当前位置:网站首页>Li Hongyi machine learning (2021 Edition)_ P5-6: small gradient processing
Li Hongyi machine learning (2021 Edition)_ P5-6: small gradient processing
2022-07-27 01:12:00 【Although Beihai is on credit, Fuyao can take it】
Catalog

Related information
Video link :https://www.bilibili.com/video/BV1JA411c7VT
Original video link :https://speech.ee.ntu.edu.tw/~hylee/ml/2021-spring.html
Leeml-notes Open source project :https://github.com/datawhalechina/leeml-notes
1、 Optimization failure reason Optimization Fails

1.1、critical point
gradient is zero, The gradient of 0 The point of , be called critical point. Contains two categories ,local minima,saddle point, as follows :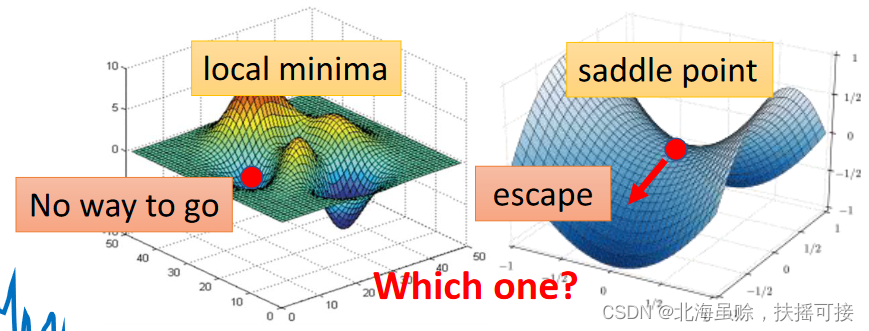
1.2、 Mathematical explanation
Using multivariate function Taylor expansion ,𝐿(𝜽) stay 𝜽 = 𝜽′ Expand as follows :
g Is the gradient of function , It's a vector ;H Hessian matrix of function , Express the second-order matrix for different parameters :
stay critical point It's about , gradient g=0, Simplified as follows :
Critical Point There are three types ,minima,maxima,Saddle point, rely on 𝒗 𝑇 𝐻 𝒗 𝒗^𝑇𝐻𝒗 vTHv Size judgment :
𝒗 𝑇 𝐻 𝒗 𝒗^𝑇𝐻𝒗 vTHv>0:𝐿(𝜽)> 𝐿(𝜽′),minima
𝒗 𝑇 𝐻 𝒗 𝒗^𝑇𝐻𝒗 vTHv<0:𝐿(𝜽)< 𝐿(𝜽′),maxima
𝒗 𝑇 𝐻 𝒗 𝒗^𝑇𝐻𝒗 vTHv>0 And <0:Saddle point
It can also be done through H Positive and negative eigenvalues of Judge three kinds of special points . give an example : 𝑦 = 𝑤 1 𝑤 2 𝑥 𝑦 = 𝑤_1𝑤_2𝑥 y=w1w2x, data (1,1)
give an example : 𝑦 = 𝑤 1 𝑤 2 𝑥 𝑦 = 𝑤_1𝑤_2𝑥 y=w1w2x, data (1,1)
Loss function : 𝐿 = ( 𝑦 ^ − 𝑤 1 𝑤 2 𝑥 ) 2 = ( 1 − 𝑤 1 𝑤 2 ) 2 𝐿= (\hat𝑦 − 𝑤_1𝑤_2𝑥)^2 = (1- 𝑤_1𝑤_2)^2 L=(y^−w1w2x)2=(1−w1w2)2;
Calculation g And H as follows :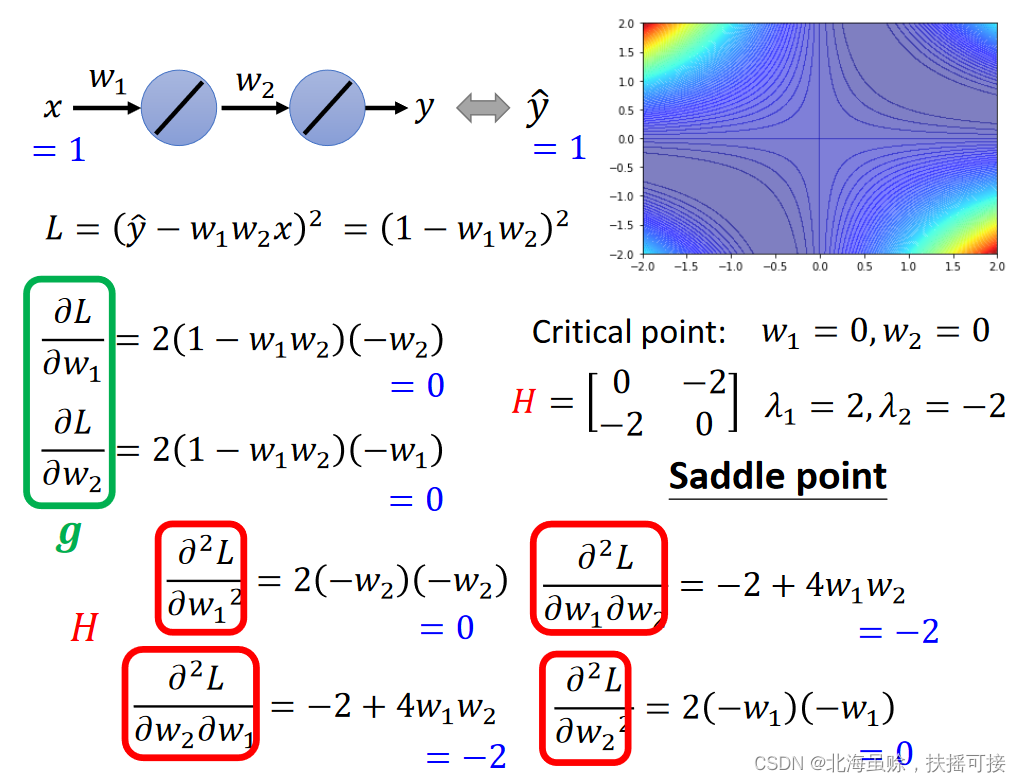
1.3、 Saddle point treatment
Rely on Hessian matrix H Determine the optimization direction of saddle point ,𝐻 may tell us parameter update direction. The hypothetical reasoning of mathematics is as follows :
Looking for Hessian matrix H A negative eigenvector of u, That is to say L Direction of descent .
give an example :
The above functions , Find the saddle point and find the direction of descent :
- stay (0,0), Hazen matrix H The eigenvalue 2,-2. There are positive and negative , Judge (0,0) For saddle point .
- Select Hessian matrix H The eigenvalue -2 Corresponding to an eigenvector 𝒖 = [1, 1], That is, the update direction .
however , Because the amount of calculation is relatively large , The above methods are rarely used .
1.4、 Proportion of critical points

M i n i m u m r a t i o = N u m b e r o f P o s i t i v e E i g e n v a l u e s N u m b e r o f E i g e n v a l u e s Minimum ratio = \frac {Number \; of \; Positive \; Eigen \;values} {Number\; of \;Eigen \;values} Minimumratio=NumberofEigenvaluesNumberofPositiveEigenvalues
Above picture , Through empirical research , Most of critical point For saddle point ,local minima Very few ( Abscissa 1 It's about , It's absolute minima).
2、Batch and Momentum
2.1、Batch batch
A training epoch Divided into several batch, every last batch Can be used for loss function parameters θ \theta θ updated . Every epoch Of batch Will be reassigned .
2.2、Small Batch v.s. Large Batch
2.2.1、 Calculation speed
use GPU Parallel computing , The time consumption of small batch and large batch is basically the same within a certain range :
But it's different batch It takes more time to switch between , So small batches epoch It takes longer :
2.2.2、 Training optimization effect
Large batch training , It is easy to cause optimization errors (Optimization Fails); Small batch training performance is better :
reason : The number of parameter updates in large batches is less , Low fault tolerance ; The number of small batch parameter updates is more , There are more possibilities to jump out local minima.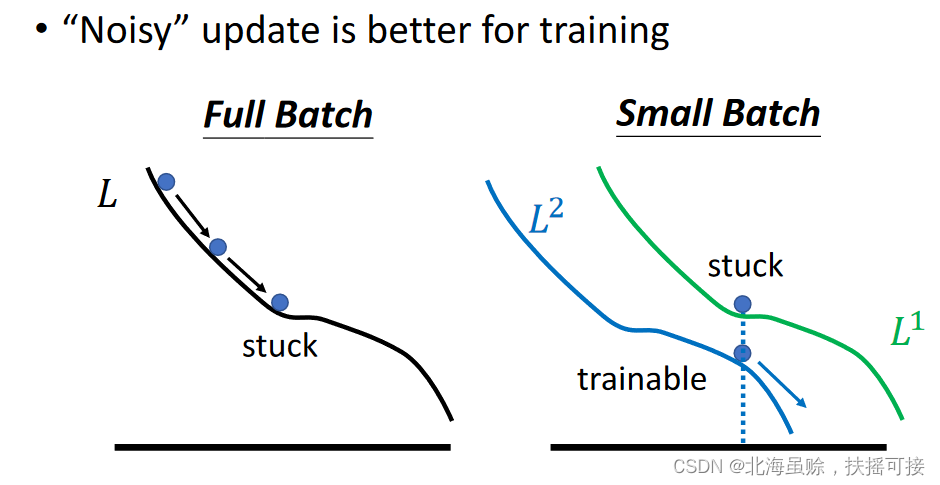
2.2.3、 Test the results
Small batch test data is better , The experimental results are as follows :SB Indicates a small batch ,LB Indicates a large batch .
The reason is still the problem of parameter update ,train And test Loss function of , Think there is a certain translation ; Small batches are more likely to fall into Sharp Minima, Cannot update :
2.2.4、 Comprehensive comparison

2.3、Momentum
Momentum: Learning rate momentum , When updating parameters , Consider not only the gradient of the function , Also consider the previously updated gradient directions :
𝒎 t = λ 𝒎 t − 1 − η 𝒈 t − 1 𝒎^t = \lambda 𝒎^{t-1} − \eta 𝒈^{t-1} mt=λmt−1−ηgt−1
Consider gradient descent and learning rate momentum , The parameters are updated as follows :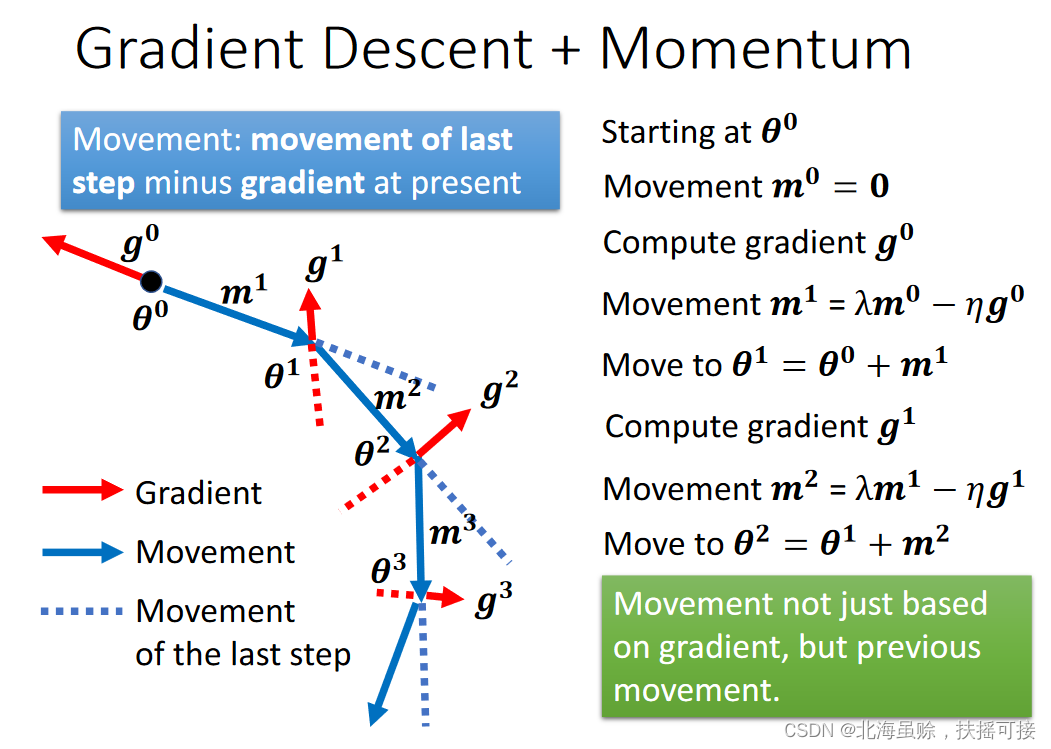
In calculation , You can find , momentum m i m^i mi contain g 0 g^0 g0 To g i g^i gi The sum of the weights of ;
𝒎 i = − ( λ i − 1 η g 0 + λ i − 2 η 2 g 1 + . . . + λ η i − 1 g i − 2 ) − η g i − 1 𝒎^i = -(\lambda^{i-1} \eta g^0 + \lambda^{i-2} \eta^2 g^1+...+\lambda \eta^{i-1} g^{i-2})-\eta g^{i-1} mi=−(λi−1ηg0+λi−2η2g1+...+ληi−1gi−2)−ηgi−1
3、 Conclusion
- critical point Critical points The exit gradient is 0.
- The critical points can be saddle points and local minima .
It can be determined by the haisai matrix H decision .
You can escape the saddle point in the direction of the eigenvector of the Hessian matrix .
Local minima may be rare . - Small batches and momentum updates help escape the tipping point .
边栏推荐
猜你喜欢

Tencent upgrades the live broadcast function of video Number applet. Tencent's foundation for continuous promotion of live broadcast is this technology called visual cube (mlvb)

进入2022年,移动互联网的小程序和短视频直播赛道还有机会吗?

Cannot find a valid baseurl for repo: HDP-3.1-repo-1

Rabbit learning notes

网站日志采集和分析流程

FaceNet

被围绕的区域

游戏项目导出AAB包上传谷歌提示超过150M的解决方案
Flink1.11 intervaljoin watermark generation, state cleaning mechanism source code understanding & demo analysis

Use and cases of partitions
随机推荐
(Spark调优~)算子的合理选择
adb.exe已停止工作 弹窗问题
Scala-模式匹配
基于Flink实时计算Demo—关于用户行为的数据分析
SQL学习(1)——表相关操作
In depth learning report (1)
深度学习报告(3)
并发编程之生产者消费者模式
Zhimi Tencent cloud live mlvb plug-in optimization tutorial: six steps to improve streaming speed + reduce live delay
5. 合法的括号串
Flinksql multi table (three table) join/interval join
SQL学习(3)——表的复杂查询与函数操作
李宏毅机器学习(2017版)_P5:误差
腾讯云直播插件MLVB如何借助这些优势成为主播直播推拉流的神助攻?
Uni-app 小程序 App 的广告变现之路:Banner 信息流广告
Choose RTMP or RTC protocol for mobile live broadcast
Select query topic exercise
数据库期中(一)
DataNode Decommision
Cannot find a valid baseurl for repo: HDP-3.1-repo-1