当前位置:网站首页>MindSpore系列一加载图像分类数据集
MindSpore系列一加载图像分类数据集
2022-06-28 18:30:00 【追猫人】
MindSpore提供了大部分常用数据集和标准格式数据集的加载接口,可以直接使用mindspore.dataset中对应的数据集加载类进行数据加载,如MNIST、CIFAR-10、CIFAR-100、VOC、COCO、ImageNet、CelebA、CLUE等, 以及业界标准格式的数据集,包括MindRecord、TFRecord、Manifest等。
常用数据集加载以cifar10为例,首先将cifar10数据集下载并解压到本地。
1、加载cifar10数据集:
DATA_DIR = "./cifar-10-batches-bin/"
sampler = ds.SequentialSampler(num_samples=5)
dataset = ds.Cifar10Dataset(DATA_DIR, sampler=sampler)
用create_dict_iterator创建数据迭代器访问数据:
for data in dataset.create_dict_iterator():
print("Image shape: {}".format(data['image'].shape), ", Label: {}".format(data['label']))

2、加载自定义图像分类数据集
使用mindspore加载自定义图像分类数据,可以使用mindspore.dataset.ImageFolderDataset接口进行加载。将相同类别的图像放在同一文件夹下,不同类别以不同文件夹区分,将所有分类的上级目录传入ImageFolderDataset接口,mindspore会自动加载图像数据并根据不同文件夹分配对应标签。
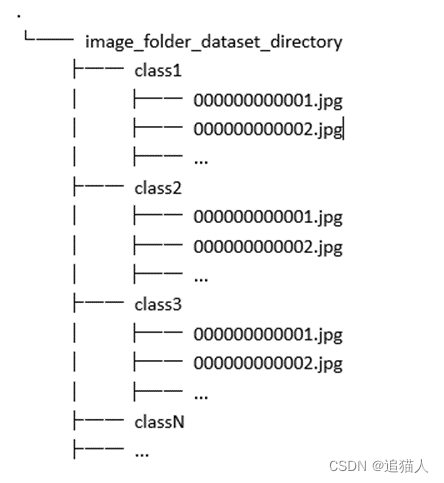

这里以TinyImageNet为例进行数据加载。首先,使用imageFolderDataset接口传入数据路径,通过num_parallel_worker可设置数据加载并行线程数,shuffle参数设置是否打乱数据顺序。另外需要通过map接口进行图像数据预处理,图像预处理接口mindspore.dataset.vision.c_transforms,通过c_transforms可进行图像解码,缩放归一化,矩阵转置等操作。
import mindspore
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as CV
import mindspore.dataset.transforms.c_transforms as C
from mindspore import dtype as mstype
def create_dataset(data_path, batch_size=24, c_transforms
repeat_num=1):
"""定义数据集"""
parallel_mode = context.get_auto_parallel_context("parallel_mode")
if parallel_mode == context.ParallelMode.DATA_PARALLEL:
data_set = ds.ImageFolderDataset(data_path, num_parallel_def create_dataset(data_path, batch_size=24, repeat_num=1):
"""定义数据集"""
data_set = ds.ImageFolderDataset(data_path, num_parallel_workers=8, shuffle=True)
image_size = [100, 100]
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
trans = [
CV.Decode(),
CV.Resize(image_size),
CV.Normalize(mean=mean, std=std),
CV.HWC2CHW()
]
# 实现数据的map映射、批量处理和数据重复的操作
type_cast_op = C.TypeCast(mstype.int32)
data_set = data_set.map(operations=trans, input_columns="image", num_parallel_workers=8)
data_set = data_set.map(operations=type_cast_op, input_columns="label", num_parallel_workers=8)
data_set = data_set.batch(batch_size, drop_remainder=True)
data_set = data_set.repeat(repeat_num)
return data_set
数据迭代,ImageFolderDataset通过create_tuple_iterator()接口对数据集进行迭代,每次迭代一个batch的数据。
if __name__ == '__main__':
datapath = 'D:/Sources/Data/datasets/TinyImageNet/val'
ds = create_dataset(datapath, batch_size=8)
iterator = ds.create_tuple_iterator()
for item in iterator:
print(f'images:{mindspore.Tensor(item[0]).shape},labels:{item[1]}')

边栏推荐
猜你喜欢

leetcode 1423. Maximum Points You Can Obtain from Cards(从牌中能得到的最大点数和)
Small program graduation project based on wechat subscription water supply mall small program graduation project opening report function reference

数据资产为王,如何解析企业数字化转型与数据资产管理的关系?

How to upgrade from RHEL 8 to RHEL 9

Win 10创建一个gin框架的项目

About Covariance and Correlation(协方差和相关)

新工作第一天

Alist+RaiDrive 给电脑整个80亿GB硬盘

Sharing-JDBC分布式事务之Seata实现

Analysis of response parsing process of SAP ui5 batch request
随机推荐
PMP怎么补考?补考费用是多少?
CANN媒体数据处理V2,JPEGD接口介绍
解析机器人主持教学的实践发展
电子商务盛行,怎么提高商店转换率?
Concept and code implementation of heap
从知名软件提取出的神器,吊打一众付费
Yixin Huachen: real estate enterprises want to grasp the opportunity of the times for digital transformation
Database Experiment 7 integrity constraints
实时Transformer:美团在单图像深度估计上的研究
剑指 Offer 11. 旋转数组的最小数字
【云驻共创】昇腾异构计算架构CANN,助力释放硬件澎湃算力
技术管理进阶——管理者如何做绩效沟通及把控风险
Can I open an account today and buy shares today? Is it safe to open an account online?
China gaobang brand story: standing guard for safety, gaobang pays attention to
curl: (56) Recv failure: Connection reset by peer
Small program graduation design based on wechat driving school examination small program graduation design opening report function reference
19.2 容器分类、array、vector容器精解
ONEFLOW source code parsing: automatic inference of operator signature
Analysis of response parsing process of SAP ui5 batch request
Openfire 3.8.2集群配置