当前位置:网站首页>Towhee 每周模型
Towhee 每周模型
2022-08-01 12:15:00 【Zilliz】
本周将继续推荐5个视频领域的 SoTA 模型:
MPViT 通过多嵌入和多路径探索多种视觉任务、 BridgeFormer 利用别样的选择题训练方式加速视频文本检索、 SVT 用自蒸馏让视觉 Transformer 训练摆脱对比学习、CoFormer 融合动作分类和物体检测来识别视频中的情境、ActionCLIP 用检索任务开拓动作识别新思路。
如果你觉得我们分享的内容还不错,请不要吝啬给我们一些免费的鼓励:点赞、喜欢、或者分享给你的小伙伴。
项目指路
https://github.com/towhee-io/towhee/blob/main/towhee/models/README_CN.md
领跑多种视觉任务,CVPR 2022 最新 backbone:多块嵌入、多路径的 MPViT
出品人:Towhee 技术团队 张晨、顾梦佳
MPViT (Multi-path Vision Transformer, 多路径 Vision Transformer)¹ 专注于使用视觉 Transformers 有效地表示多尺度特征以进行密集预测任务。广泛的实验结果表明 MPViT 可以作为各种视觉任务的多功能骨干网络,比如在图像分类、目标检测、实例分割、和语义分割上均能取得 state-of-the-art 结果。作者团队开放了tiny、xsmall、small、base 几种不同大小的模型预训练权重,这些轻量的预训练模型通过较小的参数量和计算量就能取得很好的精度。
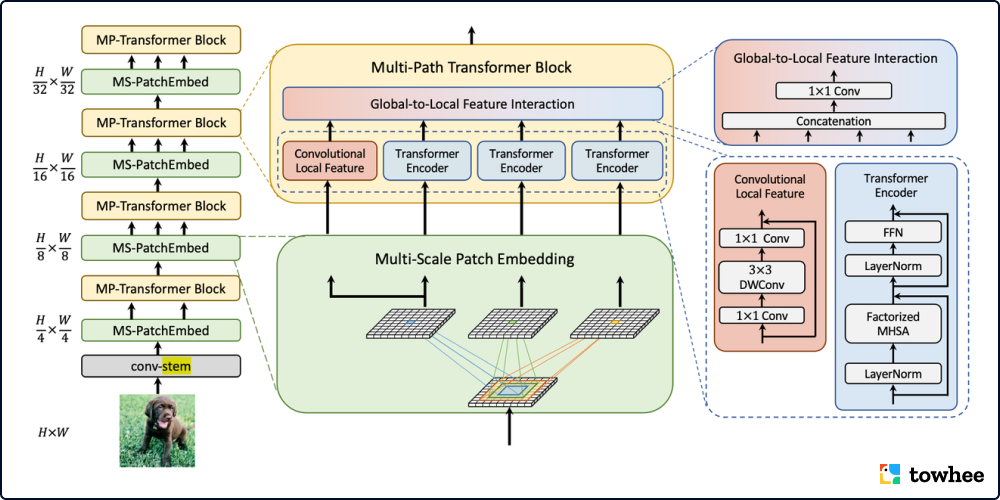
MPViT 通过探索多尺度块嵌入与多路径结构,结合重叠卷积块嵌入,可以同时对不同尺度、相同序列长度特征进行嵌入聚合。不同尺度的 Token 分别送入到不同的 Transformer 模块(即并行多路径结构)中,以构建同特征层级的粗粒度与细粒度特征的。多尺度 patch embedding 通过重叠卷积操作同时对不同大小的视觉 patch 进行 token 化,在适当调整后得到具有相同序列长度(即特征分辨率)的特征。卷积的填充/步幅。然后,来自不同尺度的 token 被独立地并行馈送到 Transformer 编码器中。每个具有不同大小 token 的 Transformer 编码器都执行全局自注意力。然后聚合生成的特征,在相同的特征级别上实现粗粒度与细粒度的特征表示。在特征聚合步骤中,引入了全局到局部特征交互(Global-to-Local Feature Interaction, GLI)过程,该过程将卷积局部特征连接到Transformer的全局特征,同时利用卷积的局部连通性和全局上下文。这样的多个 patch embedding 和 block 堆叠后就是这样一个 MPViT 的网络 backbone。
相关资料:
模型用例(Towhee Operator):https://towhee.io/image-embedding/mpvit 论文:MPViT: Multi-Path Vision Transformer for Dense Prediction(https://arxiv.org/abs/2112.11010) 更多资料: http://aijishu.com/a/1060000000287471 https://blog.csdn.net/amusi1994/article/details/123492604 https://www.w3cjava.com/technical-articles/%E8%AE%BA%E6%96%87%E9%98%85%E8%AF%BB/125500542.html
港大 & 腾讯 & 伯克利提出视频文本检索新SoTA BridgeFormer: 速度和深度交互我都要!
出品人:Towhee 技术团队 徐锦玲、顾梦佳
由港大 & 腾讯 & 伯克利联合提出,以“多项选择题” 的方式训练 BridgeFormer² 学习细粒度的视频和文本特征。由文本构成选择题,训练模型从视频内容中寻找答案。该方法能够实现高效的下游视频检索任务,在多个视频检索数据集上都刷新了性能 SoTA。

以往的视频文本检索模型采用两个分开的 Encoder(Dual-Encoder)或者一个 Encoder 进行建模,导致速度和多模态之间的深度交互不能兼得。这次提出的新架构在 Dual-Encoder 的基础上引入可拆卸模块 BridgeFormer,并加入新的任务——多项选择。它在构造训练样本时遮盖文本中的名词和动词,使用对比学习的形式进行训练,在推理时直接移除 BridgeFormer 模块。这种方法不仅可以实现训练时的多模态信息之间的深度交互,而且保证了推理时的速度。
相关资料:
模型用例(Towhee Operator):https://towhee.io/video-text-embedding/bridge-former 论文链接:Bridging Video-text Retrieval with Multiple Choice Questions(https://arxiv.org/abs/2201.04850) 更多资料:https://cloud.tencent.com/developer/article/2013425
没有对比学习也可以自监督预训练 Video Transformers
出品人:Towhee 技术团队徐锦玲、 顾梦佳
SVT (Self-Supervised Video Transformer)³ 摆脱了对比学习范式,搭上了自蒸馏学习桥梁。它不仅在视频动作识别任务上能够以更小的 batch size 取得更好的性能,还降低了对数据的要求,并减少了训练成本。
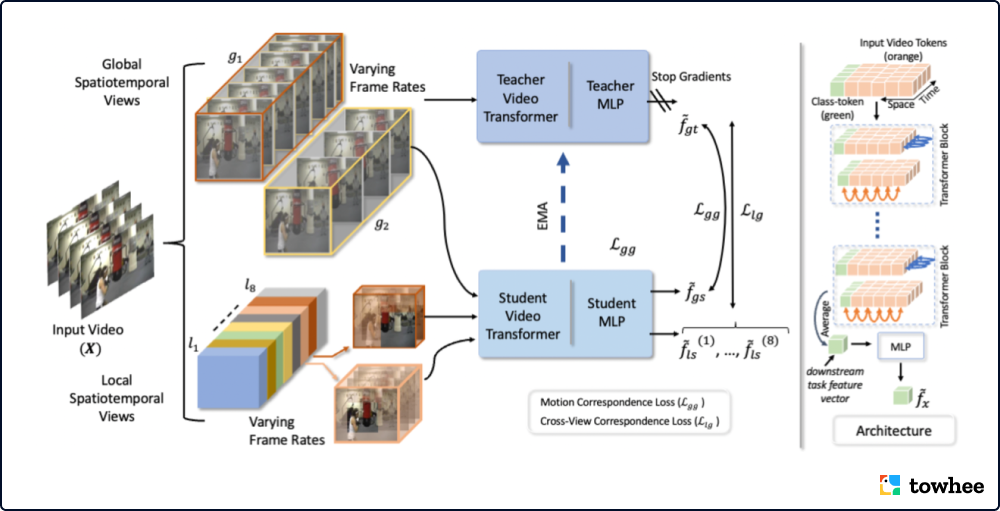
目前很多在视频上的自监督预训练模型,都是采用对比学习的方式进行训练,但是这种方式需要大的 batch size,更长的训练时间,精细的 negative 样本挖掘、以及更大的内存,并需要较好的时间采样策略,和寻找相同/不同的 clip 去减小损失。
SVT 不再使用对比学习的训练方式,而是训练 teacher 和 student 网络,采用自蒸馏的方式进行自监督训练 video transformers。其提出了 Global views 和 Local views,通过匹配 Global views 与 Global views、Global views 与 Local views 进行分别学习动作一致性(Motion Correspondences)和交叉视角一致性(Cross-View Correspondences)。在推理时,SVT 只使用student网络以加快推理速度。
相关资料:
模型代码:https://github.com/towhee-io/towhee/tree/main/towhee/models/svt 论文:https://arxiv.org/abs/2112.01514
CoFormer 带你了解视频理解领域的情境识别任务
出品人:Towhee 技术团队 顾梦佳、葛新昱
情境识别任务分为三个预测任务:识别视频中的主要活动、判断在活动中扮演特定角色的实体、寻找给定视频帧中实体的边界框。为了有效地处理这一具有挑战性的任务,CVPR 2022 收录了该领域的 SoTA 模型 CoFormer⁴ (Collaborative Transformers for Grounded Situation Recognition,协作式扫视-注视变换器) ,其中介绍了一种新的架构,使活动分类和实体识别的两个过程能够交互和互补。该模型在 SWiG 数据集上的所有评估指标上都达到了最先进的水平。

CoFormer 由两个模块组成:用于活动分类的 Glance Transformer (扫视)和用于实体识别的 Gaze Transformer (注视)。Glance transformer 通过分析实体及其相关的 Gaze Transformer 预测主要活动,而 Gaze Transformer 只关注与 Glance Transformer 预测的活动相关的物体。
相关资料:
模型代码:towhee.models.coformer 论文:https://arxiv.org/abs/2203.16518
用检索取代分类,浙大提出视频动作识别新范式 ActionCLIP
出品人:Towhee 技术团队 顾梦佳
做视频动作识别,还在为标签文本的不足而烦恼吗?一改以往单一模态分类任务的方法,ActionCLIP 提供了一种新方案:使用预训练的多模态模型,通过检索的方法识别视频动作。这种新范式不仅能够在视频动作识别的通用数据集上达到 SoTA 性能(ViT-B/16 backbone 在 Kinetics-400 上能够实现 83.8%的 top-1准确率),还具有灵活的迁移能力,无需额外标签数据,就能被应用到新的场景中。
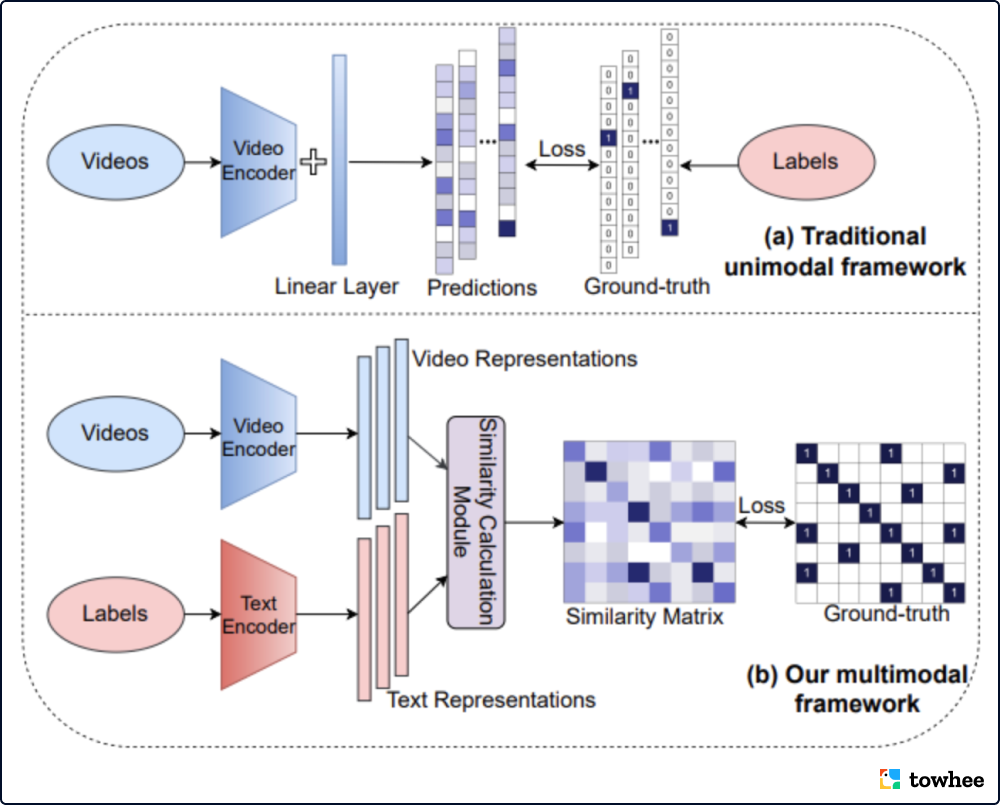
ActionCLIP⁵重视标签文本的语义信息,而不是简单地将标签映射成数字,为动作识别提供了一个新的视角。由此,动作识别任务被转换为多模态学习框架内的视频文本匹配问题,不再强烈依赖时空特征。ActionCLIP 主要分为预训练、提示和微调三个部分,使用大量的图像文本或视频文本预训练得到的特征表示,通过提示转换动作识别任务,最后对目标数据集进行微调。
相关资料:
模型用例:https://towhee.io/action_classification/actionclip 论文:ActionCLIP: A New Paradigm for Video Action Recognition(https://arxiv.org/pdf/2109.08472.pdf) 其他资料:降维打击!基于多模态框架的行为识别新范式(https://zhuanlan.zhihu.com/p/412858945)
更多项目更新及详细内容请关注我们的项目( https://github.com/towhee-io/towhee/blob/main/towhee/models/README_CN.md) ,您的关注是我们用爱发电的强大动力,欢迎 star, fork, slack 三连 :)

本文分享自微信公众号 - ZILLIZ(Zilliztech)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
边栏推荐
- Envoy source code flow chart
- Favorites|Mechanical Engineer Interview Frequently Asked Questions
- 浏览器存储
- [CLion] CLion always prompts "This file does not belong to any project target xxx" solution
- Dapr 与 NestJs ,实战编写一个 Pub & Sub 装饰器
- 库函数的模拟实现(strlen)(strcpy)(strcat)(strcmp)(strstr)(memcpy)(memmove)(C语言)(VS)
- SCHEMA解惑
- 【Unity3D插件】AVPro Video插件分享《视频播放插件》
- Audio and Video Technology Development Weekly | 256
- (ES6以上以及TS) Map对象转数组
猜你喜欢








随机推荐
R语言ggplot2可视化:使用ggpubr包的ggdensity函数可视化密度图、使用stat_central_tendency函数在密度中添加均值竖线并自定义线条类型
[CLion] CLion always prompts "This file does not belong to any project target xxx" solution
How to use DevExpress controls to draw flowcharts?After reading this article, you will understand!
Programmer's self-cultivation
A new generation of ultra-safe cellular batteries, Sihao Airun goes on sale starting at 139,900 yuan
CAN通信标准帧和扩展帧介绍
万字解析:vector类
收藏|机械工程师面试常问问题
并发编程10大坑,你踩过几个?
MarkDown公式指导手册
轮询和长轮询的区别
CloudCompare & PCL ICP registration (point to face)
音视频技术开发周刊 | 256
表达式引擎在转转平台的实践
[Open class preview]: Research and application of super-resolution technology in the field of video quality enhancement
Qt get all files in a folder
数据湖 delta lake和spark版本对应关系
C#/VB.NET 将PPT或PPTX转换为图像
Deep understanding of Istio - advanced practice of cloud native service mesh
深入解析volatile关键字