当前位置:网站首页>Warp shuffle in CUDA
Warp shuffle in CUDA
2022-07-02 06:27:00 【Little Heshang sweeping the floor】
CUDA Medium Warp Shuffle
Warp Shuffle Functions
__shfl_sync、__shfl_up_sync、__shfl_down_sync and __shfl_xor_sync stay warp Exchange variables between threads in .
By computing power 3.x Or higher device support .
Discard notice :__shfl、__shfl_up、__shfl_down and __shfl_xor stay CUDA 9.0 Has been discarded for all devices .
Delete notification : When facing with 7.x Or devices with higher computing power ,__shfl、__shfl_up、__shfl_down and __shfl_xor No longer available , Instead, use their synchronous variants .
The author added : Here may be what you will mention next threadIndex, warpIdx, laneIndex It will be confused . Then I will use the following figure to illustrate .

1. Synopsis
T __shfl_sync(unsigned mask, T var, int srcLane, int width=warpSize);
T __shfl_up_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_down_sync(unsigned mask, T var, unsigned int delta, int width=warpSize);
T __shfl_xor_sync(unsigned mask, T var, int laneMask, int width=warpSize);
T It can be int、unsigned int、long、unsigned long、long long、unsigned long long、float or double. contain cuda_fp16.h After the header file ,T It can also be __half or __half2. Again , contain cuda_bf16.h After the header file ,T It can also be __nv_bfloat16 or __nv_bfloat162.
2. Description
__shfl_sync() Intrinsic functions are allowed in warp Exchange variables between threads in , Without using shared memory . Exchange occurs simultaneously in warp All active threads in ( And mask name ), Move each thread according to the type 4 or 8 Bytes of data .
warp Threads in are called channels (lanes), And may have between 0 and warpSize-1( Include ) Index between . Four source channels are supported (source-lane) Addressing mode :
__shfl_sync()
Copy directly from the index channel
__shfl_up_sync()
From relative to the caller ID Lower channel replication
__shfl_down_sync()
From a higher relative to the caller ID Channel replication of
__shfl_xor_sync()
Based on its own channel ID Bit by bit Exclusive or Copy from channel
Threads can only participate actively __shfl_sync() Another thread of the command reads data . If the target thread is inactive , Then the retrieved value is undefined .
all __shfl_sync() Intrinsic functions take an optional width parameter , This parameter changes the behavior of the intrinsic function . width The value of must be 2 The power of ; If width No 2 The power of , Or greater than warpSize The number of , The result is undefined .
__shfl_sync() Return from srcLane Given ID Thread held var Value . If width Less than warpSize, be warp Each sub part of is represented as a separate entity , Its starting logical channel ID by 0. If srcLane Out of range [0:width-1], Then the returned value corresponds to passing srcLane srcLane modulo width Held by var Value ( That is, in the same part ).
The author added : What was originally said here is a little convoluted , I'd better use pictures to illustrate . Note that the following four figures are made by the author , If there are questions , It's just the level of the author -_-!.

__shfl_up_sync() Through the channel from the caller ID Subtract from delta To calculate the source channel ID. Returns the channel generated by ID The saved var Value : actually , var adopt delta The channel moves up . If the width is less than warpSize, be warp Each sub part of is represented as a separate entity , Start logical channel ID by 0. The source channel index does not surround the width value , So actually lower delta The channel will remain unchanged .
__shfl_down_sync() By way of delta Add the channel of the caller ID To calculate the source channel ID. Returns the channel generated by ID The saved var Value : This will have var Move down the delta The effect of the channel . If width Less than warpSize, be warp Each sub part of is represented as a separate entity , Start logical channel ID by 0. as for __shfl_up_sync(), Source channel ID The number does not surround the width value , therefore upper delta lanes Will remain unchanged .
__shfl_xor_sync() Through the channel to the caller ID And laneMask Perform bitwise XOR to calculate the source channel ID: Return the result channel ID Held by var Value . If the width is less than warpSize, Then each group of threads with continuous width can access the elements in the early thread group , But if they try to access the elements in the following thread group , Will return their own var value . This mode realizes a butterfly addressing mode , For example, it is used for tree protocol and broadcasting .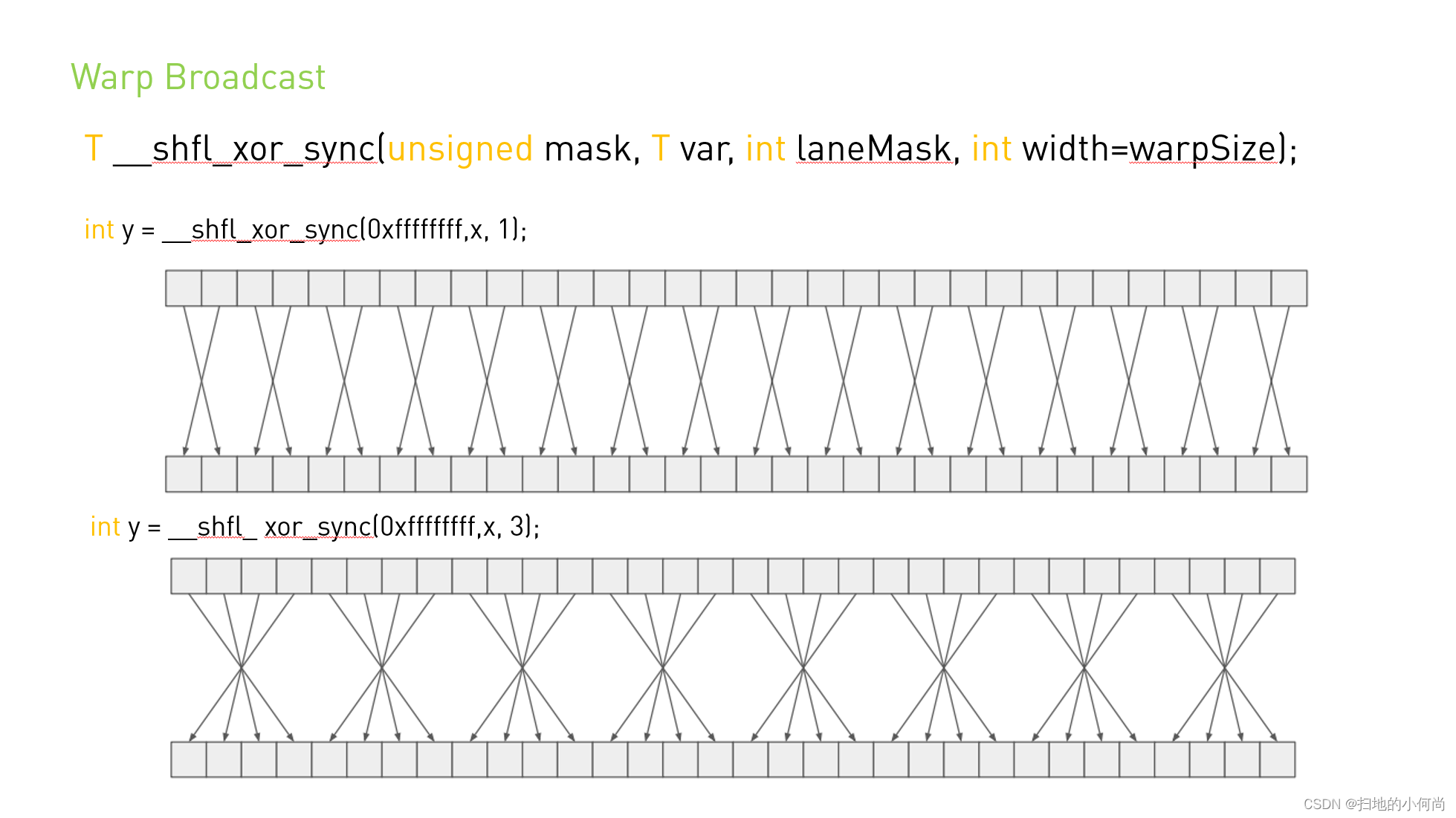
new *_sync shfl The inner function takes a mask , Indicates the thread participating in the call . A representation thread channel must be set for each participating thread ID Bit , To ensure that they converge correctly before the hardware executes internal functions . All non exiting threads named in the mask must use the same mask to execute the same intrinsic function , Otherwise the result is undefined .
3. Notes
Threads can only participate actively __shfl_sync() Another thread of the command reads data . If the target thread is inactive , Then the retrieved value is undefined .
The width must be 2 The power of ( namely 2、4、8、16 or 32). Results with no other value specified .
4. Examples
4.1. Broadcast of a single value across a warp
#include <stdio.h>
__global__ void bcast(int arg) {
int laneId = threadIdx.x & 0x1f;
int value;
if (laneId == 0) // Note unused variable for
value = arg; // all threads except lane 0
value = __shfl_sync(0xffffffff, value, 0); // Synchronize all threads in warp, and get "value" from lane 0
if (value != arg)
printf("Thread %d failed.\n", threadIdx.x);
}
int main() {
bcast<<< 1, 32 >>>(1234);
cudaDeviceSynchronize();
return 0;
}
4.2. Inclusive plus-scan across sub-partitions of 8 threads
#include <stdio.h>
__global__ void scan4() {
int laneId = threadIdx.x & 0x1f;
// Seed sample starting value (inverse of lane ID)
int value = 31 - laneId;
// Loop to accumulate scan within my partition.
// Scan requires log2(n) == 3 steps for 8 threads
// It works by an accumulated sum up the warp
// by 1, 2, 4, 8 etc. steps.
for (int i=1; i<=4; i*=2) {
// We do the __shfl_sync unconditionally so that we
// can read even from threads which won't do a
// sum, and then conditionally assign the result.
int n = __shfl_up_sync(0xffffffff, value, i, 8);
if ((laneId & 7) >= i)
value += n;
}
printf("Thread %d final value = %d\n", threadIdx.x, value);
}
int main() {
scan4<<< 1, 32 >>>();
cudaDeviceSynchronize();
return 0;
}
4.3. Reduction across a warp
#include <stdio.h>
__global__ void warpReduce() {
int laneId = threadIdx.x & 0x1f;
// Seed starting value as inverse lane ID
int value = 31 - laneId;
// Use XOR mode to perform butterfly reduction
for (int i=16; i>=1; i/=2)
value += __shfl_xor_sync(0xffffffff, value, i, 32);
// "value" now contains the sum across all threads
printf("Thread %d final value = %d\n", threadIdx.x, value);
}
int main() {
warpReduce<<< 1, 32 >>>();
cudaDeviceSynchronize();
return 0;
}
边栏推荐
猜你喜欢
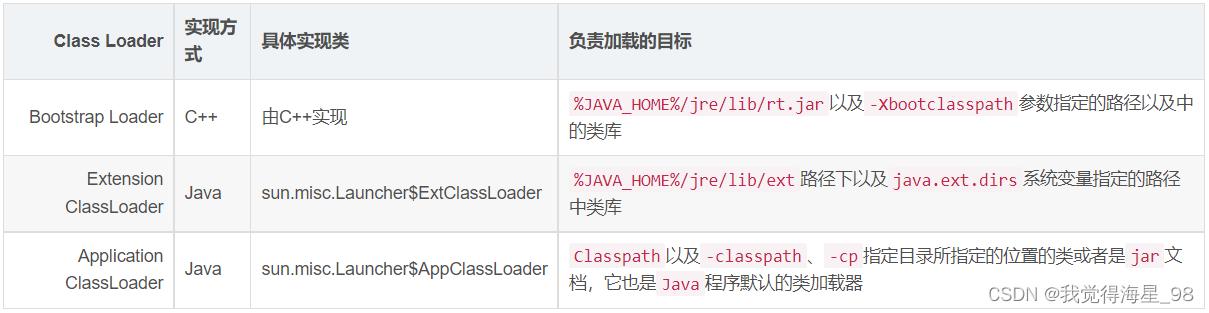
深入学习JVM底层(五):类加载机制

Learn about various joins in SQL and their differences

分布式事务 :可靠消息最终一致性方案

Summary of WLAN related knowledge points

介绍两款代码自动生成器,帮助提升工作效率
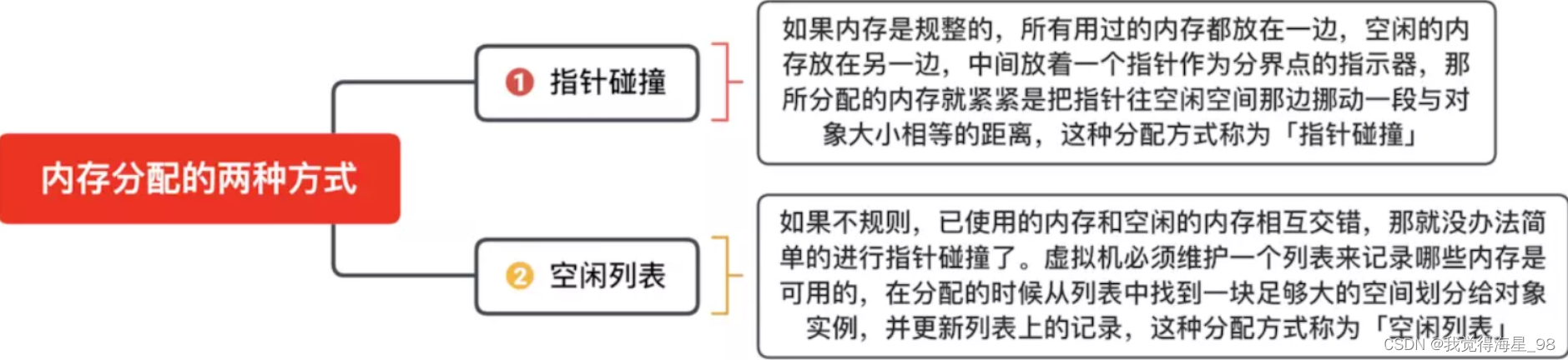
深入学习JVM底层(二):HotSpot虚拟机对象

实习生跑路留了一个大坑,搞出2个线上问题,我被坑惨了

Code skills - Controller Parameter annotation @requestparam

Name six schemes to realize delayed messages at one go
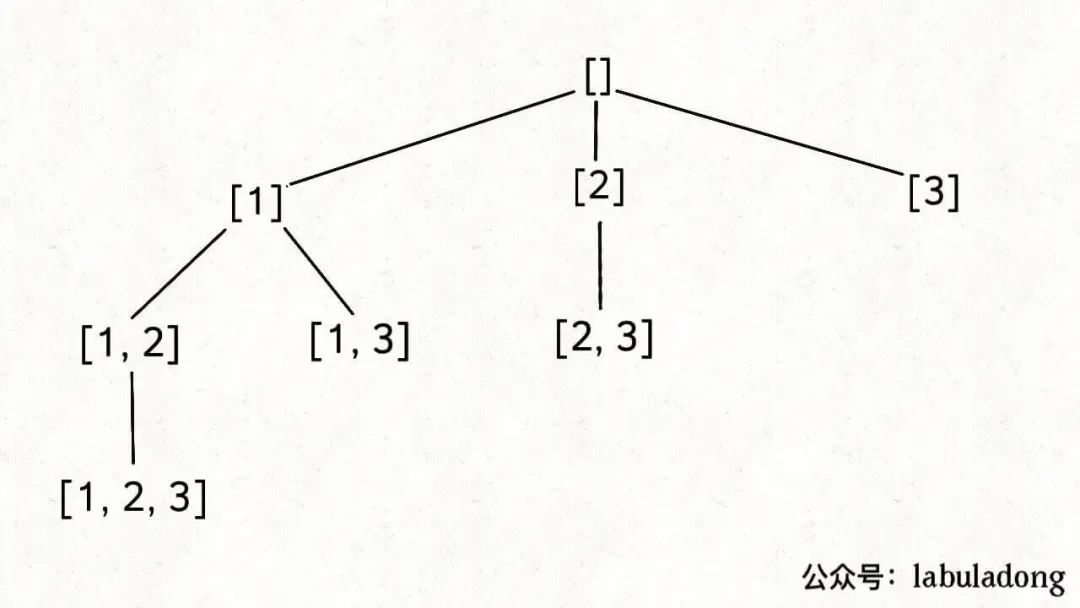
LeetCode 78. subset
随机推荐
CUDA中的Warp Shuffle
Ruijie ebgp configuration case
ShardingSphere-JDBC篇
Eggjs -typeorm 之 TreeEntity 实战
Redis - cluster data distribution algorithm & hash slot
日志 - 7 - 记录一次丢失文件(A4纸)的重大失误
标签属性disabled selected checked等布尔类型赋值不生效?
一口气说出 6 种实现延时消息的方案
WLAN相关知识点总结
The intern left a big hole when he ran away and made two online problems, which made me miserable
virtualenv和pipenv安装
Detailed definition of tensorrt data format
20201002 VS 2019 QT5.14 开发的程序打包
Sentinel 阿里开源流量防护组件
Code skills - Controller Parameter annotation @requestparam
Pbootcms collection and warehousing tutorial quick collection release
奇葩pip install
重载全局和成员new/delete
Idea announced a new default UI, which is too refreshing (including the application link)
LeetCode 40. Combined sum II