当前位置:网站首页>啥是数据库范式
啥是数据库范式
2020-11-08 12:11:00 【osc_6l5fg87g】
前言:
关于数据库范式,时常有听说过,一直没有详细去了解。一般数据库书籍或数据库课程会介绍范式相关内容,范式也经常出现在数据库考试题目中。不清楚你是否对范式有比较清晰的了解呢?本篇文章我们一起来学习下数据库范式吧。
1.数据库范式简介
为了建立冗余较小、结构合理的数据库,设计数据库时必须遵循一定的规则。在关系型数据库中这种规则就称为范式。范式是符合某一种设计要求的总结。要想设计一个结构合理的关系型数据库,必须满足一定的范式。
范式的英文名称是 Normal Form ,简称 NF 。它是英国人 E.F.Codd 在上个世纪70年代提出关系数据库模型后总结出来的。范式是关系数据库理论的基础,也是我们在设计数据库结构过程中所要遵循的规则和指导方法。
目前关系型数据库有六种常见范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。
2.常用范式详解
在设计数据库时,会参考范式要求来做,但是并不是说遵循的范式等级越高越好,范式过高虽然具有对数据关系有更好的约束性,但是也会导致表之间的关系更加繁琐,从而导致每次操作的表会变多,数据库性能下降。通常,在关系型数据库设计中,最高也就遵循到 BCNF ,普遍还是 3NF 。即一般情况下,我们使用前三个范式已经够用了。下面我们来详细了解下常用的前三个范式。
第一范式(1NF)
第一范式是最基本的范式。如果数据库表中的所有字段值都是不可分解的原子值,就说明该数据库表满足了第一范式。简单的讲第一范式就是每一行的各个数据都是不可分割的,同一列中不能有多个值,如果出现重复的属性就需要定义一个新的实体。
示例:假设一家公司要存储其员工的姓名和联系方式。它创建一个如下表:
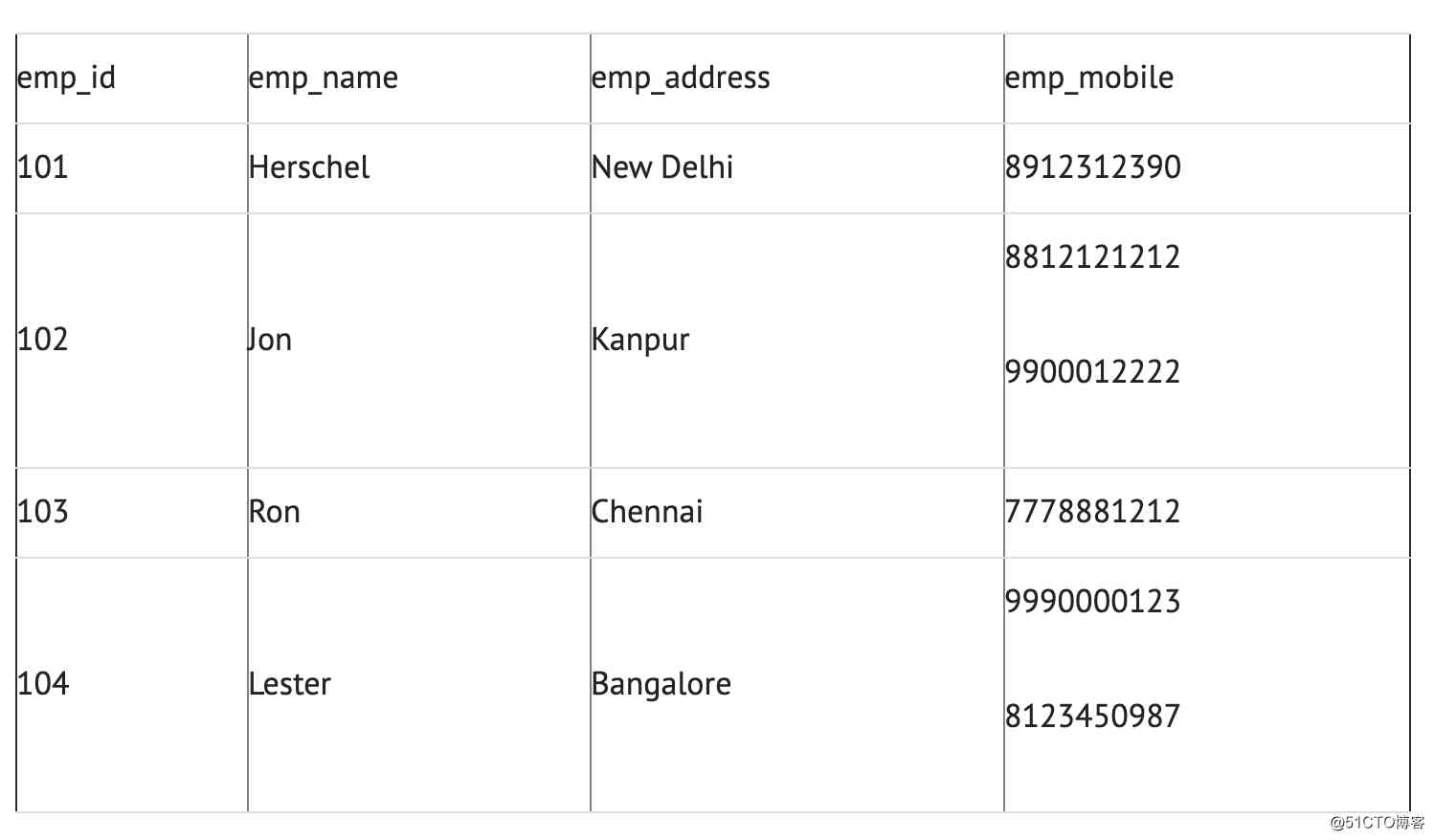
两名员工(Jon&Lester)拥有两个手机号码,因此公司将他们存储在同一表格中,如上表所示。那么该表不符合 1NF ,因为规则说“表的每个属性必须具有原子(单个)值”,Jon&Lester员工的 emp_mobile 值违反了该规则。为了使表符合 1NF ,我们应该有如下表数据:
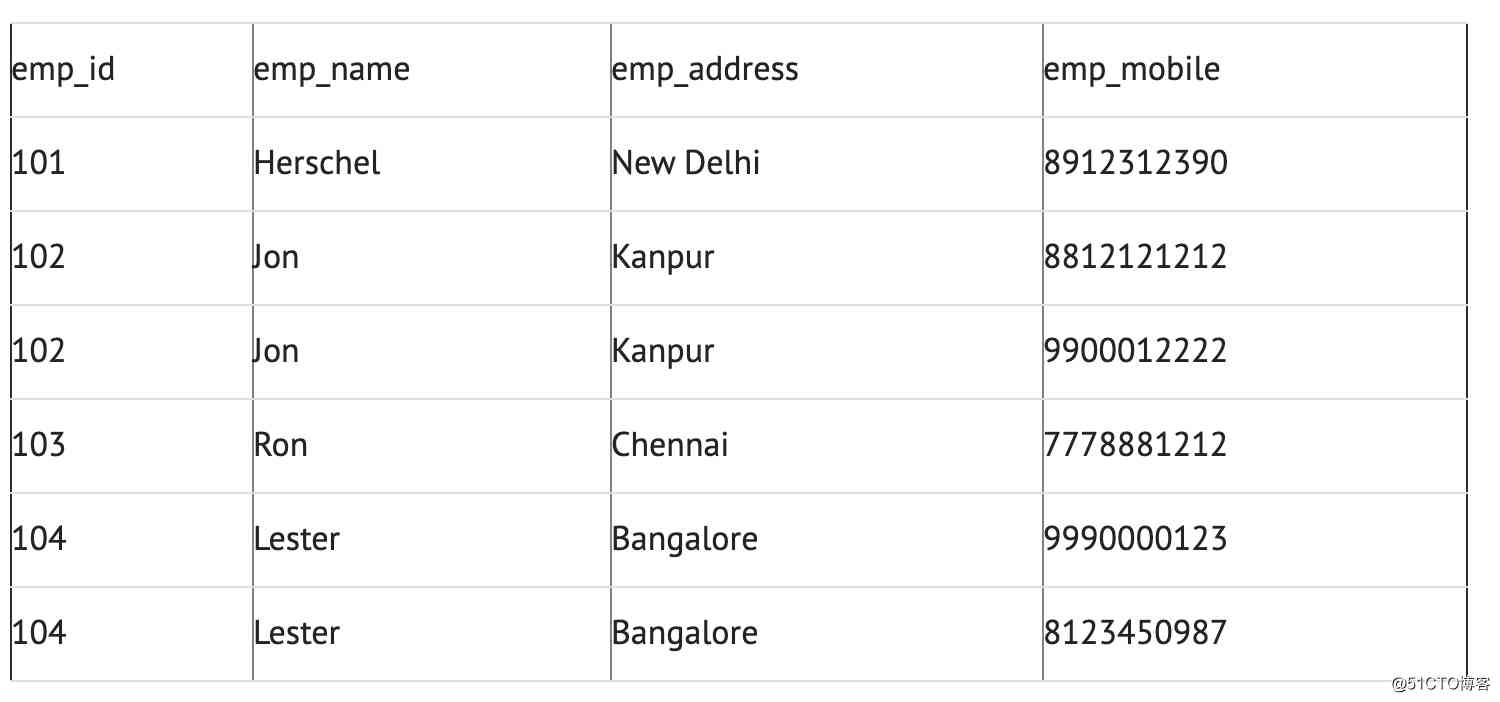
第二范式(2NF)
第二范式在第一范式的基础之上更进一层。第二范式需要确保数据库表中的每一列都和主键相关,而不能只与主键的某一部分相关(主要针对联合主键而言)。也就是说在一个数据库表中,一个表中只能保存一种数据,不可以把多种数据保存在同一张数据库表中。
+----------+-------------+-------+
| employee | department | head |
+----------+-------------+-------+
| Jones | Accountint | Jones |
| Smith | Engineering | Smith |
| Brown | Accounting | Jones |
| Green | Engineering | Smith |
+----------+-------------+-------+上表描述了被雇佣者,工作部门和领导的关系。我们把能够唯一表示数据库中表的一行的数据成为这个表的主键。表中 head 列不和主键相关。 因此,该表是不符合第二范式的,为了使上面的表符合第二范式,需要将它拆分为两个表:
-- employee 为主键
+----------+-------------+
| employee | department |
+----------+-------------+
| Brown | Accounting |
| Green | Engineering |
| Jones | Accounting |
| Smith | Engineering |
+----------+-------------+
-- department 为主键
+-------------+-------+
| department | head |
+-------------+-------+
| Accounting | Jones |
| Engineering | Smith |
+-------------+-------+第三范式(3NF)
满足 2NF 的前提下,非主键外的所有字段必须互不依赖,即需要确保数据表中的每一列数据都和主键直接相关,而不能间接相关。
简而言之,第三范式(3NF)要求一个关系中不包含已在其它关系已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。
3.关于反范式
范式的优点是明显的,它避免了大量的数据冗余,节省了存储空间,保持了数据的一致性。范式化的表通常更小,可以更好地放在内存里,所以执行操作会更快。那么是不是只要把所有的表都规范为 3NF 后,数据库的设计就是最优的呢?这可不一定。范式越高意味着表的划分更细,一个数据库中需要的表也就越多,用户不得不将原本相关联的数据分摊到多个表中。稍微复杂一些的查询语句在符合范式的数据库上都可能需要至少一次关联,也许更多,这不但代价昂贵,也可能使一些索引策略无效。
所以我们在进行数据库设计时,并不会完全按照范式要求来做,有时候也会进行反范式设计。通过增加冗余或重复的数据来提高数据库的读性能,减少关联查询时,join 表的次数。
参考:
版权声明
本文为[osc_6l5fg87g]所创,转载请带上原文链接,感谢
https://my.oschina.net/u/4325435/blog/4708081
边栏推荐
- 攻防世界之web新手题
- 2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
- Automatically generate RSS feeds for docsify
- 你的云服务器可以用来做什么?云服务器有什么用途?
- 11 server monitoring tools commonly used by operation and maintenance personnel
- A scheme to improve the memory utilization of flutter
- Understanding design patterns
- C language I blog assignment 03
- This year's salary is 35W +! Why is the salary of Internet companies getting higher and higher?
- Flink从入门到真香(6、Flink实现UDF函数-实现更细粒度的控制流)
猜你喜欢

2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
How to write a resume and project
Adobe Lightroom / LR 2021 software installation package (with installation tutorial)
原创 | 数据资产确权浅议
How TCP protocol ensures reliable transmission
Entry level! Teach you how to develop small programs without asking for help (with internet disk link)
仅用六种字符来完成Hello World,你能做到吗?

Python basic syntax variables
Q & A and book giving activities of harbor project experts
Analysis of ArrayList source code
随机推荐
学习小结(关于深度学习、视觉和学习体会)
比Python快20%,就问你兴不兴奋?
This paper analyzes the top ten Internet of things applications in 2020!
不多不少,大学里必做的五件事(从我的大一说起)
Flink从入门到真香(6、Flink实现UDF函数-实现更细粒度的控制流)
笔试面试题目:求缺失的最小正整数
Introduction to mongodb foundation of distributed document storage database
2天,利用下班后的4小时开发一个测试工具
Xamarin deploys IOS from scratch Walterlv.CloudKeyboard application
Where is the new target market? What is the anchored product? |Ten questions 2021 Chinese enterprise service
Windows10关机问题----只有“睡眠”、“更新并重启”、“更新并关机”,但是又不想更新,解决办法
Installing MacOS 11 Big Sur in virtual machine
Top 5 Chinese cloud manufacturers in 2018: Alibaba cloud, Tencent cloud, AWS, telecom, Unicom
Ali teaches you how to use the Internet of things platform! (Internet disk link attached)
How to write a resume and project
阿里教你深入浅出玩转物联网平台!(附网盘链接)
The progress bar written in Python is so wonderful~
还不快看!对于阿里云云原生数据湖体系全解读!(附网盘链接)
2018中国云厂商TOP5:阿里云、腾讯云、AWS、电信、联通 ...
This year's salary is 35W +! Why is the salary of Internet companies getting higher and higher?