当前位置:网站首页>NebulaGraph v3.2.0 Performance Report
NebulaGraph v3.2.0 Performance Report
2022-08-01 13:03:00 【NebulaGraph】

本文系 NebulaGraph 社区版 v3.2.0 的性能测试报告.
本文目录
总结
测试环境
测试数据
- 关于LDBC-SNB
Nebula Commit
测试说明
基线测试
- Use cases and results
- Query edge properties
- Query the attribute with destination point
- Query edge properties+Destination point attribute
- LOOKUP
- FETCH点
- FETCH边
- MATCH索引
- MATCH一跳
- MATCH两跳
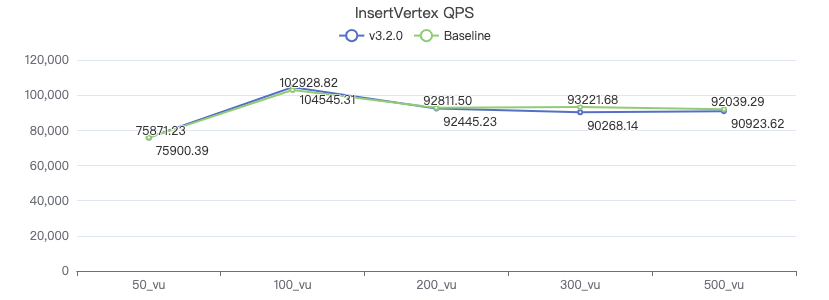
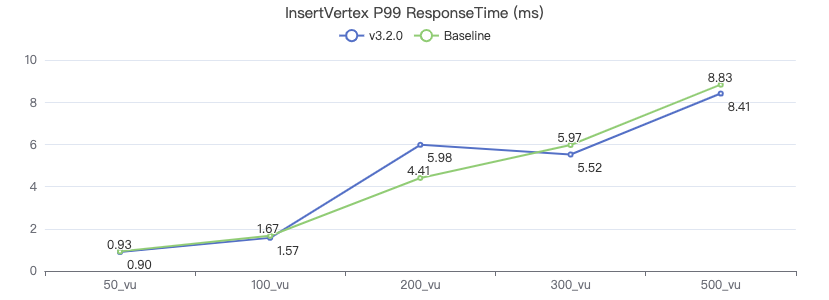
- 插入点
- 插入边
- MatchTest1
- MatchTest2
- MatchTest3
- MatchTest4
- MatchTest5
- Use cases and results
3.2.0 vs 3.1.0(Baseline)
- Query edge properties
- Query the attribute with destination point
- Query edge properties+Destination point attribute
- LOOKUP
- FETCH点
- FETCH边
- MATCH索引
- MATCH一跳
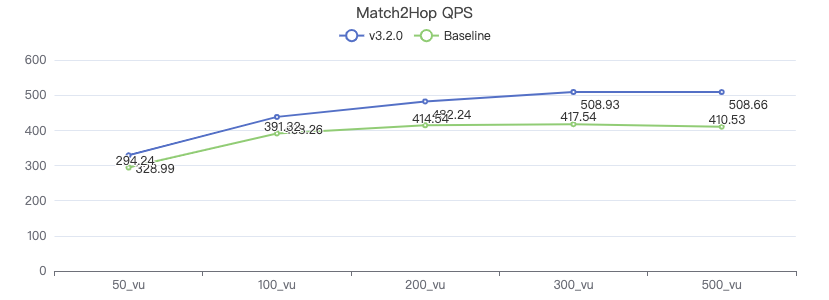
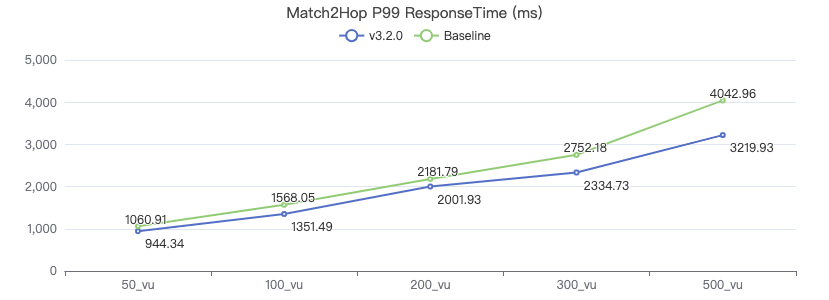
- MATCH两跳
- 插入点
- 插入边
- MatchTest1
- MatchTest2
- MatchTest3
- MatchTest4
- MatchTest5
新增测试用例
- 测试Use cases and results(新增case)
- Query edge properties_count
- Query the attribute with destination point_count
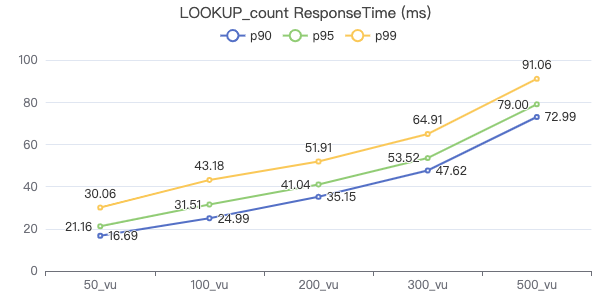
- LOOKUP_count
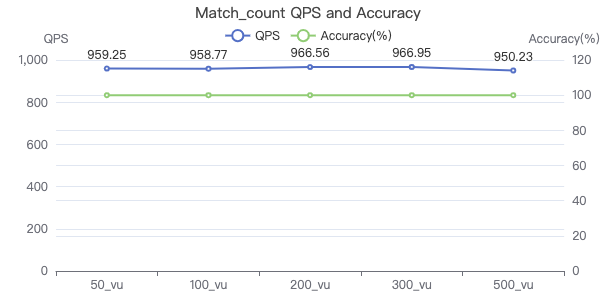
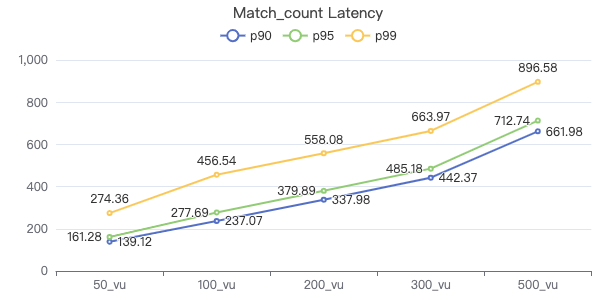
- Match_count
- Match1Hop_count
- Match2Hop_count
- 3.2.0 vs 3.1.0(新增case)
- Query edge properties_count
- Query the attribute with destination point_count
- LOOKUP_count
- Match_count
- Match1Hop_count
- Match2Hop_count
- 测试Use cases and results(新增case)
总结
v3.2.0 The version optimizes the calculation pushdown for point edges,The performance is generally better v3.1.0 The version has slightly increased,主要表现如下:
overall use case Latency Performance has been slightly improved,time reduction by approx. 5%~10%
Match 索引及 Match2Hop 的 QPS 增幅约 20%
Added to this report go 、match、lookup 查询返回 count 的用例,同时新增了 RowSize 指标,It can be analyzed in combination with other indicators「网络回传结果时长 + 客户端反序列化结果时长」对 QPS 的影响.
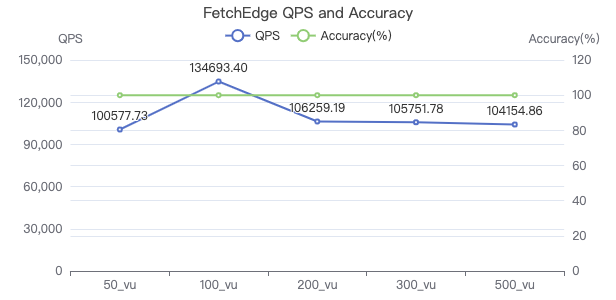
from the performance graph,Some use cases can be seen QPS 大于 10w will drop suddenly,Because the single-machine pressure test is currently used,大于 10w Afterwards, the client will become bottlenecked and no more requests can be made,In the future, multiple pressure testing machines can be considered for testing.
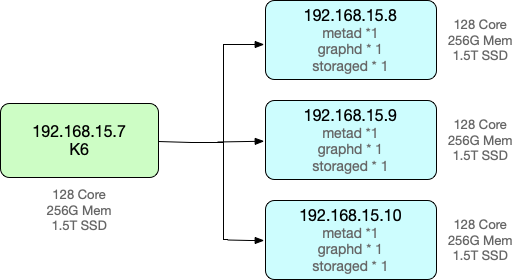
测试环境
服务器和压测机皆为物理机
测试数据
测试数据采用 LDBC-SNB SF100 数据集,SF100数据集大小为 100G,共有 282,386,021 个点以及 1,775,513,185 条边.测试用的图空间分区数为 24,副本数为 3.
关于LDBC-SNB
关联数据基准委员会(LDBC,Linked Data Benchmark Council),是图(Graph)和 RDF 数据管理的基准指南制定者.社交网路基准(SNB,Social Network Benchmark)是关联数据基准委员会(LDBC)开发的软件基准(Benchmark)之一.关于 LDBC-SNB 数据集,具体请参考以下文档:
NebulaGraph Commit
- nebula-graphd version ef6d6a0
- nebula-storaged version ef6d6a0
- nebula-metad version ef6d6a0
测试说明
图表中横坐标轴的“50_vu“、“100_vu“等中的”vu“表示的是 k6 使用的概念“virtual user”,即性能测试中的并发数;50_vu 表示 50 个并发用户,100_vu 表示 100 个并发用户,以此类推…
性能基线使用正式发布的 3.1.0 版本
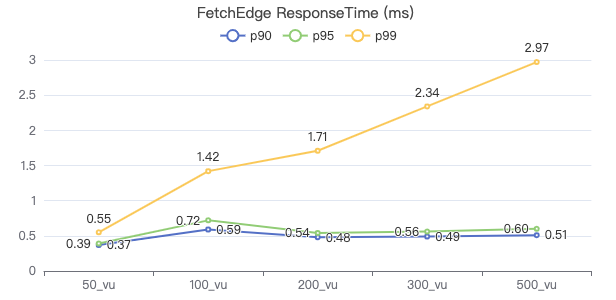
ResponseTime=Latency(服务端处理时长)+网络回传结果时长+客户端反序列化结果时长
基线测试
注:Explanation of the words involved in the figure below
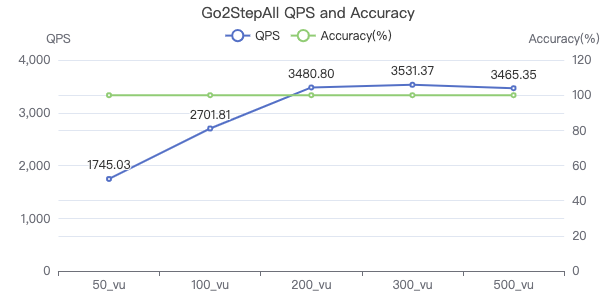
- QPS 即吞吐率
- Latency 即服务端耗时
- ResponseTime 即客户端耗时
- RowSize 即The request returns the number of rows
Use cases and results
Query edge properties
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate
一跳·吞吐率
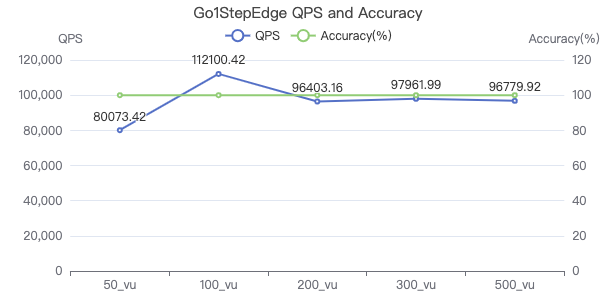
一跳·服务端耗时(ms)

一跳·客户端耗时(ms)
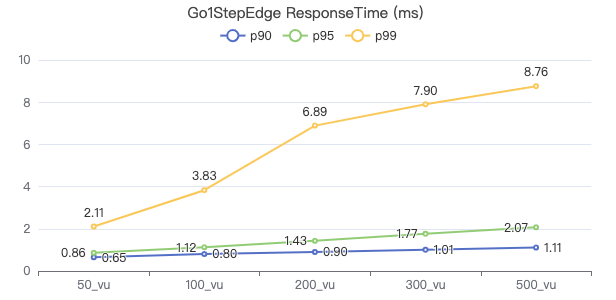
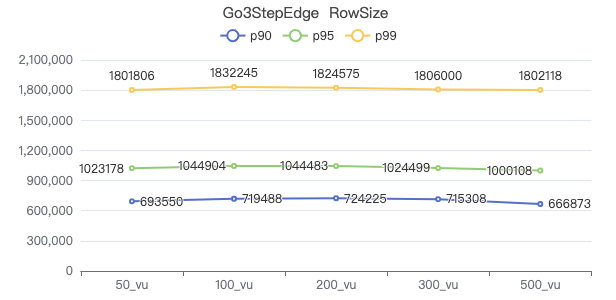
一跳·The request returns the number of rows
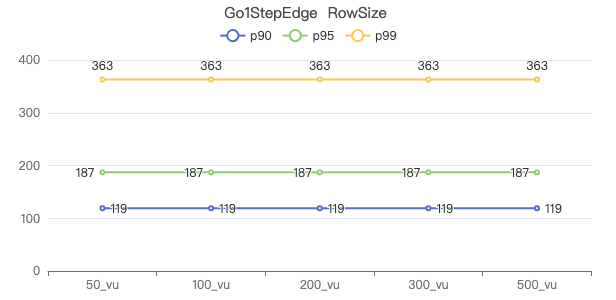
两跳·吞吐率

两跳·服务端耗时(ms)

两跳·客户端耗时(ms)
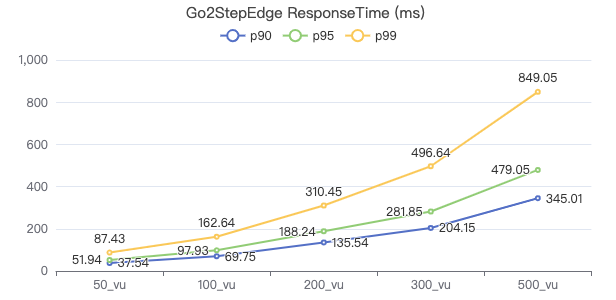
两跳·The request returns the number of rows
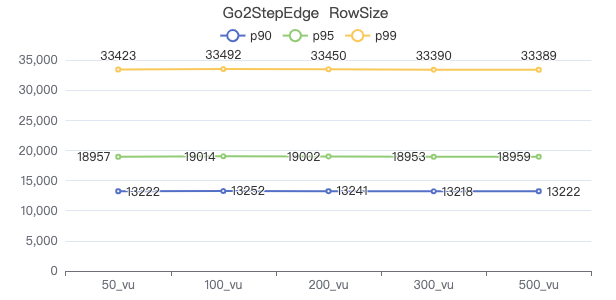
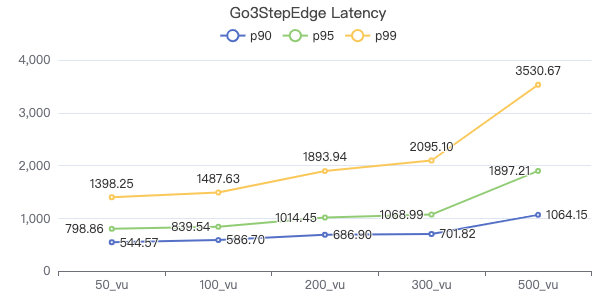
三跳·吞吐率

三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
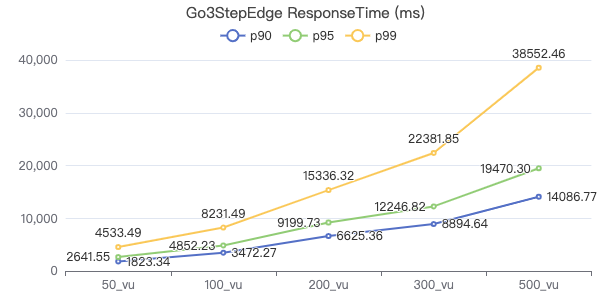
三跳·The request returns the number of rows
Query the attribute with destination point
GO {} STEP FROM {} OVER KNOWS yield $$.Person.firstName
一跳·吞吐率

一跳·服务端耗时(ms)

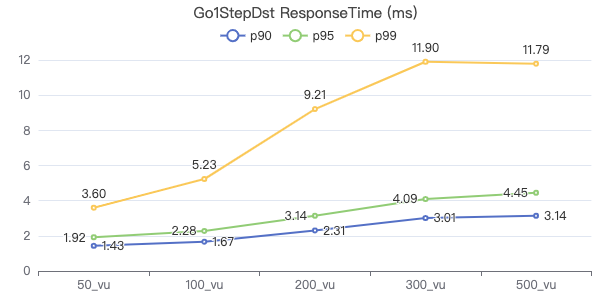
一跳·客户端耗时(ms)
一跳·The request returns the number of rows
两跳·吞吐率
两跳·服务端耗时(ms)
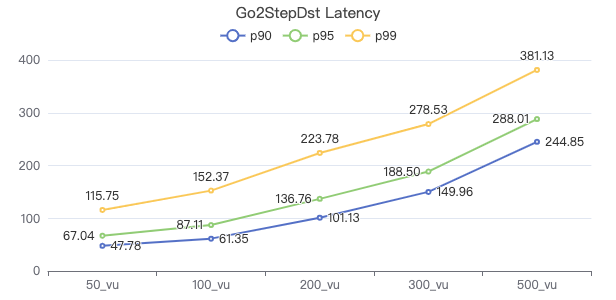
两跳·客户端耗时(ms)
两跳·The request returns the number of rows

三跳·吞吐率
三跳·服务端耗时(ms)

三跳·客户端耗时(ms)

三跳·The request returns the number of rows

Query edge properties+Destination point attribute
GO {} STEP FROM {} OVER KNOWS yield DISTINCT KNOWS.creationDate as t, $$.Person.firstName, $$.Person.lastName, $$.Person.birthday as birth | order by $-.t, $-.birth | limit 10
一跳·吞吐率

一跳·服务端耗时(ms)
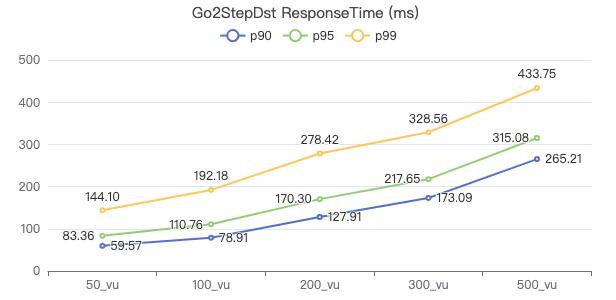
一跳·客户端耗时(ms)
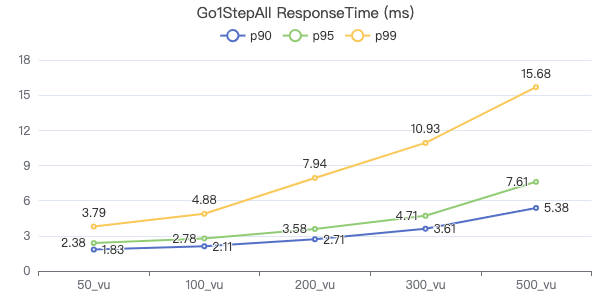
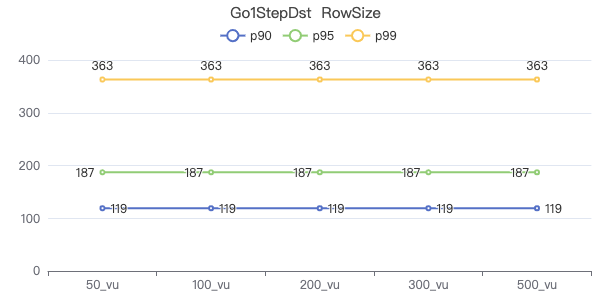
一跳·The request returns the number of rows
二跳·吞吐率
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)

二跳·The request returns the number of rows
三跳·吞吐率
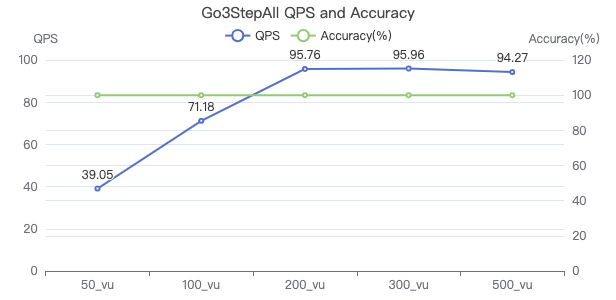
三跳·服务端耗时(ms)
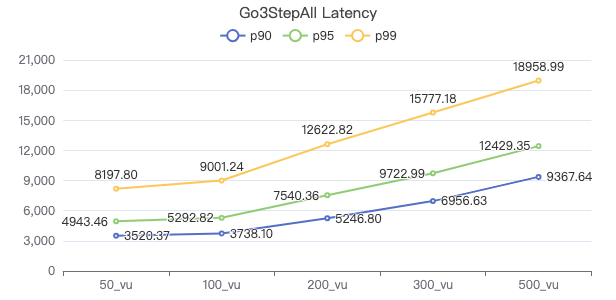
三跳·客户端耗时(ms)
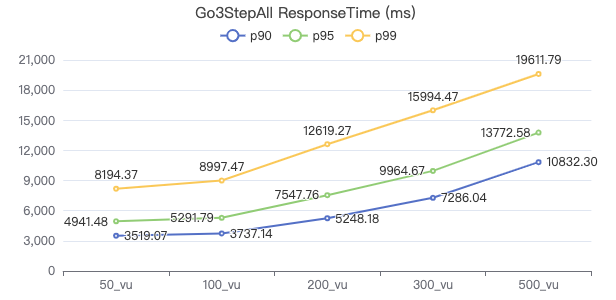
三跳·The request returns the number of rows
LOOKUP
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed

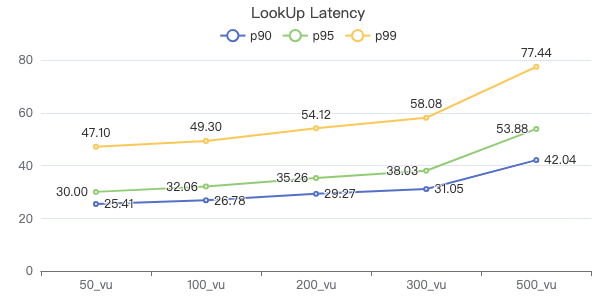
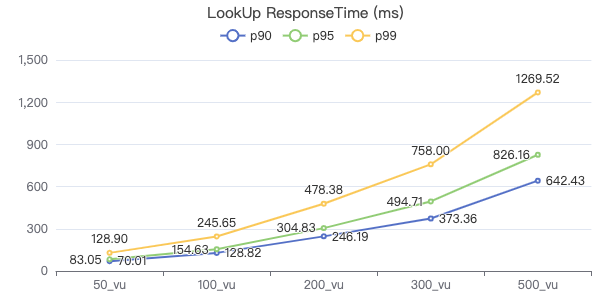
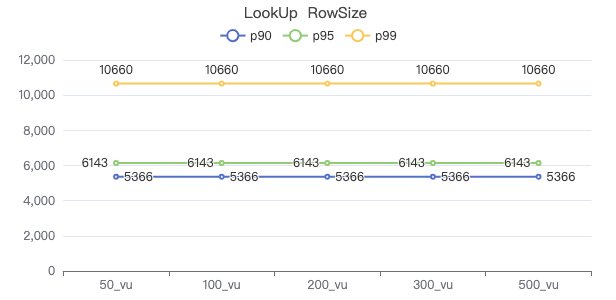
FETCH 点
FETCH PROP ON Person {} YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed

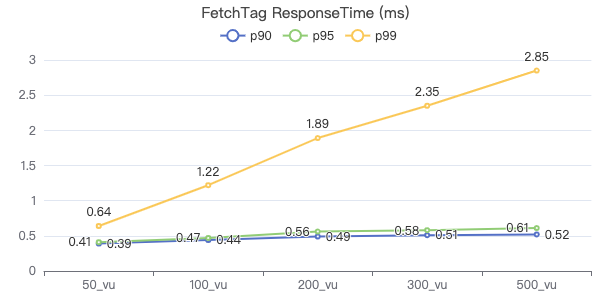
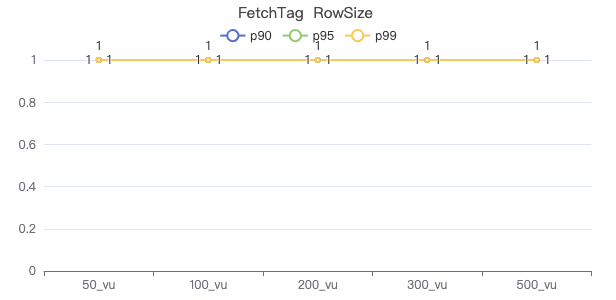
FETCH 边
FETCH PROP ON KNOWS {} -> {} YIELD KNOWS.creationDate


MATCH 索引
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN v
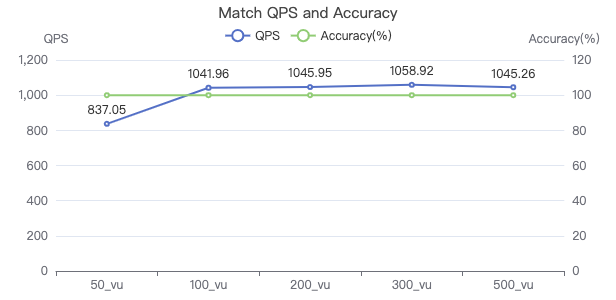

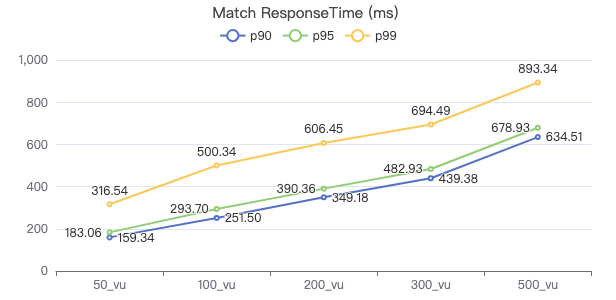

MATCH 一跳
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN v2


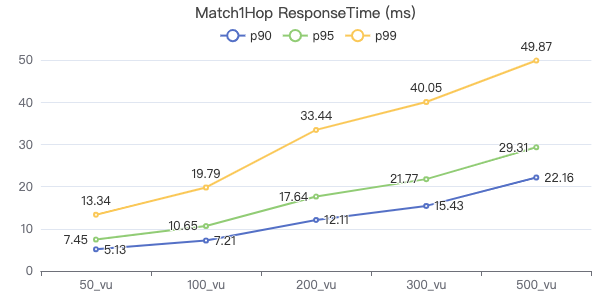

MATCH 两跳
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN v2



插入点
INSERT VERTEX Comment (creationDate, locationIP, browserUsed, content, length) VALUES {}:('{}', '{}', '{}', '{}', {})
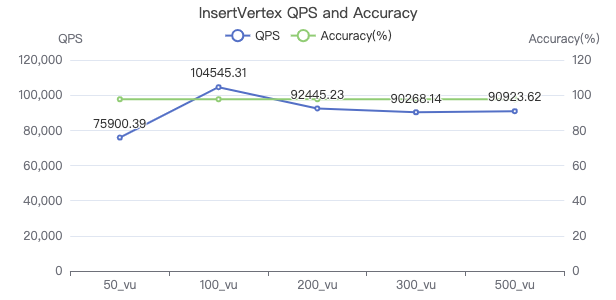
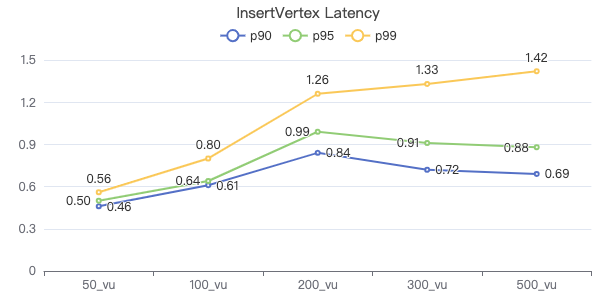
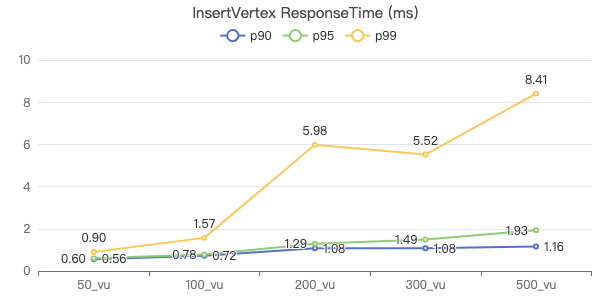
插入边
INSERT EDGE LIKES (creationDate) VALUES {}→{}:('{}')
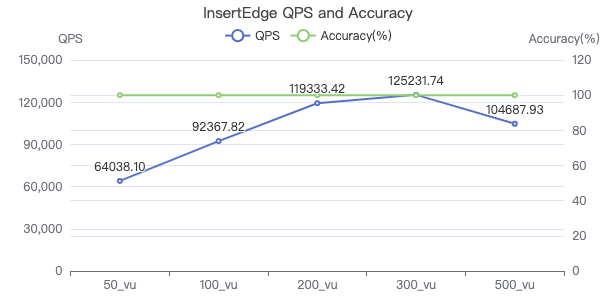


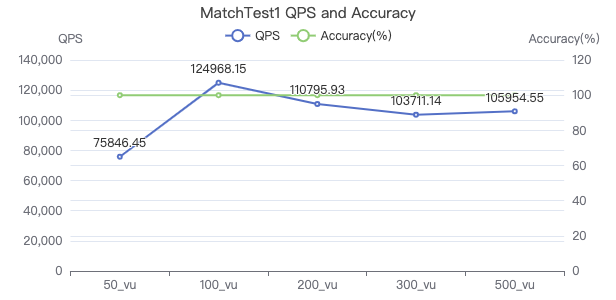
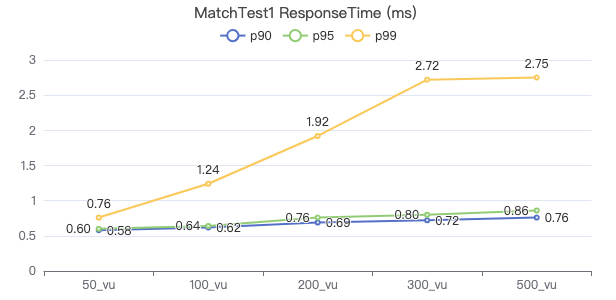
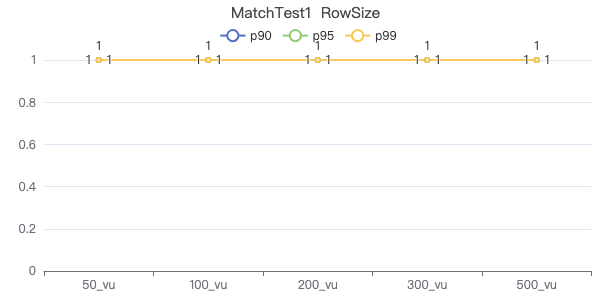
MatchTest 1
match (v:Person) where id(v) == {} return count(v.Person.firstName)
吞吐率
服务端耗时(ms)

客户端耗时(ms)
The request returns the number of rows
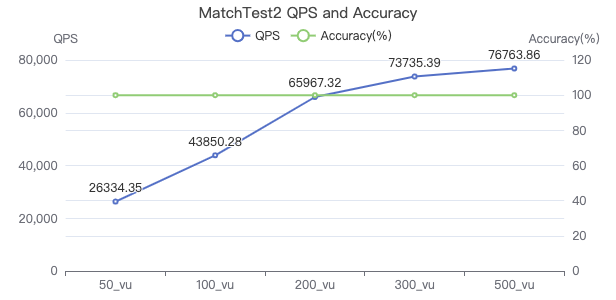
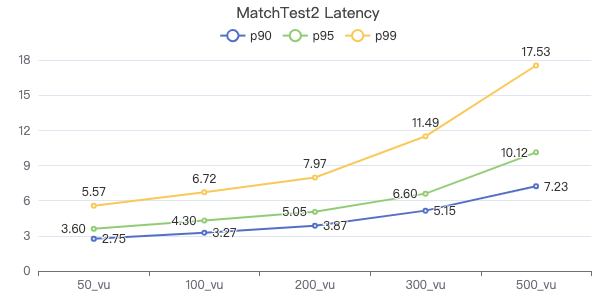
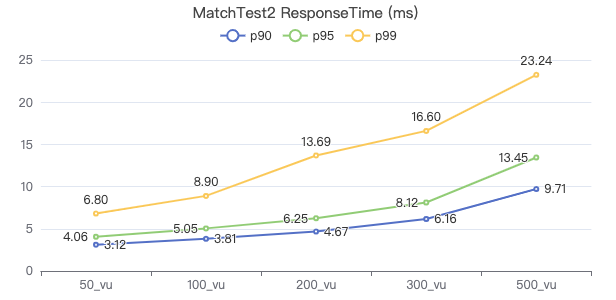
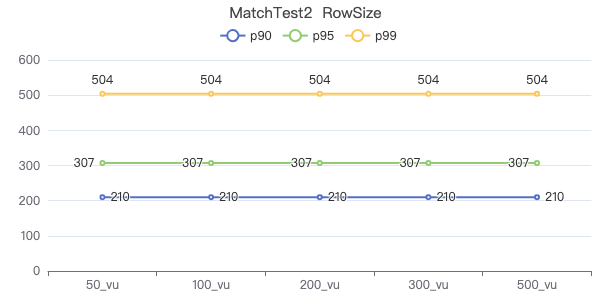
MatchTest 2
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' return length(v.Person.browserUsed) + length(v2.Person.gender)
吞吐率
服务端耗时(ms)
客户端耗时(ms)
The request returns the number of rows
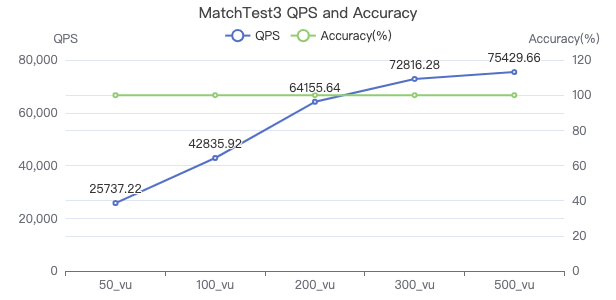
MatchTest 3
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' with v, v2 as v3 return length(v.Person.browserUsed) + (v3.Person.gender)
吞吐率
服务端耗时(ms)

客户端耗时(ms)

The request returns the number of rows

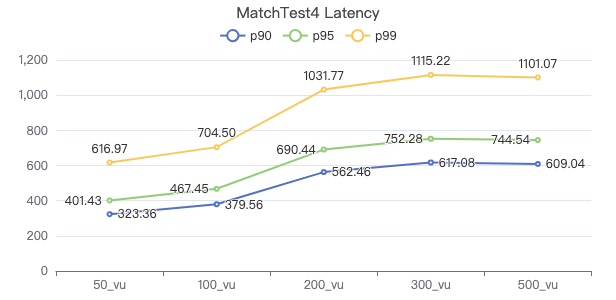
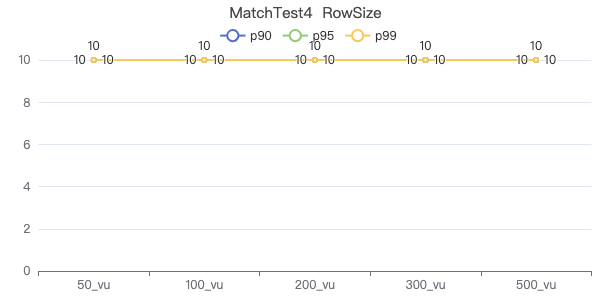
MatchTest 4
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} OPTIONAL MATCH (n)<-[:KNOWS]-(l) RETURN length(m.Person.lastName) AS n1, length(n.Person.lastName) AS n2, l.Person.creationDate AS n3 ORDER BY n1, n2, n3 LIMIT 10
吞吐率

服务端耗时(ms)
客户端耗时(ms)

The request returns the number of rows
MatchTest 5
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} MATCH (n)-[:KNOWS]-(l) WITH m AS x, n AS y, l RETURN x.Person.firstName AS n1, y.Person.firstName AS n2, CASE WHEN l.Person.firstName is not null THEN l.Person.firstName WHEN l.Person.gender is not null THEN l.Person.birthday ELSE 'null' END AS n3 ORDER BY n1, n2, n3 LIMIT 10
吞吐率
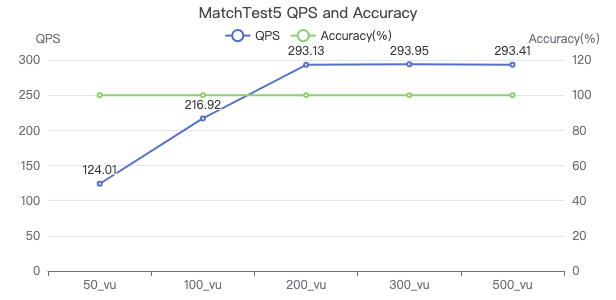
服务端耗时(ms)
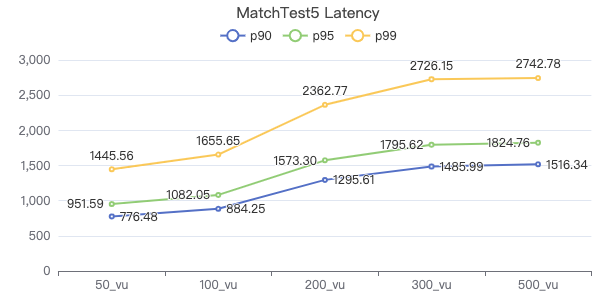
客户端耗时(ms)

The request returns the number of rows
3.2.0 vs 3.1.0(Baseline)
以下数据选取 P99 值.
Query edge properties
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate
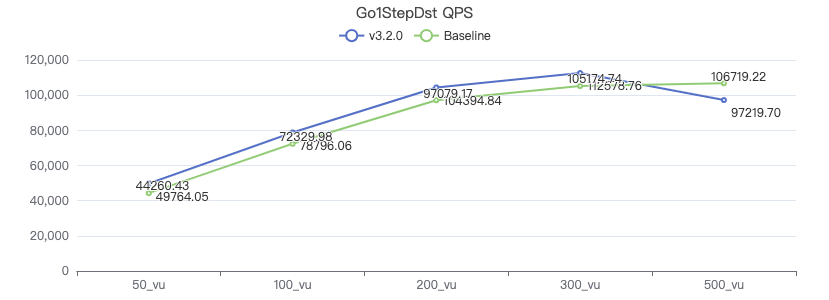
一跳·吞吐率

一跳·服务端耗时(ms)
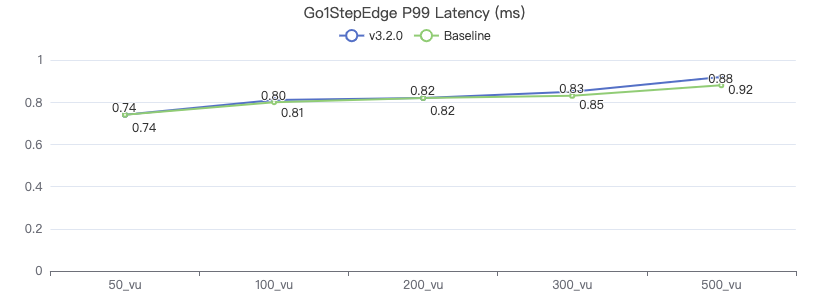
一跳·客户端耗时(ms)

二跳·吞吐率

二跳·服务端耗时(ms)

二跳·客户端耗时(ms)
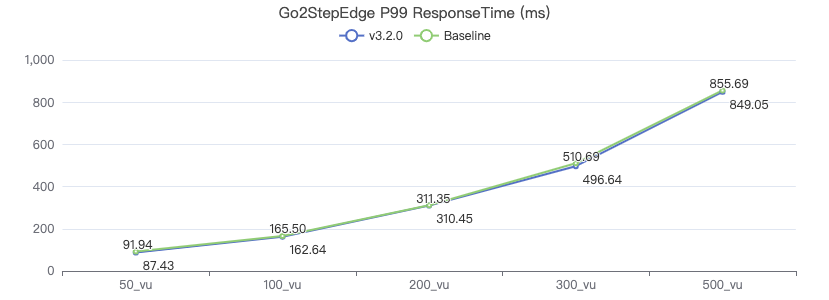
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)

Query the attribute with destination point
GO {} STEP FROM {} OVER KNOWS yield $$.Person.firstName
一跳·吞吐率
一跳·服务端耗时(ms)
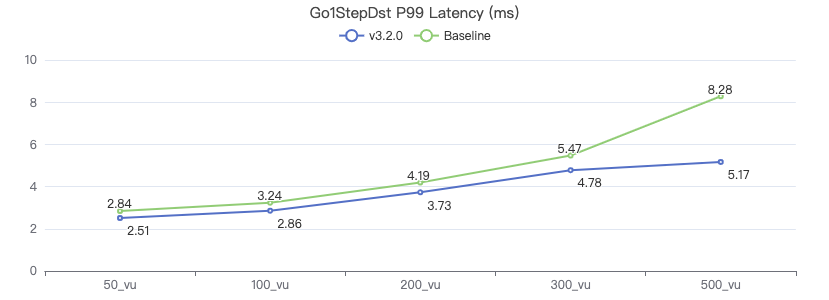
一跳·客户端耗时(ms)
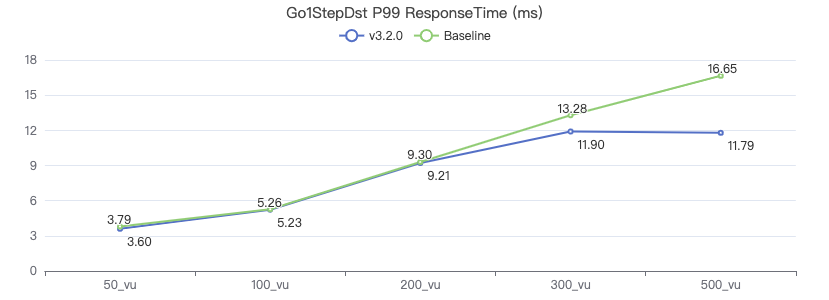
二跳·吞吐率

二跳·服务端耗时(ms)
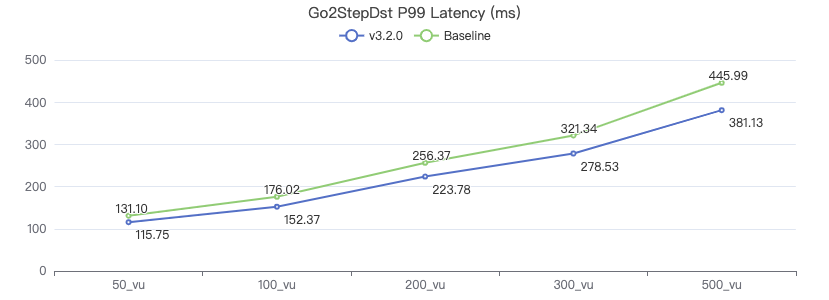
二跳·客户端耗时(ms)
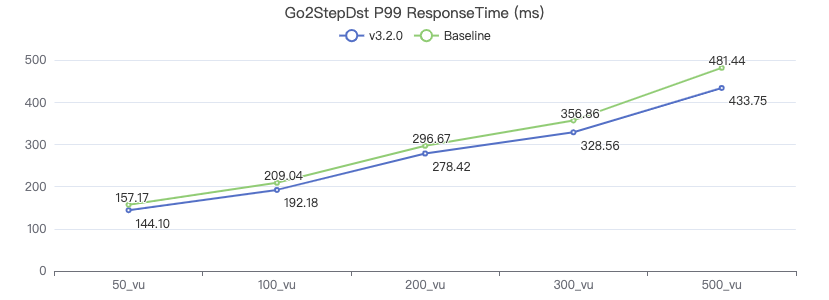
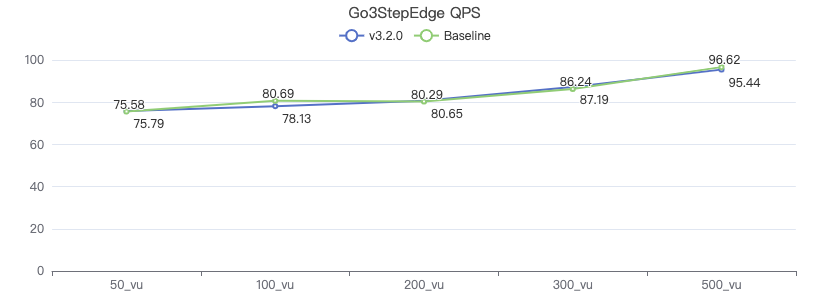
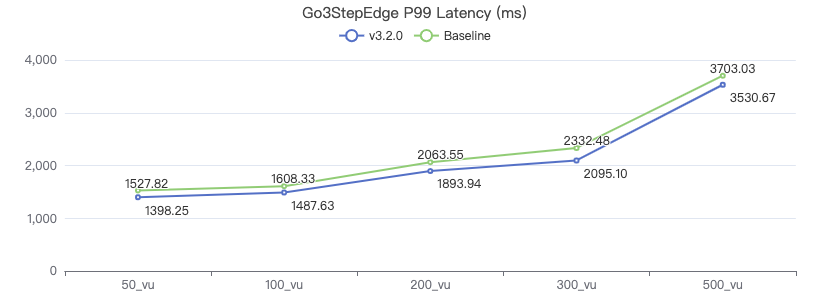
三跳·吞吐率
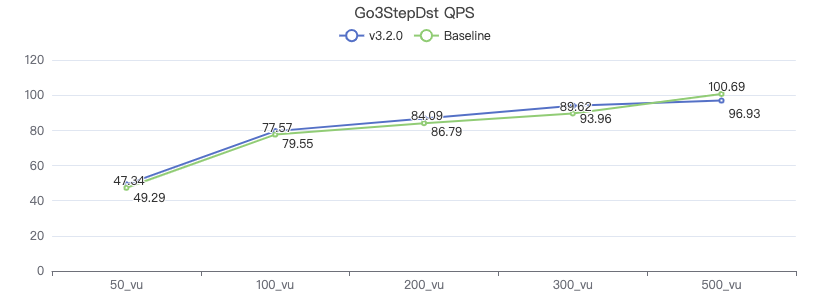
三跳·服务端耗时(ms)

三跳·客户端耗时(ms)

Query edge properties+Destination point attribute
GO {} STEP FROM {} OVER KNOWS yield DISTINCT KNOWS.creationDate as t, $$.Person.firstName, $$.Person.lastName, $$.Person.birthday as birth | order by $-.t, $-.birth | limit 10
一跳·吞吐率
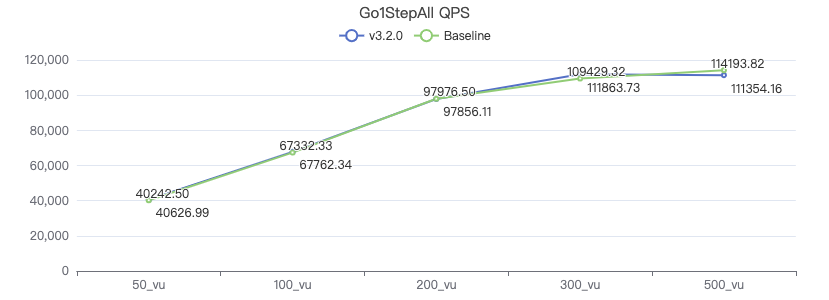
一跳·服务端耗时(ms)
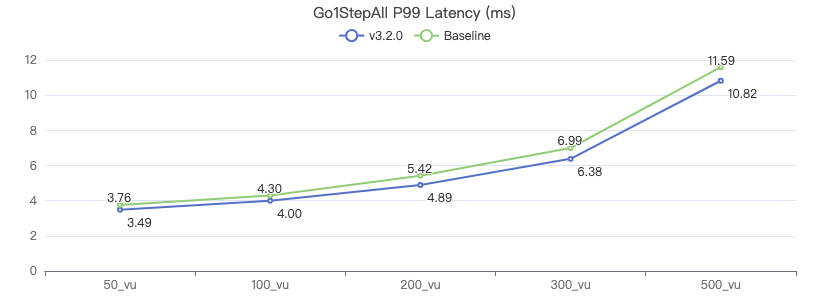
一跳·客户端耗时(ms)
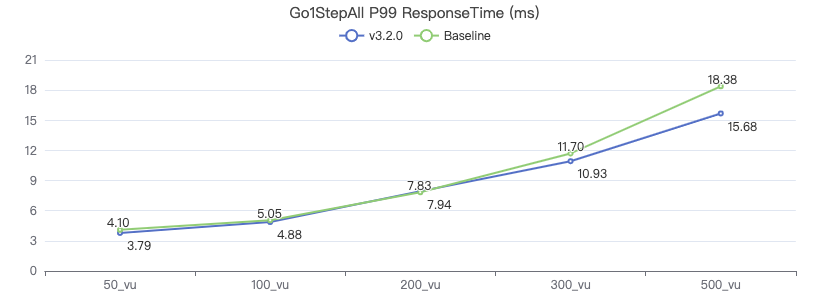
二跳·吞吐率
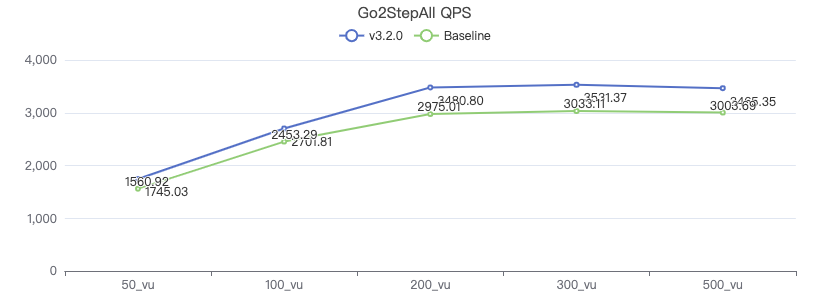
二跳·服务端耗时(ms)
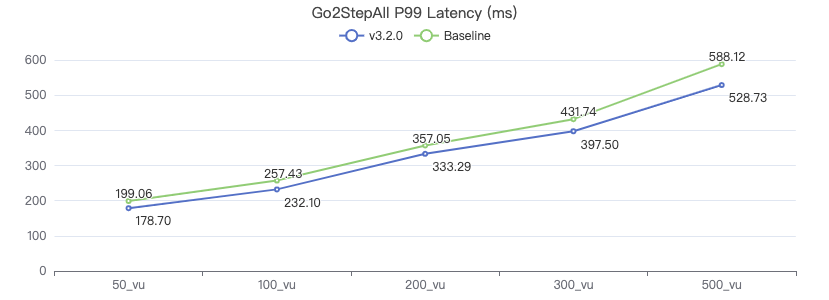
二跳·客户端耗时(ms)

三跳·吞吐率

三跳·服务端耗时(ms)

三跳·客户端耗时(ms)

LOOKUP
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed

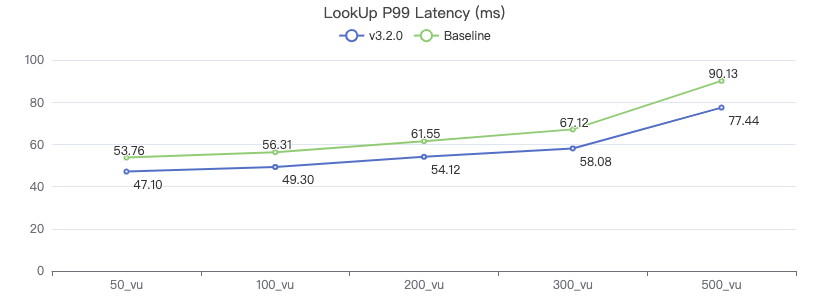
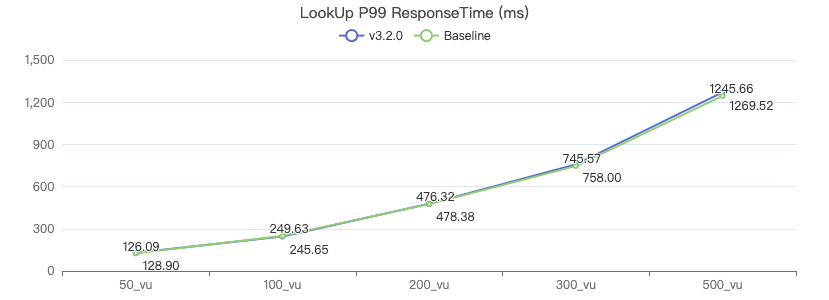
FETCH 点
FETCH PROP ON Person {} YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed

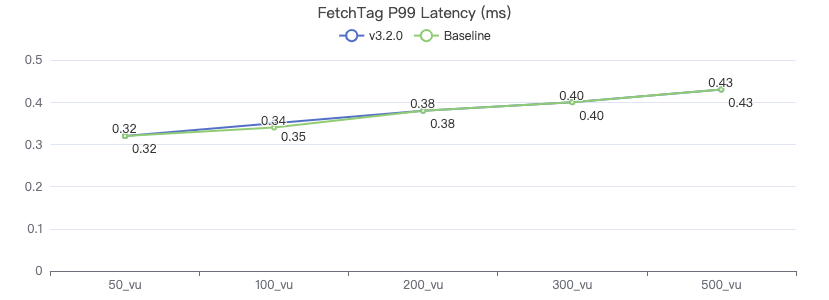

FETCH 边
FETCH PROP ON KNOWS {} -> {} YIELD KNOWS.creationDate


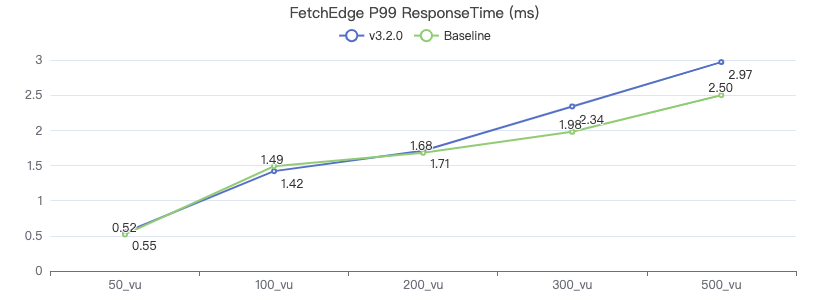
MATCH 索引
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN v
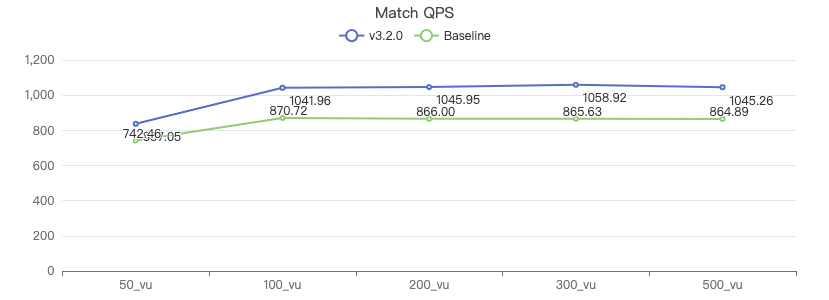
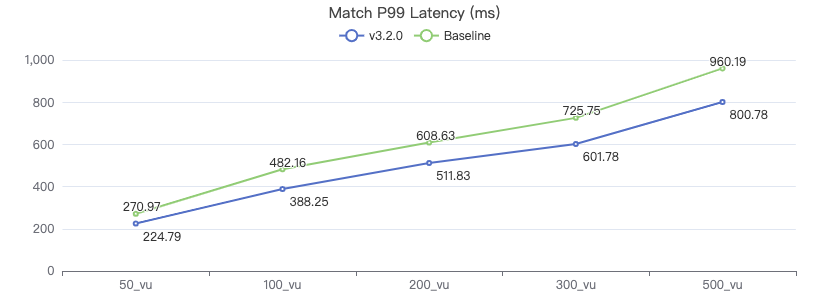
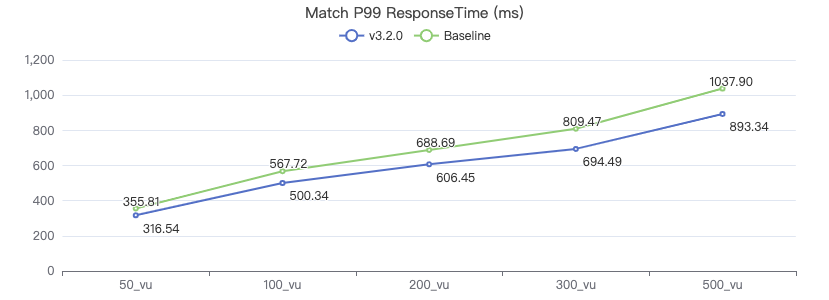
MATCH 一跳
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN v2
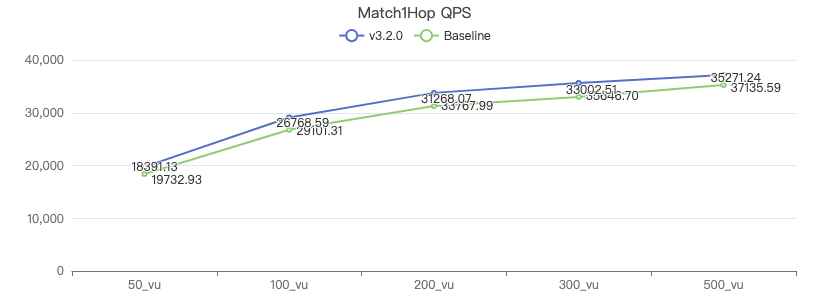
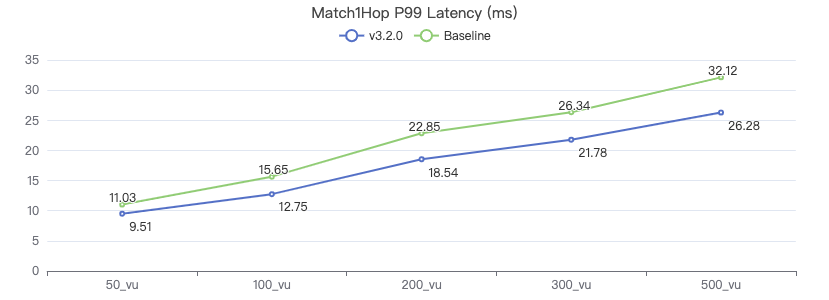
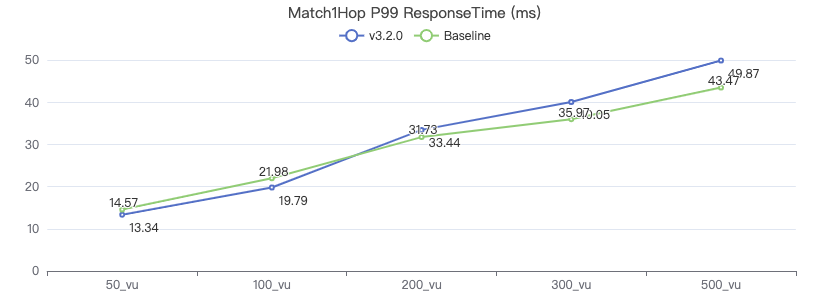
MATCH 两跳
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN v2

插入点
INSERT VERTEX Comment (creationDate, locationIP, browserUsed, content, length) VALUES {}:('{}', '{}', '{}', '{}', {})

插入边
INSERT EDGE LIKES (creationDate) VALUES {}→{}:('{}')

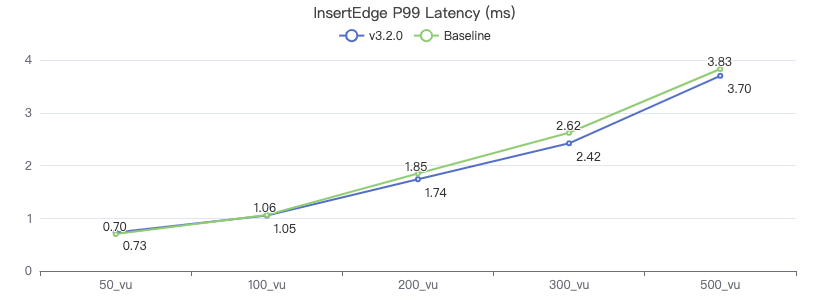
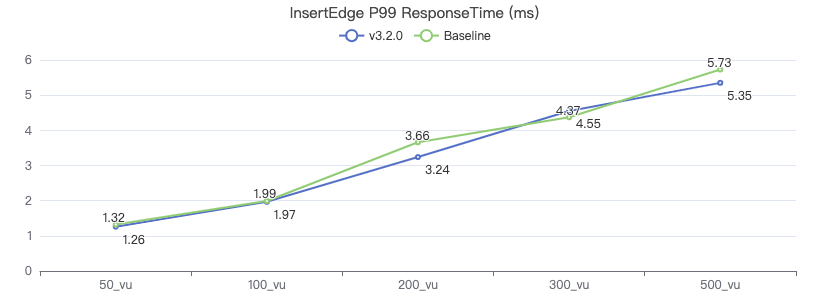
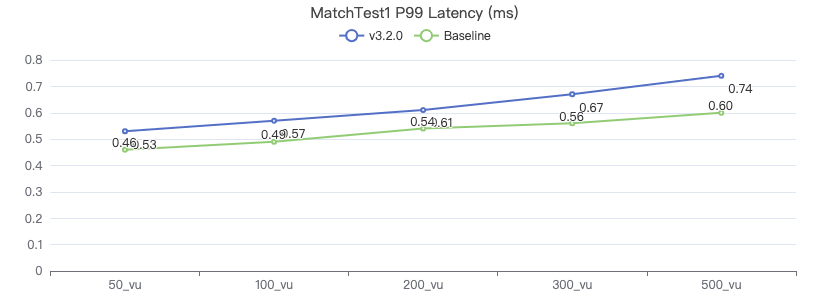
MatchTest 1
match (v:Person) where id(v) == {} return count(v.Person.firstName)


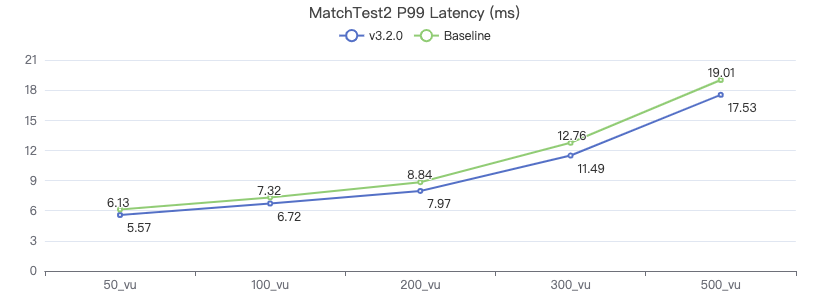
MatchTest 2
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' return length(v.Person.browserUsed) + length(v2.Person.gender)

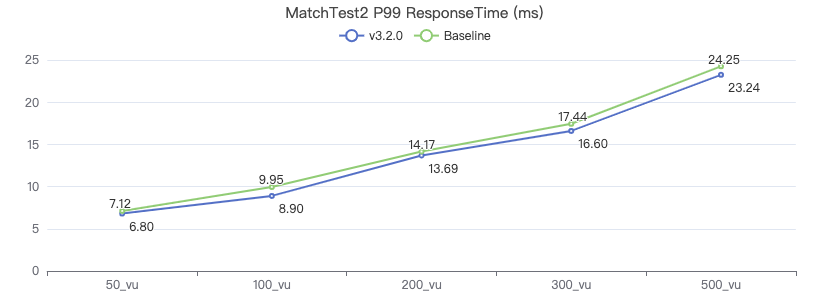
MatchTest 3
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' with v, v2 as v3 return length(v.Person.browserUsed) + (v3.Person.gender)
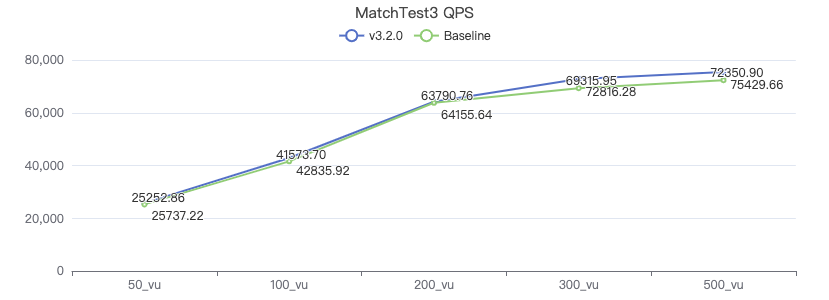


MatchTest 4
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} OPTIONAL MATCH (n)<-[:KNOWS]-(l) RETURN length(m.Person.lastName) AS n1, length(n.Person.lastName) AS n2, l.Person.creationDate AS n3 ORDER BY n1, n2, n3 LIMIT 10
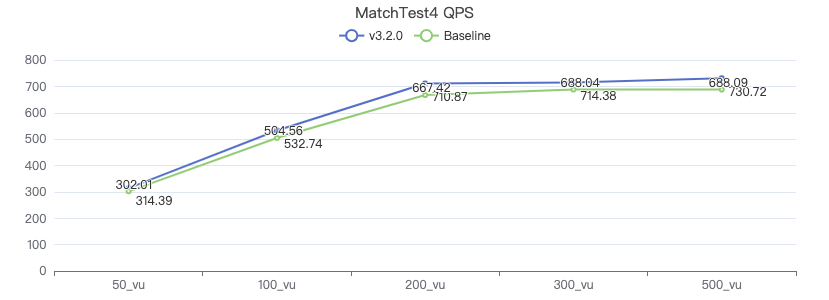
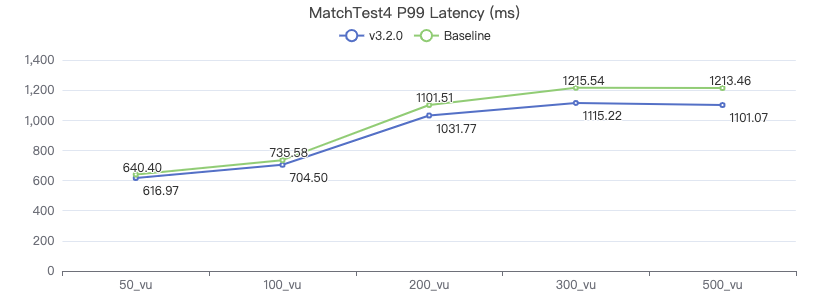
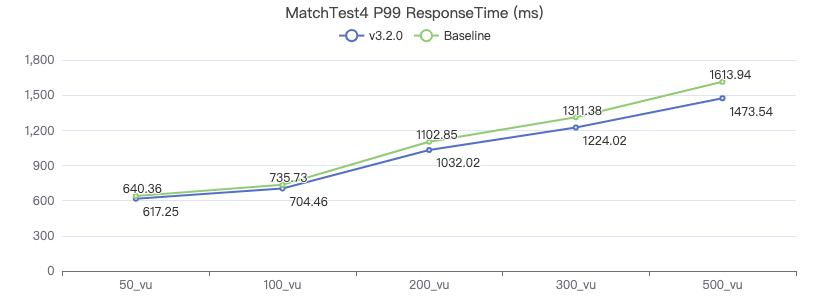
MatchTest 5
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} MATCH (n)-[:KNOWS]-(l) WITH m AS x, n AS y, l RETURN x.Person.firstName AS n1, y.Person.firstName AS n2, CASE WHEN l.Person.firstName is not null THEN l.Person.firstName WHEN l.Person.gender is not null THEN l.Person.birthday ELSE 'null' END AS n3 ORDER BY n1, n2, n3 LIMIT 10
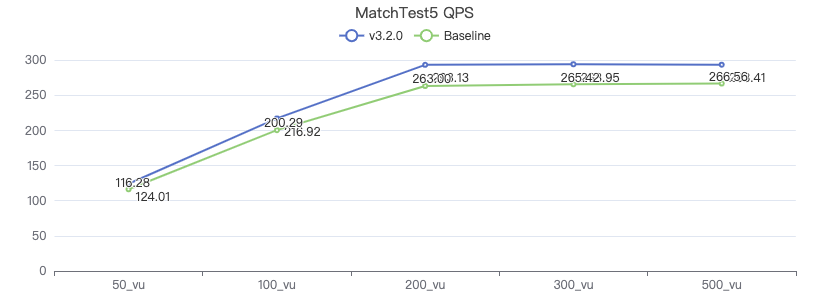
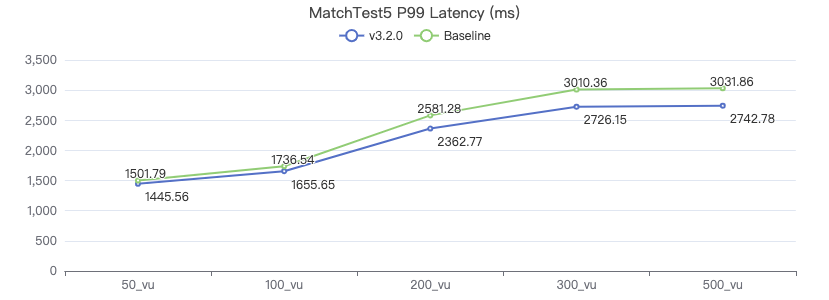
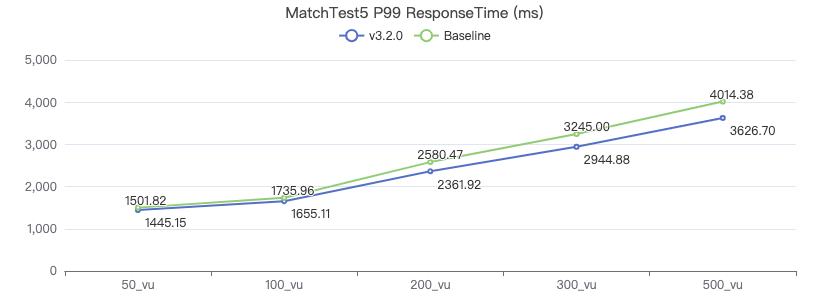
新增测试用例
测试Use cases and results(新增case)
Query edge properties_count
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate | return count(*) ;
一跳·吞吐率
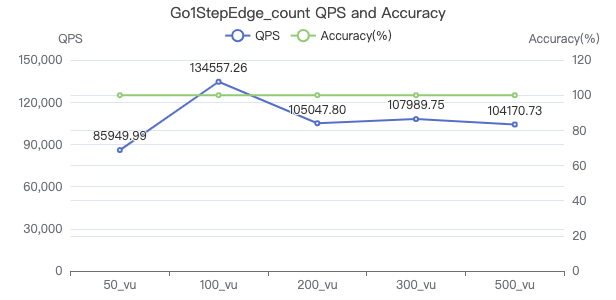
一跳·服务端耗时(ms)
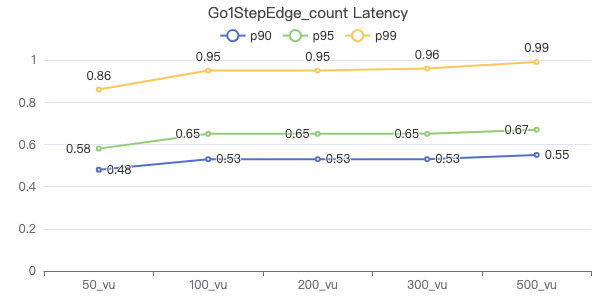
一跳·客户端耗时(ms)
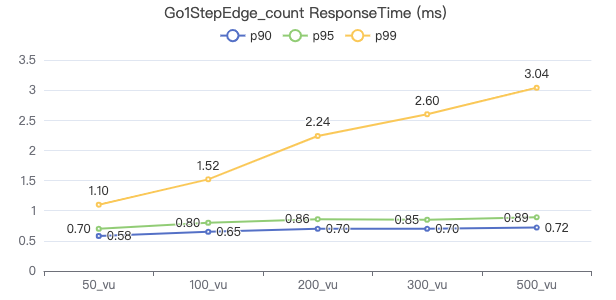
一跳·The request returns the number of rows

二跳·吞吐率
二跳·服务端耗时(ms)
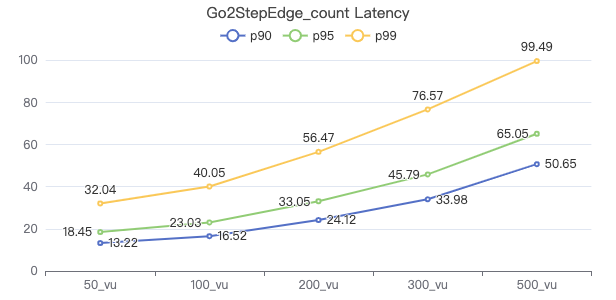
二跳·客户端耗时(ms)
二跳·The request returns the number of rows
三跳·吞吐率

三跳·服务端耗时(ms)
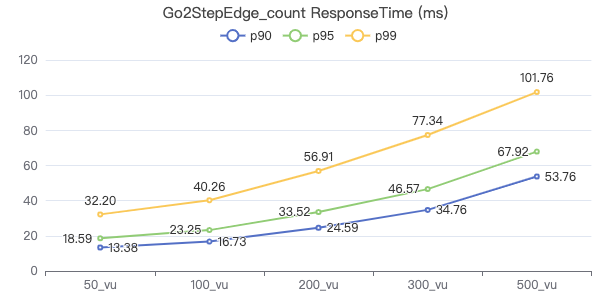
三跳·客户端耗时(ms)
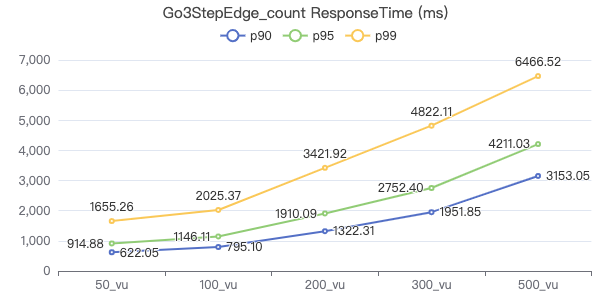
三跳·The request returns the number of rows
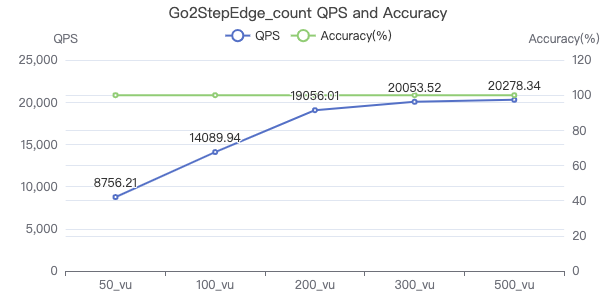
Query the attribute with destination point_count
GO 1 STEP FROM {} OVER KNOWS yield $$.Person.firstName | return count(*) 一跳·吞吐率

一跳·服务端耗时(ms)

一跳·客户端耗时(ms)
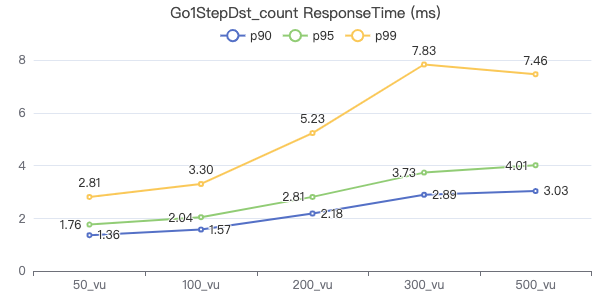
一跳·The request returns the number of rows
二跳·吞吐率

二跳·服务端耗时(ms)
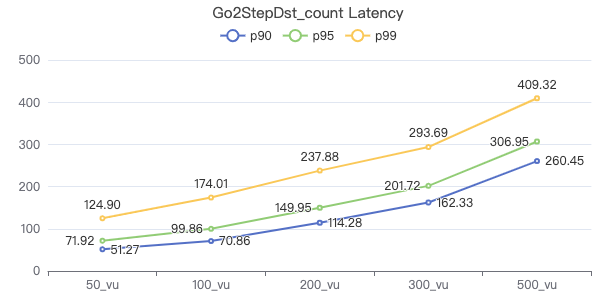
二跳·客户端耗时(ms)
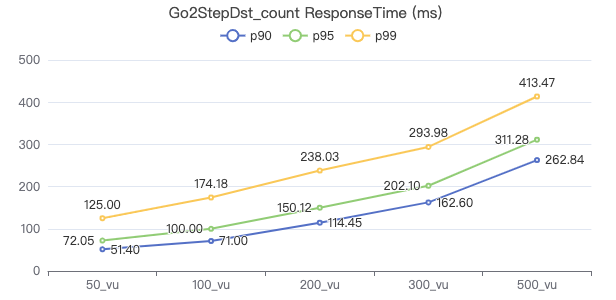
二跳·The request returns the number of rows

三跳·吞吐率

三跳·服务端耗时(ms)
三跳·客户端耗时(ms)

三跳·The request returns the number of rows
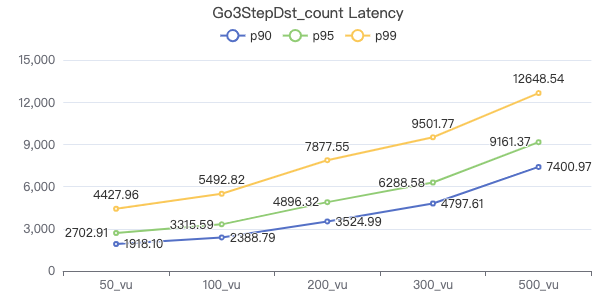
LOOKUP_count
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName | count(*)



Match_count
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN count(*)
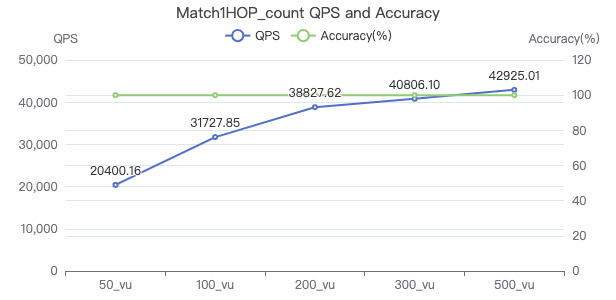
Match1Hop_count
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
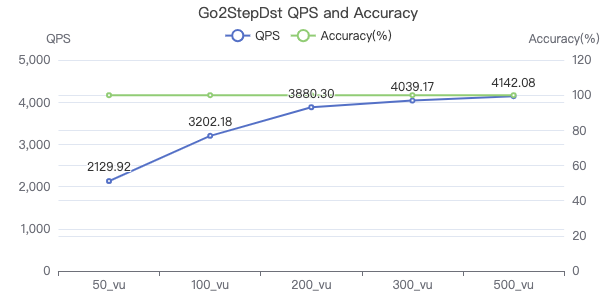
吞吐率
服务端耗时(ms)

客户端耗时(ms)
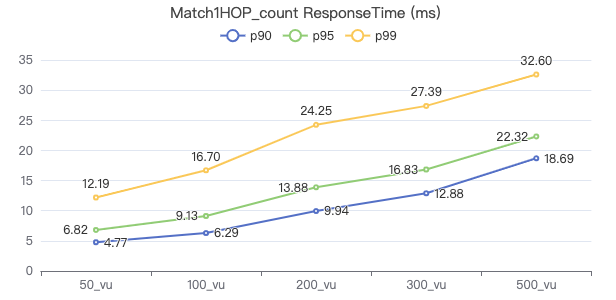
The request returns the number of rows

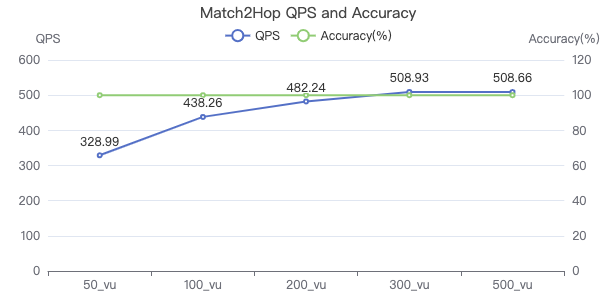
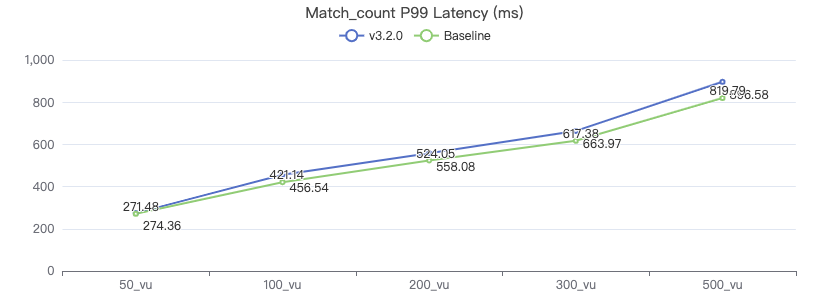
Match2Hop_count
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率

服务端耗时(ms)
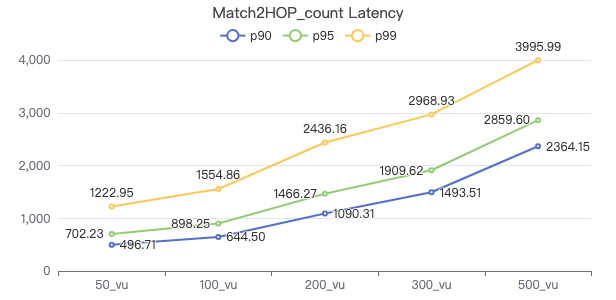
客户端耗时(ms)
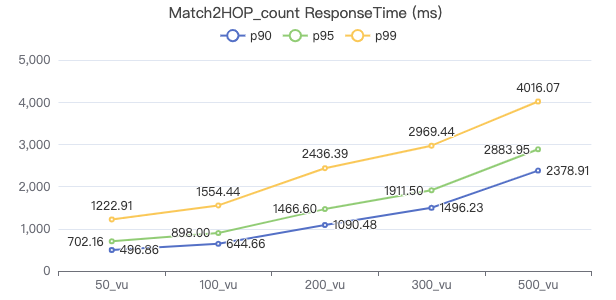
The request returns the number of rows
3.2.0 vs 3.1.0(新增case)
Query edge properties_count
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate | return count(*) ;
一跳·吞吐率

一跳·服务端耗时(ms)

一跳·客户端耗时(ms)
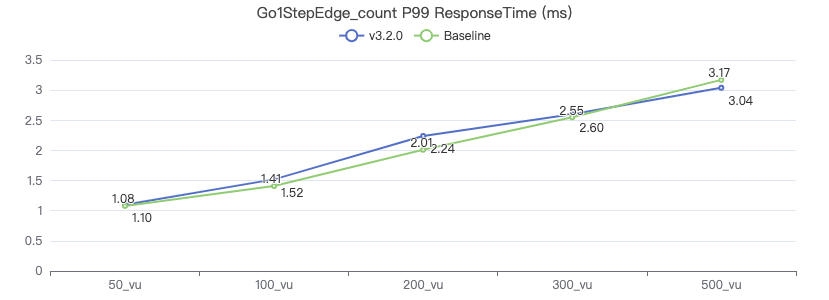
二跳·吞吐率

二跳·服务端耗时(ms)

二跳·客户端耗时(ms)
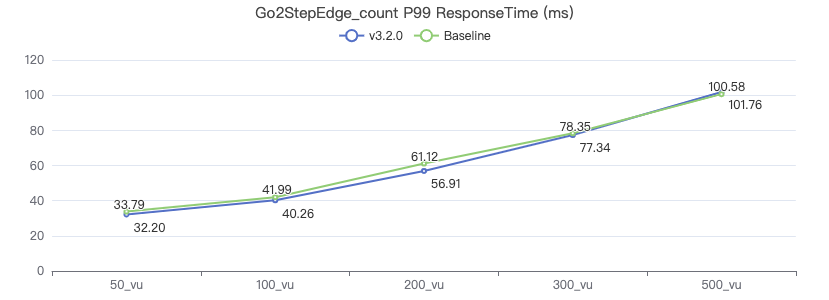
三跳·吞吐率

三跳·服务端耗时(ms)

三跳·客户端耗时(ms)
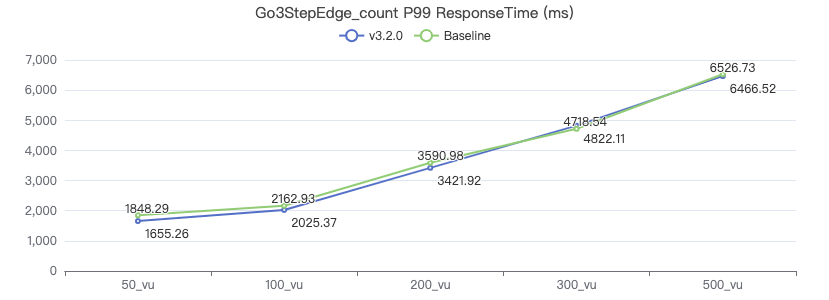
Query the attribute with destination point_count
GO 1 STEP FROM {} OVER KNOWS yield $$.Person.firstName | return count(*) 一跳·吞吐率
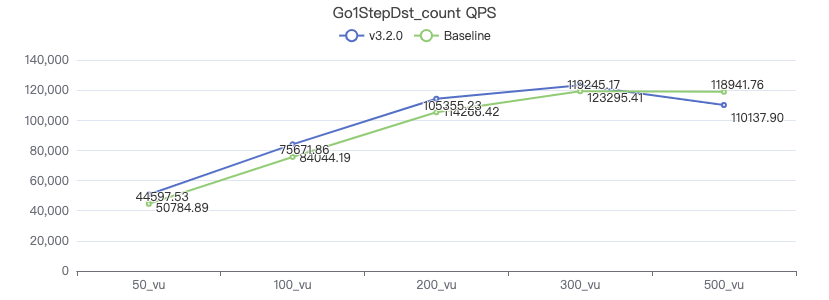
一跳·服务端耗时(ms)

一跳·客户端耗时(ms)

二跳·吞吐率

二跳·服务端耗时(ms)
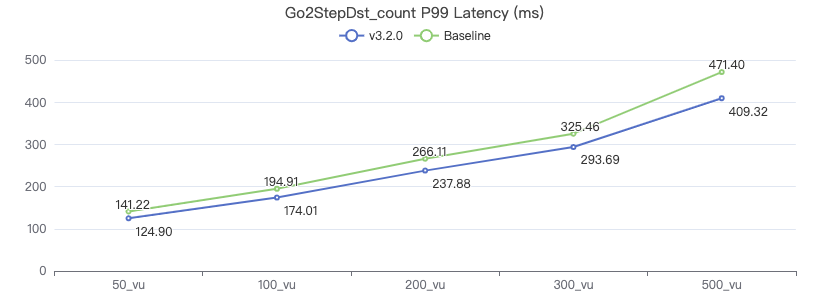
二跳·客户端耗时(ms)
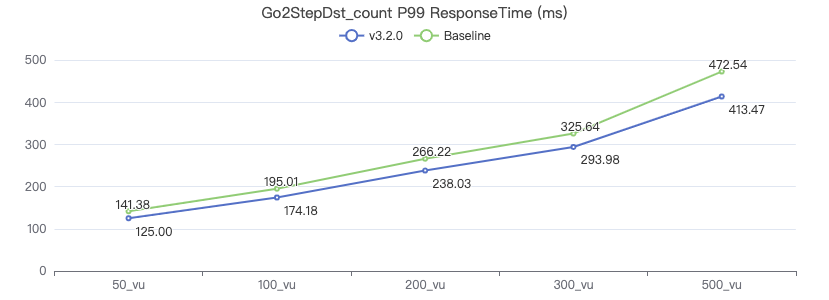
三跳·吞吐率
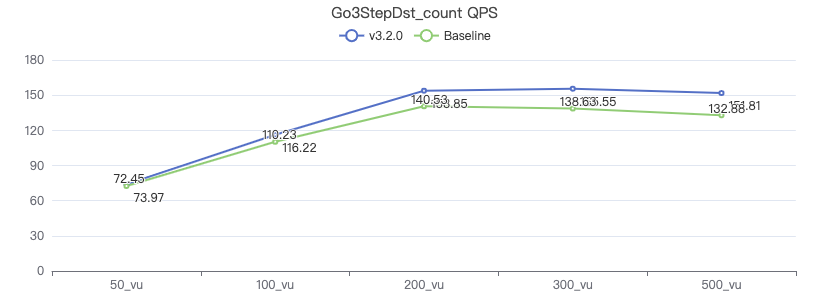
三跳·服务端耗时(ms)

三跳·客户端耗时(ms)
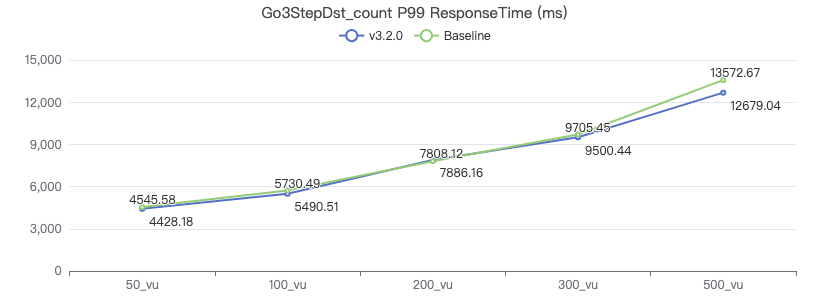
LOOKUP_count
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName | count(*)

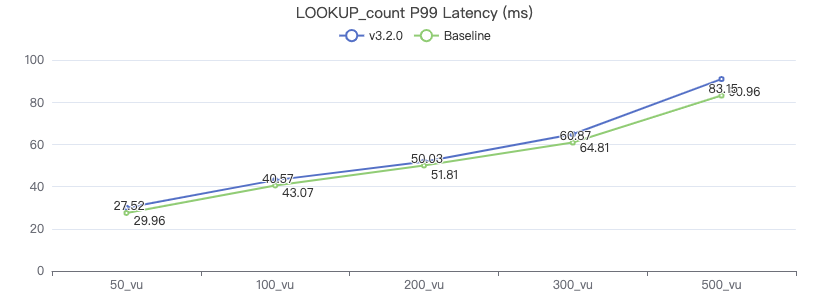
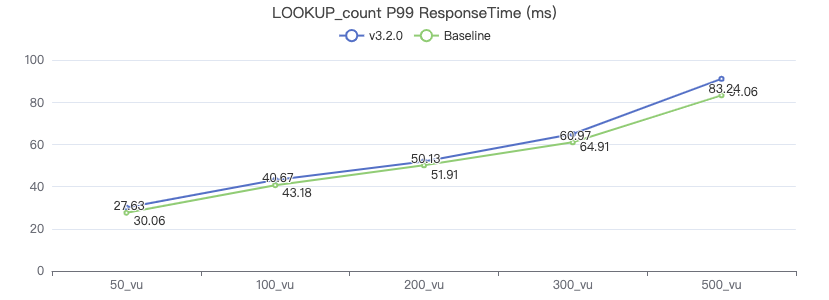
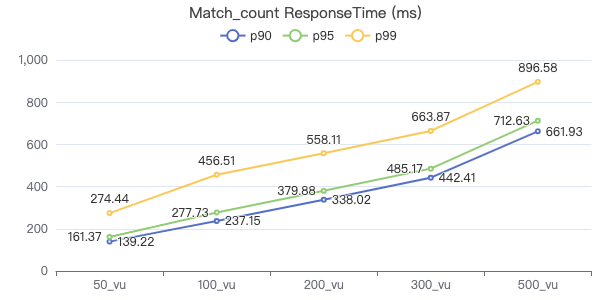
Match_count
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN count(*)


Match1Hop_count
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率

服务端耗时(ms)

客户端耗时(ms)

Match2Hop_count
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率

服务端耗时(ms)
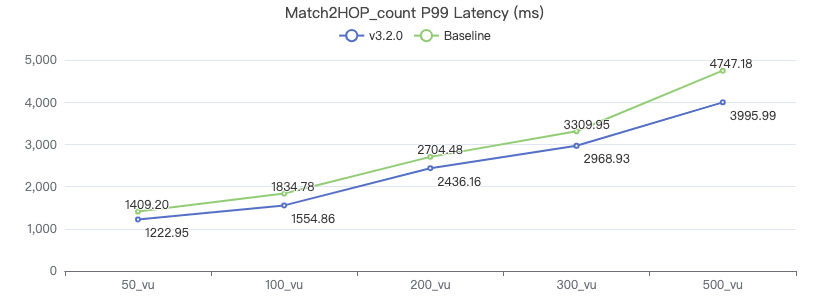
客户端耗时(ms)

交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
title: "NebulaGraph v3.2.0 性能报告" date: 2022-07-28 description: "v3.2.0 The version optimizes the calculation pushdown for point edges,The performance is generally better v3.1.0 版本有所提升.overall use case Latency The performance has been improved to a certain extent,time reduction by approx. 5%~10%;Match 索引及 Match2Hop 的 QPS 增幅约 20%." tags: ["性能测评"] author: "NebulaGraph 官方"
本文系 NebulaGraph 社区版 v3.2.0 的性能测试报告.
本文目录
总结
测试环境
测试数据
- 关于LDBC-SNB
Nebula Commit
测试说明
基线测试
- Use cases and results
- Query edge properties
- Query the attribute with destination point
- Query edge properties+Destination point attribute
- LOOKUP
- FETCH点
- FETCH边
- MATCH索引
- MATCH一跳
- MATCH两跳
- 插入点
- 插入边
- MatchTest1
- MatchTest2
- MatchTest3
- MatchTest4
- MatchTest5
- Use cases and results
3.2.0 vs 3.1.0(Baseline)
- Query edge properties
- Query the attribute with destination point
- Query edge properties+Destination point attribute
- LOOKUP
- FETCH点
- FETCH边
- MATCH索引
- MATCH一跳
- MATCH两跳
- 插入点
- 插入边
- MatchTest1
- MatchTest2
- MatchTest3
- MatchTest4
- MatchTest5
新增测试用例
- 测试Use cases and results(新增case)
- Query edge properties_count
- Query the attribute with destination point_count
- LOOKUP_count
- Match_count
- Match1Hop_count
- Match2Hop_count
- 3.2.0 vs 3.1.0(新增case)
- Query edge properties_count
- Query the attribute with destination point_count
- LOOKUP_count
- Match_count
- Match1Hop_count
- Match2Hop_count
- 测试Use cases and results(新增case)
总结
v3.2.0 The version optimizes the calculation pushdown for point edges,The performance is generally better v3.1.0 The version has slightly increased,主要表现如下:
overall use case Latency Performance has been slightly improved,time reduction by approx. 5%~10%
Match 索引及 Match2Hop 的 QPS 增幅约 20%
Added to this report go 、match、lookup 查询返回 count 的用例,同时新增了 RowSize 指标,It can be analyzed in combination with other indicators「网络回传结果时长 + 客户端反序列化结果时长」对 QPS 的影响.
from the performance graph,Some use cases can be seen QPS 大于 10w will drop suddenly,Because the single-machine pressure test is currently used,大于 10w Afterwards, the client will become bottlenecked and no more requests can be made,In the future, multiple pressure testing machines can be considered for testing.
测试环境
服务器和压测机皆为物理机
测试数据
测试数据采用 LDBC-SNB SF100 数据集,SF100数据集大小为 100G,共有 282,386,021 个点以及 1,775,513,185 条边.测试用的图空间分区数为 24,副本数为 3.
关于LDBC-SNB
关联数据基准委员会(LDBC,Linked Data Benchmark Council),是图(Graph)和 RDF 数据管理的基准指南制定者.社交网路基准(SNB,Social Network Benchmark)是关联数据基准委员会(LDBC)开发的软件基准(Benchmark)之一.关于 LDBC-SNB 数据集,具体请参考以下文档:
NebulaGraph Commit
- nebula-graphd version ef6d6a0
- nebula-storaged version ef6d6a0
- nebula-metad version ef6d6a0
测试说明
图表中横坐标轴的“50_vu“、“100_vu“等中的”vu“表示的是 k6 使用的概念“virtual user”,即性能测试中的并发数;50_vu 表示 50 个并发用户,100_vu 表示 100 个并发用户,以此类推…
性能基线使用正式发布的 3.1.0 版本
ResponseTime=Latency(服务端处理时长)+网络回传结果时长+客户端反序列化结果时长
基线测试
注:Explanation of the words involved in the figure below
- QPS 即吞吐率
- Latency 即服务端耗时
- ResponseTime 即客户端耗时
- RowSize 即The request returns the number of rows
Use cases and results
Query edge properties
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate
一跳·吞吐率
一跳·服务端耗时(ms)
一跳·客户端耗时(ms)
一跳·The request returns the number of rows
两跳·吞吐率
两跳·服务端耗时(ms)
两跳·客户端耗时(ms)
两跳·The request returns the number of rows
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
三跳·The request returns the number of rows
Query the attribute with destination point
GO {} STEP FROM {} OVER KNOWS yield $$.Person.firstName
一跳·吞吐率
一跳·服务端耗时(ms)
一跳·客户端耗时(ms)
一跳·The request returns the number of rows
两跳·吞吐率
两跳·服务端耗时(ms)
两跳·客户端耗时(ms)
两跳·The request returns the number of rows
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
三跳·The request returns the number of rows
Query edge properties+Destination point attribute
GO {} STEP FROM {} OVER KNOWS yield DISTINCT KNOWS.creationDate as t, $$.Person.firstName, $$.Person.lastName, $$.Person.birthday as birth | order by $-.t, $-.birth | limit 10
一跳·吞吐率
一跳·服务端耗时(ms)
一跳·客户端耗时(ms)
一跳·The request returns the number of rows
二跳·吞吐率
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
二跳·The request returns the number of rows
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
三跳·The request returns the number of rows
LOOKUP
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed
FETCH 点
FETCH PROP ON Person {} YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed
FETCH 边
FETCH PROP ON KNOWS {} -> {} YIELD KNOWS.creationDate
MATCH 索引
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN v
MATCH 一跳
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN v2
MATCH 两跳
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN v2
插入点
INSERT VERTEX Comment (creationDate, locationIP, browserUsed, content, length) VALUES {}:('{}', '{}', '{}', '{}', {})
插入边
INSERT EDGE LIKES (creationDate) VALUES {}→{}:('{}')
MatchTest 1
match (v:Person) where id(v) == {} return count(v.Person.firstName)
吞吐率
服务端耗时(ms)
客户端耗时(ms)
The request returns the number of rows
MatchTest 2
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' return length(v.Person.browserUsed) + length(v2.Person.gender)
吞吐率
服务端耗时(ms)
客户端耗时(ms)
The request returns the number of rows
MatchTest 3
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' with v, v2 as v3 return length(v.Person.browserUsed) + (v3.Person.gender)
吞吐率
服务端耗时(ms)
客户端耗时(ms)
The request returns the number of rows
MatchTest 4
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} OPTIONAL MATCH (n)<-[:KNOWS]-(l) RETURN length(m.Person.lastName) AS n1, length(n.Person.lastName) AS n2, l.Person.creationDate AS n3 ORDER BY n1, n2, n3 LIMIT 10
吞吐率
服务端耗时(ms)
客户端耗时(ms)
The request returns the number of rows
MatchTest 5
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} MATCH (n)-[:KNOWS]-(l) WITH m AS x, n AS y, l RETURN x.Person.firstName AS n1, y.Person.firstName AS n2, CASE WHEN l.Person.firstName is not null THEN l.Person.firstName WHEN l.Person.gender is not null THEN l.Person.birthday ELSE 'null' END AS n3 ORDER BY n1, n2, n3 LIMIT 10
吞吐率
服务端耗时(ms)
客户端耗时(ms)
The request returns the number of rows
3.2.0 vs 3.1.0(Baseline)
以下数据选取 P99 值.
Query edge properties
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate
一跳·吞吐率
一跳·服务端耗时(ms)
一跳·客户端耗时(ms)
二跳·吞吐率
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
Query the attribute with destination point
GO {} STEP FROM {} OVER KNOWS yield $$.Person.firstName
一跳·吞吐率
一跳·服务端耗时(ms)
一跳·客户端耗时(ms)
二跳·吞吐率
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
Query edge properties+Destination point attribute
GO {} STEP FROM {} OVER KNOWS yield DISTINCT KNOWS.creationDate as t, $$.Person.firstName, $$.Person.lastName, $$.Person.birthday as birth | order by $-.t, $-.birth | limit 10
一跳·吞吐率
一跳·服务端耗时(ms)
一跳·客户端耗时(ms)
二跳·吞吐率
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
LOOKUP
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed
FETCH 点
FETCH PROP ON Person {} YIELD Person.firstName, Person.lastName, Person.gender, Person.birthday, Person.creationDate, Person.locationIP, Person.browserUsed
FETCH 边
FETCH PROP ON KNOWS {} -> {} YIELD KNOWS.creationDate
MATCH 索引
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN v
MATCH 一跳
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN v2
MATCH 两跳
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN v2
插入点
INSERT VERTEX Comment (creationDate, locationIP, browserUsed, content, length) VALUES {}:('{}', '{}', '{}', '{}', {})
插入边
INSERT EDGE LIKES (creationDate) VALUES {}→{}:('{}')
MatchTest 1
match (v:Person) where id(v) == {} return count(v.Person.firstName)
MatchTest 2
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' return length(v.Person.browserUsed) + length(v2.Person.gender)
MatchTest 3
match (v:Person)-[e:KNOWS]-(v2) where id(v) == {} and v2.Person.locationIP != 'yyy' with v, v2 as v3 return length(v.Person.browserUsed) + (v3.Person.gender)
MatchTest 4
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} OPTIONAL MATCH (n)<-[:KNOWS]-(l) RETURN length(m.Person.lastName) AS n1, length(n.Person.lastName) AS n2, l.Person.creationDate AS n3 ORDER BY n1, n2, n3 LIMIT 10
MatchTest 5
MATCH (m)-[:KNOWS]-(n) WHERE id(m)=={} MATCH (n)-[:KNOWS]-(l) WITH m AS x, n AS y, l RETURN x.Person.firstName AS n1, y.Person.firstName AS n2, CASE WHEN l.Person.firstName is not null THEN l.Person.firstName WHEN l.Person.gender is not null THEN l.Person.birthday ELSE 'null' END AS n3 ORDER BY n1, n2, n3 LIMIT 10
新增测试用例
测试Use cases and results(新增case)
Query edge properties_count
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate | return count(*) ;
一跳·吞吐率
一跳·服务端耗时(ms)
一跳·客户端耗时(ms)
一跳·The request returns the number of rows
二跳·吞吐率
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
二跳·The request returns the number of rows
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
三跳·The request returns the number of rows
Query the attribute with destination point_count
GO 1 STEP FROM {} OVER KNOWS yield $$.Person.firstName | return count(*) 一跳·吞吐率
一跳·服务端耗时(ms)
一跳·客户端耗时(ms)
一跳·The request returns the number of rows
二跳·吞吐率
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
二跳·The request returns the number of rows
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
三跳·The request returns the number of rows
LOOKUP_count
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName | count(*)
Match_count
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN count(*)
Match1Hop_count
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率
服务端耗时(ms)
客户端耗时(ms)
The request returns the number of rows
Match2Hop_count
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率
服务端耗时(ms)
客户端耗时(ms)
The request returns the number of rows
3.2.0 vs 3.1.0(新增case)
Query edge properties_count
GO {} STEP FROM {} OVER KNOWS yield KNOWS.creationDate | return count(*) ;
一跳·吞吐率
一跳·服务端耗时(ms)
一跳·客户端耗时(ms)
二跳·吞吐率
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
Query the attribute with destination point_count
GO 1 STEP FROM {} OVER KNOWS yield $$.Person.firstName | return count(*) 一跳·吞吐率
一跳·服务端耗时(ms)
一跳·客户端耗时(ms)
二跳·吞吐率
二跳·服务端耗时(ms)
二跳·客户端耗时(ms)
三跳·吞吐率
三跳·服务端耗时(ms)
三跳·客户端耗时(ms)
LOOKUP_count
LOOKUP ON Person WHERE Person.firstName == '{}' YIELD Person.firstName | count(*)
Match_count
MATCH (v:Person) WHERE v.Person.firstName == '{}' RETURN count(*)
Match1Hop_count
MATCH (v1:Person)-[e:KNOWS]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率
服务端耗时(ms)
客户端耗时(ms)
Match2Hop_count
MATCH (v1:Person)-[e:KNOWS*2]->(v2:Person) WHERE id(v1) == {} RETURN count(*)
吞吐率
服务端耗时(ms)
客户端耗时(ms)
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
NebulaGraph 的开源地址是 GitHub :https://github.com/vesoft-inc/nebula ,欢迎体验 and 给我们提建议~
边栏推荐
猜你喜欢

STM32 CAN过滤器配置详解
故障007:dexp导数莫名中断
![[Open class preview]: Research and application of super-resolution technology in the field of video quality enhancement](/img/fc/cd859efa69fa7b45f173de74c04858.png)
[Open class preview]: Research and application of super-resolution technology in the field of video quality enhancement

Towhee 每周模型

ECCV22|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
消息中间件解析 | 如何正确理解软件应用系统中关于系统通信的那些事?

Programmer's self-cultivation

脚本语言Lua的基础知识总结

《MySQL核心知识》第6章:查询语句

CAN通信标准帧和扩展帧介绍
随机推荐
Pytest电商项目实战(下)
The obstacles to put Istio into production and how we solve them
How to get the address of WeChat video account (link address of WeChat public account)
This article will take you to thoroughly clarify the working mechanism of certificates in Isito
观察者模式
关于亚马逊测评,你了解多少?
SCHEMA solves the puzzle
Process sibling data into tree data
数据湖 delta lake和spark版本对应关系
四足机器人软件架构现状分析
Dapr 与 NestJs ,实战编写一个 Pub & Sub 装饰器
ECCV22|只能11%的参数就能优于Swin,微软提出快速预训练蒸馏方法TinyViT
Qt获取文件夹下所有文件
MVVM响应式
PanGu-Coder:函数级的代码生成模型
iframe标签属性说明 详解[通俗易懂]
R language ggplot2 visualization: use ggpubr package ggscatter function visualization scatterplot, use xscale wasn't entirely specified X axis measurement adjustment function, set the X coordinate for
多线程案例——定时器
formatdatetime函数 mysql(date sub函数)
Why does the maximum plus one equal the minimum