当前位置:网站首页>A specially designed loss is used to deal with data sets with unbalanced categories
A specially designed loss is used to deal with data sets with unbalanced categories
2022-07-02 21:42:00 【Xiaobai learns vision】
Click on the above “ Xiaobai studies vision ”, Optional plus " Star standard " or “ Roof placement ”
Heavy dry goods , First time delivery 
Reading guide
This article is about Google CVPR ' 19 A summary of an article published on , The title of the article is Class-Balanced Loss Based on Effective Number of Samples. It is the most commonly used loss (softmax-cross-entropy、focal loss etc. ) A reweighting scheme for each category is proposed , It can quickly improve the accuracy , Especially when dealing with highly unbalanced data .
This article is about Google CVPR ' 19 A summary of an article published on , The title of the article is Class-Balanced Loss Based on Effective Number of Samples.
It is the most commonly used loss (softmax-cross-entropy、focal loss etc. ) A reweighting scheme for each category is proposed , It can quickly improve the accuracy , Especially when dealing with highly unbalanced data
Of the paper PyTorch Implementation source code :https://github.com/vandit15/Class-balanced-loss-pytorch
Effective number of samples
Dealing with long tailed data sets ( Most of the samples belong to very few classes , Many other classes have very few samples ) When , How to weight different types of losses may be tricky . Usually , The weight is set to the reciprocal of the class sample or the reciprocal of the square root of the class sample .
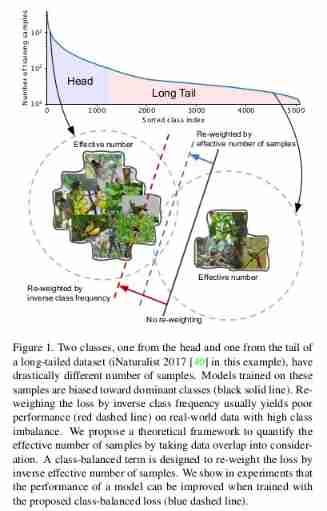
However , As shown in the figure above , This excess is due to As the number of samples increases , The benefits of new data points will be reduced . The newly added sample is most likely an approximate copy of the existing sample , Especially when training neural networks, a large amount of data is used to enhance ( Such as rescaling 、 Random cutting 、 Flip, etc ) When , Many are such samples . Reweighting with the number of effective samples can get better results .
The number of effective samples can be imagined as n The actual volume covered by samples , The total volume N Represented by total samples .
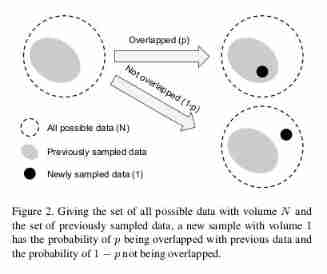
We wrote :
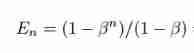
We can also write it as follows :
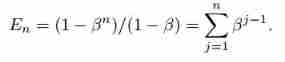
This means No j The contribution of samples to the number of effective samples is βj-1.
Another meaning of the above formula is , If β=0, be En=1. Again , When β→1 When En→n. The latter can be easily proved by lobida's law . It means to be N When a large , Number of effective samples and number of samples N identical . under these circumstances , Number of unique prototypes N It's big , Each sample is unique . However , If N=1, This means that all data can be represented by a prototype .
Category equilibrium loss
If there is no additional information , We cannot set separate for each class Beta value , therefore , When using the whole data , We will set it to a specific value ( Usually set to 0.9、0.99、0.999、0.9999 One of them ).
therefore , The category equilibrium loss can be expressed as :
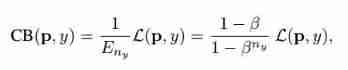
here , L(p,y) It can be any loss .
Class balance Focal Loss
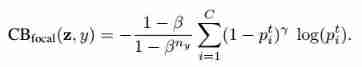
Original version of focal loss There is one α Equilibrium variables . here , We will reweight each class with the number of valid samples .
Similarly , Such a reweighted term can also be applied to other well-known losses (sigmod -cross-entropy, softmax-cross-entropy etc. ).
Realization
Before we start the implementation , One thing to note is that , In use based on sigmoid The loss of training , Use b=-log(C-1) Initialize the deviation of the last layer , among C It's the number of classes , instead of 0. This is because of the settings b=0 It will cause huge losses at the beginning of training , Because the output probability of each class is close to 0.5. therefore , We can assume that a priori class is 1/C, And set it accordingly b Value .
Calculation of weight of each class

The above code line is a simple implementation of getting weights and standardizing them .

ad locum , We get the exclusive calorific value of the weight , In this way, they can be multiplied by the loss value of each class .
experiment
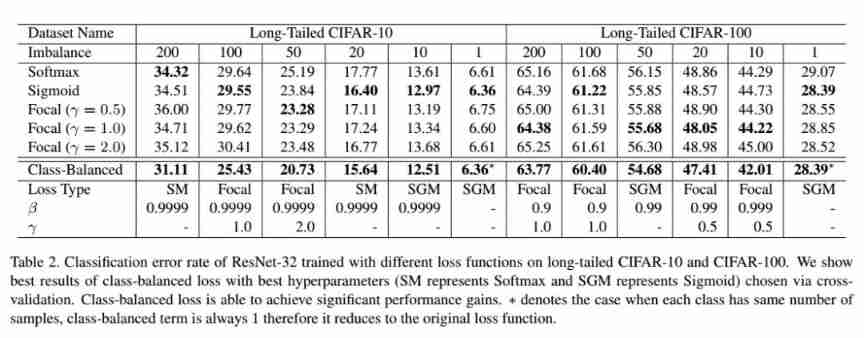
Class equilibrium provides significant benefits , Especially when the data set is highly unbalanced ( out-off-balance = 200,100).
Conclusion
Using the concept of effective sample number , It can solve the problem of data overlap . Because we don't make any assumptions about the dataset itself , Therefore, reweighting is usually applied to multiple data sets and multiple loss functions . therefore , A more appropriate structure can be used to deal with class imbalance , This is important , Because most actual data sets have a large amount of data imbalance .

—END—
The original English text :https://towardsdatascience.com/handling-class-imbalanced-data-using-a-loss-specifically-made-for-it-6e58fd65ffab
download 1:OpenCV-Contrib Chinese version of extension module
stay 「 Xiaobai studies vision 」 Official account back office reply : Extension module Chinese course , You can download the first copy of the whole network OpenCV Extension module tutorial Chinese version , cover Expansion module installation 、SFM Algorithm 、 Stereo vision 、 Target tracking 、 Biological vision 、 Super resolution processing And more than 20 chapters .
download 2:Python Visual combat project 52 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :Python Visual combat project , You can download the Image segmentation 、 Mask detection 、 Lane line detection 、 Vehicle count 、 Add Eyeliner 、 License plate recognition 、 Character recognition 、 Emotional tests 、 Text content extraction 、 face recognition etc. 31 A visual combat project , Help fast school computer vision .
download 3:OpenCV Actual project 20 speak
stay 「 Xiaobai studies vision 」 Official account back office reply :OpenCV Actual project 20 speak , You can download the 20 Based on OpenCV Realization 20 individual Actual project , Realization OpenCV Learn advanced .
Communication group
Welcome to join the official account reader group to communicate with your colleagues , There are SLAM、 3 d visual 、 sensor 、 Autopilot 、 Computational photography 、 testing 、 Division 、 distinguish 、 Medical imaging 、GAN、 Wechat groups such as algorithm competition ( It will be subdivided gradually in the future ), Please scan the following micro signal clustering , remarks :” nickname + School / company + Research direction “, for example :” Zhang San + Shanghai Jiaotong University + Vision SLAM“. Please note... According to the format , Otherwise, it will not pass . After successful addition, they will be invited to relevant wechat groups according to the research direction . Do not Send ads within the group , Or you'll be invited out , Thanks for your understanding ~

边栏推荐
- Redis -- three special data types
- How to test the process of restoring backup files?
- Analysis of neural network
- Gbase8s database type
- Research Report on market supply and demand and strategy of China's atomic spectrometer industry
- Accounting regulations and professional ethics [18]
- Analysis of enterprise financial statements [4]
- treevalue——Master Nested Data Like Tensor
- Golang string segmentation
- Analyze comp-206 advanced UNIX utils
猜你喜欢

Research Report on ranking analysis and investment strategic planning of RFID market competitiveness of China's industrial manufacturing 2022-2028 Edition
MySQL learning record (5)
![[shutter] statefulwidget component (pageview component)](/img/0f/af6edf09fc4f9d757c53c773ce06c8.jpg)
[shutter] statefulwidget component (pageview component)

Common routines of compressed packets in CTF
![[shutter] shutter page Jump (route | navigator | page close)](/img/af/3fb2ca18bcec23a5c0c6897570fb53.gif)
[shutter] shutter page Jump (route | navigator | page close)

MySQL learning record (6)

Structure array, pointer and function and application cases
26 FPS video super-resolution model DAP! Output 720p Video Online

In depth research and investment feasibility report of global and Chinese isolator industry, 2022-2028

MySQL learning record (8)
随机推荐
Construction and maintenance of business websites [10]
Structured text language XML
China plastic bottle and container market trend report, technological innovation and market forecast
[C language] [sword finger offer article] - replace spaces
Go cache of go cache series
[shutter] shutter page Jump (route | navigator | page close)
Research Report on market supply and demand and strategy of microplate instrument industry in China
pyqt圖片解碼 編碼後加載圖片
Research Report on micro gripper industry - market status analysis and development prospect prediction
Go web programming practice (2) -- process control statement
Research Report on market supply and demand and strategy of Chinese garden equipment industry
VictoriaMetrics 简介
Write the content into the picture with type or echo and view it with WinHex
[shutter] statefulwidget component (pageview component)
Construction and maintenance of business websites [9]
MySQL learning record (4)
MySQL learning record (7)
Who do you want to open a stock account? Is it safe to open a mobile account?
Chargement de l'image pyqt après décodage et codage de l'image
[dynamic planning] p1220: interval DP: turn off the street lights