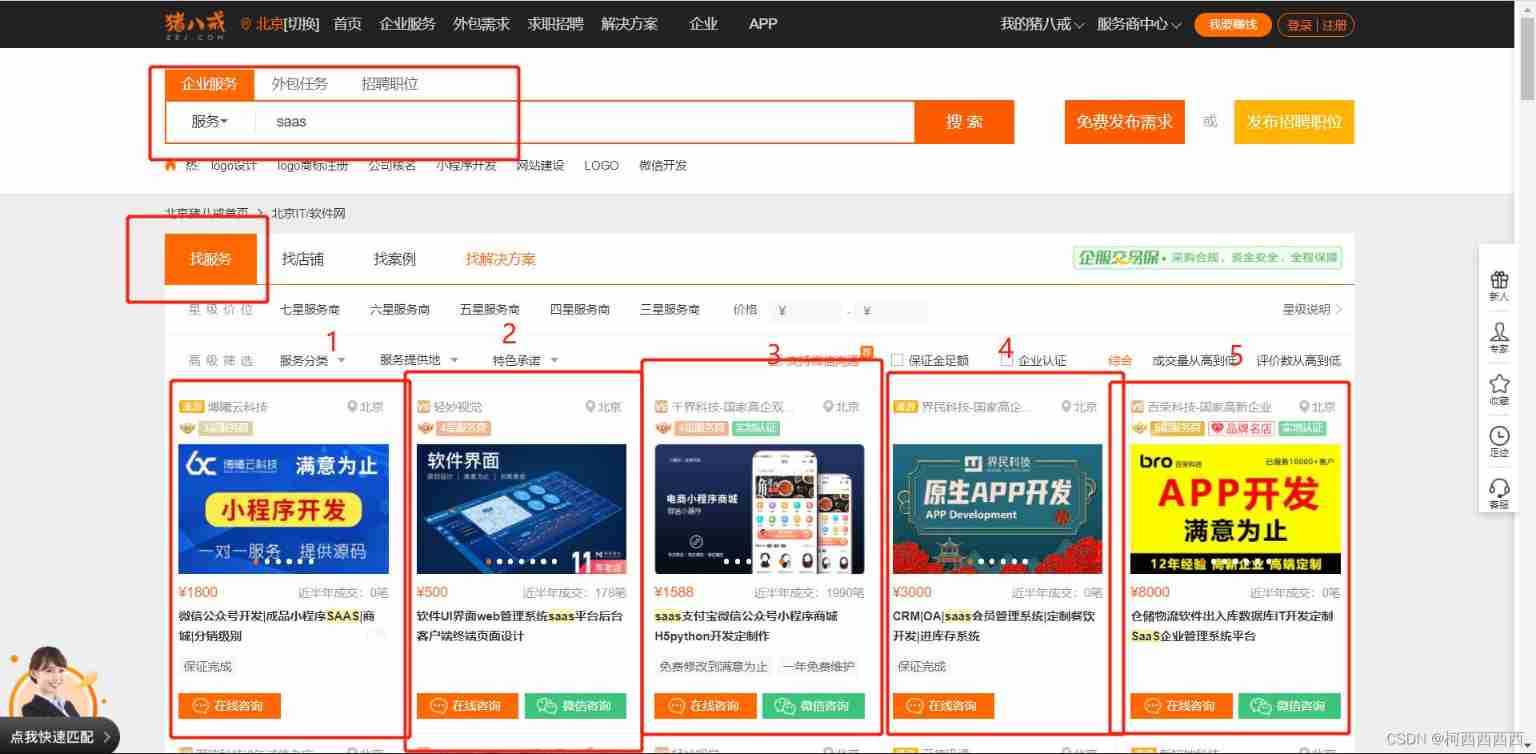
# Crawl the information of zhubajie.com
import requests
from lxml import etree
url = "https://beijing.zbj.com/search/f/?kw=saas"
resp = requests.get(url)
resp.close()
# print(resp.text)
# analysis
html = etree.HTML(resp.text)
# Get on behalf of all service providers div Label part
divs_commercial = html.xpath("/html/body/div[6]/div/div/div[2]/div[5]/div[1]/div")
# print(divs_commercial)
for div in divs_commercial: # For each div retrieval , Information of each service provider
name = div.xpath("./div/div/a[1]/div[1]/p/text()")
address = div.xpath("./div/div/a[1]/div[1]/div/span/text()")
price = div.xpath("./div/div/a[2]/div[2]/div[1]/span[1]/text()")
amount = div.xpath("./div/div/a[2]/div[2]/div[1]/span[2]/text()")
title = "saas".join(div.xpath("./div/div/a[2]/div[2]/div[2]/p/text()"))
# level = div.xpath("./div/div/a[1]/div[2]/span/i/text()")
print("name:", name[1].strip("\n"))
print("title:", title)
print("price:", price[0].strip("¥"))
print("amount:", amount[0])
print("address:", address[0])
# print("level:", level)
print("------------------------------------------------")
边栏推荐
- JMeter Foundation
- Local MySQL forget password modification method (Windows) [easy to understand]
- SQL greatest() function instance detailed example
- Login operation (for user name and password)
- Canoe - the third simulation project - bus simulation - 2 function introduction, network topology
- Dos and path
- Configure SSH certificate login
- XMIND installation
- re. Sub() usage
- Xiaobing · beauty appraisal
猜你喜欢
Installation of ES plug-in in Google browser
Summary of collection: (to be updated)
Elevator dispatching (pairing project) ②
Elevator dispatching (pairing project) ④

OSI seven layer reference model
20 kinds of hardware engineers must be aware of basic components | the latest update to 8.13
Elevator dispatching (pairing project) ③
2021 annual summary - it seems that I have done everything except studying hard
Simple understanding of seesion, cookies, tokens
Serialization oriented - pickle library, JSON Library
随机推荐
R built in data set
JMeter assembly point technology and logic controller
IO stream ----- open
3W word will help you master the C language as soon as you get started - the latest update is up to 5.22
Usage of case when then else end statement
Unittest+airtest+beatiulreport combine the three to make a beautiful test report
Regular expression
Object. Assign () & JS (= >) arrow function & foreach () function
Fundamentals of software testing
JMeter common configuration components and parameterization
Take advantage of the world's sleeping gap to improve and surpass yourself -- get up early
Elevator dispatching (pairing project) ④
2021 annual summary - it seems that I have done everything except studying hard
Iptables cause heartbeat brain fissure
2020 Summary - Magic year, magic me
本地Mysql忘记密码的修改方法(windows)
LxC shared directory permission configuration
Data transmission in the network
Lvs+kept realizes four layers of load and high availability
Iterator generators and modules