当前位置:网站首页>[lecture notes] how to do in-depth learning in poor data?
[lecture notes] how to do in-depth learning in poor data?
2022-07-29 07:49:00 【Have you studied hard today】
intro: The results of deep learning are not only the functions of powerful models , It is also because there is a large amount of high-quality data to support . But when the data available for training is poor 、 What to do when there are various problems ?
This lecture introduces several imperfect data situations , For example, federal learning 、 Long tail learning 、 Noise label learning 、 Continuous learning, etc , And introduce how to make the deep learning method deal with these situations , Still strong .
Success of Deep Learning
What is a good data set ?
Large-scaled labeled data
Good training data should have the following traits:
- Accessible
- Large-scaled
- Balanced
- Clean
If your data does not meet the above Perfect data set characteristic , How to make deep learning still effective ?
- Data is locally stored ( When the data is not in hand , How to use others' data to train your own model ): Federal learning ,
Federated Learning - Class distribution is imbalanced ( When data categories are unbalanced ): Long tail learning ,
Long-tail Learning - Label is not accurate( When the data is dirty ):
Noisy Label Learning - Partial data is available( When data is only partially available ): Continuous learning ,
Continual Learning
Federal learning
Federated Learning Framework
Federal learning , No data transmission , Transfer model parameters .
- Applicable scenario : Many data are not available , It's private data .
- Federal learning consists of Google On 2016 in . The goal is learn a model without centralized training.
- Data is stored privately in each client .
- Models are trained separately , And aggregate on the server .
- We send model parameters, other than data.
Main difficulties :Data heterogeneity ( Data heterogeneity )
- Number of training data on each client is different.
- Classes for training on each client is different.
- Imbalance ratio on each client is different.
Other difficulties :
- personalized FL, Personalized federal learning
- Communication and Compression, Need transmission and compression
- Preserving Privacy, privacy protection ( Some can deduce data through models )
- Fairness, fair ( The model should be as good )
- Data Poisoning Attacks, Data poisoning attack ( Someone wants to destroy the model with bad data )
- Incentive, Reward mechanism ( Someone wants to go whoring for nothing , The contribution to the model needs to be quantified )
- Vertical Federated Learning
- …
Long tail learning
- Applicable scenario : Category imbalance .
The amount of data in one category is much larger than that in another .
majority class & minority class
Aiming at the problem of data imbalance , Before the popularity of deep learning , There are mainly two kinds of commonly used methods :
- Resampling ,re-sampling method( Make the data more balanced )
- Reweighting ,re-weighting method ( For example, make a certain kind of punishment more serious )
In the face of deep learning problems , There are new challenges :
- Classified tasks More categories 了 , For example, there are thousands of categories . The imbalance problem becomes very complicated , For example, half a lot, half a little ? There are still many classes , Few classes ?
- Most deep learning models are End to end Of .
therefore , stay 2019 In, a new concept was put forward : Long tail learning .
Compared with traditional unbalanced learning , Long tail learning has the following characteristics :
- Many categories
- The number of samples in each category is subject to power-law distribution
- focus on deep learning models(most for CV tasks)
Method Methodology:
- Re-weighting, If there are fewer classes, they are classified incorrectly , Give more serious punishment
- Augmentation, Data to enhance
- Decoupling,RS or RW may damage feature representation. They only help build the classifier.
- Ensemble Learning, Integrated learning , Train multiple models and vote
Noise label learning
Applicable scenario : There is a certain error rate in labels .
Method :
Image source: B. Han et al., “A Survey of label-noise Representation Learning: Past, Present and Future”, 2020.
for example :
Estimate the noise transfer matrix , That is to estimate the probability that a certain kind of samples will be divided into another kind .
Co-Teaching:
Future Direction: OOD Noise
Clean, ID noise, OOD Noise(out of distribution)
Continuous learning
( Lifelong learning 、 Incremental learning 、 Data flow learning )
Data comes as time goes on.
The problem is :
- Limited memory , Previous samples will be discarded
- Data distribution may change
- The past cannot be forgotten
trade-off: The model should be stable , But also plastic .stability & plasticity
The plasticity of deep learning model is relatively easy , But it's also easy to forget what you learned before , This phenomenon is Catastrophic oblivion (catastrophic forgetting).
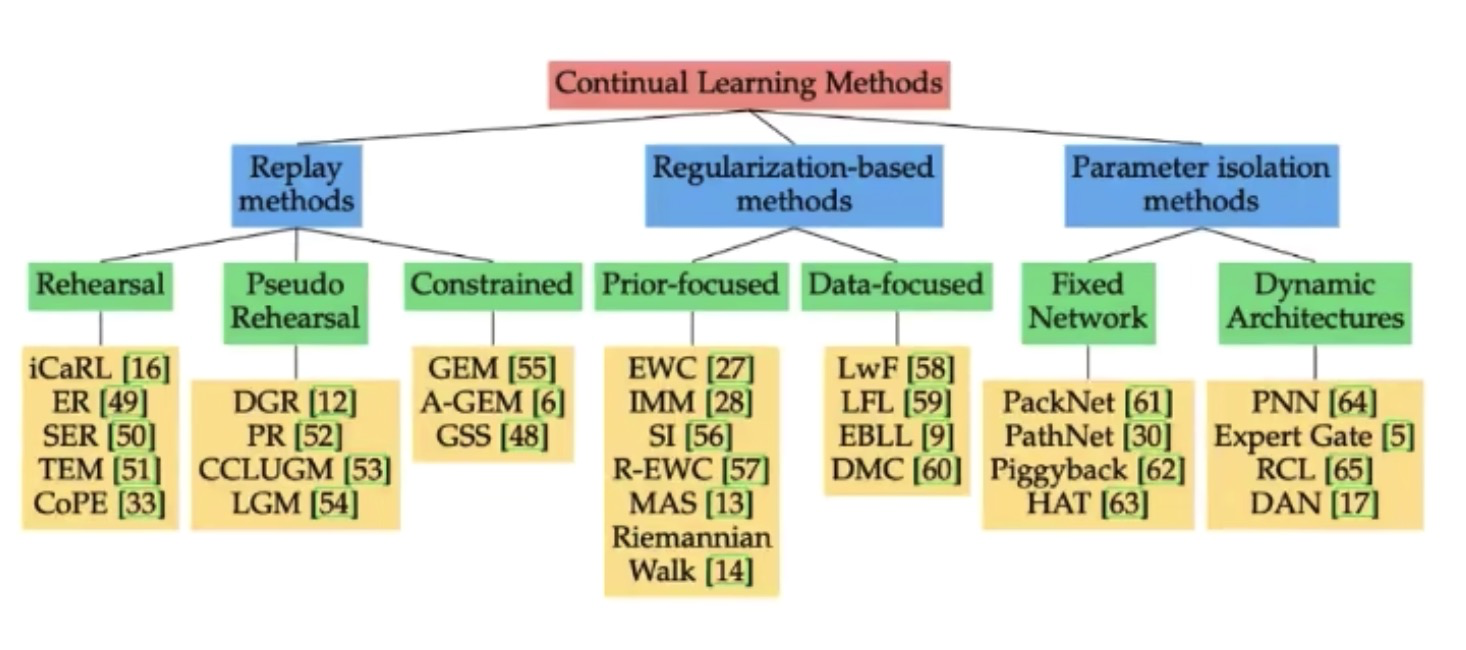
Replay methods:
Select some representative ones from the old samples , Add it to the new training .
Select and keep a few representative samples in each task. Incorporate them into the training process of future tasks.
How to use it? ? for example GEM, Added restrictions , The performance of the new model on the old sample cannot deteriorate .
How to choose ? For example, data set compression ,Dataset Condensation.
Playback model shortcoming :
- Cannot meet the requirements of lifelong learning , Always throw away a lot of data .
- Some data cannot be saved .
but SOTA Our approach is still based on Dataset Condensation Of .
regularization-based method A regularization based approach
Such methods do not store past data , You can save the model . In the process of optimization , It is required that the new model should not differ too much from the old model .
elastic weight consolidation
parameter isolation methods Parameter isolation method
Specify different model parameters for each task , To prevent possible forgetting .dedicate different model parameters to each task, to prevent any possible forgetting.
Generally, the important parameters of the past tasks are fixed.
The model is very large , Not all parameters are useful , So large models can be compressed into small models , Maintain its function . So after every study , Compress the model , Next time, use the empty parameter space to learn the next task .
Conclusion
The above discusses four kinds of imperfect data in the training of deep learning model :
- federated learning: data is not centralized.
- Long-tail learning: data is class imbalanced.
- Noisy label learning: data is mislabeled.
- Continual learning: data is gradually coming.
Reference:
Xiamen University Lu Yang Lectures on the frontier of information technology
A u t h o r : C h i e r Author: Chier Author:Chier
边栏推荐
- MySQL 45 讲 | 07 行锁功过:怎么减少行锁对性能的影响?
- CFdiv1+2-Bash and a Tough Math Puzzle-(线段树单点区间维护gcd+总结)
- 【深度学习】数据准备-pytorch自定义图像分割类数据集加载
- UPC 小C的王者峡谷
- [WPF] realize language switching through dynamic / static resources
- 小D的刺绣
- [skill accumulation] presentation practical skill accumulation, common sentence patterns
- Strongly connected component
- C# 之 volatile关键字解析
- 基于高阶无六环的LDPC最小和译码matlab仿真
猜你喜欢

Do you want to meet all the needs of customers

Cs61abc sharing session (VI) detailed explanation of program input and output - standard input and output, file, device, EOF, command line parameters
![[flask introduction series] installation and configuration of flask Sqlalchemy](/img/62/3d108561f2cfeb182f8241192a79ba.png)
[flask introduction series] installation and configuration of flask Sqlalchemy
![[paper reading] tomoalign: a novel approach to correcting sample motion and 3D CTF in cryoet](/img/3a/75c211f21758ca2d9bb1a40d739d80.png)
[paper reading] tomoalign: a novel approach to correcting sample motion and 3D CTF in cryoet

Multi thread shopping

Joseph Ring problem
![[summer daily question] Luogu p6461 [coci2006-2007 5] trik](/img/bf/c0e03f1bf477730f0b3661b3256d1d.png)
[summer daily question] Luogu p6461 [coci2006-2007 5] trik

Why don't you like it? It's easy to send email in cicd

LANDSCAPE
![[MySQL] - [subquery]](/img/81/0880f798f0f41724fd485ae82d142d.png)
[MySQL] - [subquery]
随机推荐
Do you want to meet all the needs of customers
Use custom annotations to verify the size of the list
[summer daily question] Luogu p6320 [coci2006-2007 4] sibice
信用卡购物积分
Dilworth 定理
Gin abort cannot prevent subsequent code problems
String类
Dilworth theorem
LANDSCAPE
[summer daily question] Luogu p7760 [coci2016-2017 5] tuna
Phased learning about the entry-level application of SQL Server statements - necessary for job hunting (I)
My entrepreneurial neighbors
监听页面滚动位置定位底部按钮(包含页面初始化定位不对鼠标滑动生效的解决方案)
Go 事,如何成为一个Gopher ,并在7天找到 Go 语言相关工作,第1篇
小D的刺绣
Halcon installation and testing in vs2017, DLL configuration in vs2017
Analyze the roadmap of 25 major DFI protocols and predict the seven major trends in the future of DFI
输出1234无重复的三位数
State machine DP 3D
[summer daily question] Luogu P6500 [coci2010-2011 3] zbroj