当前位置:网站首页>Popular understanding of gradient descent
Popular understanding of gradient descent
2022-07-03 15:16:00 【alw_ one hundred and twenty-three】
I have planned to present this series of blog posts in the form of animated interesting popular science , If you're interested Click here .
0. What is the use of gradient descent ?
In fact, gradient descent is not a machine learning algorithm , It's a search based optimization method . Because many algorithms do not have closed form solutions , Therefore, we need to find a set of parameters through iteration after iteration to minimize our loss function . The approximate routine of loss function can be seen in this figure :
So , If we use human words to describe what gradient descent is , Namely ... I keep bathing ( seek ), greasy ( By spectrum ) My elder martial sister ( The weight ) Where is the ( How much is the )..
1. How to search ?
Just now we know that gradient descent is used to find weights , Then how to find the weight pinch ? blind XX Metaphysical guess ? impossible .. It's impossible for metaphysics to guess in this life . Just think about it , The value range of weight can be regarded as a real number space , that 100 These characteristics correspond to 100 A weight ,10000 These characteristics correspond to 10000 A weight . If you rely on blindness XX If metaphysics guesses the weight . Um. , I should never guess it in my life . So find a routine to find the weight . This routine is gradient !!!
So what is the gradient ? If the formula comes out, it is maozi :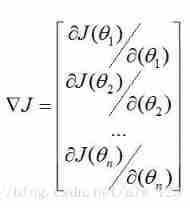
Um. .. Is it familiar to you , If translated into Chinese, it is maozi :
At this time, the gradient can be clearly seen , It's nothing more than calculating the partial derivative of the weight to the loss function and arranging it into a vector . And the gradient has another property , That is, the gradient direction is the direction in which the function value increases fastest . How to understand this property ? Take a chestnut . If I am a person who wants to be LOL The dead fat house of the suburban King , Then there may be several factors to become the king of the suburbs , One is the depth of the hero pool , One is the overall view , There is also a Sao operation . They all have a certain weight for me to become a king . As shown in the figure , The arrow of each factor has a direction ( That is, the partial direction of factors for me to become king ) And length ( The size of the value of the partial derivative ). Then under the joint action of these factors , I will eventually train in one direction ( For example, the relationship between component force and resultant force in Physics ), At this time, I can go further to the king of the suburbs as soon as possible .
That is to say, if I keep working towards the final direction , Theoretically, I can become the king of the suburbs as soon as possible .
OK. Now we know that the direction of gradient is the fastest growing direction of function , Then I'll take a minus sign in front of the gradient ( In the opposite direction ), That's the fastest direction of function decline .( You can still make up your brain by yourself according to the picture of suburban King = =) So WOW , The essence of gradient descent is nothing more than updating the weight in the opposite direction of the gradient . Like the following figure , If I were blind , And then somehow came to a valley . Now all I have to do is go to the bottom of the valley . Because I'm blind , So I can only move little by little . If you want to move , Then I must sweep my feet around me , Where I feel more like going down the mountain, I'll go there . Then I can finally reach the bottom of the valley by repeating this cycle .
So le , Follow this routine , We can roll out the pseudo code of gradient descent :
Cycling is equivalent to walking down the mountain , In code α Pretending to force is called learning rate , In fact, it represents how big my step is when I go down the mountain . The smaller the value is, the more I want to , Take small steps , I'm afraid of falling into the pit . The higher the value, the more coquettish I am , But it's easy to pull eggs ~~
OK. This is my popular understanding of gradient descent , I hope it can help you .
边栏推荐
- 【Transformer】入门篇-哈佛Harvard NLP的原作者在2018年初以逐行实现的形式呈现了论文The Annotated Transformer
- "Seven weapons" in the "treasure chest" of machine learning: Zhou Zhihua leads the publication of the new book "machine learning theory guide"
- redis单线程问题强制梳理门外汉扫盲
- Redis lock Optimization Practice issued by gaobingfa
- 视觉上位系统设计开发(halcon-winform)-4.通信管理
- Global and Chinese market of Bus HVAC systems 2022-2028: Research Report on technology, participants, trends, market size and share
- Yolov5系列(一)——网络可视化工具netron
- 视觉上位系统设计开发(halcon-winform)
- Characteristics of MySQL InnoDB storage engine -- Analysis of row lock
- 官网MapReduce实例代码详细批注
猜你喜欢

B2020 points candy
![[set theory] inclusion exclusion principle (complex example)](/img/9a/db5a75e27516378c31531773a8a221.jpg)
[set theory] inclusion exclusion principle (complex example)

Jvm-06-execution engine

【可能是全中文网最全】pushgateway入门笔记
![[cloud native training camp] module VIII kubernetes life cycle management and service discovery](/img/87/92638402820b32a15383f19f6f8b91.png)
[cloud native training camp] module VIII kubernetes life cycle management and service discovery

Idea does not specify an output path for the module
Redis主从、哨兵、集群模式介绍

What are the composite types of Blackhorse Clickhouse, an OLAP database recognized in the industry
Tencent internship interview sorting
Redis cache penetration, cache breakdown, cache avalanche solution
随机推荐
Global and Chinese market of iron free motors 2022-2028: Research Report on technology, participants, trends, market size and share
The state does not change after the assignment of El switch
视觉上位系统设计开发(halcon-winform)-1.流程节点设计
Influxdb2 sources add data sources
运维体系的构建
Concurrency-02-visibility, atomicity, orderliness, volatile, CAS, atomic class, unsafe
Global and Chinese markets of AC electromechanical relays 2022-2028: Research Report on technology, participants, trends, market size and share
官网MapReduce实例代码详细批注
Jvm-08-garbage collector
开启 Chrome 和 Edge 浏览器多线程下载
Chapter 04_ Logical architecture
Yolov5系列(一)——网络可视化工具netron
There are links in the linked list. Can you walk three steps faster or slower
Incluxdb2 buckets create database
SQL server installation location cannot be changed
Analysis of development mode process based on SVN branch
百度智能云助力石嘴山市升级“互联网+养老服务”智慧康养新模式
Yolov5 advanced seven target tracking latest environment construction (II)
Yolov5 advanced nine target tracking example 1
Explanation of time complexity and space complexity