当前位置:网站首页>Reptile practice
Reptile practice
2022-07-05 21:49:00 【Computer Trainee】
Reptile practice —urllib Library usage
Hello ! Welcome to Computer Trainee Blog post .
If you want to learn relevant content , You can follow bloggers Computer Trainee , Communicate and discuss problems with bloggers .
urllib Library basic use
# -*- coding=utf-8 -*-
# ------------urllib Basic use ----------------
import urllib.request
# Enter url
url = 'http://www.baidu.com'
# Impersonate a browser to send a request , return response
response = urllib.request.urlopen(url)
# read Read the content ,decode decode ,utf-8 by <html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"
content = response.read().decode('utf-8')
# Print the content
print(content)
# 1, A byte by byte read
content1 = response.read()
# 2, Before reading 5 Bytes
content2 = response.read(5)
# 3, Read a line
content3 = response.readline()
# 4, Read multiple lines
content4 = response.readlines()
# 5, Read the head
content5 = response.getheaders()
# Read the status code ,200 It's normal
code = response.getcode()
# Read URL
urll = response.geturl()
# ------------------------------------------------
The above content is for basic use , Readers can run , View results . If you have questions, you can leave a message .
urllib Download Baidu pictures and videos
- Find the link address of the video or picture
The picture link address is right click , Directly copy the address into the program
The video link address is shown in the figure below ( The steps are left click ):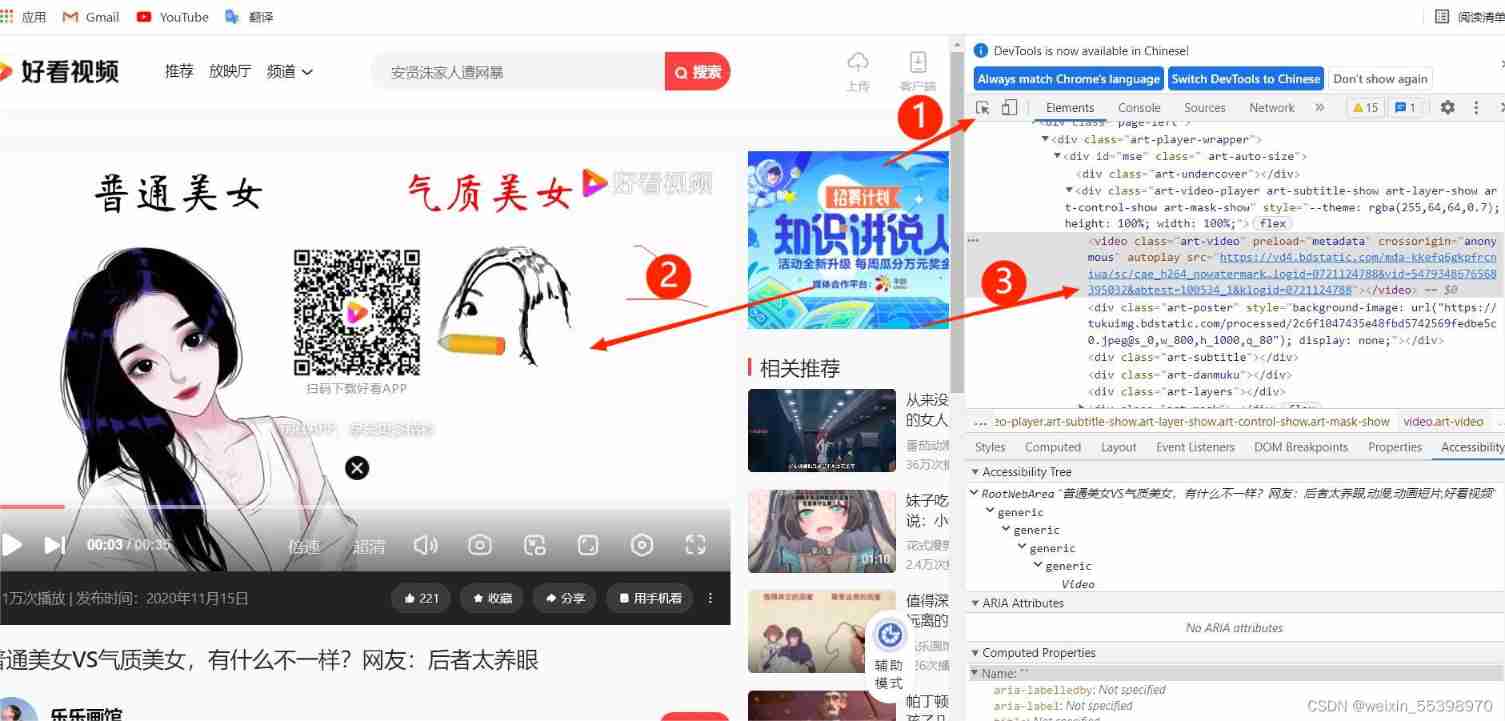
find src, That is the link address of the video . Copy it into the program .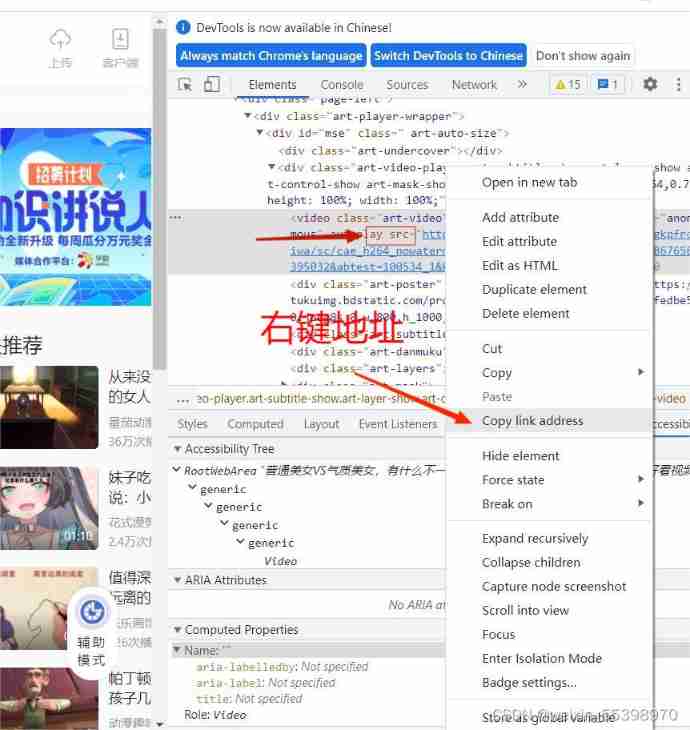
- Use urlretrieve Download
urlretrieve For downloaded functions , Usage method: :urlretrieve( video / The link address of the picture , ‘ Save the path ’)
# ---------------- Download pictures and videos ----------------------
from urllib.request import urlopen, urlretrieve
url = 'http://www.baidu.com'
# Copy image address
url_img = 'https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fimg.jj20.com%2Fup%2Fallimg%2F4k%2Fs%2F02%2F2109242129504953-0-lp.jpg&refer=http%3A%2F%2Fimg.jj20.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=jpeg?sec=1646899077&t=6585c66ba1ae162ac19a4665f8120aea'
# url_img File download path ,' File save path '
urlretrieve(url_img, 'F://python- introduction / Reptile practice /girl.jpg')
# Check , Copy the address of the video , See crawler handwriting for detailed operation
url_video = 'https://vd4.bdstatic.com/mda-kkefq6gkpfrcniwa/sc/cae_h264_nowatermark/1605409952/mda-kkefq6gkpfrcniwa.mp4?v_from_s=hkapp-haokan-nanjing&auth_key=1644309721-0-0-3296c254900172089ec79be4faf7c27e&bcevod_channel=searchbox_feed&pd=1&pt=3&logid=0721124788&vid=5479348676568395032&abtest=100534_1&klogid=0721124788'
urlretrieve(url_video, 'F://python- introduction / Reptile practice / beauty .mp4')
# -------------------------------------------------
Customization of request header ——UA Back climbing
- Right click the mouse , Click to check , Refresh web page
Click on Network, Click the icon to find the website and click , Slide down to UA, Copy into the program .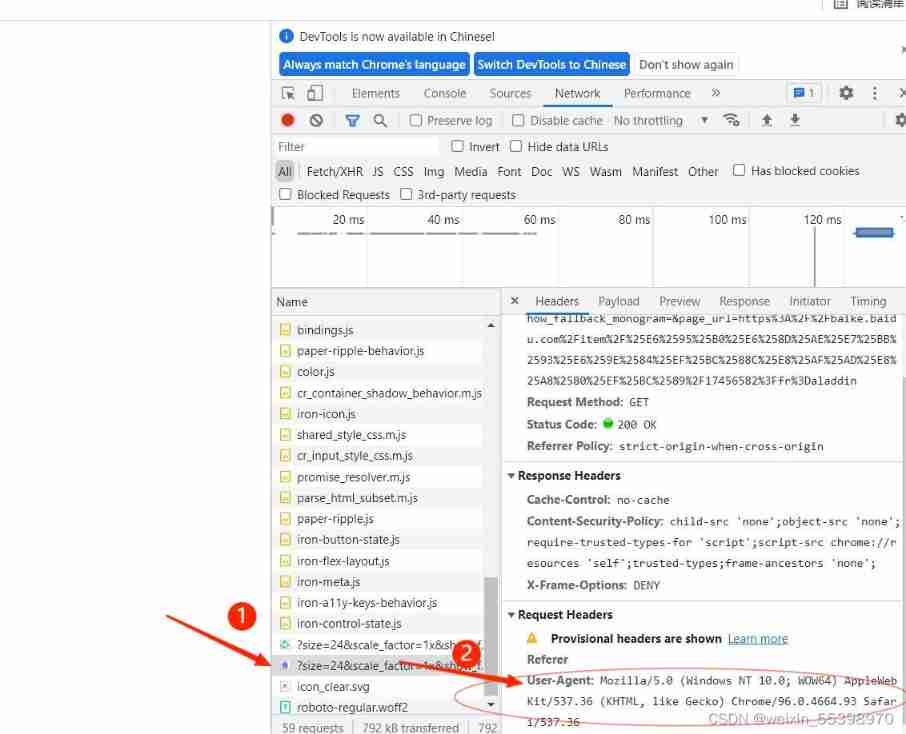
# ----------------- Request object customization ---------------------
from urllib.request import urlopen, Request
url = 'http://www.baidu.com/'
# Set request header
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.93 Safari/537.36'
}
# Simulate the browser to send a request to the server
request = Request(url=url, headers=header)
# Return the requested content
response = urlopen(request)
# Read request content ,Content-Type: text/html;charset=utf-8
content = response.read().decode('utf-8')
print(content)
# ---------------------------------------------------
The above is the actual operation of reptile entry , If you have any questions, you can contact the author for communication .
Paying attention to the author can learn more about the actual operation of the program .
边栏推荐
- Poj 3237 Tree (Tree Chain Split)
- SQL common syntax records
- Making global exception handling classes with aspect
- Multiplexing of Oracle control files
- Gcc9.5 offline installation
- 阿里云有奖体验:用PolarDB-X搭建一个高可用系统
- EasyExcel的读写操作
- Deeply convinced plan X - network protocol basic DNS
- Selenium gets the verification code image in DOM
- PIP install beatifulsoup4 installation failed
猜你喜欢
2.2.5 basic sentences of R language drawing
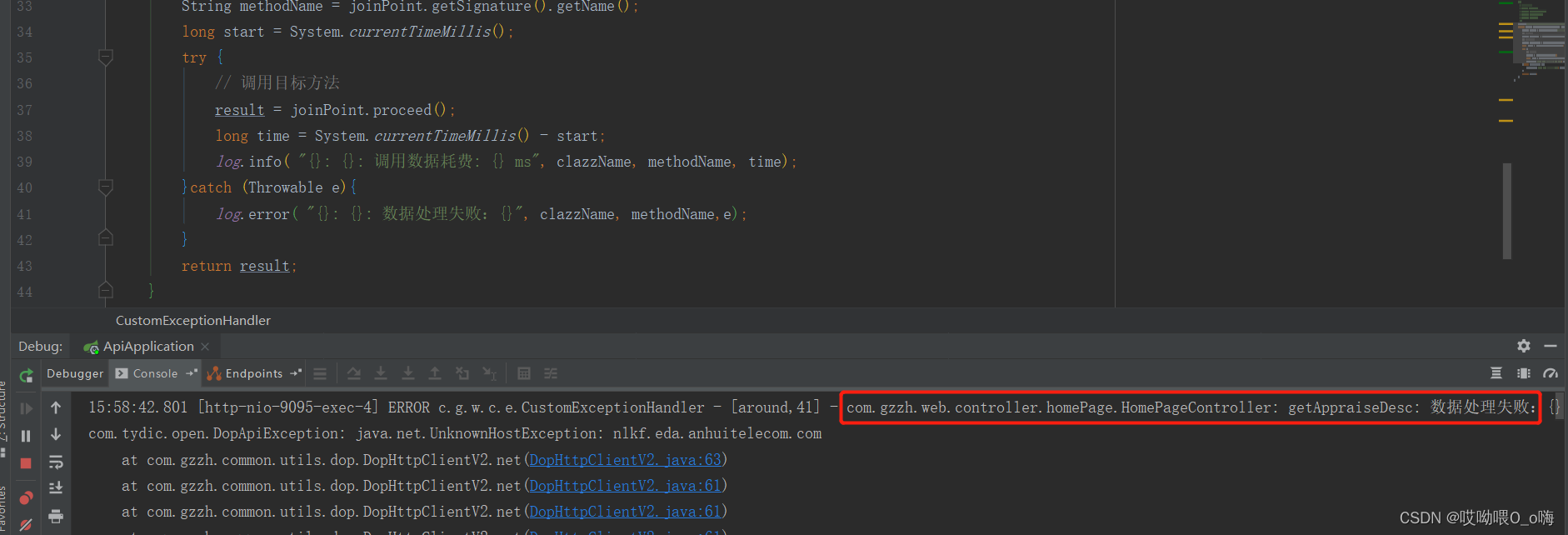
Making global exception handling classes with aspect
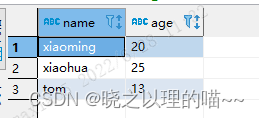
Dbeaver executes multiple insert into error processing at the same time
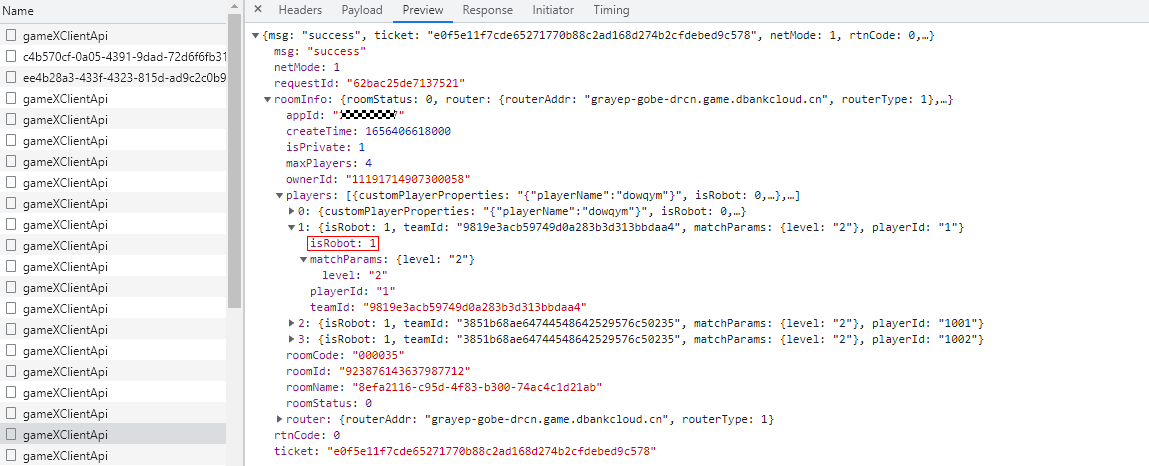
How can Huawei online match improve the success rate of player matching
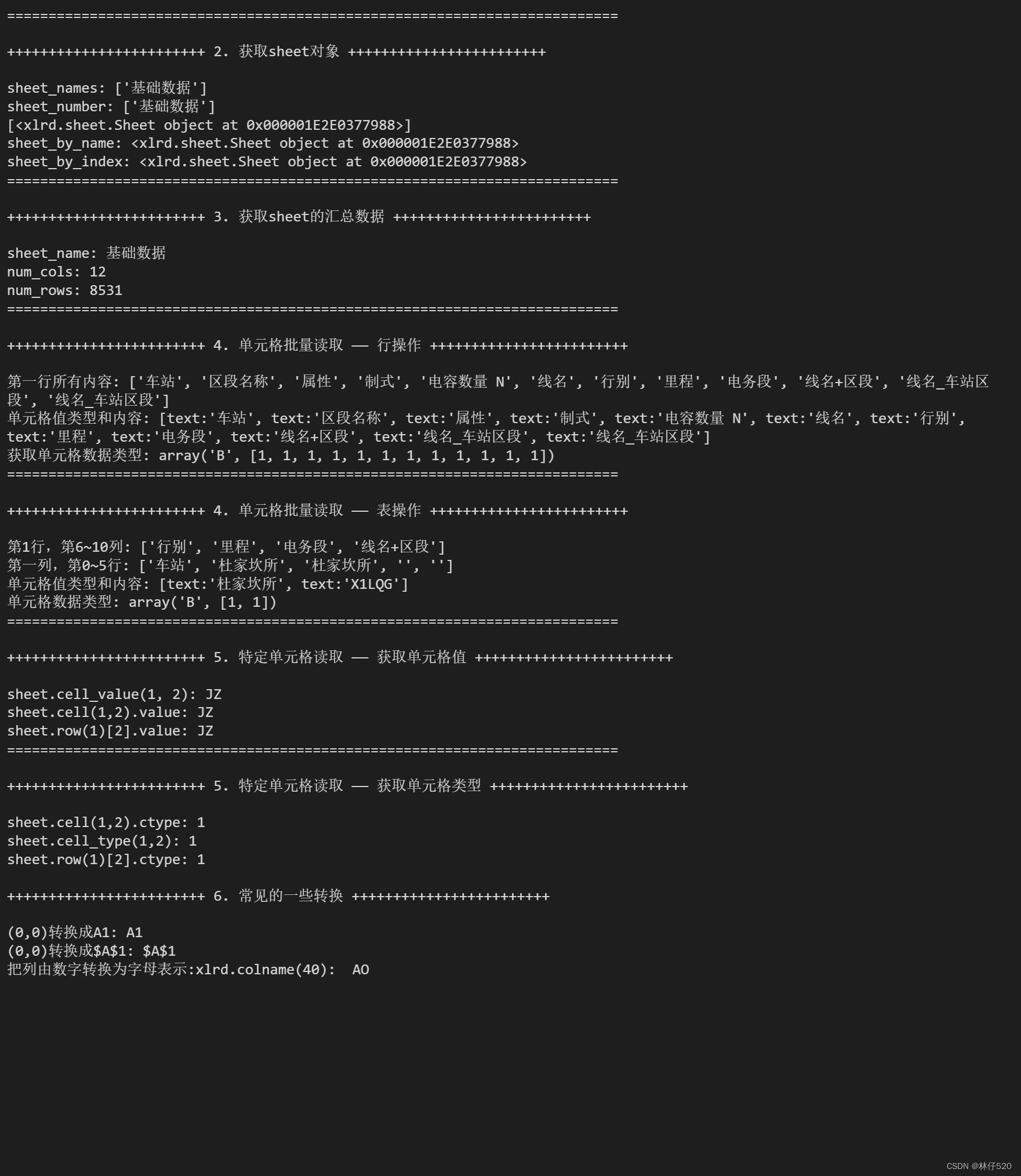
xlrd常见操作

资深电感厂家告诉你电感什么情况会有噪音电感噪音是比较常见的一种电感故障情况,如果使用的电感出现了噪音大家也不用着急,只需要准确查找分析出什么何原因,其实还是有具体的方法来解决的。作为一家拥有18年品牌

Teach yourself to train pytorch model to Caffe (III)
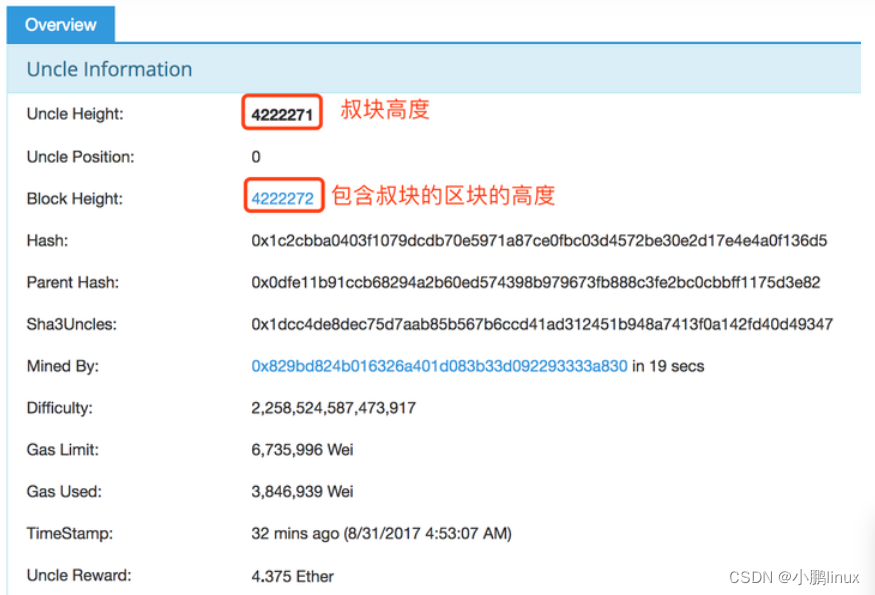
Incentive mechanism of Ethereum eth
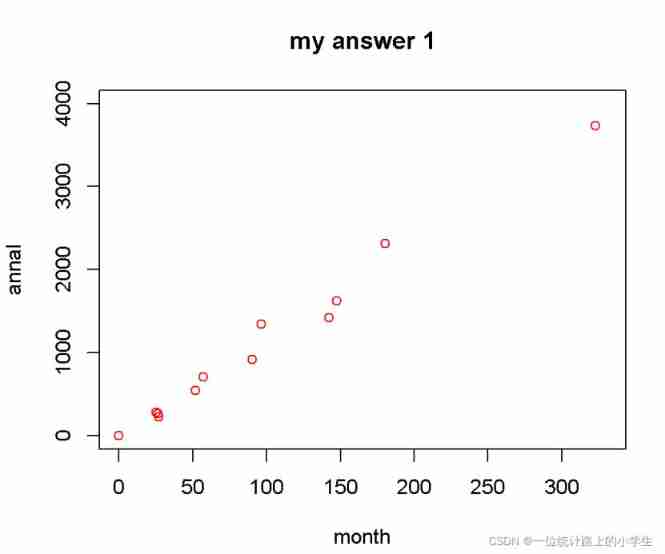
Exercise 1 simple training of R language drawing
Teach yourself to train pytorch model to Caffe (2)
随机推荐
Exercise 1 simple training of R language drawing
Four components of logger
递归查询多级菜单数据
Gcc9.5 offline installation
Two ways to realize video recording based on avfoundation
Problems encountered in office--
有些事情让感情无处安放
Zhang Lijun: penetrating uncertainty depends on four "invariants"
Why can't Chinese software companies produce products? Abandon the Internet after 00; Open source high-performance API gateway component of station B | weekly email exclusive to VIP members of Menon w
Selenium finds the contents of B or P Tags
sql常用语法记录
张丽俊:穿透不确定性要靠四个“不变”
Pointer parameter passing vs reference parameter passing vs value parameter passing
Net small and medium-sized enterprise project development framework series (one)
2.2.5 basic sentences of R language drawing
Golang (1) | from environmental preparation to quick start
The primary key is set after the table is created, but auto increment is not set
华为联机对战如何提升玩家匹配成功几率
ESP32
Huawei game multimedia service calls the method of shielding the voice of the specified player, and the error code 3010 is returned