当前位置:网站首页>全尺度表示的上下文非局部对齐,南科大&优图提出NAFS解决基于文本的Re ID
全尺度表示的上下文非局部对齐,南科大&优图提出NAFS解决基于文本的Re ID
2022-08-03 17:31:00 【FightingCV】

【写在前面】
基于文本的人物搜索旨在使用人物的描述性句子在图像库中检索目标人物。这是一个非常具有挑战性的问题,因为模态差异使得有效提取鉴别特征更加困难。此外,行人图像和描述的类间方差很小。因此,需要综合信息来在所有尺度上对齐视觉和文本线索。大多数现有方法仅考虑单个尺度(例如仅全局尺度或仅部分尺度)内图像和文本之间的局部对齐,或仅在每个尺度上单独构建对齐。为了解决这个问题,作者提出了一种能够跨所有尺度自适应对齐图像和文本特征的方法,称为NAFS(即全尺度表示的非局部对齐)。首先,提出了一种新的阶梯网络结构来提取局部性更好的全尺度图像特征。其次,提出了一种局部注意力训练的BERT,以获得不同尺度下的描述表示。然后,不是在每个尺度上单独对齐特征,而是应用一种新的上下文非局部注意机制来同时发现所有尺度上的潜在对齐。实验结果表明,在基于文本的个人搜索数据集上,本文的方法在top-1和top-5方面分别优于最先进的方法5.53%和5.35%。
1. 论文和代码地址

Contextual Non-Local Alignment over Full-Scale Representation for Text-Based Person Search
论文地址:https://arxiv.org/abs/2101.03036[1]
代码地址:https://github.com/TencentYoutuResearch/PersonReID-NAFS[2]
2. Motivation
基于文本的人物搜索旨在使用人物的描述性句子在图像库中检索目标人物。与经典的人物再识别(Reid)相比,它不需要目标人物的图像作为查询。此外,基于文本的人员搜索更易于用户使用,因为它可以支持开放式自然语言查询。因此,它具有更广泛的应用潜力。
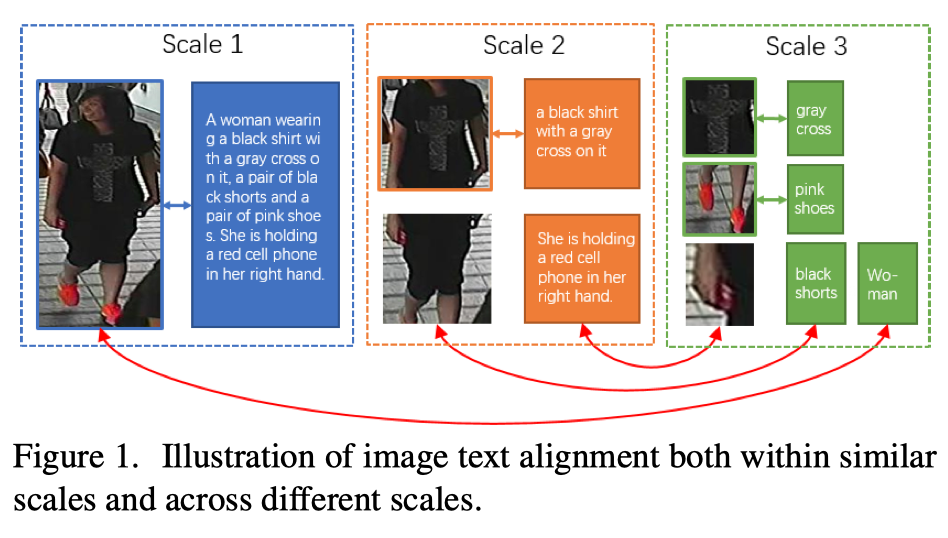
与一幅图像可能包含多个对象的一般图像-文本匹配任务相比,基于文本的人员搜索是一项更具挑战性的任务,因为不同行人图像之间的高层语义非常相似,导致行人图像和文本描述的类间差异很小。因此,为了探索更有特色和更全面的信息,基于文本的人搜索需要一种算法来从所有尺度中提取图像和文本特征。例如,上图中的图像和文本描述都可以分解为不同比例的表示。这个句子可以用短句来表示,例如在3级的“黑色短裤”,或者在2级的更长的子句。类似地,图像也可以按比例3和比例2划分为不同大小的子区域。由于这些图像表示和文本表示之间的正确对齐是图像-文本匹配任务的基础,因此必须在所有尺度上表示图像和文本描述。在本文中,作者称之为全尺度表示。然而,不同尺度下的复杂相关性使得很难建立合理的对齐方案。如上图所示,在大多数情况下,对齐发生在相似的比例下,例如子句“一件黑色衬衫,上面有一个灰色十字架”和比例2中的图像区域。但偶尔也会在不同的尺度上发生对齐。例如,如上图中的红色箭头所示,比例3中的单个单词“woman”与比例1中的整个图像对齐。这些现象说明了在相似尺度和不同尺度下联合对齐图像和描述的重要性。因此,一种合理的基于文本的人员搜索方法通常包含两个关键部分。一个是以从粗到细的方式学习所有尺度下的图像和文本表示,另一个是探索适当的对齐方式,以自动和自适应地匹配这些不同尺度的表示。
现有的大多数作品无法完全满足上述两个角度。一方面,对于多尺度表示,大多数方法仅在一定尺度上学习图像和文本描述的表示。几种粗粒度方法侧重于在全局尺度上学习表示,即上图比例1所示的整个图像和句子。细粒度方法以最小比例对图像和文本描述进行建模,例如上图比例3中所示的图像区域和短短语。尽管一些细粒度方法[考虑将最小尺度与全局尺度相结合,但它们仍然缺乏中尺度信息,导致一些描述段(图像区域)无法与适当的图像区域(描述段)正确对齐。
另一方面,对于跨尺度对齐,现有方法尝试使用预先定义的规则来对齐不同尺度的图像和文本描述。一些方法只考虑图像和文本描述的全局匹配。其他一些方法添加了短短语和图像区域之间的对齐,如图1比例3所示,但忽略了不同比例之间的对齐。最近,一些方法进一步增加了整个图像和短句之间的额外对齐,以及小图像条纹和整个句子之间的对齐。这些方法表明,利用多尺度特征可以显著提高性能。然而,它们都预先定义了不同尺度(例如全局-全局、局部-局部)的图像表示和文本表示之间的几种对齐规则,并分别在这些固定尺度对内建立对齐。因此,它将对齐限制在一定范围内,导致完全忽略比例对之外的图像表示和文本表示之间的对齐。
为了解决上述问题,在本文中,作者提出了一种新的基于文本的人员搜索方法,该方法为图像和文本表示构建全尺度表示,并在所有尺度上自适应对齐它们,称为NAFS(全尺度表示上的非局部对齐)。首先,作者提出了一种新的阶梯网络将更好的局部性结合到学习的全尺寸图像特征中的条纹分割操作。然后,通过添加局部约束注意的改进BERT语言模型来提取全尺度文本特征。接下来,作者开发了一种更灵活的对齐机制,称为语境非局部注意,它能够联合将所有尺度的图像表示和文本表示作为输入,然后自适应地在所有尺度上建立对齐,而不是在几个预先定义的尺度下对齐特征(例如,局部-局部、全局-全局)。最后,提出了一种新的基于最近视觉邻域的重新排序算法,以进一步提高排序质量。
本文的主要贡献可以总结如下:(1)专门开发了一种新的阶梯CNN网络和局部约束BERT模型来提取全尺度图像和文本表示。(2) 提出了一种上下文非局部注意机制,用于在所有尺度上自适应对齐学习的表示。(3) 该框架在具有挑战性的数据集CUHK-PEDES上实现了最先进的结果。广泛的消融研究清楚地证明了本文方法中每个成分的有效性。
3. 方法
在本节中,首先,作者介绍了提取视觉和文本表示的过程。然后作者描述了本文的语境非局部注意机制。最后,作者介绍了所提出的通过视觉邻居重新排序的方法,以进一步提高性能。
3.1. 提取视觉表示
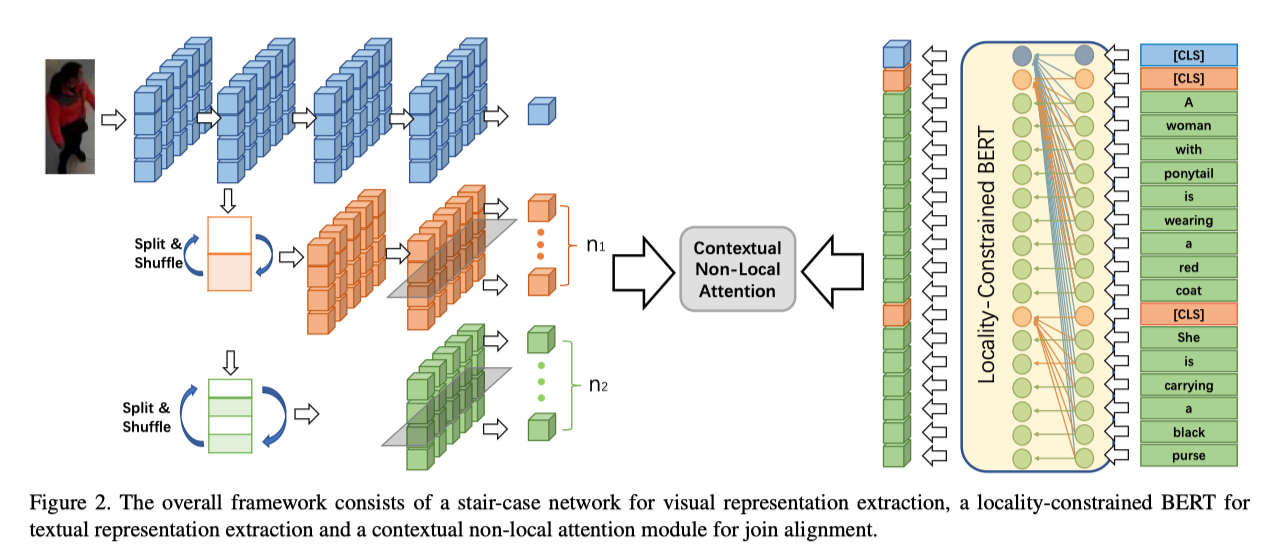
楼梯主干结构
首先,作者详细阐述了所提出的楼梯网络的实现细节。如上图所示,它包含三个分支,每个分支负责从粗到细提取不同尺度的视觉特征,即全局分支(蓝色)、区域分支(黄色)和patch分支(绿色)。一般的ResNet网络用作主干网。1) 全局分支用于提取全局和最粗糙的特征。2) 区域分支从图像中的大子区域中提取内部特征。它将全局分支第二阶段的特征映射作为输入,然后输入到两个连续的res块中,在区域尺度上提取特征。然后将区域分支的输出特征映射水平分割为个条带,每个条带进一步编码为特定区域的局部特征。3) patch分支从图像中的小patch中提取最新特征。它将全局分支第三阶段的特征图作为输入,然后将其输入到一个res块中,以在小patch尺度上提取特征。然后,作者将输出的特征图水平分割成条条纹,以提取局部patch的个特征向量。
拆分和shuffle操作
基于条带的ReID模型面临的一个挑战是,由于CNN模型的感知域很大,深层特征图的条带可能也包含全局信息。因此,为了保证多尺度图像特征具有更好的局部性,作者引入了一种新的分割&shuffle操作。它将中间特征映射作为输入,然后将特征映射平均划分为几个水平条带,表示为列表,其中是从特征映射顶部开始的第i个条带。然后,对这组分区条纹沿纵轴进行随机分解和重新连接形成完整的特征图作为输出。第2阶段和第3阶段的特征图将在分别输入范围和patch分支之前首先分割和细化。通过随机分割条纹,它可以打破连续条纹之间的相互关系,使模型能够专注于每个条纹内的信息。由于本文的上下文非局部注意力不依赖于特征图片段的顺序,因此没有必要将分割的条纹重新组织为原始顺序。
视觉表征提取模块将行人图像作为输入,然后可以获得不同尺度的图像特征列表,并将其表示为,其中。
3.2. 提取文本表示
给定文本描述,作者在BERT中添加局部约束以提取的不同尺度表示。在本文的方法中,文本描述将分别在三个尺度中表示。1) 在句子层面,作者在句子的开头添加了一个特殊的分类token([CLS])。与该token对应的最终隐藏状态可以用作整个句子在全局视图中的句子层面表示。2) 在中间层,作者用逗号分隔句子,从而得到一系列较短的子句子。对于列表中的每个子句,[CLS] token也附加到子句的开头,其最终隐藏状态也用作每个子句的表示。3) 在词级,每个词的最终隐藏状态直接用作词级表示。
对于常见的基于BERT的模型,所有token的隐藏变量具有相同的全局感知场。每个token都可以处理整个输入句子中的任何token。为了为句子中的子区域表示(子句子的[CLS]标记)提供局部性,作者提出了一个局部性约束注意模块来关注一定范围内的token。与原始BERT类似,假设查询对应于子实体(表示为)的[CLS] token,局部约束注意力计算如下:
其中和分别表示对应于句子中所有token的键和值。U是该子句子范围内的token集,是一个指示函数,当第i个token在U中时返回1。
文本表示提取模块将行人描述作为输入,然后可以获得不同尺度的文本嵌入列表,并表示为,其中。
3.3. 语境非局部注意机制
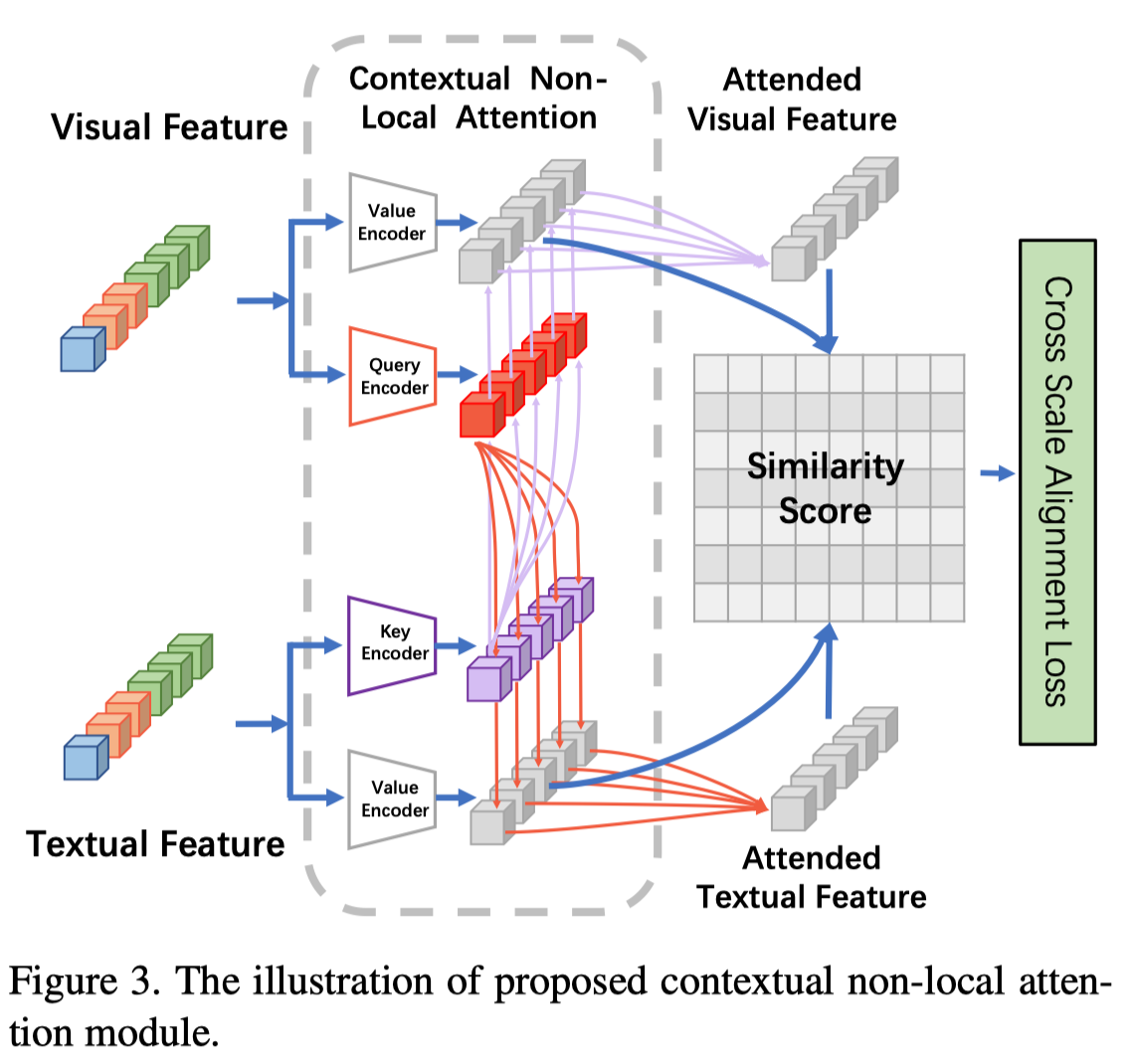
如上图所示,语境非局部注意需要两个输入:一组视觉特征和一组文本特征。注意力模块的输出是衡量图像-文本对相关性的相似性分数。简言之,语境非局部注意使跨模态特征能够根据其语义以从粗到细的方式相互对齐,而不仅仅是使用预先定义和固定的规则(例如,局部-局部、全局-全局)。
受自注意力的启发,作者可以将本文提出的注意力机制解释为将查询和一组键值对映射到输出。对于视觉特征,使用两个学习的线性投影将I映射到视觉查询和视觉值。类似地,探索了两个线性投影,以将T映射到文本键和文本值。基于,作者从图像-文本和文本-图像两个方面介绍了本文提出的注意机制。
图像-文本上下文非局部注意
提出的图像-文本注意模块包括两个阶段。首先,每个视觉查询关注文本键,以获得相应的关注文本值。然后,考虑所有视觉值及其相关文本值,可以确定图像-文本对之间的相似性。具体来说,为了获得关注的文本值,作者首先计算和的余弦相似矩阵以获得上的权重:
其中,表示第a个视觉查询和第b个文本键之间的相似性。此外,作者将其归一化为。此外,为了滤除不相关的文本值,作者使用焦点注意力技巧,其中。然后,作者计算加权文本值为:
其中是softmax函数的inverse temperature。
在第二阶段,作者利用和之间的余弦相似性确定视觉值与其相应文本语境之间的相关性:
通过平均所有,得到图像-文本对的相似性为:
每个视觉特征都更加关注相关的文本特征。相关的文本特征可能来自一个单词、一个短语或整个句子,这仅仅取决于视觉特征和文本特征是否具有相似的语义。相反,以前的方法倾向于以固定的方式建立对应关系。作者通过启用基于语义的注意机制来建立跨不同尺度的对应关系,从而放松了这些约束,这有助于更自适应、更正确地对齐图像-文本对。
文本-图像上下文非局部注意
与图像-文本上下文非局部注意类似,作者分别将文本键视为查询和视觉查询视为键,并针对视觉查询关注文本键。然后,利用文本值和关注的视觉值,计算图像-文本对之间的相似性。具体而言,第b个视觉值相对于第a个文本值的权重定义为。归一化和聚焦加权定义为。
加权视觉值定义为。
使用加权视觉值 和文本值,作者计算他们的相似度。然后通过平均操作获得他们最终的相似度。
对齐目标
作者引入了一个名为跨尺度对齐损失(CSAL)的目标函数来优化该算法。给定一batch图像,标题和所有图像-文本对,如果是匹配对,则,否则为0,作者将的图像-文本相似性定义为,将文本-图像相似性定义为。为了最大化匹配对之间的相似性并抑制不匹配对的作者将CSAL定义为:
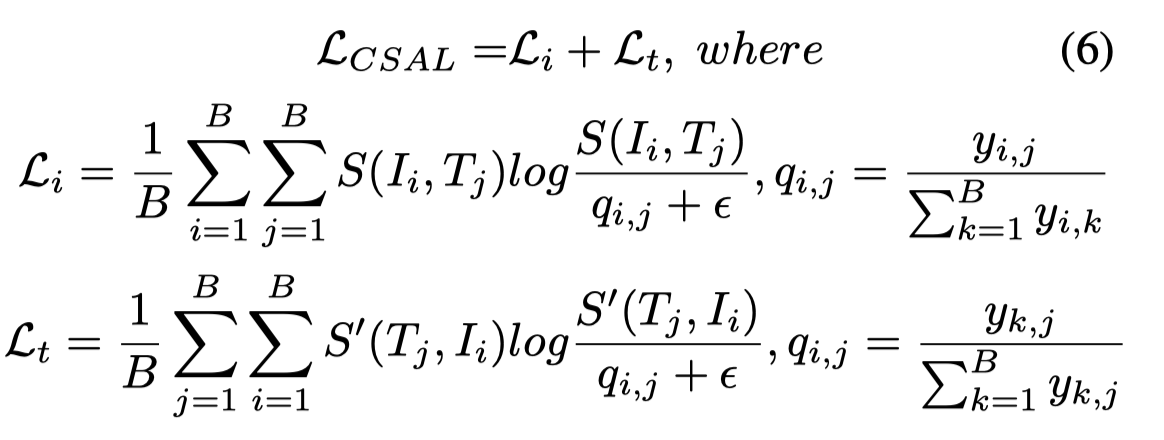
其中表示一个小数字,以避免数值问题。
考虑到主干对多尺度特征至关重要,作者使用的跨模态投影匹配(CMPM)和跨模态投影分类(CMPC),通过在从全局分支提取的特征上添加CMPM和CMPC损失来稳定训练过程。因此,最终目标函数为:
3.4. 按视觉邻居重新排序
作者提出了一种多模态重新排序算法,通过将查询的视觉邻居与库(RVN)进行比较来进一步提高性能。给定文本查询T,根据图像与查询的相似性对图像进行排序,从而获得初始排名列表。然后,对于初始列表中的每个图像I,作者根据其视觉表示的相似性获得其l-最近邻图像,表示为。类似地,可以基于文本表示和图像视觉表示之间的相似性来获得文本查询的最近邻,表示为。在这里,为了加速计算,仅使用全局特征来查找最近邻。然后,作者通过比较最近的邻居和Jaccard距离,重新计算文本查询和图库中每个图像之间的成对相似性:
最后,根据原始相似度和Jaccard距离的平均分数对库进行重新排序。
4.实验
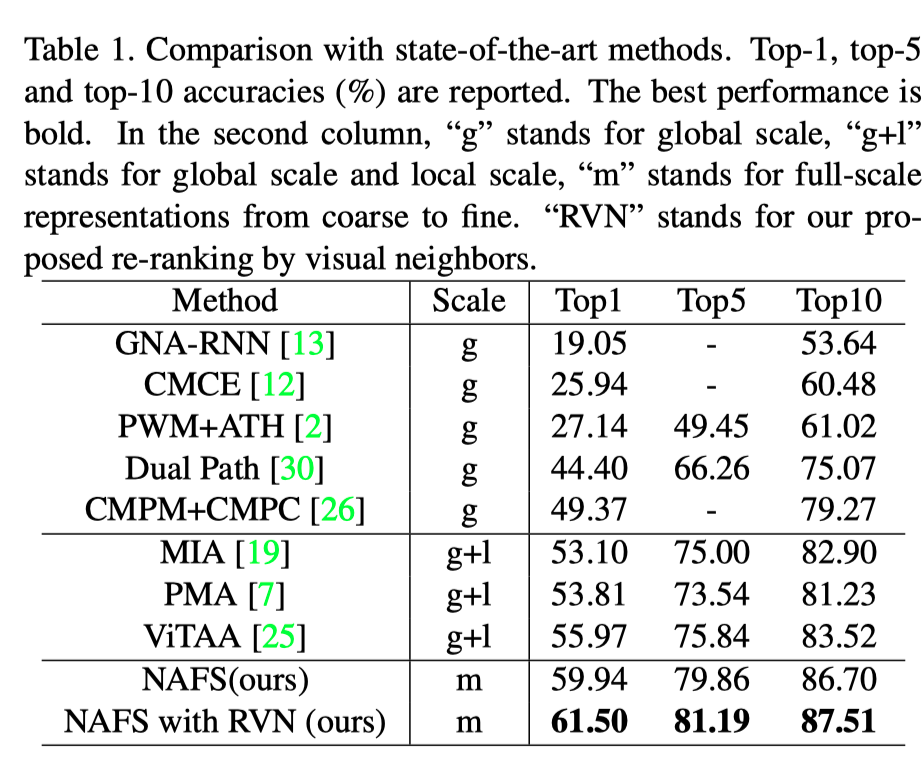
上表展示了本文方法在显示了本文的结果与最先进的方法在CUHK-PEDES上的比较。

上表显示了在不同尺度下使用表示的性能。添加局部信息后,Top1性能从55.47提高到56.90。添加中等规模信息后,top1性能从56.90提高到59.94。这意味着不同的比例信息有利于对齐过程。
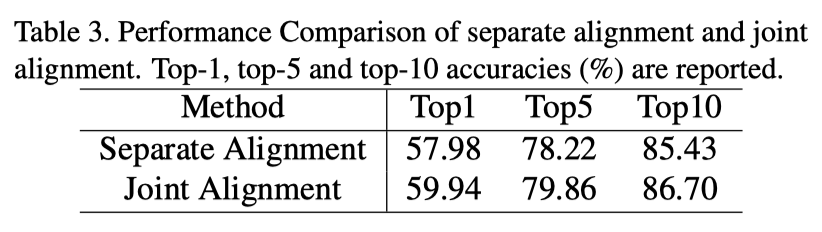
为了验证在不同尺度下将联合对齐引入表示的有效性,作者在上表中将本文的联合对齐与使用预定义对齐的方法进行了比较。
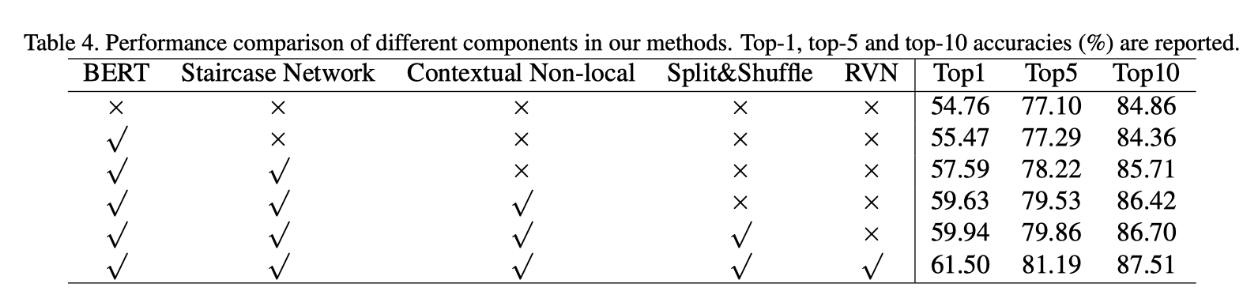
上表展示了本文提出的不同模块的有效性的消融实验结果。
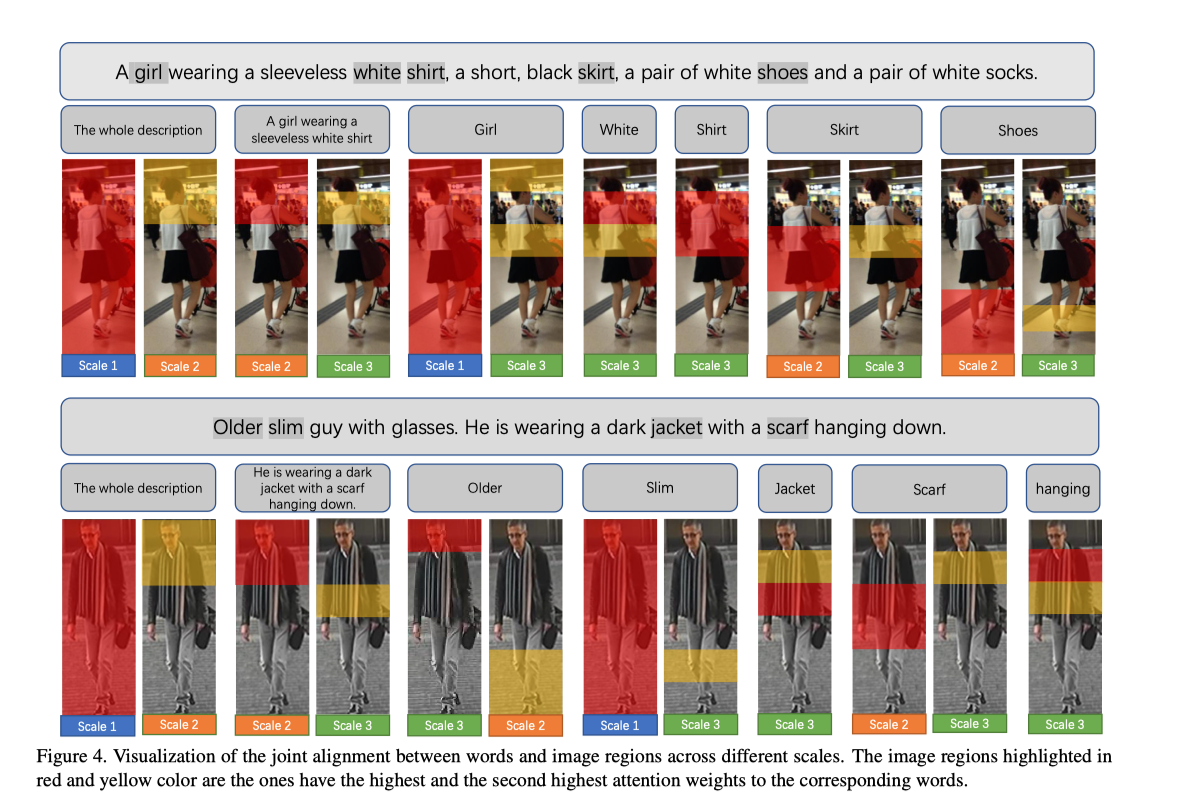
为了证明NAFS在不同尺度下发现联合对齐的能力,作者在不同尺度下可视化了文本描述和图像区域之间的对齐结果,如上图所示。为了更好地可视化所提出的上下文非局部注意机制,作者在区域分支中将输出特征图水平划分为三条条纹,在patch分支中划分为六条条纹分别地用红色和黄色高亮显示的图像区域对相应的文本描述具有最高和第二高的注意力权重。对于注意力权重相似的两个子区域,这两个子区域都将突出显示。
5. 总结
作者提出了一种新颖的基于文本的人员搜索方法,该方法可以对称为NAFS的全尺寸表示进行联合对齐。提出了一种新颖的楼梯CNN网络和局部受限的BERT模型来提取多尺度图像和文本表示。上下文的非局部注意机制自适应地调整了不同尺度上的学习表示。对CUHK-PEDES数据集的广泛消融研究表明,我们的方法在很大程度上优于最先进的方法。
已建立深度学习公众号——FightingCV,欢迎大家关注!!!
ICCV、CVPR、NeurIPS、ICML论文解析汇总:https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading
面向小白的Attention、重参数、MLP、卷积核心代码学习:https://github.com/xmu-xiaoma666/External-Attention-pytorch
加入交流群,请添加小助手wx:FightngCV666
参考资料
https://arxiv.org/abs/2101.03036: https://arxiv.org/abs/2101.03036
[2]https://github.com/TencentYoutuResearch/PersonReID-NAFS: https://github.com/TencentYoutuResearch/PersonReID-NAFS
边栏推荐
猜你喜欢
After using Stream for many years, does collect still have these "saucy operations"?

【指针初解】

PTA递归练习

The strongest distributed lock tool: Redisson

Cool open technology x StarRocks: unified OLAP analysis engine, comprehensive building digital model of OTT
11. Container With Most Water
CC2530_ZigBee+华为云IOT:设计一套属于自己的冷链采集系统
酷开科技 × StarRocks:统一 OLAP 分析引擎,全面打造数字化的 OTT 模式
多表查询最值

云图说丨初识华为云微服务引擎CSE
随机推荐
精酿啤酒品牌,过把瘾就死?
How ArkUI adapter somehow the screen
基于DMS的数仓智能运维服务,知多少?
为什么我用了Redis之后,系统的性能却没有提升
Interpretation of the paper (JKnet) "Representation Learning on Graphs with Jumping Knowledge Networks"
国内首发可视化智能调优平台,小龙带你玩转KeenTune UI
【机器学习】机器学习的基本概念/术语2
PTA递归练习
每周推荐短视频:为了填补学习资源的空缺,作者专门写了本书?
IP属地如何高效率识别
【时间的比较】
102. 最佳牛围栏
出海,是泡泡玛特的“解药”吗?
ThreeJS简介
003_Kubernetes核心技术
383. Ransom Note
分享一个开源的USB-CAN工具!
【目标检测】Focal Loss for Dense Object Detection
【云驻共创】【HCSD大咖直播】亲授大厂面试秘诀
如何避免无效的沟通