当前位置:网站首页>大csv拆分和合并
大csv拆分和合并
2022-07-03 15:29:00 【ASKCOS】
import pandas as pd
import os
import warnings
warnings.filterwarnings('ignore')
class PyCSV:
def merge_csv(self, save_name, file_dir, csv_encoding='utf-8'):
""" :param save_name: 合并后保存的文件名称,需要用户传入 :param file_dir: 需要合并的csv文件所在文件夹 :param csv_encoding: csv文件编码, 默认 utf-8 :return: None """
# 合并后保存的文件路径 = 需要合并文件所在文件夹 + 合并后的文件名称
self.save_path = os.path.join(file_dir, save_name)
self.__check_name()
# 指定编码
self.encoding = csv_encoding
# 需要合并的csv文件所在文件夹
self.file_dir = file_dir
self.__check_dir_exist(self.file_dir)
# 文件路径列表
self.file_list = [os.path.join(self.file_dir, i) for i in os.listdir(self.file_dir)]
self.__check_singal_dir(self.file_list)
# 合并到指定文件中
print("开始合并csv文件 !")
for file in self.file_list:
df = pd.read_csv(file, encoding=self.encoding)
df.to_csv(self.save_path, index=False, quoting=1, header=not os.path.exists(self.save_path), mode='a')
print(f"{
file} 已经被合并到 {
self.save_path} !")
print("所有文件已经合并完成 !")
def split_csv(self, csv_path, save_dir, split_line=100000, csv_encoding='utf-8'):
""" 切分文件并获取csv文件信息。 :param csv_path: csv文件路径 :param save_dir: 切分文件的保存路径 :param split_line: 按照多少行数进行切分,默认为10万 :param csv_encoding: csv文件的编码格式 :return: None """
# 传入csv文件路径和切分后小csv文件的保存路径
self.csv_path = csv_path
self.save_dir = save_dir
# 检测csv文件路径和保存路径是否符合规范
self.__check_dir_exist(self.save_dir)
self.__check_file_exist(self.csv_path)
# 设置编码格式
self.encoding = csv_encoding
# 按照split_line行,进行切分
self.split_line = split_line
print("正在切分文件... ")
# 获取文件大小
self.file_size = round(os.path.getsize(self.csv_path) / 1024 / 1024, 2)
# 获取数据行数
self.line_numbers = 0
# 切分后文件的后缀
i = 0
# df生成器,每个元素是一个df,df的行数为split_line,默认100000行
df_iter = pd.read_csv(self.csv_path,
chunksize=self.split_line,
encoding=self.encoding)
# 每次生成一个df,直到数据全部取玩
for df in df_iter:
# 后缀从1开始
i += 1
# 统计数据总行数
self.line_numbers += df.shape[0]
# 设置切分后文件的保存路径
save_filename = os.path.join(self.save_dir, self.filename + "_" + str(i) + self.extension)
# 打印保存信息
print(f"{
save_filename} 已经生成!")
# 保存切分后的数
df.to_csv(save_filename, index=False, encoding='utf-8', quoting=1)
# 获取数据列名
self.column_names = pd.read_csv(self.csv_path, nrows=10).columns.tolist()
print("切分完毕!")
return None
def __check_dir_exist(self, dirpath):
""" 检验 save_dir 是否存在,如果不存在则创建该文件夹。 :return: None """
if not os.path.exists(dirpath):
raise FileNotFoundError(f'{
dirpath} 目录不存在,请检查!')
if not os.path.isdir(dirpath):
raise TypeError(f'{
dirpath} 目标路径不是文件夹,请检查!')
def __check_file_exist(self, csv_path):
""" 检验 csv_path 是否是CSV文件。 :return: None """
if not os.path.exists(csv_path):
raise FileNotFoundError(f'{
csv_path} 文件不存在,请检查文件路径!')
if not os.path.isfile(csv_path):
raise TypeError(f'{
csv_path} 路径非文件格式,请检查!')
# 文件存在路径
self.file_path_root = os.path.split(csv_path)[0]
# 文件名称
self.filename = os.path.split(csv_path)[1].replace('.csv', '').replace('.CSV', '')
# 文件后缀
self.extension = os.path.splitext(csv_path)[1]
if self.extension.upper() != '.CSV':
raise TypeError(f'{
csv_path} 文件类型错误,非CSV文件类型,请检查!')
def __check_name(self):
""" 检查文件名称是否 .csv 结尾 :return: """
if not self.save_path.upper().endswith('.CSV'):
raise TypeError('文件名称设置错误')
def __check_singal_dir(self, file_list):
""" 检查需要被合并的csv文件所在文件夹是否符合要求。 1. 不应该存在除csv文件以外的文件 2. 不应该存在文件夹。 :return: """
for file in file_list:
if os.path.isdir(file):
raise EnvironmentError(f'发现文件夹 {
file}, 当前文件夹中存其他文件夹,请检查!')
if not file.upper().endswith('.CSV'):
raise EnvironmentError(f'发现非CSV文件:{
file}, 请确保当前文件夹仅存放csv文件!')
if __name__ == '__main__':
# 测试切分
csv_path = r'E:\simple.csv'
save_dir = r'E:\simple_splited_files'
PyCSV().split_csv(csv_path, save_dir, split_line=10000)
# 测试合并
files_dir = r'E:\simple_splited_files'
save_name = r'merge_simple.csv'
PyCSV().merge_csv(save_name, files_dir)
https://zhuanlan.zhihu.com/p/431104537
边栏推荐
- Using Tengine to solve the session problem of load balancing
- 详解指针进阶1
- Kubernetes带你从头到尾捋一遍
- Detailed comments on MapReduce instance code on the official website
- 视觉上位系统设计开发(halcon-winform)-2.全局变量设计
- Puppet automatic operation and maintenance troubleshooting cases
- Introduction to redis master-slave, sentinel and cluster mode
- socket.io搭建分布式Web推送服务器
- Matplotlib drawing label cannot display Chinese problems
- Wechat payment -jsapi: code implementation (payment asynchronous callback, Chinese parameter solution)
猜你喜欢

Solve the problem that pushgateway data will be overwritten by multiple push

Reentrantlock usage and source code analysis

Characteristics of MySQL InnoDB storage engine -- Analysis of row lock
![[cloud native training camp] module 7 kubernetes control plane component: scheduler and controller](/img/a4/2156b61fbf50db65fdf59c8f5538f8.png)
[cloud native training camp] module 7 kubernetes control plane component: scheduler and controller

Jvm-06-execution engine
![[cloud native training camp] module VIII kubernetes life cycle management and service discovery](/img/87/92638402820b32a15383f19f6f8b91.png)
[cloud native training camp] module VIII kubernetes life cycle management and service discovery
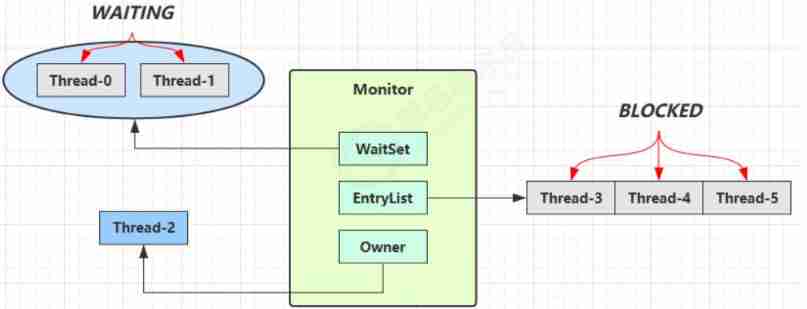
Concurrency-01-create thread, sleep, yield, wait, join, interrupt, thread state, synchronized, park, reentrantlock

函数栈帧的创建和销毁
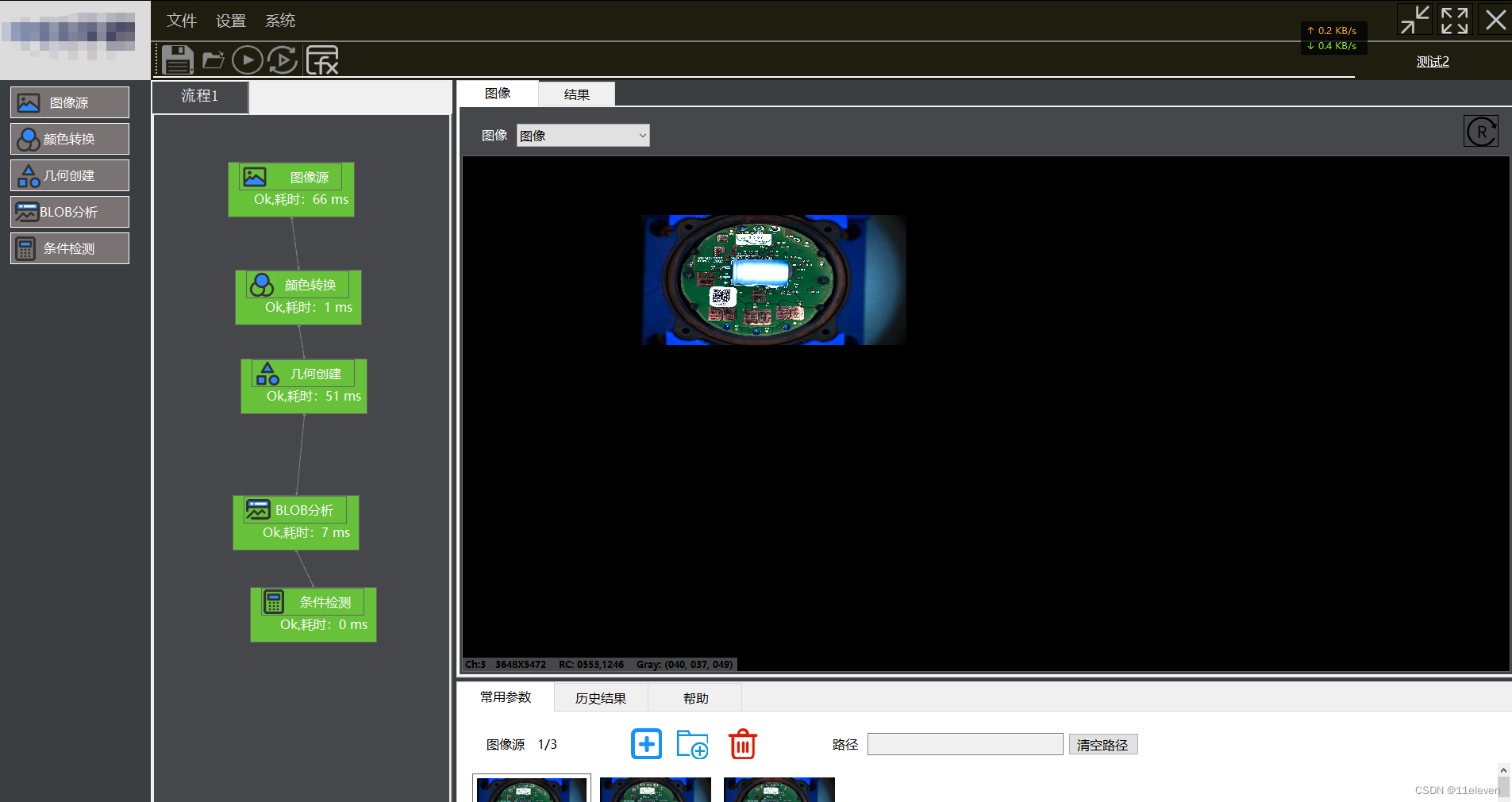
Halcon与Winform学习第二节
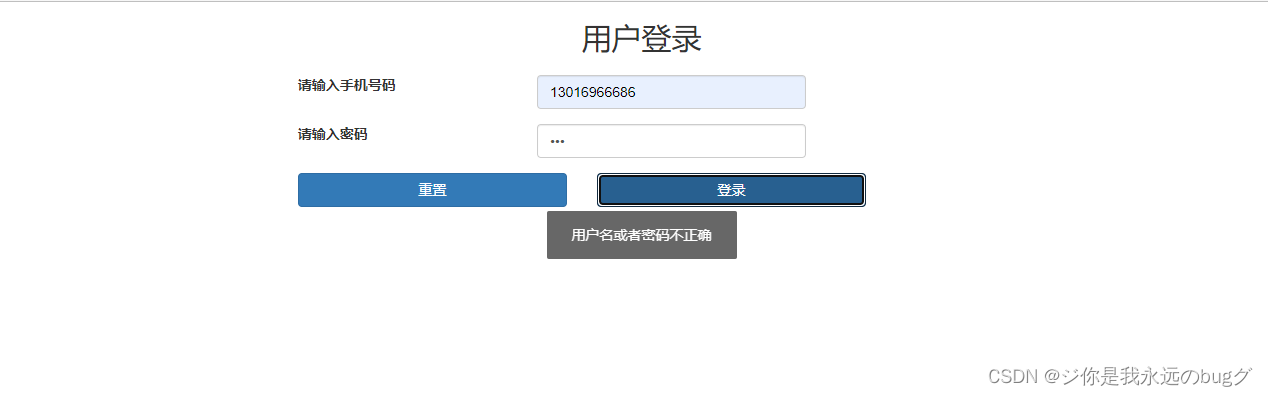
秒杀系统1-登录功能
随机推荐
Custom annotation
Puppet automatic operation and maintenance troubleshooting cases
VS2017通过IP调试驱动(双机调试)
Tensorflow realizes verification code recognition (I)
CString的GetBuffer和ReleaseBuffer使用说明
Concurrency-02-visibility, atomicity, orderliness, volatile, CAS, atomic class, unsafe
Subclass hides the function with the same name of the parent class
GCC cannot find the library file after specifying the link library path
Unity function - unity offline document download and use
Halcon and WinForm study section 1
How are integer and floating-point types stored in memory
Kubernetes - yaml file interpretation
Srs4.0+obs studio+vlc3 (environment construction and basic use demonstration)
Kubernetes - YAML文件解读
Stress test WebService with JMeter
[daily training] 395 Longest substring with at least k repeated characters
Visual upper system design and development (Halcon WinForm) -4 Communication management
WinDbg分析dump文件
Kubernetes带你从头到尾捋一遍
Kubernetes advanced training camp pod Foundation