当前位置:网站首页>学习笔记14--机器学习在局部路径规划中的应用
学习笔记14--机器学习在局部路径规划中的应用
2022-08-05 07:56:00 【FUXI_Willard】
本系列博客包括6个专栏,分别为:《自动驾驶技术概览》、《自动驾驶汽车平台技术基础》、《自动驾驶汽车定位技术》、《自动驾驶汽车环境感知》、《自动驾驶汽车决策与控制》、《自动驾驶系统设计及应用》。
此专栏是关于《自动驾驶汽车决策与控制》书籍的笔记.
2.汽车局部轨迹规划
2.4 机器学习在局部路径规划中的应用
概述
模仿学习
状态-动作的映射关系可以通过在专家示例数据中学习得到;但是这种学习缺乏对环境的整体认知,仅适用于有限或简单场景,同时还需要收集大量的数据用于训练,数据的质量、数量、覆盖面对于模仿学习非常重要;
基于激励函数的优化
此类方法将空间离散成不同栅格后,再应用诸如动态规划或其他数学优化手段的搜索方法,激励/代价函数由专家数据提供或通过逆向增强学习得到;
逆向增强学习
逆向增强学习(Inverse Reinforcement Learning,IRL)通过将专家示例数据与生成的轨迹或优化激励函数的策略相比较来学习得到激励函数;
可以通过期望特征匹配的方法学习得到激励函数,或直接将这一过程延伸为更广泛的最大化边界条件的优化问题;通过特征期望匹配进行的优化十分模糊,需要位于策略子空间中的优化策略,策略空间中的行为虽然不是最优的,但仍能与示例行为相匹配;
基于学习的方法应用于自动驾驶运动规划问题的难点:
- 自动驾驶系统需要保证公共道路交通的安全,这一点在训练和测试过程中十分重要,很多基于学习的方法需要足够的线上训练以从实际驾驶环境中收集足够的反馈数据,这一过程有可能危及道路安全;
- 自动驾驶数据的再现很困难,不同场景中的专家驾驶数据很容易收集,但要在仿真环境中再现则难度很大,因为此部分数据包含主车与周围环境的复杂交互;
- 自动驾驶运动规划器不仅需要应对动态变化的复杂交通环境,还需要在每时每刻遵循交通规则,增强学习系统地将这些约束条件整合起来十分难;
基于增强学习的最优轨迹训练
以基于百度Apollo平台的自整定的运动规划系统为例介绍。
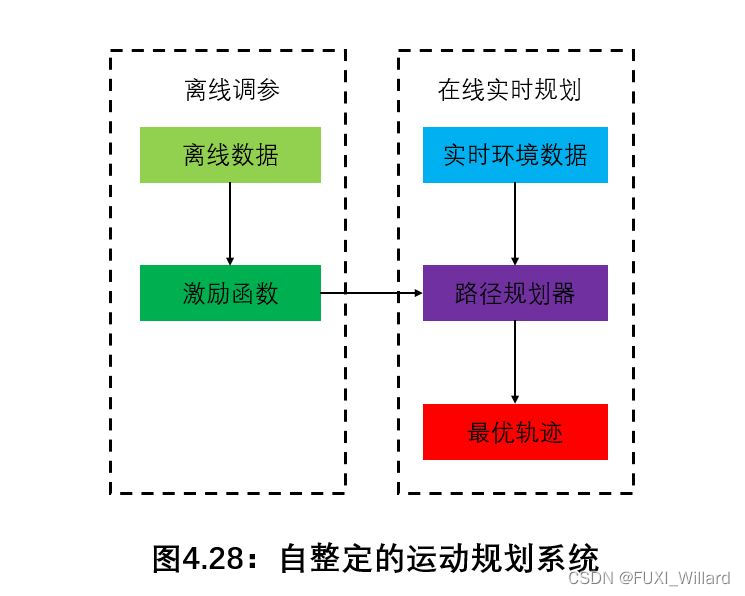
在线模块负责在满足约束条件的前提下,基于给定的激励函数进行轨迹优化;
运动规划模块无须限定用特定的方法完成,可以用基于采样的优化、动态规划甚至是增强学习来生成轨迹;但这些规划方法将由定量分析其优化性和鲁棒性的矩阵来进行评估,其中优化性通过优化轨迹与所生成轨迹的激励函数值之间的差异来衡量,鲁棒性由特定场景下生成轨迹的方差来衡量;在此基础上,通过仿真和路测提供对于运动规划模块的功能进行最终测试;
离线整定模块负责生成能应用于不同驾驶场景的激励/代价函数;激励/代价函数包含描述轨迹光滑性及本车与环境间的交互的特征因素,并可以通过仿真和道路测试来进行调试整定;
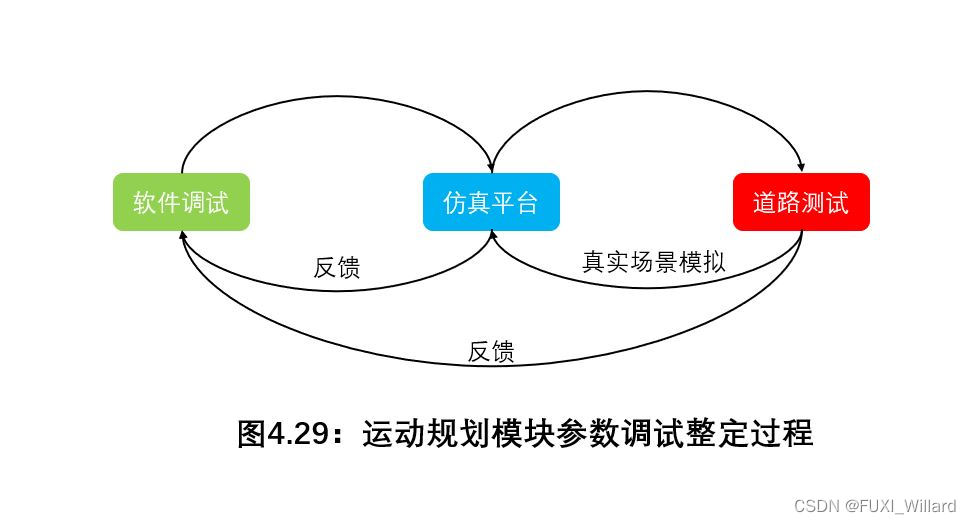
- 测试参数的效果需要仿真和路测来验证,反馈环节是耗时最长的,需要在上千计的驾驶场景中对参数性能进行验证;
- 这些驾驶场景包括:城市、高速公路、拥挤道路等,为了调试得到满足这些不同场景的激励函数,传统的思路:将这一过程由简单场景拓展到复杂场景,这种方式下,若当前参数在新场景中效果欠佳,需要进一步对参数进行调试甚至扩展参数范围,调参效率非常低效;如果用基于序列的条件逆向增强学习框架来针对自动驾驶运动规划激励/代价函数的参数调整,可以有很好的效果;
在线轨迹评估与离线激励函数训练过程如下图所示:
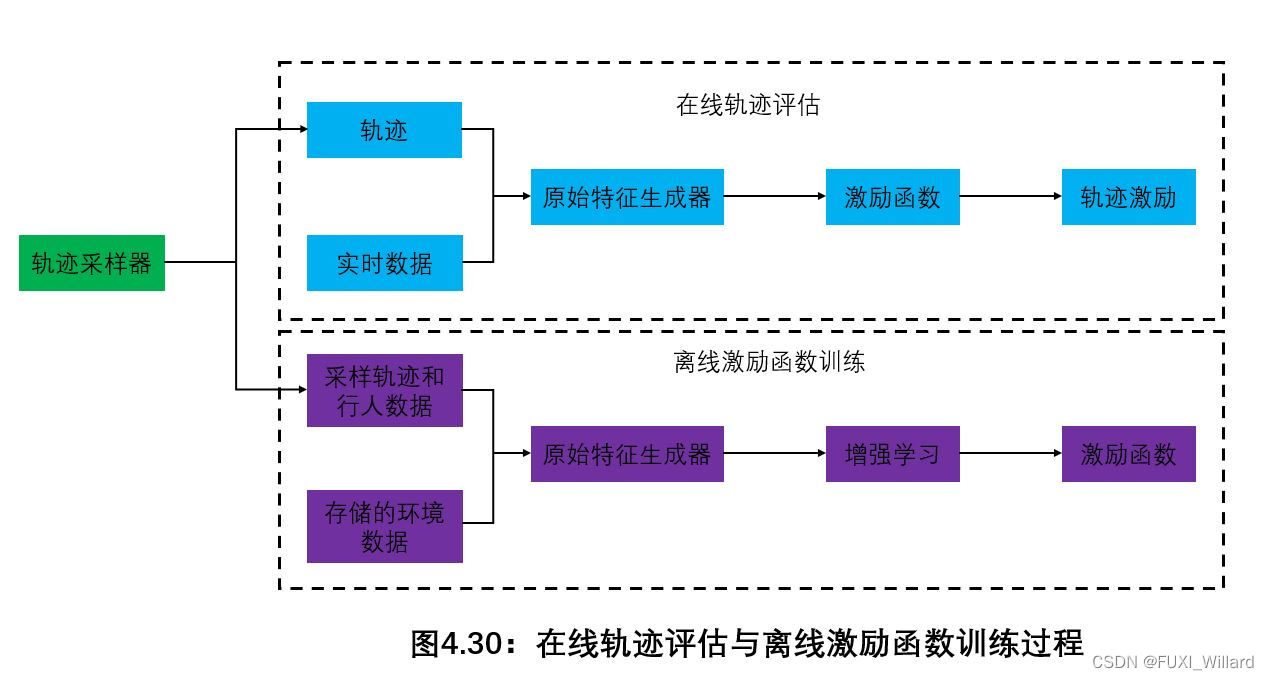
原始特征生成以环境数据为输入并对采样得到的或取自人类专家的轨迹数据进行评估,轨迹采样工具为在线和离线模块提供候选轨迹;在线评估模块中,从轨迹中提取原始特征后,激励/代价函数对其进行打分并进行排序,得分最高的轨迹作为最终轨迹输出;
激励/代价函数参数训练基于SIAMESE网络结构实现。
以马尔科夫决策为基础对轨迹进行描述: ξ = ( a 0 , s 0 , … , a N , s N ) ∈ Ξ \xi=(a_0,s_0,\dots,a_N,s_N)\in{\Xi} ξ=(a0,s0,…,aN,sN)∈Ξ,空间 Ξ \Xi Ξ是轨迹采样空间;以下值函数对轨迹初始状态进行评估:
V ξ ( s 0 ) = ∑ t = 1 N γ t R ( a t , s t ) (40) V^{\xi}(s_0)=\sum_{t=1}^N\gamma_tR(a_t,s_t)\tag{40} Vξ(s0)=t=1∑NγtR(at,st)(40)
此值函数是不同时刻点下激励函数值的线性组合;原始特征生成模块基于当前状态和动作提供一系列特征,这些特征以 f j ( a t , s t ) , j = 1 , 2 , … , K f_j(a_t,s_t),j=1,2,\dots,K fj(at,st),j=1,2,…,K进行表达;选择以下激励函数 R R R作为所有特征和参数 θ ∈ Ω \theta\in\Omega θ∈Ω的函数:
R θ ( a t , s t ) = R ~ ( f 1 , f 2 , … , f K , θ ) (41) R_{\theta}(a_t,s_t)=\tilde{R}(f_1,f_2,\dots,f_K,\theta)\tag{41} Rθ(at,st)=R~(f1,f2,…,fK,θ)(41)
R ~ \tilde{R} R~可以是所有特征的线性组合,或则是以特征作为输入的神经网络关系,这种神经网络可以视为进一步获取状态-动作映射内部特征的编码过程;这一训练过程称为RC-IRL;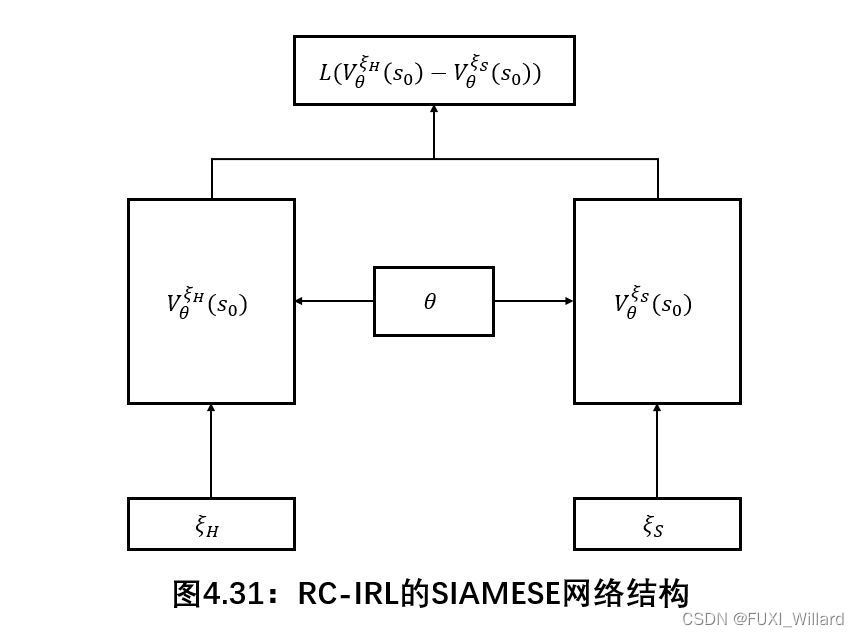
其中: ξ H \xi_H ξH代表人类专家演示数据, ξ S \xi_S ξS代表空间 Ξ \Xi Ξ下随机生成的采样轨迹;损失函数是一个非负实数函数,用来量化模型预测和真实标签之间的差异,最小化损失函数的过程,即为通过对参数的迭代使得人类驾驶轨迹的代价小于随机采样轨迹的代价;
损失函数定义如下, a = 0.05 a=0.05 a=0.05:
L ( y ) = { y , y ≥ 0 a y , y < 0 (42) L(y)= \begin{cases} y,&y≥0\\ ay,&y<0 \end{cases}\tag{42} L(y)={ y,ay,y≥0y<0(42)
值函数训练网络结构如下图所示: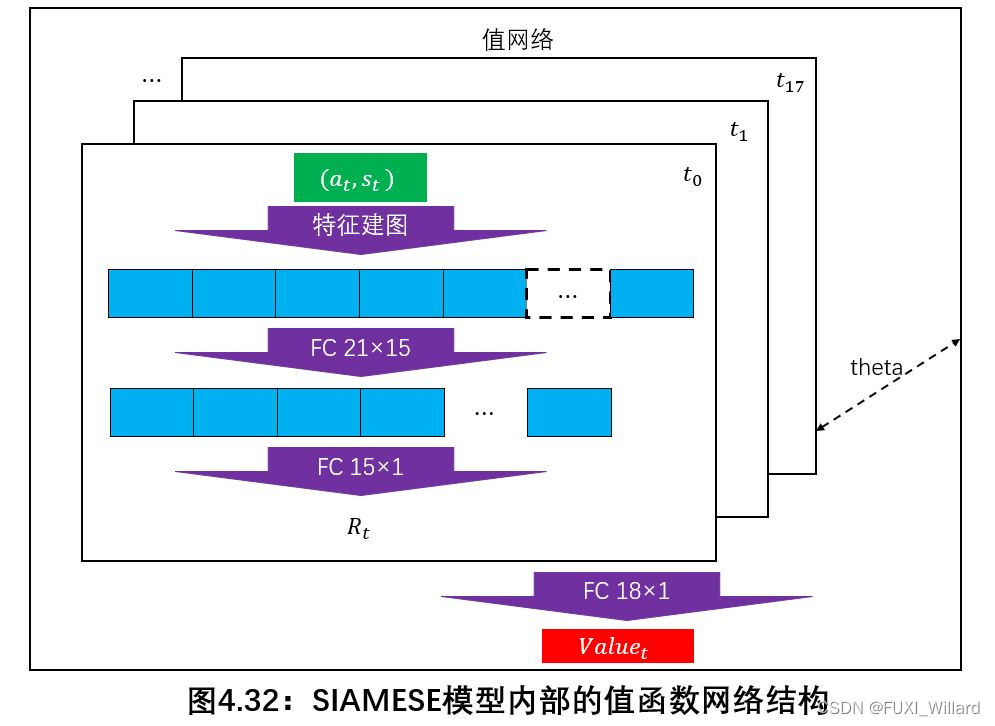
边栏推荐
猜你喜欢





随机推荐
moment的使用
2006年星座运势全解-射手
U++ UE4官方文档课后作业
向美国人学习“如何快乐”
【无标题】长期招聘硬件工程师-深圳宝安
强网杯2022 pwn 赛题解析——house_of_cat
TRACE32——List源代码查看
达梦数据库大表添加字段
MongoDB 语法大全
配合屏幕录像专家,又小又清晰!
TensorFlow安装步骤
【深度学习实践(一)】安装TensorFlow
唤醒手腕 - 微信小程序、QQ小程序、抖音小程序学习笔记(更新中)
C-Eighty seven(背包+bitset)
创业者如何吸引风险投资商
Unity—物理引擎+“武器模块”
2022.8.2 模拟赛
Redis实现分布式锁-原理-问题详解
网络安全研究发现,P2E项目遭遇黑客攻击只是时间问题
C语言制作-QQ聊天室