当前位置:网站首页>19. Support Vector Machines - Intuitive Understanding of Optimization Objectives and Large Spacing
19. Support Vector Machines - Intuitive Understanding of Optimization Objectives and Large Spacing
2022-07-31 02:19:00 【WuJiaYFN】
主要内容
- 优化目标
- 大间距的直观理解
- SVM所作的优化
一、优化目标
- 支持向量机(Support Vector Machine) is a more powerful algorithm,Widely used in industry and academia.与逻辑回归和神经网络相比, SVMLearning complex非线性方程 provides a more clarity,更加强大的方式
Converted to by logistic regressionSVM的步骤
1.Review the hypothesis function for logistic regression:
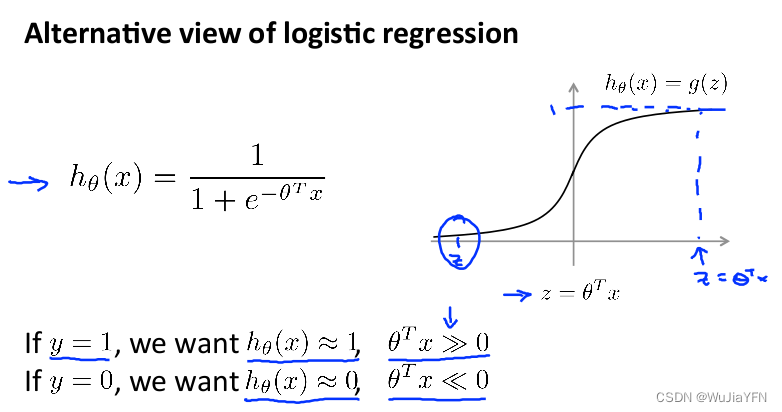
- If we wish to assume a function of The output value will approach 1,则应当θ^Tx远大于0,>> Means far greater than,当 θ^Tx 远大于0时,That is, to the right of the figure,It is found that the output of logistic regression will be close to 1
- If we wish to assume a function of The output value will approach 0,则应当θ^Tx远小于0,<< means far less than,当 θ^Tx 远小于0时,That is, to the left of the figure,It is found that the output of logistic regression will be close to 0
2.Review the cost function for logistic regression:

- 当 y = 1 时,随着 z 增大,h(x)=1/(1+e-z)逼近1,cost逐渐减小;Logistic regression above cost function Only the first item remains(Get the grey curve in the left image above)
- 当 y = 0 时,随着 z 减小,h(x)=1/(1+e-z)逼近0,cost逐渐减小;Logistic regression above cost function Only the second item remains(Get the grey curve in the right image above)
3.为构建SVM,The cost function in logistic regression needs to be modifiedcost function
- 将新的 cost function instead of in logistic regression cost function, 新的 The cost function is the rose-colored curve in the figure above,It is divided into two parts: straight line and diagonal line.
- We call the function on the leftcost1(z),The function on the right is called cost0(z)
4.构建SVM

- 如上图所示,Cost function in logistic regression(cost function)分为 A、B两个部分,进行下面的操作:
- (1) 使用第3步定义的 cost1() 和 cost0() Replace the corresponding term in the formula
- (2) 根据 SVM 的习惯,除去 1/m 这个系数(因为1/m 仅是个常量,Removing it gives the same θ 最优值)
- (3) 对于逻辑回归, cost function 为 A + λ × B ,通过设置不同的 λ 达到优化目的.对于SVM, 我们删掉 λ,引入常数 C, 将 cost function 改为 C × A + B, 通过设置不同的 C 达到优化目的. (在优化过程中,Its meaning is the same as logistic regression;可以理解为 C = 1 / λ)
5. Get support vector machinesSVM的代价函数:

- 注意:The assumed output in logistic regression is a probability value. 而 SVM 直接预测 y = 1,还是 y = 0
6. SVM的预测方法:

- 当θTx ≥ 0 时,SVM will predict the result as 1,其他情况下,预测结果为0
二、大间距的直观理解
Sometimes support vector machines are called 大间距分类器,That is, to find a positive class、The separator with the largest distance for the negative class(The black line in the image below)
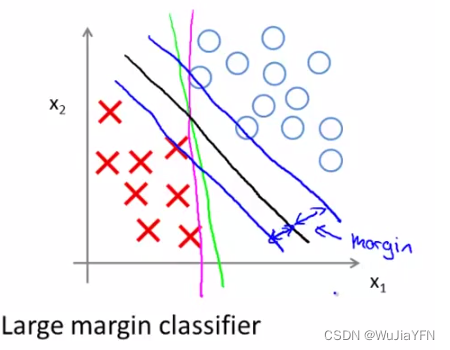
- The two blue lines drawn by the figure,It can be found that there is a larger shortest distance between the black border and the training samples,However, the first and blue line training samples are very close,It will perform worse than the black line when separating the samples
- We call this distance 支持向量机的间距,This is why support vector machines are robust,Because he strives to separate the samples with a maximum spacing
- 鲁棒性 It means that the system is disturbed by uncertainty,具有保持某种性能不变的能力,It is also the ability of the system to survive abnormal and dangerous situations
三、 SVM 所作的优化
- 为了增加鲁棒性,得到更好的结果(避免欠拟合、过拟合,Cope with linear inseparability),SVM Do more than maximize spacing,The following optimizations are also made:
3.1 SVMClassification requirements are more stringent
在逻辑回归中,in the previous definition,θTx ≥ 0 are classified as positive,θTx < 0 classified as negative.事实上,SVM 的要求更严格: θTx ≥ 1 are classified as positive;θTx ≤ -1 classified as negative

This is equivalent to embedding an extra security factor in the SVM,或者说安全的间距因子
3.2 关于参数 C

当C 特别大时,We want to make the first term of the cost function 0,则应该满足 θ^Tx >=1 且 y=1 或者 θ^Tx <=1 且 y=0
当第一项为0后,The goal becomes to minimize the second term
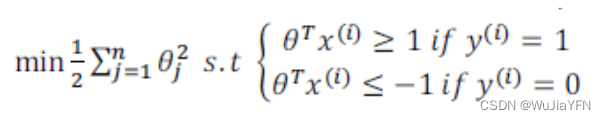
If you want to separate the samples with the maximum spacing,即将 C 设置的很大.Then just because of one outlier,The decision boundary will change from the black line in the image below to the pink line,这是不明智的

如果 C 设置的小一点,You end up with this black line.It can ignore the effects of some outliers,And when the data is linearly inseparable,They can also be properly separated,Get better decision boundaries
因为 C = 1 / λ,因此:
C 较小时,相当于 λ 较大.可能会导致欠拟合,高偏差 variance
C 较大时,相当于 λ 较小.可能会导致过拟合,高方差 bias
C的取值问题才是SVM的核心,CGet it when not so big,In order to have both a big boundary and a certain one/Some abnormal data are not sensitive
如果觉得文章不错的话,可以给我点赞鼓励一下我,Welcome friends to collect articles
关注我,我们一起学习,一起进步!!!
边栏推荐
- First acquaintance with C language -- array
- 如何在 go 程序中暴露 Prometheus 指标
- tcp框架需要解决的问题
- Path and the largest
- Calculate S=a+aa+…+aa…a
- Fiddler captures packets to simulate weak network environment testing
- mmdetection trains a model related command
- PDF 拆分/合并
- Introduction to flask series 】 【 flask - using SQLAlchemy
- 【银行系列第一期】中国人民银行
猜你喜欢
STP选举(步骤+案列)详解

Shell script to loop through values in log file to sum and calculate average, max and min
mysql 视图

Static routing + PAT + static NAT (explanation + experiment)

STM32CUBEMX开发GD32F303(11)----ADC在DMA模式下扫描多个通道

Arbitrum 专访 | L2 Summer, 脱颖而出的 Arbitrum 为开发者带来了什么?
Are you still working hard on the limit of MySQL paging?
Installation, start and stop of redis7 under Linux

leetcode-1161: Maximum in-layer element sum
pycharm cannot run after renaming (error: can't open file...No such file or directory)
随机推荐
Observer mode (1)
直播预告 | KDD2022博士论文奖冠亚军对话
16. Registration Center-consul
[1153] The boundary range of between in mysql
User interaction + formatted output
成为比开发硬气的测试人,我都经历了什么?
两个有序数组间相加和的Topk问题
221. Largest Square
完整复制虚拟机原理(云计算)
What are the project management tools like MS Project
LeetCode 1161 最大层内元素和[BFS 二叉树] HERODING的LeetCode之路
Introduction to flask series 】 【 flask - using SQLAlchemy
加密生活,Web3 项目合伙人的一天
The real CTO is a technical person who understands products
最大路径和
tcp框架需要解决的问题
Real-time image acquisition based on FPGA
静态路由解析(最长掩码匹配原则+主备路由)
General introduction to the Unity interface
力扣刷题之有效的正方形(每日一题7/29)