当前位置:网站首页>IP属地如何高效率识别
IP属地如何高效率识别
2022-08-03 17:01:00 【欧菲斯集团】
概述
IP属地显示各大平台已经有更新,抖音、今日头条、知乎、小红书等,作为一个技术,如果实现获取IP属地呢,正好近期需要做一个IP属地跳转,识别IP的归属地如果单纯的靠调用接口获取属地信息在效率上难以保证,因此给大家分享一个强大的离线IP地址定位库ip2region获取IP归属地。

获取IP属地那么重要的步骤就是获取IP地址,怎么获取ip地址呢?
获取用户ip地址
HttpServletRequest 获取 IP
/**
* 获取ip地址
*/
public static String getIpAddress(HttpServletRequest request) {
String ip = request.getHeader("x-forwarded-for");
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("Proxy-Client-IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("WL-Proxy-Client-IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("HTTP_CLIENT_IP");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getHeader("HTTP_X_FORWARDED_FOR");
}
if (ip == null || ip.length() == 0 || "unknown".equalsIgnoreCase(ip)) {
ip = request.getRemoteAddr();
}
// 本机访问
if ("localhost".equalsIgnoreCase(ip) || "127.0.0.1".equalsIgnoreCase(ip) || "0:0:0:0:0:0:0:1".equalsIgnoreCase(ip)){
// 根据网卡取本机配置的IP
InetAddress inet;
try {
inet = InetAddress.getLocalHost();
ip = inet.getHostAddress();
} catch (UnknownHostException e) {
e.printStackTrace();
}
}
// 对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
if (null != ip && ip.length() > 15) {
if (ip.indexOf(",") > 15) {
ip = ip.substring(0, ip.indexOf(","));
}
}
return ip;
}
通过此方法,从请求 Header 中获取到用户的 IP 地址。
获取IP归属地的方法
1、在线方式
我们可以 通过一些网络接口获取IP的归属地,例如ip.taobao.com淘宝ip地址库来获取,
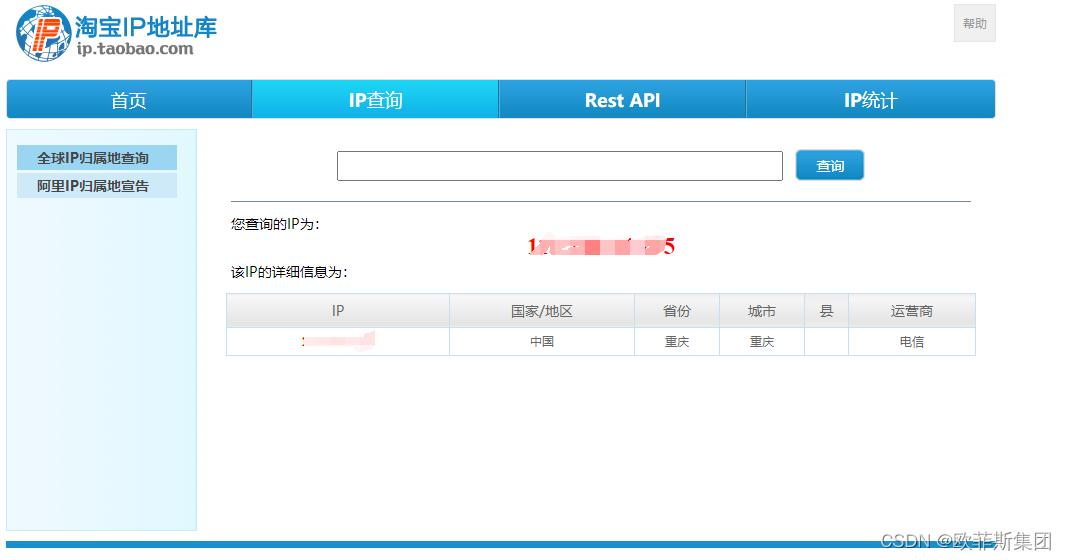
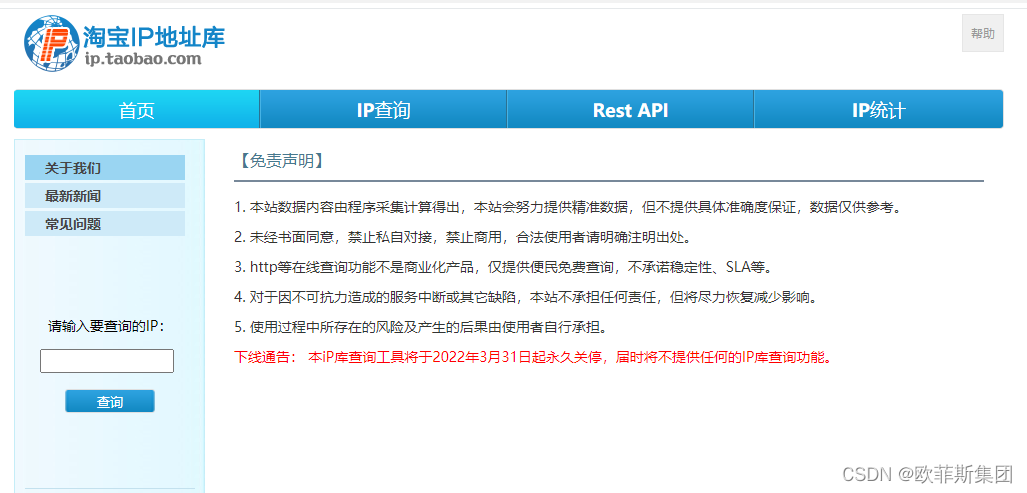
但是今天我进入淘宝ip地址库看到2022年3月31日起永久关停,如果我们使用在线的ip地址查询接口的时候也是需要防止对方接口停用到带来的损失,因此我们还有其它的方式获取ip地址属地吗?,答案是有的。
2、离线获取IP地址属地库---Ip2region
1、Ip2region 是什么
ip2region v2.0 - 是一个离线IP地址定位库和IP定位数据管理框架,10微秒级别的查询效率,提供了众多主流编程语言的 xdb 数据生成和查询客户端实现。v1.0 旧版本: v1.0版本入口
github 地址:https://github.com/lionsoul2014/ip2region
2、Ip2region 特性
标准化的数据格式、数据去重和压缩、极速查询响应、IP 数据管理框架,使用固定的 512KiB 的内存空间缓存 vector index 数据,减少一次 IO 磁盘操作,保持平均查询效率稳定在10-20微秒之间。并且准确率达到惊人的99.9% 准确率
3、最新版本
目前最新已更新到了 v2.0 版本,ip2region v2.0 是一个离线 IP 地址定位库和 IP 定位数据管理框架,10 微秒级别的查询效率,准提供了众多主流编程语言的 xdb 数据生成和查询客户端实现。
4、多查询客户端的支持

5、ip2region xdb java 查询客户端实现
1)maven 仓库引入
<dependency>
<groupId>org.lionsoul</groupId>
<artifactId>ip2region</artifactId>
<version>2.6.5</version>
</dependency>2)下载离线IP库
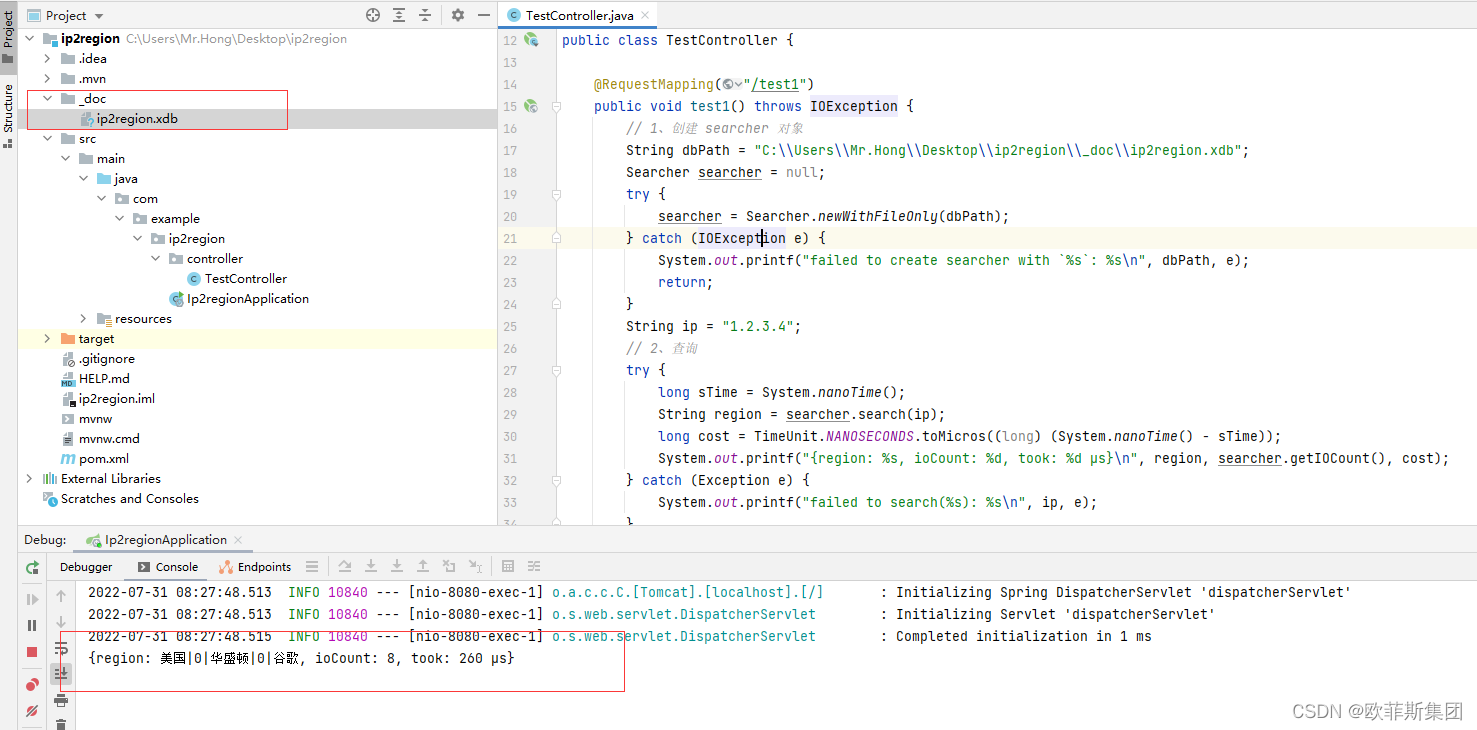
3)完全基于文件的查询
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
// 1、创建 searcher 对象
String dbPath = "ip2region.xdb file path";
Searcher searcher = null;
try {
searcher = Searcher.newWithFileOnly(dbPath);
} catch (IOException e) {
System.out.printf("failed to create searcher with `%s`: %s\n", dbPath, e);
return;
}
String ip = "1.2.3.4";
// 2、查询
try {
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 3、关闭资源
searcher.close();
// 备注:并发使用,每个线程需要创建一个独立的 searcher 对象单独使用。
}
}
}
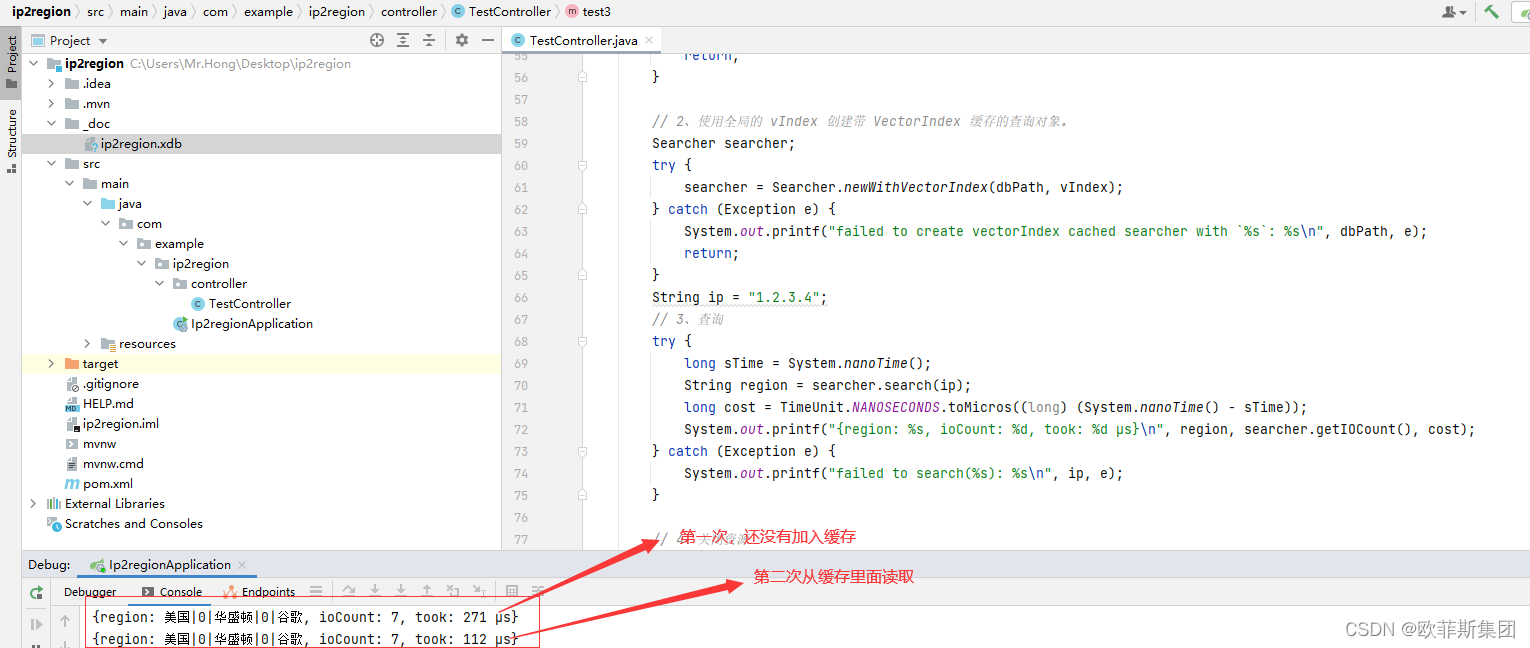
4)缓存 VectorIndex 索引
全局缓存,每次创建 Searcher 对象的时候使用全局的 VectorIndex 缓存可以减少一次固定的 IO 操作,从而加速查询,减少 IO 压力。
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
String dbPath = "ip2region.xdb file path";
// 1、从 dbPath 中预先加载 VectorIndex 缓存,并且把这个得到的数据作为全局变量,后续反复使用。
byte[] vIndex;
try {
vIndex = Searcher.loadVectorIndexFromFile(dbPath);
} catch (Exception e) {
System.out.printf("failed to load vector index from `%s`: %s\n", dbPath, e);
return;
}
// 2、使用全局的 vIndex 创建带 VectorIndex 缓存的查询对象。
Searcher searcher;
try {
searcher = Searcher.newWithVectorIndex(dbPath, vIndex);
} catch (Exception e) {
System.out.printf("failed to create vectorIndex cached searcher with `%s`: %s\n", dbPath, e);
return;
}
String ip = "1.2.3.4";
// 3、查询
try {
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 4、关闭资源
searcher.close();
// 备注:每个线程需要单独创建一个独立的 Searcher 对象,但是都共享全局的制度 vIndex 缓存。
}
}
5)缓存整个 xdb 数据
预先加载整个 ip2region.xdb 的数据到内存,然后基于这个数据创建查询对象来实现完全基于文件的查询
import org.lionsoul.ip2region.xdb.Searcher;
import java.io.*;
import java.util.concurrent.TimeUnit;
public class SearcherTest {
public static void main(String[] args) {
String dbPath = "C:\\Users\\Mr.Hong\\Desktop\\ip2region\\_doc\\ip2region.xdb";
// 1、从 dbPath 加载整个 xdb 到内存。
byte[] cBuff;
try {
cBuff = Searcher.loadContentFromFile(dbPath);
} catch (Exception e) {
System.out.printf("failed to load content from `%s`: %s\n", dbPath, e);
return;
}
// 2、使用上述的 cBuff 创建一个完全基于内存的查询对象。
Searcher searcher;
try {
searcher = Searcher.newWithBuffer(cBuff);
} catch (Exception e) {
System.out.printf("failed to create content cached searcher: %s\n", e);
return;
}
String ip = "1.2.3.4";
// 3、查询
try {
long sTime = System.nanoTime();
String region = searcher.search(ip);
long cost = TimeUnit.NANOSECONDS.toMicros((long) (System.nanoTime() - sTime));
System.out.printf("{region: %s, ioCount: %d, took: %d μs}\n", region, searcher.getIOCount(), cost);
} catch (Exception e) {
System.out.printf("failed to search(%s): %s\n", ip, e);
}
// 4、关闭资源 - 该 searcher 对象可以安全用于并发,等整个服务关闭的时候再关闭 searcher
// searcher.close();
// 备注:并发使用,用整个 xdb 数据缓存创建的查询对象可以安全的用于并发,也就是你可以把这个 searcher 对象做成全局对象去跨线程访问。
}
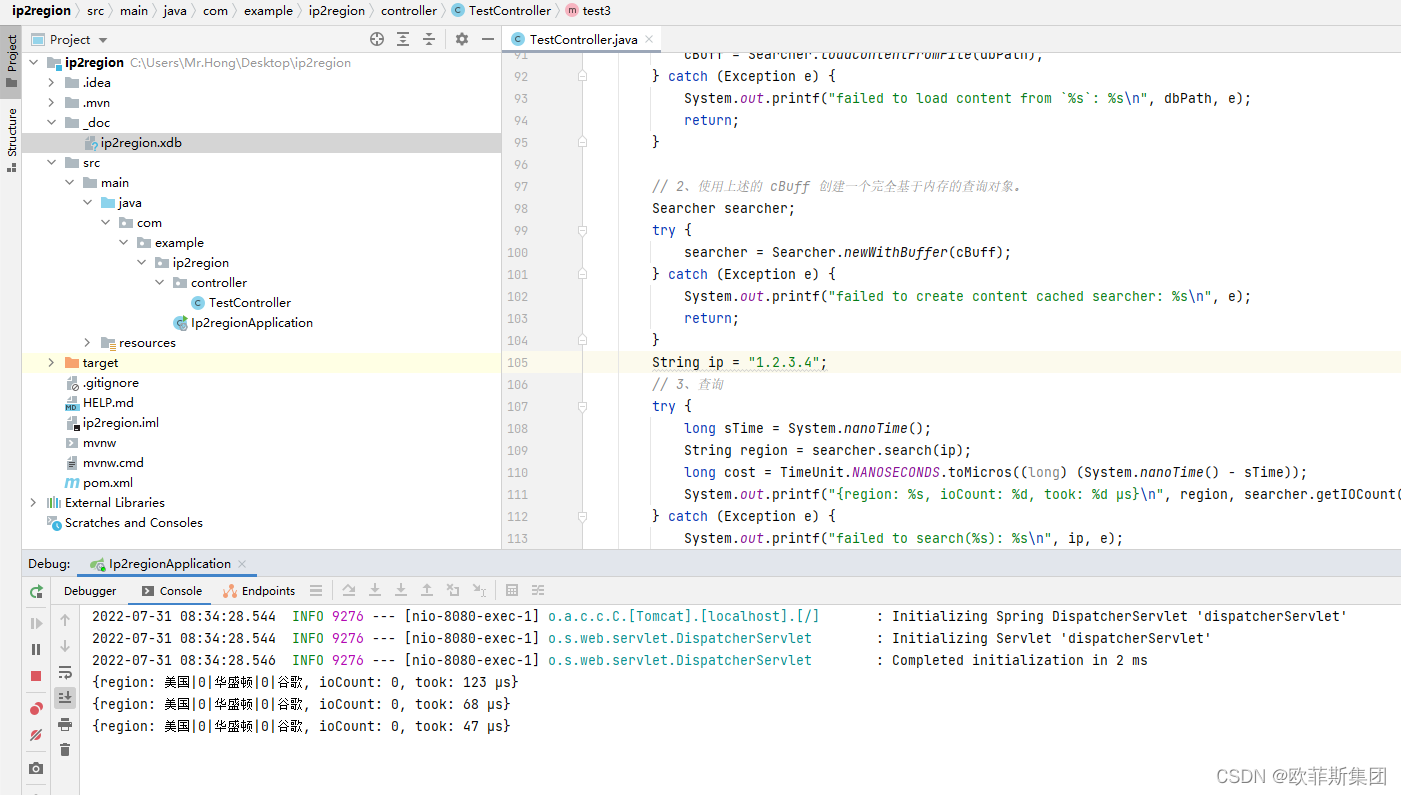
}
结束语
使用ip2region xdb的方式查询ip地址属地效率是非常高的,可以看到我的几种不同测试中,最快的速度达到了惊人的47纳秒,可以说基本上是及时响应。所以有了这么好用的工具,并且准确率达到99%,所以以后使用IP属地查询,如果频率非常高,那么建议使用。
边栏推荐
猜你喜欢
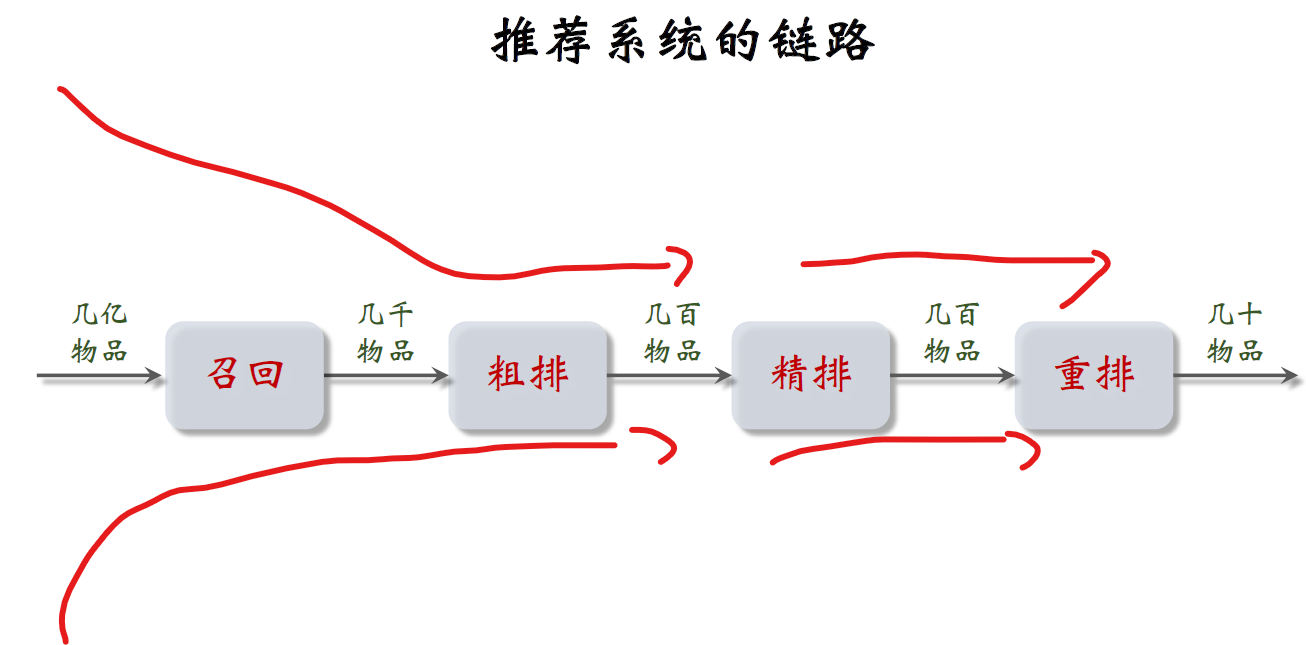
Understand the recommendation system in one article: Outline 02: The link of the recommendation system, from recalling rough sorting, to fine sorting, to rearranging, and finally showing the recommend
FinClip | 2022 年 7 月产品大事记
C专家编程 第1章 C:穿越时空的迷雾 1.9 阅读ANSI C标准,寻找乐趣和裨益

中小微企业如何简单便捷、低成本实现数字化?360视觉云有妙招

B站回应HR称核心用户是Loser;微博回应宕机原因;Go 1.19 正式发布|极客头条
FinClip | July 2022 Product Highlights
“68道 Redis+168道 MySQL”精品面试题(带解析),你背废了吗?
sphinx coreseek的安装和php下使用
产品-Axure9英文版,轮播图效果

2年开发经验去面试,吊打面试官,即将面试的程序员这些笔记建议复习
随机推荐
如何在 DataWorks 中 写SQL语句监控数据的变化到达一定的值 进行提示
通用型安全监测数据管理系统
虹科分享 | 如何测试与验证复杂的FPGA设计(3)——硬件测试
C语言01、数据类型、变量常量、字符串、转义字符、注释
After using Stream for many years, does collect still have these "saucy operations"?
数据万象内容审核 — 共建安全互联网,专项开展“清朗”直播整治行动
设置海思芯片MMZ内存、OS内存详解
论文解读(JKnet)《Representation Learning on Graphs with Jumping Knowledge Networks》
阿里二面:没有 accept,能建立 TCP 连接吗?
[Unity Getting Started Plan] Basic Concepts (6) - Sprite Renderer Sprite Renderer
LeetCode·1163.按字典序排在最后的子串·最小表示法
C语言03、数组
sphinx error connection to 127.0.0.1:9312 failed (errno=0, msg=)
php之相似文章标题similar_text()函数使用
新特性解读 | MySQL 8.0 在线调整 REDO
附录A 程序员工作面试的秘密
TiKV & TiFlash 加速复杂业务查询丨TiFlash 应用实践
#yyds干货盘点# 面试必刷TOP101:两个链表的第一个公共结点
浅谈Service&nbsp;Mesh对业务系统的价值
论文解读(JKnet)《Representation Learning on Graphs with Jumping Knowledge Networks》