当前位置:网站首页>RoBERTa:A Robustly Optimized BERT Pretraining Approach
RoBERTa:A Robustly Optimized BERT Pretraining Approach
2022-07-29 07:31:00 【Live up to your youth】
Model overview
RoBERTa It can be seen as BERT Of Improved version , In terms of model structure , comparison BERT,RoBERTa There is basically no innovation , It's more about BERT Further exploration in pre training . It improves BERT Many pre training strategies , The result shows that , original BERT Maybe not enough training , Not fully learning the language knowledge in the training data .
RoBERTa At model scale 、 Computational power and data , And BERT Compared with the following improvements :
Bigger bacth size.RoBERTa In the training process, a larger bacth size. Tried from 256 To 8000 No wait bacth size.
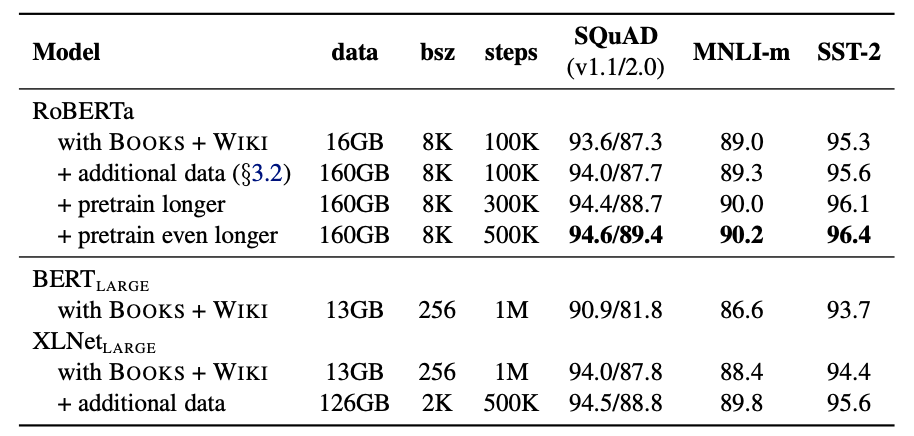
More training data .RoBERTa Adopted 160G Training text for , and BERT Only 16G Training text for .
Longer training steps .RoBERT stay 160G Training data 、8K Of batch size The training steps are as high as 500K.
RoBERTa Compare the training methods BERT Improvements include : Remove the next prediction (NSP) Mission ; Use dynamic mask ; use BPE Encoding mode .
To sum up , Let me draw a picture :
Model optimization
Use dynamic mask
BERT There was a Masking Language Model(MLM) Pretraining task , When preparing training data , need Mask Drop some token, Let the model predict these during the training token, Here is the data Mask after , The training data will not change , These data will be used until the end of the training , such Mask The method is called Static Masking.
If during training , Expect the training data of each round ,Mask The position of also changes accordingly , This is it. Dynamic Masking,RoBERTa What you use is Dynamic Masking.
stay RoBERTa in , This is how it is implemented , Copy multiple copies of the original training data , Then proceed Masking. In this way, the same data is randomly Masking The position of has also changed , Equivalent to Dynamic Masking Purpose . For example, the original data has been copied 10 Copy of the data , Training is needed in total 40 round , Then each mask The method of will be used in training 4 Time .
Cancel NSP Mission , Use FULL-SENTENCES How to construct data
BERT In the construction data NSP This is what you do when you are working , Put two segment Splice as a series of sequence input model , And then use NSP The task is to predict these two segment Whether there is a context relationship , But the overall length of the sequence is less than 512.
However ,RoBERTa It is found through experiments that , Get rid of NSP The task will be improved down-stream Task indicators . As shown in the figure :
among ,SEGMENT-PAIR、SENTENCE-PAIR、FULL-SENTENCES、DOC-SENTENCE Respectively represent different ways of constructing input data ,RoBERTa Used FULL-SENTENCES, And removed NSP Mission .
FULL-SENTENCES It means to extract sentences continuously from one or more articles , Fill in the model input sequence . in other words , An input sequence may span multiple article boundaries . In particular , It will continuously extract sentences from an article to fill the input sequence , But if it comes to the end of the article , Then we will continue to extract sentences from the next article and fill them in the sequence , The content in different articles is still in accordance with SEP Separator to split .
use BPE code
Byte-Pair Encodeing(BPE) It is a kind of word , How to generate a vocabulary .BERT Medium BPE The algorithm is character based BPE Algorithm , Constructed by it ” word ” Often between characters and words , The common form is the fragment in the word as an independent ” word ”, Especially for those longer words . For example, words woderful It may be split into two sub words ”wonder” and ”ful”.
differ BERT,RoBERTa Based on Byte Of BPE, The vocabulary contains 50K Left and right words , In this way, there is no need to worry about the appearance of unlisted words , Because it will start from Byte To decompose words at the level of .
Bigger data
comparison BERT, RoBERTa Using more training data :

Longer training steps
RoBERTa With the increase of training data and training steps , Model in down-stream Our performance is also improving .
Bigger batch size
RoBERTa By increasing the training process Batch Size Size , Come and watch the model in the pre training task and down-stream Mission performance . Found an increase in Batch Size It is beneficial to reduce the number of reserved training data Perplexity, Improve down-stream Indicators of .

in addition ,RoBERTa Reference resources transformer Improvement , Use β 1 \beta_1 β1=0.9, β 2 \beta_2 β2=0.999, ϵ \epsilon ϵ=1e-6,weight_decay_rate=0.01,num_warmup_steps=10000,init_lr=1e-4 Adaptive learning rate Adam Optimizer .

边栏推荐
- Reflect reflect
- 我想问一下,我flink作业是以upsert-kafka的方式写入数据的,但是我在mysql里面去更
- 【暑期每日一题】洛谷 P1601 A+B Problem(高精)
- 基于高阶无六环的LDPC最小和译码matlab仿真
- BeanUtils.setProperty()
- QT basic day 2 (2) QT basic components: button class, layout class, output class, input class, container and other individual examples
- 【MYSQL】-【子查询】
- Full process flow of CMOS chip manufacturing
- Description of rollingfileappender attribute in logback
- Meta configuration item of route
猜你喜欢

多线程购物

新生代公链再攻「不可能三角」
Scala 高阶(九):Scala中的模式匹配

Round avatar of user list and follow small blocks
Scala 高阶(十):Scala中的异常处理

Female graduate students do "mind mapping" and quarrel with their boyfriend! Netizen: the "king of infighting" in the quarrel

利用C语言巧妙实现棋类游戏——三子棋
![[MySQL] - [subquery]](/img/81/0880f798f0f41724fd485ae82d142d.png)
[MySQL] - [subquery]

3-全局异常处理

leetcode力扣经典问题——4.寻找两个正序数组的中位数

随机推荐
【暑期每日一题】洛谷 P7760 [COCI2016-2017#5] Tuna
写点dp
【Unity实战100例】Unity万能答题系统之单选多选判断题全部通用
Log4qt memory leak, use of heob memory detection tool
梳理市面上的2大NFT定价范式和4种解决方案
状态机dp三维
thinkphp6 实现数据库备份
MySQL如何把行转换为列?
零数科技深度参与信通院隐私计算金融场景标准制定
I'd like to ask, my flick job writes data in the way of upsert Kafka, but I'm more careful in MySQL
How to use GS_ Expansion expansion node
5-整合swagger2
小D的刺绣
Pat class a 1146 topology sequence
What is the function of fileappender in logback?
A long article --- in-depth understanding of synchronized
[summer daily question] Luogu p4413 [coci2006-2007 2] R2
How does MySQL convert rows to columns?
女研究生做“思维导图”与男友吵架!网友:吵架届的“内卷之王”....
[daily question in summer] Luogu p6408 [coci2008-2009 3] pet