当前位置:网站首页>Reading notes on the way of Huawei data
Reading notes on the way of Huawei data
2022-06-10 22:44:00 【ZWZhangYu】
List of articles
- The requirements of digital transformation on data governance
- The overall framework of Huawei's data work construction
- Huawei data governance system framework
- Data source management principles
- Unstructured data management based on feature extraction
- Data flow processing
- The core elements of information architecture construction : Design and Implementation Based on business objects
- Basic characteristic class attributes of unstructured data
- Label design
- Data services
- Key capabilities of data maps - Data search
- Data awareness architecture
- Sensing data recommends storage media
- Control data quality
- Comprehensively monitor enterprise business abnormal data
The requirements of digital transformation on data governance
1: Based on unified data management rules , Ensure the quality of the data source and the data into the lake , Form clean 、 complete 、 Consistent data Lake .
2: Business and data driven , Strengthen the construction of data connection , And be able to use data services , Flexible to meet business self-service data consumption demands .
3: For the massive internal and external data gathered , Can ensure data security compliance .
4: Constantly improve the business object 、 Digitizing processes and rules , Improve the ability of automatic data collection , Reduce manual entry .
The overall framework of Huawei's data work construction

1) data source : Business digitization is the premise of data work , Through business objects 、 Digital rules and processes , Continuously improve data quality , Establish cleanliness 、 Reliable data sources .
2) Data Lake : be based on “ To promote as a whole 、 To promote construction with use ” The construction strategy of , Strictly follow the six standards , Through the physical and virtual two ways to enter the lake , Gather massive data both inside and outside Huawei , Form clean 、 complete 、 Consistent data Lake .
3) Data topic join : Through five ways of data connection , Planning and demand driven , Establish data subject connection , And support data consumption through services .
4) Data consumption : Focus on data consumption scenarios , By providing a unified data analysis platform , Meet the needs of self-service data consumption .
5) Data governance : In order to ensure the orderly development of data work in various business fields , We need to establish a unified data governance capability , Such as data system 、 data classification 、 Data perception 、 Data quality 、 Security and privacy . The overall framework of data system construction , Based on unified rules and platforms , Digital business is the premise , Data into the lake based , Linking and providing services through data topics , Support business digital operation
Huawei data governance system framework

Data source management principles
Article 1 with a : All critical data must be certified data sources . Key data refers to data that affect the operation of the company 、 Data from operational reports , Issued uniformly within the company .
Second : Data management professional organizations designate sources for critical data , Data sources must comply with information architecture and Standards , It becomes a data source after being certified by the information architecture expert committee .
Article 3 the : All key data can only be entered in the data source 、 modify , The whole process is shared , Other calling systems cannot modify . Data source quality problems found in downstream links , Corrections should be made at the data source .
Article 4. : All application systems must obtain key data from the data source or data source image .
Article 5. : data Owner Ensure the data quality of the data source , For data sources that do not meet the data quality standards , It must be rectified within a time limit .
Unstructured data management based on feature extraction
As business demands for big data analysis are growing , The management of unstructured data has gradually become an important part of data management . Unstructured data includes plain text 、 Various format documents 、 Images 、 Audio 、 Video and other heterogeneous grid files , Compared with structured data , It's harder to standardize and understand , So it's storing 、 Retrieval and consumption need to be intelligent IT Technology matches it . Unstructured data includes documents ( mail 、Excel、Word、PPT)、 picture 、 Audio 、 Video etc. .
Compared to structured data , Unstructured metadata management needs to manage the title of file objects 、 Format 、Owner Beyond the basic features and definitions , It is also necessary to manage the objective understanding of the data content , Such as labels 、 Similarity retrieval 、 Similarity, etc , In order to facilitate users to search and consume . therefore , The core of unstructured data governance is to extract its basic features and content , And through the implementation of metadata .
Data flow processing
To better identify 、 Manage data in processes and IT Flow between systems , Through the information chain 、 Data flow to describe , Reflect how a certain data is created in a process or application system (Create)、 Read (Read)、 to update (Update)、 Delete (Delete) Of .
The core elements of information architecture construction : Design and Implementation Based on business objects
Principle one : Business objects refer to those that do not Missing important people 、 things 、 matter .
Principle two : Business objects have unique identity information .
Principle three : Business objects are relatively independent and have attribute descriptions .
Principle four : Business objects can be instantiated .
Traditional information architecture extends to business digitalization : object 、 The process 、 The rules
There are a lot of rules in business execution , But most of the rules lack effective management , Often only through file and document management , Even if some rules are solidified to IT In the system , It can not be adjusted flexibly . for example , Some business people often complain , Because some documents are released every year to formulate business specifications , So I don't know what is the latest , And whether there are overlaps and contradictions among multiple historical norms ; in addition , If you want to refresh rules based on business changes , But these rules are fixed in IT In the code ,IT It often takes several months for the system to be modified , At this time, the business may have undergone new changes .
The purpose of rule digitization is to manage complex rules in complex scenes by digital means . Good rule Digital Management , Should be able to implement business rules and IT The application of decoupling , All key business rule data shall be configurable , Be able to adjust flexibly according to business changes .
5 Comparison of three ways of data entering the lake

Basic characteristic class attributes of unstructured data


Text parsing of the file contents of the data source 、 Split and enter the lake . In the process of entering the lake , The original file is still stored on the source system , Only the parsed content enhanced metadata is stored in the data lake . The content analysis into the lake shall meet the following conditions at the same time .
It has been determined that the parsed content corresponds to Owner、 Classification and scope of use .
The basic feature metadata of the corresponding original file before parsing has been obtained .
The storage location after content parsing has been determined , And guarantee that it will not be relocated for at least one year .
Label design
Tags are based on the needs of business scenarios , By targeting objects ( Including static state 、 Dynamic characteristics ) Use abstraction 、 inductive 、 Highly refined feature identification obtained by reasoning and other algorithms , For differentiated management and decision making . Tags consist of tags and tag values , Hit the target .
Tags are gradually extended from the Internet to other fields , The object of tagging is also up to the user 、 Products and so on expand to the channel 、 Marketing activities, etc . In the field of Internet , Labels help achieve precision marketing 、 Directional push 、 Improve the user's differentiated experience, etc ; In the industry , Labels help more with strategic grading 、 Intelligent search 、 Optimize operations 、 Precision marketing 、 Optimized service 、 Smart management, etc . Labels are divided into fact labels 、 Rule tags and model tags .
Fact labels are objective facts that describe entities , Focus on the attributes of entities , If a part is a purchased part or a non purchased part , It's a man and a woman , Tags come from the attributes of entities , It's objective and static ; Regular labels are labels after data processing , It's the statistical result of the combination of attribute and measurement , If the goods are overweight or not , Whether the product is a hot product, etc , Tags are generated by attributes combined with some judgment rules , It's relatively objective and static ; Model labels are insights into the different characteristics of business value orientation , It's the assessment and prediction of entities , For example, the potential consumption of consumers is strong 、 Ordinary or inferior , Tags are generated by combining attributes with algorithms , It's subjective and dynamic .
Data services
Data service is based on data distribution 、 Published framework , Treat data as a service product Provide , To meet customers' real-time data needs , It can be reused and conform to enterprise and industrial standards , Both data sharing and security .
Data services are very different from traditional integration methods , The user of the data ( not only IT System people , It can also be a specific business person ) No more point-to-point search for data sources , And then point-to-point data integration , So as to form a complex integration relationship , Instead, various types of data are obtained on demand through public data services 
1) guarantee “ Count a hole ”, Improve data consistency . Getting data through services is similar to “ Burn after reading ”, In most cases, the data will not be landed in the user's system , Therefore, the data is reduced “ house-moving ”, Once the user of the data does not own the data , This reduces the data inconsistency caused by the secondary transmission to the downstream .
2) Data consumers don't have to pay attention to technical details , It can meet the needs of different types of data services . For data consumers , Don't worry about “ Where is the data I want ”, For example, the user does not need to know which system the data comes from 、 Which database 、 Which physical table , Just know your data needs , You can find the corresponding data service , And then get the data .
2) Improve the data agile response capability . Once the data service is completed , There is no need to build the integration channel repeatedly by users , But through “ subscribe ” The data service quickly obtains data .
4) Meet users' flexible and diverse consumption demands . The provider of the data service does not need to care about how the user “ consumption ” data , It avoids the problem that the supplier's continuous development can not meet the flexible data use demands of the consumer .
5) Give consideration to data security . The use of all data services can be managed , The data provider can accurately 、 Keep abreast of “ who ” Using their own data , And various security measures can be implemented in the construction of data services , Ensure compliance with data usage .
Key capabilities of data maps - Data search
Data map (DMAP) It is for data oriented end users to target data “ Find it ”“ Read it ” Designed to meet the needs of , Application based on metadata , Take data search as the core , Through visualization , Comprehensively reflect the source of relevant data 、 Number 、 quality 、 Distribution 、 standard 、 flow 、 Connections , Let users find data efficiently , Read the data , Support data consumption . Data map is the distribution center of data management achievements , Need to provide a variety of data , Meet the needs of multiple users 、 Data consumption demand of various scenarios , Therefore, Huawei has developed the data map framework shown in the figure in combination with the actual business .
Data search can improve the search accuracy of users , Enable users to quickly understand the data content searched , Search by combination 、 Filter classification , Data labels continue to improve the user experience .
Encapsulate the search engine through the interface , Expose only a single search bar to the user , Search through a single or combined search bar , Find data . Take the picture for example , When users search “ Data standards ” when , Assets that can accurately match names , The matching assets are brought out and displayed through association search , You can also enter keywords that cannot directly match the names of logical entities or physical tables , Perform a fuzzy logic search , To the participle before 、 Post participle 、 Match the middle participle , Except for the logical entity name , Attribute names are also involved 、 Business description and more . When there is no direct asset that exactly matches ( Such as “ personnel ”), Will search according to the front and back participles , In this way, there will be more records of the overall results , It will also cover the search attribute name or the “ personnel ” key word .
Sorting recommendations makes it easier for users to find high quality 、 Consumable data assets , Narrow the search result set , Reduce the time of data identification and judgment , The ultimate goal is to enable users to achieve “ What you search is what you get ” The effect of . Corresponding to the recommended sorting of search results , Two types of services are provided on the function side , So that users can manage search results through passive and active methods .
Data awareness architecture
With the promotion of digital transformation of enterprise business , Non digital native enterprises put forward new requirements and challenges to the perception and acquisition of data , The data output and manual input capabilities of the original information platform have been far from meeting the operational needs of the enterprise's internal organizations under the digital environment . Enterprises need to build data awareness , Adopt modern means to collect and acquire data , Reduce manual entry . The data awareness architecture is shown in the figure .
Data awareness can be divided into “ Hard perception ” and “ Soft perception ”, For different scenarios .“ Hard perception ” It mainly uses equipment or devices to collect data , The collection object is the physical entity in the physical world , Or information carried by physical entities 、 event 、 Process, etc . and “ Soft perception ” Use software or various technologies to collect data , The objects collected exist in the digital world , It usually does not rely on physical devices for collection .

3 class “ Soft perception ”

Buried point
Buried point is the field of data acquisition , Especially in the field of user behavior data collection , Refers to technologies that capture specific user behaviors or events . The technical essence of burying point , It is used to listen for events during the running of software applications , Judge and capture events that need attention when they happen . The main function of embedding point is to help business and data analysts get through the inherent information wall , To understand user interaction behavior 、 Expand user information and move forward operation opportunities to provide data support . In the initial stage of product data analysis , Business personnel know about... Through their own or third-party data statistics platforms App Data indicators accessed by users , Including the number of new users 、 Number of active users, etc . These indicators can help enterprises understand the overall situation and trend of user access in a macro way , Grasp the operation status of the product in general , Data obtained through analysis of buried points , Develop product improvement strategies . At present, there are mainly the following categories of buried point technology , Each category has its own unique advantages and disadvantages , Can be based on business needs , Match to use .
Code embedding is the mainstream embedding method at present , According to their own statistical needs, business personnel select the area and method of embedding points , Form a detailed buried point scheme , The technical personnel manually add these statistical codes to the statistical points that want to obtain data . Visual embedment point sets the embedment point area and events through the visualization page ID, So as to record the operation behavior when the user operates . The full burying point is at SDK Make unified embedding points during deployment , take App Or the operation of the application should be collected as much as possible . No matter whether the business personnel need to bury point data , All buried sites will collect the user behavior data and corresponding information .Log data collection
Log data collection is a real-time collection server 、 Applications 、 Log records generated by network devices, etc , The purpose of this process is to identify operational errors 、 Configuration error 、 Intrusion attempts 、 Policy violations or security issues . In enterprise business management , be based on IT Log contents generated by system construction and operation , Logs can be divided into three categories . Because of the diversity of the system and the difference of the analysis dimension , Log management faces many data management problems . The operation log , It refers to a series of operation records during the use of the system by the system user . This log is helpful for future reference and providing relevant safety audit data . Run log , It is used to record the status and information of the ne device or application during operation , Including abnormal status 、 action 、 Key events, etc . Security log , It is used to record the safety events on the equipment side , Such as login 、 Authority, etc .Web crawler
Web crawler (Web Crawler) Also known as web spider 、 Network robot , It is a program or script that automatically grabs web information according to certain rules . The rise of search and digital operations , The technology of reptile has been greatly developed , Crawler technology as a network 、 The intersection of database and machine learning , It has become a best practice to meet the needs of personalized data .Python、Java、PHP、C#、Go And other languages can implement crawlers , especially Python The convenience of configuring crawlers in , Make the reptile technology popularized rapidly , Also contributed to the government 、 Business 、 Personal concerns about information security and privacy .
Sensing data recommends storage media

As the core of data asset management , Perceptual metadata management should include two aspects 
Control data quality
Data quality refers to “ The data meets the reliability of the application ”, Data quality is described from the following six dimensions .
1) integrity : It means that data is being created 、 There is no missing or omission in the transmission process , Including physical integrity 、 Attribute integrity 、 Record integrity and field value integrity . Integrity is the most fundamental aspect of data quality , For example, the employee ID cannot be blank .
2) timeliness : It refers to the timely recording and transmission of relevant data , Meet the time requirements of business for information acquisition . Data delivery should be timely , The extraction shall be timely , The presentation should be timely . Too long data delivery time may lead to the loss of reference significance of the analysis conclusion .
3) accuracy : Means true 、 Accurately record original data , No false data and information . Data should accurately reflect what it models “ real world ” Entity . For example, the identity information of the employee must be consistent with the information on the identity document .
4) Uniformity : It refers to recording and transmitting data and information in accordance with unified data standards , Mainly reflected in whether the data records are standardized 、 Is the data logical . For example, the names of employees in different systems corresponding to the same job number must be consistent .
5) Uniqueness : The same data can only have unique identifiers . In a data set , An entity appears only once , And each unique entity has a key value that only points to the entity . For example, an employee has only one valid job number .
6) effectiveness : Refers to the value of the data 、 The format and presentation form meet the requirements of data definition and business definition . For example, the nationality of an employee must be the allowable value defined in the national basic data .
Comprehensively monitor enterprise business abnormal data
Abnormal data does not meet the data standard 、 Objectively existing data that does not conform to the essence of the business , For example, the nationality information of an employee is wrong 、 Wrong customer name information of a customer, etc .
Huawei combines ISO8000 Data quality standards 、 Data quality control and evaluation principles ( National standard SY/T 7005—2014), A total of 15 Class rule , The details are shown in the figure .
Rules classification contents and examples 

边栏推荐
- [tcapulusdb knowledge base] tcapulusdb machine initialization and launch introduction
- 【TcaplusDB知识库】TcaplusDB查看线上运行情况介绍
- 【TcaplusDB知识库】TcaplusDB进程启动介绍
- Solution de gestion de la zone pittoresque intelligente pour la réunion des baleines
- Tcapulusdb Jun · industry news collection (V)
- 记录(三)
- Whale conference sharing: what should we do if the conference is difficult?
- 【TcaplusDB知识库】TcaplusDB引擎参数调整介绍
- Matlab - Implementation of evolutionary game theory
- Web3生态去中心化金融平台——Sealem Finance
猜你喜欢

Sealem Finance打造Web3去中心化金融平台基础设施

Whale conference empowers intelligent epidemic prevention
![[tcapulusdb knowledge base] Introduction to tcapulusdb patrol inspection statistics](/img/67/e0112903cb3992a64bab02060dd59a.png)
[tcapulusdb knowledge base] Introduction to tcapulusdb patrol inspection statistics

《暗黑破坏神不朽》数据库资料站地址 暗黑不朽资料库网址

Tcapulusdb Jun · industry news collection (VI)

What about the popular state management library mobx?
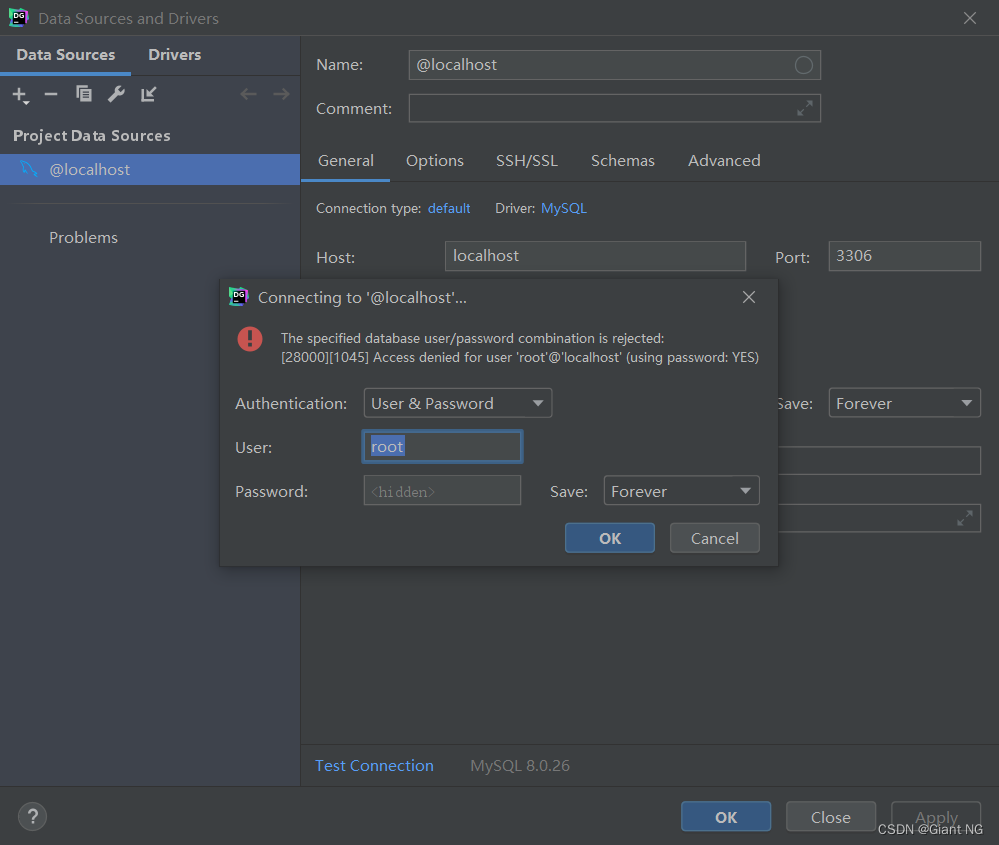
datagrip 报错 “The specified database user/password combination is rejected...”的解决方法
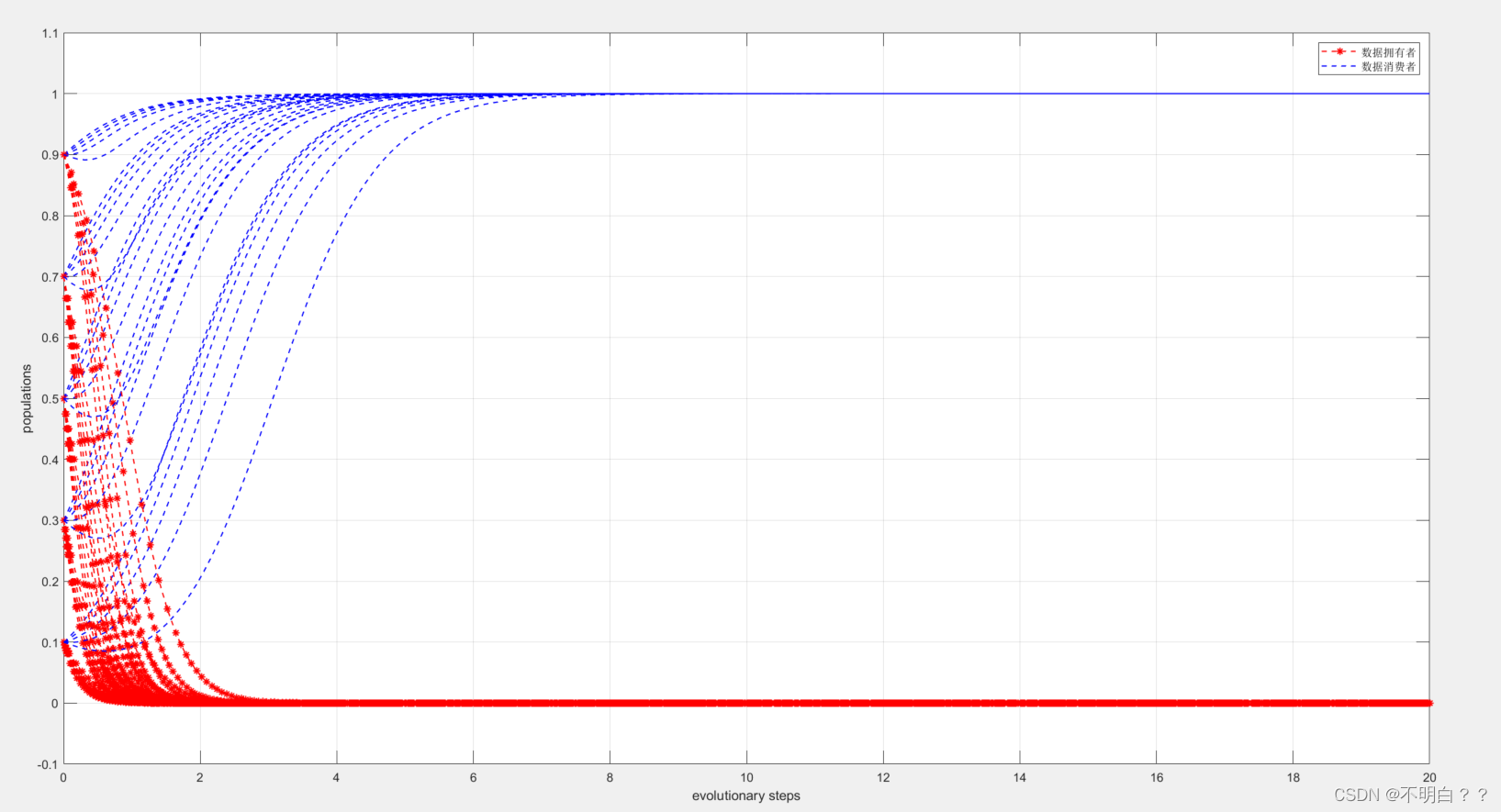
Matlab - 演化博弈论实现
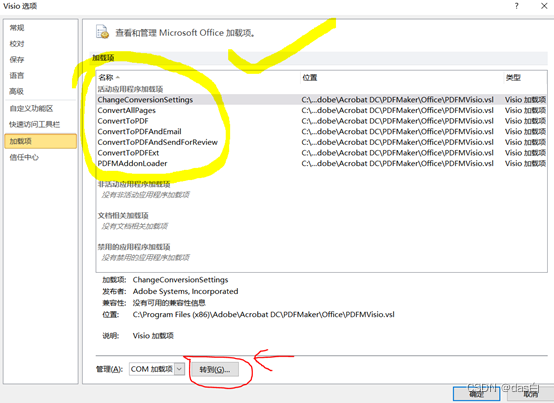
Visio to high quality pdf
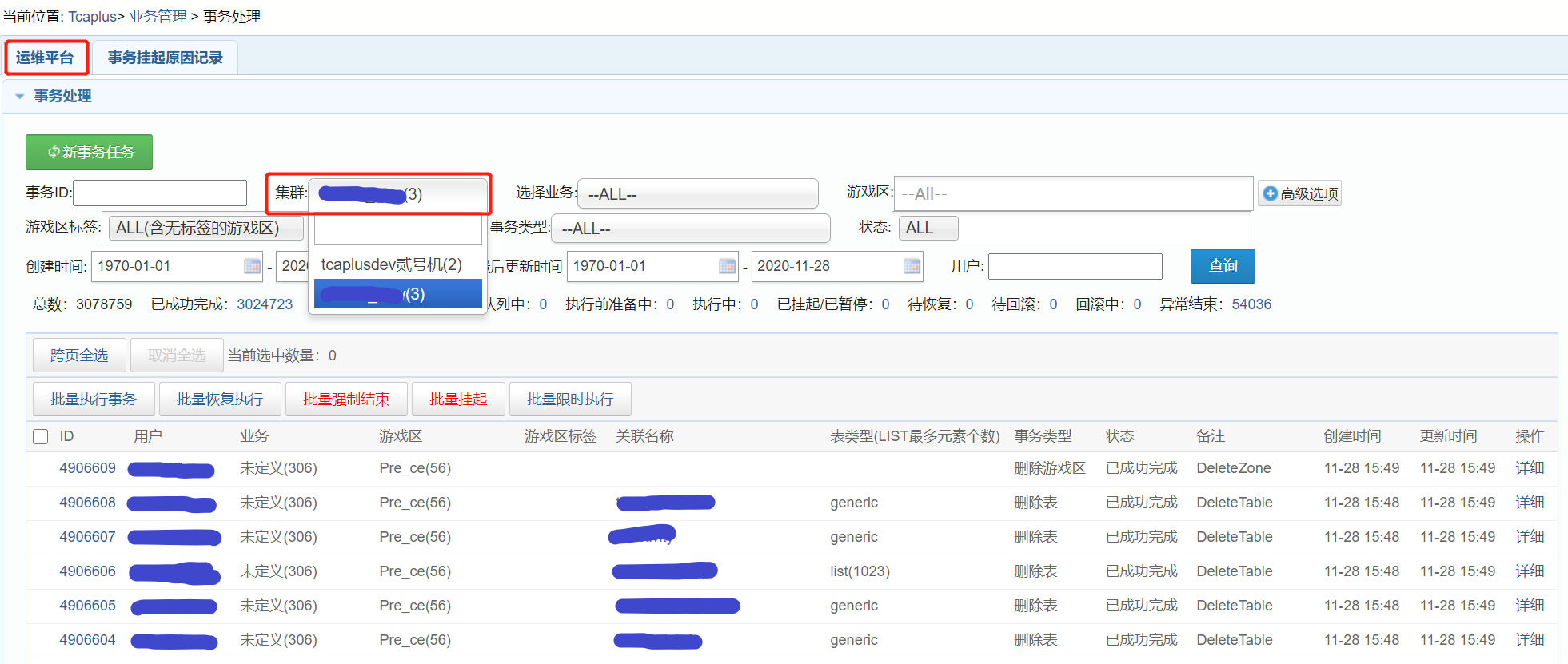
【TcaplusDB知识库】TcaplusDB查看进程所在机器介绍
随机推荐
Tcapulusdb Jun · industry news collection (V)
How small and micro enterprises build micro official websites at low cost
Error parsing mapper XML
[MySQL] Table constraints
Sealem Finance打造Web3去中心化金融平台基础设施
【TcaplusDB知识库】TcaplusDB查看线上运行情况介绍
CCF CSP 202109-1 array derivation
(十一)TableView
[tcapulusdb knowledge base] tcapulusdb tcapdb capacity expansion and contraction introduction
鯨會務智慧景區管理解决方案
Model construction of mmdetection
Record (III)
Mmcv Config class introduction
重排 (reflow) 与重绘 (repaint)
SQL Server查询区分大小写
【TcaplusDB知识库】TcaplusDB巡检统计介绍
1.Tornado简介&&本专栏搭建tornado项目简介
Differences between disk serial number, disk ID and volume serial number
Matlab - 演化博弈论实现
【TcaplusDB知识库】TcaplusDB查看进程所在机器介绍