当前位置:网站首页>Redis high availability principle
Redis high availability principle
2022-07-01 15:25:00 【Louzai】

Hello everyone , I'm Lou Zi !
Redis High availability , It's too important ! Previous job interviews , The frequency of this question interview can be ranked in the top , Especially some big factories , Don't worry about reading the article first , If the interviewer asks you such a question , How would you answer , You can think first 5 minute .
Wait here 5 minute ...
In fact, I can also steal a lazy , Completely reprint other blogs , But I didn't find what I wanted , In order to live up to the fans , Brother Lou still writes a separate article for you , Mainly based on this knowledge , Combined with some previous interviews , Talk to everyone .
1. Redis Fragmentation strategy
1.1 Hash Fragmentation
We all know , about Redis colony , We need to pass hash Strategy , take key Play in Redis On different pieces of .
If we have 3 Taiwan machine , The common slicing method is hash(IP)%3, among 3 Is the total number of machines .

At present, many small companies play like this , Quick start , Simple and crude , But this approach has a fatal drawback : When increasing or decreasing cache nodes , The total number of nodes changes , Cause the slice value to change , The cached data needs to be migrated .
Then how to solve the problem , The answer is consistency Hash.
1.2 Uniformity Hash
The consistent hash algorithm is 1997 A distributed hash implementation algorithm proposed by MIT in .
Annular space : According to the usual hash The algorithm will correspond to key Hash to one with 2^32 In the space of the next bucket , namely 0~(2^32)-1 In the digital space , Now we can connect these numbers head to tail , Think of it as a closed ring .

Key hash Hash Ring : Now we will object1、object2、object3、object4 Four objects pass through a specific Hash The function calculates the corresponding key value , Then hash to Hash On the ring .
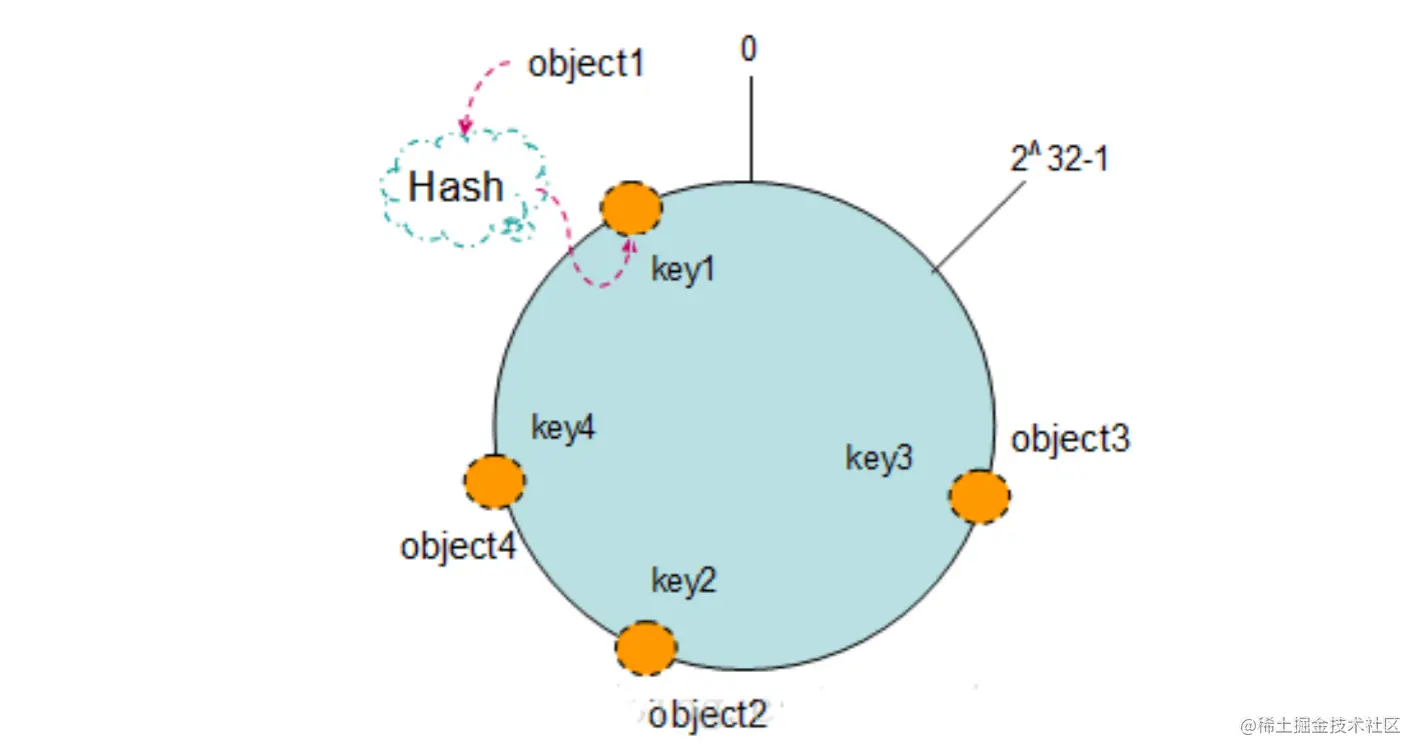
Machine hash Hash Ring : Suppose there are now NODE1、NODE2、NODE3 Three machines , Calculate in a clockwise direction , Store all objects in the nearest machine ,object1 It's stored in NODE1,object3 It's stored in NODE2,object2、object4 It's stored in NODE3.

The node to delete : If NODE2 The fault has been removed ,object3 Will be moved to NODE3 in , It's just object3 The mapping location of has changed , There are no changes to other objects .

Add a node : If you add a new node to the cluster NODE4,object2 Was moved to NODE4 in , Other objects remain unchanged .

Through the analysis of adding and deleting nodes , The consistency hash algorithm keeps monotonicity at the same time , It also minimizes data migration , This algorithm is very suitable for distributed cluster , Avoid a lot of data migration , Reduce the pressure on the server .
If the number of machines is too small , In order to avoid a large amount of data concentrated on several machines , Achieve balance , Virtual nodes can be established ( For example, a machine builds 3-4 Virtual nodes ), Then the virtual nodes are Hash.
2. High availability solution
A lot of times , The company only provides us with one set of Redis colony , As for how to calculate the partition , We usually have 2 A set of mature solutions .
Client solution : That is, the client calculates itself Redis Fragmentation , Whether you use Hash Fragmentation , Or consistency Hash, It's all done by the client itself .
The client scheme is simple and crude , But it can only be reused between single language systems , If you're using PHP The system of , later Java Also need to use , You need to use Java Rewrite a set of slicing logic .
In order to solve the problem of multilingualism 、 The reuse of different platforms , The intermediate agent layer scheme is derived .
Intermediate agent layer scheme : Migrate the experience of client solutions to the agent layer , Through a common protocol ( Such as Redis agreement ) To implement reuse in other languages , Users do not need to care about how to achieve high availability of cache , Just rely on your agent layer .
The agent layer is mainly responsible for the routing function of read-write requests , And built in some highly available logic .

You can have a look , Your company's Redis What kind of scheme is used ? about “ Client solution ”, In fact, some don't have to write by themselves , For example, responsible for maintenance Redis Our department will provide different languages SDK, You just need to integrate the corresponding SDK that will do .
3. High availability principle
3.1 Redis Master-slave
Redis Basically passed “ Lord - from ” Pattern to deploy , The master and slave libraries are separated by reading and writing .

Same as MySQL similar , The main library supports writing and reading , Reading from the library is only supported , The data will be written to the main database first , Then synchronize it to the slave library regularly , Specific synchronization rules , Main RDB Logs are synchronized from the master database to the slave database , And then read it from the library RDB journal , It's a little bit more complicated here , It also involves replication buffer, It doesn't unfold anymore .
Here's the problem , During one synchronization , The main library needs to be completed 2 Time consuming operations : Generate RDB File and transfer RDB file .
If the number of slave libraries is too large , The main library is busy fock Child process generation RDB File and data synchronization , It will block the normal request of the main database .
How to solve this problem ? The answer is “ Lord - from - from ” Pattern .
In order to avoid all slave libraries being synchronized from the master RDB journal , You can complete synchronization with the help of slave Library : For example, adding 3、4 Two Slave, Sure etc. Slave 2 After synchronization , Re pass Slave 2 Sync to Slave 3 and Slave 4.

If I were the interviewer , I may continue to ask , If the data is synchronized 80%, The network broke down suddenly , When the network is subsequently restored ,Redis How will it operate ?
3.2 Redis Fragmentation
This is a bit like MySQL Sub database and sub table , Store data in different places , Avoid concentrating all queries on one instance .

In fact, there is another advantage , That is, when data is synchronized between master and slave , If RDB Too much data , Will block the main thread seriously , If you use the way of slices , Data can be allocated , For example, there were 10 GB The data of , After apportionment , Each slice has only 2 GB.
Maybe some students will ask ,Redis Fragmentation , and “ Lord - from ” What does the pattern matter ? You can understand , Each fragment in the figure is the main library , Each piece has its own “ Lord - from ” Pattern structure .
So how can the data find the corresponding fragment , As I have said before , If we have 3 Taiwan machine , The common slicing method is hash(IP)%3, among 3 Is the total number of machines ,hash Value is machine IP, In this way, each machine has its own slice number .
about key, In the same way , Find the corresponding machine partition number hash(key)%3,hash There are many algorithms , It can be used CRC16(key), You can also take key The characters in , adopt ASCII Convert codes into numbers .
3.3 Redis Sentinel mechanism
3.3.1 What is the sentinel mechanism ?
In master-slave mode , If master It's down. , The slave cannot synchronize data from the master , The main library cannot provide read and write functions .

What shall I do? ? At this time, we need to introduce the sentinel mechanism !
Sentinel nodes are special Redis service , No read-write service , It's mainly used to monitor Redis Instance node .

So when master Downtime , How do sentinels perform ?
3.3.2 Judge whether the host is offline
The sentinel process will use PING The command detects itself and the master 、 Network connection of slave library , Used to determine the state of an instance , If the sentry finds the master or slave library to PING The response to the command timed out , The sentinel will mark it as “ Subjective offline ”.
Is that a sentinel's judgment “ Subjective offline ”, Just go offline master Well ?
The answer must be No , Need to follow “ The minority is subordinate to the majority ” principle : Yes N/2+1 An instance determines the main database “ Subjective offline ”, Before deciding that the main database is “ Objective offline ”.

For example, the picture above has 3 A sentinel , Yes 2 A judgment “ Subjective offline ”, Then mark the main library as “ Objective offline ”.
3.3.3 Select a new master library
We have 5 A slave , You need to select an optimal slave library as the master library , branch 2 Step :
- Screening : Check the current online status and previous network connection status of the slave Library , Filter unsuitable slave libraries ;
- Scoring : According to the slave priority 、 Score with the data synchronization proximity of the old main database , Choose the highest score as the main database .

What if the scores are consistent ? Redis There is also a strategy :ID The one with the smallest number gets the highest score from the library , Will be selected as the new master library .
When slave 3 After being elected as the new master database , Other slave libraries and clients will be notified , Announce that you are the new master database , Everyone has to listen to me !
So much for today , See you next time , Did everyone learn to waste ?
「 Exchange of learning 」
Focus on 「 Louzai 」 official account .
边栏推荐
- What is the relationship between network speed, broadband, bandwidth and traffic?
- skywalking 6.4 分布式链路跟踪 使用笔记
- cmake 基本使用过程
- Opencv learning notes 5 -- document scanning +ocr character recognition
- 雷神科技冲刺北交所,拟募集资金5.4亿元
- Wechat official account subscription message Wx open subscribe implementation and pit closure guide
- Zhang Chi Consulting: household appliance enterprises use Six Sigma projects to reduce customers' unreasonable return cases
- Opencv Learning Notes 6 -- image mosaic
- Solid basic basic grammar and definition function
- 【ROS进阶篇】第五讲 ROS中的TF坐标变换
猜你喜欢

Skywalking 6.4 distributed link tracking usage notes

智能运维实战:银行业务流程及单笔交易追踪

MySQL service is starting. MySQL service cannot be started. Solution

微信网页订阅消息实现

Phpcms background upload picture button cannot be clicked

Qt+pcl Chapter 9 point cloud reconstruction Series 2

张驰咨询:家电企业用六西格玛项目减少客户非合理退货案例

Wechat official account subscription message Wx open subscribe implementation and pit closure guide

【目标跟踪】|STARK

Task. Run(), Task. Factory. Analysis of behavior inconsistency between startnew() and new task()
随机推荐
DirectX repair tool v4.1 public beta! [easy to understand]
Flink 系例 之 TableAPI & SQL 与 MYSQL 数据查询
《性能之巅第2版》阅读笔记(五)--file-system监测
厦门灌口镇田头村特色农产品 甜头村特色农产品蚂蚁新村7.1答案
Lean Six Sigma project counseling: centralized counseling and point-to-point counseling
These three online PS tools should be tried
openssl客户端编程:一个不起眼的函数导致的SSL会话失败问题
Qt+pcl Chapter 6 point cloud registration ICP series 4
An intrusion detection model
Beilianzhuguan joined the dragon lizard community to jointly promote carbon neutralization
leetcode:329. 矩阵中的最长递增路径
如何实现时钟信号分频?
贝联珠贯加入龙蜥社区,共同促进碳中和
Filter & (login interception)
Apk signature principle
Qt+pcl Chapter 9 point cloud reconstruction Series 2
MySQL 服务正在启动 MySQL 服务无法启动解决途径
A unifying review of deep and shallow anomaly detection
《QT+PCL第六章》点云配准icp系列6
Recommendation of data acquisition tools and detailed graphic process of data acquisition list