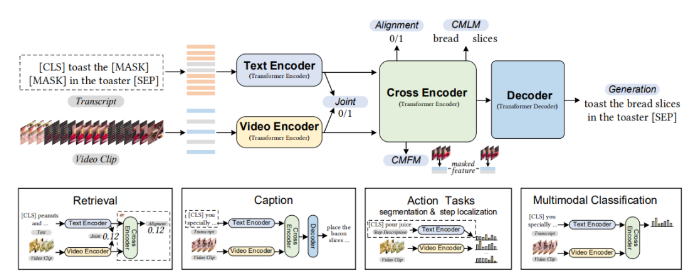
当前位置:网站首页>Sell notes | brief introduction to video text pre training
Sell notes | brief introduction to video text pre training
2022-06-27 23:55:00 【Zhiyuan community】
author : Harbin Institute of technology SCIR Zhong Weihong
1. brief introduction
With the development of the pre training model , Researchers also began to try to apply the framework and method of pre training model to multimodal tasks . In the picture - Text multimodal tasks , The application of pre training model has achieved excellent performance . Compared to pictures , The information contained in the video content is more abundant and redundant , Multiple frames may contain highly similar pictures . Different from the picture , Video content naturally contains timing information , As the length of video grows , It contains more and more time series information . meanwhile , Because the volume of video data is larger than that of pictures , Data sets 、 The construction of models has posed a greater challenge for researchers . therefore , How to be more elegant , Build video with high quality - The connection between textual representations 、 Have a good interaction , And bring improvement to downstream tasks , It has become a problem for researchers to explore .
This article briefly combs the current video - The model architecture of text pre training and related data sets , meanwhile , Aiming at the redundancy of video information , The work of introducing fine-grained information is briefly introduced .
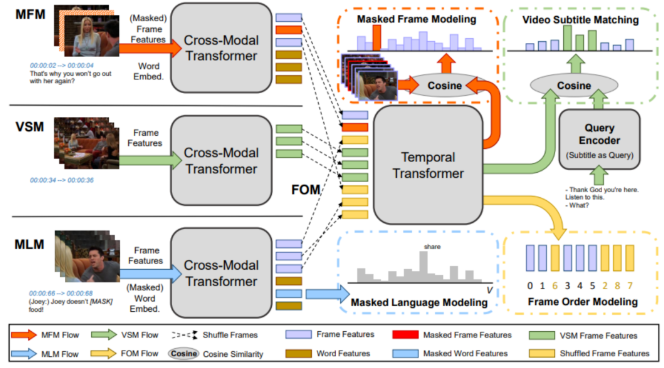
2. Commonly used pre training data sets
The data of multimodal pre training usually comes from large-scale modal alignment sample pairs . Due to the existence of temporal dimension , Video contains more abundant and redundant information than pictures . therefore , Collect large-scale videos - It is difficult to use text alignment data for video pre training . at present , The public pre training datasets used by most researchers mainly include HowTo100M[1] and WebVid[2] Data sets , Besides , Due to the similarity of video and picture features , There is also a lot of work using pictures - Text pre training data set for training , This section focuses on video - The commonly used data sets in text pre training are briefly introduced .
2.1 HowTo100M
Learning video - The cross modal representation of text usually requires manual annotation of video clips (clip), Labeling such a large data set is very expensive .Miech[1] And so on HowTo100M Data sets , Help model from voiceover text with auto transcribe (automatically transcribed narrations) Learn the cross modal representation from the video data of .HowTo100M from 1.22M A teaching with narration (instructional) In the network video, you can get 136M A video clip (clip). The teaching content of video is mostly displayed by human beings , It contains more than 23, 000 different visual tasks .





surface 3 Conceptual Captions Statistical data [3]
















[1] Miech A, Zhukov D, Alayrac J B, et al. Howto100m: Learning a text-video embedding by watching hundred million narrated video clips[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 2630-2640.
[2] Bain M, Nagrani A, Varol G, et al. Frozen in time: A joint video and image encoder for end-to-end retrieval[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 1728-1738.
[3] Sharma P, Ding N, Goodman S, et al. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018: 2556-2565.
[4] Sun C, Myers A, Vondrick C, et al. Videobert: A joint model for video and language representation learning[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 7464-7473.
[5] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[6] Lei J, Li L, Zhou L, et al. Less is more: Clipbert for video-and-language learning via sparse sampling[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 7331-7341.
[7] Xu H, Ghosh G, Huang P Y, et al. VLM: Task-agnostic video-language model pre-training for video understanding[J]. arXiv preprint arXiv:2105.09996, 2021.
[8] Sun C, Baradel F, Murphy K, et al. Learning video representations using contrastive bidirectional transformer[J]. arXiv preprint arXiv:1906.05743, 2019.
[9] Luo H, Ji L, Shi B, et al. Univl: A unified video and language pre-training model for multimodal understanding and generation[J]. arXiv preprint arXiv:2002.06353, 2020.
[10] Bertasius G, Wang H, Torresani L. Is space-time attention all you need for video understanding?[C]//ICML. 2021, 2(3): 4.
[11] Li L, Chen Y C, Cheng Y, et al. Hero: Hierarchical encoder for video+ language omni-representation pre-training[J]. arXiv preprint arXiv:2005.00200, 2020.
[12] Zellers R, Lu X, Hessel J, et al. Merlot: Multimodal neural script knowledge models[J]. Advances in Neural Information Processing Systems, 2021, 34: 23634-23651.
[13] Tang Z, Lei J, Bansal M. Decembert: Learning from noisy instructional videos via dense captions and entropy minimization[C]//Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021: 2415-2426.
[14] Fu T J, Li L, Gan Z, et al. VIOLET: End-to-end video-language transformers with masked visual-token modeling[J]. arXiv preprint arXiv:2111.12681, 2021.
[15] Zhu L, Yang Y. Actbert: Learning global-local video-text representations[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 8746-8755.
[16] Wang J, Ge Y, Cai G, et al. Object-aware Video-language Pre-training for Retrieval[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 3313-3322.
[17] Li D, Li J, Li H, et al. Align and Prompt: Video-and-Language Pre-training with Entity Prompts[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 4953-4963.
[18] Radford A, Kim J W, Hallacy C, et al. Learning transferable visual models from natural language supervision[C]//International Conference on Machine Learning. PMLR, 2021: 8748-8763.
[19] Ge Y, Ge Y, Liu X, et al. Bridging Video-Text Retrieval With Multiple Choice Questions[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2022: 16167-16176.
[20] Liu S, Fan H, Qian S, et al. Hit: Hierarchical transformer with momentum contrast for video-text retrieval[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021: 11915-11925.
[21] Min S, Kong W, Tu R C, et al. HunYuan_tvr for Text-Video Retrivial[J]. arXiv preprint arXiv:2204.03382, 2022.
[22] Van Den Oord A, Vinyals O. Neural discrete representation learning[J]. Advances in neural information processing systems, 2017, 30.
边栏推荐
- Cornernet understands from simple to profound
- [PCL self study: pclplotter] pclplotter draws data analysis chart
- seata
- The file or assembly 'cefsharp.core.runtime.dll' or one of its dependencies could not be loaded. Is not a valid Win32 Application. (exception from hresult:0x800700c1)
- Use of go log package log
- 【AI应用】NVIDIA Tesla V100S-PCIE-32GB的详情参数
- An analysis of C language functions
- 思源笔记订阅停止直接删云端数据嘛?
- 超纲练习题不超纲
- C language - date formatting [easy to understand]
猜你喜欢
![[tinyriscv verilator] branch transplanted to Da Vinci development board of punctual atom](/img/a8/4786e82d0646b08c195dd0a17af227.png)
[tinyriscv verilator] branch transplanted to Da Vinci development board of punctual atom

零基础自学SQL课程 | CASE函数
webService
![[microservices sentinel] sentinel data persistence](/img/9f/2767945db99761bb35e2bb5434b44d.png)
[microservices sentinel] sentinel data persistence

Transmitting and receiving antenna pattern

Cornernet由浅入深理解
C# Winform 读取Resources图片
Zero foundation self-study SQL course | case function

Safe, fuel-efficient and environment-friendly camel AGM start stop battery is full of charm
发射,接收天线方向图
随机推荐
Golang uses Mongo driver operation - query (basic)
Msp430f5529 MCU reads gy-906 infrared temperature sensor
golang使用mongo-driver操作——查(数组相关)
Can you do these five steps of single cell data cleaning?
Swing UI container (I)
virtualbox扩展动态磁盘大小的坑
MySQL read / write separation configuration
VMware virtual machine bridging connectivity
100 questions for an enterprise architect interview
N methods for obtaining effective length of genes
matlab axis坐标轴相关设置详解
Google Earth engine (GEE) 03 vector data type
Although the TCGA database has 33 cancers
通过中金证券经理的开户二维码开股票账户安全吗?还是去证券公司开户安全?
Instructions for vivado FFT IP
零基础自学SQL课程 | SQL中的日期函数大全
【AI应用】Jetson Xavier NX的详情参数
How to use the apipost script - global variables
NDSS 2022 received list
go日志包 log的使用